VideoFrom3D: 3D Scene Video Generation via Complementary Image and Video Diffusion Models
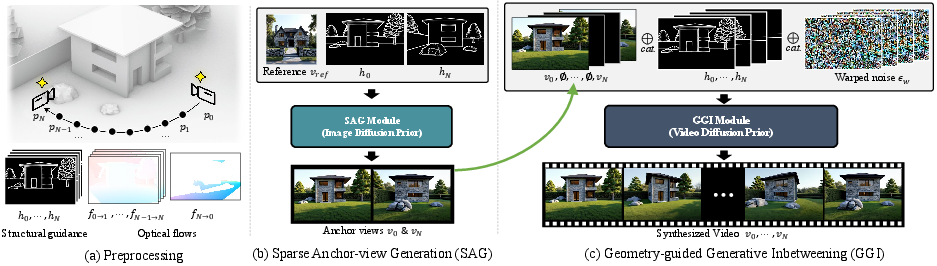
Abstract: In this paper, we propose VideoFrom3D, a novel framework for synthesizing high-quality 3D scene videos from coarse geometry, a camera trajectory, and a reference image. Our approach streamlines the 3D graphic design workflow, enabling flexible design exploration and rapid production of deliverables. A straightforward approach to synthesizing a video from coarse geometry might condition a video diffusion model on geometric structure. However, existing video diffusion models struggle to generate high-fidelity results for complex scenes due to the difficulty of jointly modeling visual quality, motion, and temporal consistency. To address this, we propose a generative framework that leverages the complementary strengths of image and video diffusion models. Specifically, our framework consists of a Sparse Anchor-view Generation (SAG) and a Geometry-guided Generative Inbetweening (GGI) module. The SAG module generates high-quality, cross-view consistent anchor views using an image diffusion model, aided by Sparse Appearance-guided Sampling. Building on these anchor views, GGI module faithfully interpolates intermediate frames using a video diffusion model, enhanced by flow-based camera control and structural guidance. Notably, both modules operate without any paired dataset of 3D scene models and natural images, which is extremely difficult to obtain. Comprehensive experiments show that our method produces high-quality, style-consistent scene videos under diverse and challenging scenarios, outperforming simple and extended baselines.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces VideoFrom3D, a new way to make high‑quality videos of 3D scenes using only simple 3D shapes, a planned camera path, and one example picture for visual style. Think of it like turning a rough 3D sketch into a polished animated clip that matches a look you love, fast and with less manual work.
Objectives: What questions are they trying to answer?
The researchers wanted to solve three practical problems in 3D design:
- How can we quickly create good‑looking scene videos from simple, unfinished 3D geometry?
- How can we keep the video consistent with the scene’s structure (so walls look like walls, windows stay where they should) and with a chosen visual style (like “cozy winter” or “watercolor painting”)?
- How can we avoid the usual issues with video generators, like low detail, wobbly motion, and flickering, especially in complex scenes?
Methods: How did they do it?
Their core idea is to combine two types of AI models—one that’s great at single images and one that’s great at videos—so each does what it’s best at.
Key ideas, explained simply
- Image diffusion model: Like an extremely smart “image painter” that can create very detailed pictures.
- Video diffusion model: Like an “animation maker” that creates a sequence of frames that move smoothly over time.
- Anchor views: Imagine key frames in animation—strong, high‑quality images at important camera positions.
- Inbetweening: Filling in the frames between those key frames so the motion looks smooth.
- Optical flow: Think of tiny arrows telling you where each pixel moves from one frame to the next.
- Edge maps: The outlines of objects in the scene (like drawing the borders of buildings and doors) to preserve structure.
- ControlNet and LoRA: Tools that let the models follow guidance (like edges) and learn a specific style from your reference image, without retraining the whole model.
The two main modules
- Sparse Anchor‑view Generation (SAG): Make the key frames look great and match the style
- Inputs: simple 3D geometry, the camera path, and a style reference image.
- The system first extracts edge maps (the outlines) from the 3D scene at the starting and ending camera positions.
- It uses an image diffusion model, guided by these edges and the style image, to produce two high‑quality “anchor” frames: the start and end views.
- To keep these two views consistent (so the building doesn’t change color or lose windows), they use Sparse Appearance‑guided Sampling:
- They “warp” (transform) the start frame toward the end frame using optical flow (the arrows showing how things move).
- Even though this warped image looks distorted, it carries useful clues about colors and what belongs where.
- During generation, the model gently borrows this information in the visible regions early on, helping the end frame stay consistent with the start frame’s look.
- Geometry‑guided Generative Inbetweening (GGI): Fill in the frames between the anchors smoothly
- The video diffusion model starts with the start and end anchor frames and generates the frames in between.
- Flow‑based camera control: They create a “warped noise” sequence using optical flow so the model follows the planned camera motion more precisely.
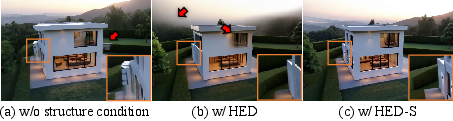
- Structural guidance: They feed in the edge maps for every frame so objects keep their shape and don’t bend or melt.
Training approach (made practical)
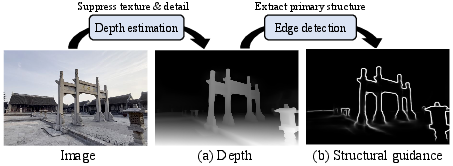
- There’s no easy dataset of “simple 3D models + camera paths + matching real photos,” so they train the video part using regular scene videos.
- To mimic the “3D edge maps” during training, they estimate depth from those videos, then detect edges on the depth (depth doesn’t include texture, so edges feel more like clean geometry).
- This makes training inputs similar to what they use at test time (geometry‑based edges), reducing mismatch.
Findings: What did they discover?
- Better visual quality and structure: Their method produced sharper, more realistic details and kept buildings, rooms, and objects shaped correctly, even in complex scenes.
- Strong style consistency: Videos matched the reference image’s look reliably, including non‑photorealistic styles (like animation or painting).
- Smooth motion with fewer artifacts: The inbetweening preserved camera motion and avoided flickering and distortions better than other approaches.
- Flexible style changes: You can switch styles between anchor frames (for example, summer to winter) and the system smoothly transitions the scene’s appearance over time.
- Outperformed baselines: Compared to popular alternatives that use only video diffusion or few‑shot 3D reconstruction methods, VideoFrom3D got higher scores on quality and consistency and looked better in visual comparisons.
Implications: Why does this matter?
This approach can speed up and simplify 3D design and storytelling:
- Faster iteration: Designers can try different camera moves, layouts, and visual styles without rebuilding detailed 3D assets or handcrafting textures and lighting.
- Early previews that look good: You can explore ideas with videos that already feel polished, helping teams give feedback sooner.
- Handles dynamic effects naturally: Because it generates video directly, it can show steam rising, reflections changing, flames flickering—things static textures struggle with.
- Useful across fields: Architecture, games, films, VR, and metaverse projects can benefit from quicker, more flexible visual prototypes.
Limitations to keep in mind
- Not real‑time: You can’t freely fly the camera around interactively.
- Occasional flicker: Diffusion models can still introduce small temporal inconsistencies.
- Some setup time: It needs short style training with LoRA per style, which takes extra minutes.
Overall, VideoFrom3D shows that teaming up image and video AI—using images for high detail and video for smooth motion—creates more reliable, stylish, and structure‑correct scene videos from minimal inputs. This can make creative workflows faster and more fun.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Dataset availability: there is no paired dataset of 3D scene meshes, camera trajectories, and high-quality multi-view natural images; develop and release such a dataset (including 3D-derived edge maps) to enable principled training and benchmarking.
- Structural guidance training: ControlNet is pretrained on HED edges from 2D images, not on 3D-model-derived edges; investigate training or adapting ControlNet on 3D-projected structural cues (edges, depth, normals) to reduce mismatch and improve fidelity.
- Domain gap in GGI training: structural guidance during training is simulated via HED-on-estimated-depth from videos; quantify and reduce the residual domain gap vs. Blender-style 3D edges used at inference (e.g., with synthetic CAD renderings).
- Camera conditioning fidelity: flow-based camera control in a downsampled latent space is only approximate; explore architectures that condition directly on camera extrinsics/intrinsics and trajectory while avoiding scale ambiguity and flicker.
- Occlusion/disocclusion handling: Sparse Appearance-guided Sampling warps v0 to vN and ignores unobserved regions; develop explicit occlusion handling and confidence-aware guidance to reduce seams and hallucinations under large disocclusions and wide baselines.
- Theoretical and empirical schedule design: the early-timestep latent replacement (12 of 25 steps) in SAG is heuristic; study principled schedules (adaptive by flow magnitude, occlusion, or uncertainty) and their impact on consistency vs. detail.
- Anchor selection strategy: the pipeline uses two anchors (v0, vN) with iterative application for longer trajectories; devise automatic anchor placement strategies (number and positions) that minimize drift and artifacts over long paths.
- Long-sequence scalability: the method generates 46 frames at 720×480; evaluate and improve scalability to minute-long sequences and higher resolutions (e.g., 1080p/4K), including memory/latency optimizations and drift control across segments.
- Temporal stability: diffusion randomness can cause flicker; develop temporal regularization losses, seed management, or consistent latent constraints to further reduce frame-to-frame variations without oversmoothing.
- Dynamic scene content: training and demonstrations focus on static scenes; extend the framework to handle moving/deformable objects and scene dynamics (people, vehicles), including geometry-aware motion conditioning.
- Physical consistency of view-dependent effects: generated reflections, steam, flames, etc. are not constrained by physical models; investigate integrating differentiable rendering or PBR priors to enforce lighting/shading consistency with geometry.
- Metric rigor: visual/structural fidelity is measured via pseudo-ground-truth warped anchors and monocular depth; establish stronger evaluation protocols (synthetic GT, multi-view consistency metrics, human preference studies) and geometry adherence measures tied to 3D edges.
- Style alignment without fine-tuning: LoRA training takes ~27 minutes per style and uses a single reference image; explore zero/few-shot style alignment (e.g., pretrained style encoders, multiple references, style disentanglement) to remove or reduce per-style fine-tuning.
- Multi-style and regional control: style switching is achieved via prompts or identifier tokens, but global; develop spatially localized style controls (per-object/region), temporal style schedules, and constraint mechanisms for seamless transitions.
- Robustness to extreme coarse geometry: edges may be sparse/ambiguous on very coarse proxies; characterize failure modes and investigate additional structural cues (semantics, normals, silhouette confidence) to preserve shape under minimal geometry.
- Generalization across geometry types: the pipeline is mesh-centric; extend to point clouds, voxels, Gaussian splats, NeRFs, or semantic proxies, and study the best structural guidance per representation.
- Camera trajectory compliance: quantify deviations between intended and realized camera paths and structural adherence; improve control via multi-scale flow guidance, pose-aware conditioning, or explicit trajectory losses.
- Failure analysis under wide baselines: although robustness is claimed, identify upper limits of anchor separation and motion complexity, and design mitigations (additional anchors, hierarchical inbetweening).
- High-resolution texturing vs. video: the paper contrasts video generation with texture synthesis but does not explore hybrids; assess pipelines that combine coarse textures with generative video overlays or view-dependent layers for better realism and editability.
- Edge type selection: Blender provides silhouette, crease, object boundary, intersection edges; study which subsets or learned edge-weighting schemes best guide diffusion across diverse scenes and styles.
- Controllability of dynamic effects: beyond camera motion and global style, users cannot precisely control temporal effects (e.g., steam intensity, flicker speed); introduce interpretable controls or latent sliders for effect amplitude and timing.
- Pose-conditioned multi-view consistency: the method does not enforce pixel-level multi-view consistency; investigate multi-view constraints in generation (e.g., 3D-aware latent spaces, cross-view feature binding) to enable reconstruction or texture extraction from outputs.
- Computational efficiency: end-to-end latency is ~197 s per trajectory plus style fine-tuning; explore model distillation, quantization, caching of conditions, or incremental generation to support interactive iteration.
- Robust training data: GGI training uses RAFT flows and MiDaS depth estimates; improve training with accurate GT flows/depth (synthetic data or multi-sensor datasets) to reduce noise-induced biases in motion and structure encoding.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s methods and findings today, along with sector alignment, potential tools/workflows, and key assumptions or dependencies.
- Previsualization for film, TV, and advertising
- Sector: media/entertainment, advertising
- What: Turn blockmesh or coarse set layouts plus director-provided camera paths and mood boards into style-consistent previz videos; quickly iterate on camera moves, lighting vibes, and set dressing without full asset texturing/lighting.
- Tools/workflows: Blender/OpenUSD pipeline → edge extraction → SAG anchor views with LoRA “style identifiers” → GGI inbetweening; “Style Bank” manager to reuse LoRAs across productions.
- Assumptions/dependencies: Needs GPU (e.g., A100 recommended for latency), per-style LoRA training (~27 min/style), valid licenses for FLUX/ControlNet-HED/CogVideoX; not real-time; potential minor temporal flicker.
- Architecture and interior design client walkthroughs
- Sector: AEC (architecture, engineering, construction), real estate
- What: Generate concept-level walkthroughs of BIM/coarse 3D models in different materials/seasons/moods (e.g., “cozy winter,” “bright minimalist”) using post-prompt style variations.
- Tools/workflows: Revit/SketchUp/Blender → camera path → style reference → SAG+GGI; “Style A/B testing” workflow for client reviews.
- Assumptions/dependencies: Coarse geometry must reflect key volumes and boundaries; static-scene assumption; style reference sourcing and copyright.
- Game level design “greybox-to-mood” previews
- Sector: gaming/software
- What: Convert greybox levels and designer camera rails into evocative look-and-feel videos for pitching mood/motion to stakeholders; explore different art directions via LoRA prompts.
- Tools/workflows: Unreal/Unity → export mesh and cameras → Blender edges → SAG/ControlNet-HED → GGI; “Level concept board” workflow where each concept equals one style LoRA.
- Assumptions/dependencies: Not interactive; no multi-view pixel-level consistency; relies on quality of coarse layout.
- Rapid content for marketing and social media
- Sector: media/marketing, e-commerce
- What: Stage products in stylized environments from asset kits and simple camera paths; produce thematic seasonality variants at low cost/time.
- Tools/workflows: Asset libraries → style reference images → style LoRA library → batch SAG+GGI jobs; SaaS/CLI pipeline for non-technical marketers.
- Assumptions/dependencies: Requires GPU inference; brand-safe and IP-safe style references; renders are videos (not reusable textured assets).
- Urban planning and public consultation visuals
- Sector: public policy, urban planning
- What: Show alternative camera fly-throughs of proposed site layouts in multiple potential visual styles (e.g., “green corridor,” “heritage façade”), enabling community engagement before costly modeling.
- Tools/workflows: GIS/3D proxy geometry → Blender edges → style references from precedent images → SAG anchor views → GGI sequences; “option deck” workflow.
- Assumptions/dependencies: Communicate that output is conceptual, not physically accurate; ensure licensing and attribution for reference styles.
- Education and training in 3D, cinematography, and design
- Sector: education
- What: In-class demos of how camera trajectories, edge-guided structure, and style references affect resulting videos; assignments that iterate on style banks and anchor view planning.
- Tools/workflows: Course kits with example meshes and camera paths → students train LoRAs for styles → run SAG+GGI; compare temporal profiles to discuss flicker/consistency.
- Assumptions/dependencies: Access to GPUs in lab or cloud; curated style references.
- Concept visualization for healthcare facilities and labs
- Sector: healthcare (facility design), life sciences infrastructure
- What: Produce early-stage walkthroughs of clinical/lab spaces using coarse layouts and style references (materials, cleanliness cues) for stakeholder buy-in.
- Tools/workflows: BIM → camera trajectories → LoRA style identifiers aligned to branding/infection-control palettes → SAG+GGI.
- Assumptions/dependencies: Static scenes; conceptual fidelity (not suitability for clinical workflow validation).
- Graphics/AI research prototyping
- Sector: academia/research
- What: Evaluate hybrid image+video diffusion workflows; study edge-conditioned control and flow-based noise warping; build small benchmarks for geometry-guided video generation.
- Tools/workflows: Reproduce SAG/GGI modules; ablation of HED vs. depth vs. canny; simulate structural guidance from depth+HED; use provided GitHub code.
- Assumptions/dependencies: Model licenses; compute; understanding of LoRA/control conditioning.
Long-Term Applications
These use cases require further research and engineering (e.g., multi-view consistency, real-time performance, physical accuracy, interactive control, asset conversion).
- Real-time interactive navigation and “live previz”
- Sector: media/gaming/AEC
- What: Move from offline video synthesis to interactive camera control in stylized worlds; adjust path and style on the fly.
- Tools/products: GPU-optimized SAG/GGI variants; streaming inference engines; editor plugins with live edge guidance.
- Dependencies: Major speedups; better temporal stability; responsive conditioning; likely model distillation/optimization.
- Multi-view consistent asset creation (video-to-texture/backfitting)
- Sector: software/graphics pipelines
- What: Derive coherent textures/materials from generated videos to populate meshes, enabling reuse in rendering engines.
- Tools/products: Inverse rendering extensions; consistency-enforcing training; “VideoFrom3D-to-Texture” converter.
- Dependencies: New methods for cross-view consistency and texture reconstruction; supervision or multi-view constraints.
- Physically grounded environmental effects and dynamic elements
- Sector: AEC/urban planning/media
- What: Integrate physically plausible simulation for lighting, fluids, and crowd behavior; ensure realistic reflections, flame flicker, steam flow.
- Tools/products: Hybrid generative-physics frameworks; structure-aware controls beyond edges (normals, materials).
- Dependencies: Coupled simulators; richer conditioning signals; data for supervised alignment.
- Synthetic data generation for perception and robotics
- Sector: robotics/AV/computer vision
- What: Create diverse, stylized videos for training perception models (e.g., detection, tracking) from proxy geometry and camera paths.
- Tools/products: Label propagation from geometry (semantic masks, depth), domain-randomized style banks; dataset generators.
- Dependencies: Improved temporal/pixel consistency; annotation fidelity; physically plausible motion.
- Digital twins and smart city scenario libraries
- Sector: urban tech, policy
- What: Rapidly update digital twin “look” for narrative scenarios (seasonal changes, material palettes) to communicate policy choices.
- Tools/products: Twin-integrated stylization services; scenario versioning with LoRA “style identifiers.”
- Dependencies: Scalable pipelines; governance and provenance; clear disclaimers about non-physical accuracy.
- E-commerce product staging with mass personalization
- Sector: retail/e-commerce
- What: Auto-generate product environment videos tailored to user segments/styles at scale.
- Tools/products: Cloud service with style banks, API for camera presets; CRM integration for personalization.
- Dependencies: Efficient per-style adaptation (few-shot or style transfer without heavy LoRA training); brand/IP compliance.
- Broadcast and virtual set design automation
- Sector: media/broadcast
- What: Generate program-specific virtual sets and transitions from wireframes, quickly testing multiple looks for shows/events.
- Tools/products: “Virtual set generator” plugins for broadcast pipelines; multi-style rehearsal tool.
- Dependencies: Better multi-view consistency for set reuse; real-time constraints; integration with tracking/camera systems.
- Education content platforms and open datasets
- Sector: education/academia
- What: Open repositories of coarse geometry + style references + generated videos for teaching generative graphics; curriculum around hybrid diffusion.
- Tools/products: Public “style banks,” anchor-view benchmarks; instructor dashboards showing structural guidance effects.
- Dependencies: Dataset curation; model licensing for distribution; compute-access equity.
Notes on Assumptions and Dependencies
- Compute and latency: Reported latencies are feasible on an A100-80GB (e.g., ~197 seconds per trajectory after LoRA training). Deployment on consumer GPUs requires careful performance planning.
- Model stack: Depends on FLUX (image diffusion), ControlNet-HED, CogVideoX (I2V), and LoRA training per style. Licensing and model availability must be verified.
- Inputs: Requires coarse geometry and explicit camera trajectories; edge extraction (e.g., Blender) and optical-flow from geometry are part of preprocessing.
- Quality and stability: VideoFrom3D does not guarantee pixel-level multi-view consistency, real-time interaction, or complete temporal stability; flicker can occur.
- Style/IP: Using reference images raises copyright and brand safety considerations; organizations should enforce style governance and provenance.
- Physical realism: Outputs are conceptual visualizations; they should not be used to make safety-critical or engineering decisions without additional validation.
- Data/domain gaps: Structural guidance (HED edges from depth) reduces training-inference gap, but domain mismatch may still impact fidelity in unconventional scenes.
Glossary
- 3D causal VAE: A variational autoencoder with spatiotemporal causality used to encode video conditions in diffusion models. "Additional implementation details on encoding the conditions with the 3D causal VAE of CogVideo-X are provided in the supplemental document."
- 3D Gaussian Splatting: A point/volume-based scene representation rendering method using anisotropic Gaussians for fast, differentiable image synthesis. "For example, MVSplat360~\cite{mvsplat360} builds a coarse 3D Gaussian Splatting~\cite{3dgs} via feedforward prediction to guide video generation."
- Background Consistency (BC): A metric that measures background similarity across frames using learned features. "as well as Subject Consistency (SC) and Background Consistency (BC) \cite{vbench++}, which compute feature similarity between each frame and both the first and adjacent frames using DINO~\cite{dino} and CLIP, respectively."
- BLIP: A vision-LLM used for image captioning/prompting to generate text descriptions from images. "we provide a text prompt generated from the first frame using BLIP~\cite{blip}, as the base model, CogVideoX, requires an input text prompt."
- Canny-edge map: An edge representation produced by the Canny detector, used as structural conditioning. "FLUX ControlNet generation results using (b) HED edge map, (c) Canny-edge map and (d) depth map."
- CLIP (Contrastive Language–Image Pretraining): A multimodal model for aligning images and text, often used for similarity and aesthetic metrics. "CLIP image similarity~\cite{clip} (CLIP-I)"
- CLIP-A: A CLIP-based aesthetics score used to evaluate image aesthetic quality. "Image aesthetics (CLIP-A) and quality (MUSIQ) are compared across 1,000 generated samples (parameter size in parentheses)."
- CLIP-I: A CLIP-based image similarity metric that measures similarity to a reference image. "For style similarity, we measure CLIP image similarity~\cite{clip} (CLIP-I) with the reference style image"
- CogVideoX-5B-1.0: A large pretrained image-to-video diffusion model used as the base for video generation. "we build upon a pretrained Image-to-Video (I2V) diffusion model, CogVideoX-5B-1.0~\cite{cogvideox}."
- ControlNet: A conditioning mechanism for diffusion models that injects structural control signals (e.g., edges, depth). "the SAG module adopts ControlNet~\cite{controlnet} as the conditioning mechanism."
- Depth-I2V: A depth-conditioned image-to-video baseline model used for comparison. "Depth-I2V is trained on DL3DV-10K~\cite{dl3dv} by concatenating depth maps to the latent input, and is initialized from I2V-CogVideoX-5B-1.0."
- DINO: A self-supervised vision transformer whose features are used for consistency metrics. "using DINO~\cite{dino} and CLIP, respectively."
- Distribution alignment: Training/fine-tuning strategy that aligns a model’s output distribution to a target style/domain. "It is noteworthy that the proposed approach is made possible thanks to the distribution alignment using the style reference image performed before synthesizing anchor views."
- FLUX-dev: A state-of-the-art text-to-image diffusion model used for generating high-quality anchor views. "The SAG module synthesizes high-quality anchor views, and , using FLUX-dev~\cite{flux}, a state-of-the-art text-to-image diffusion model."
- Flow-based camera control: A method to guide video generation along a specified camera motion using optical flow cues. "we incorporate flow-based camera control and structural guidance into the GGI module."
- Gaussianity: The property of a noise distribution being Gaussian; preserved during noise warping for diffusion sampling. "while preserving Gaussianity."
- Geometry-guided Generative Inbetweening (GGI): The proposed video module that synthesizes temporally coherent frames between anchor views with structural guidance. "Geometry-guided Generative Inbetweening (GGI) module."
- Go-with-the-Flow: A flow-aware conditioning technique/LoRA that leverages warped noise for motion control in video diffusion. "we adopt a flow-based camera control approach similar to Go-with-the-Flow~\cite{gowiththeflow,flovd}."
- HED edge detector: Holistically-Nested Edge Detection model used to produce perceptually aligned edge maps for conditioning. "we adopt a pretrained ControlNet using edges from the HED edge detector~\cite{hed}, which extracts perceptually-aligned edges from 2D images"
- Histogram equalization: A normalization technique applied to depth maps to mitigate nonlinearity/scale differences before metric computation. "we apply histogram equalization before computing PSNR."
- Image-to-Video (I2V) diffusion model: A diffusion model that generates video sequences conditioned on images (e.g., start/end frames). "we build upon a pretrained Image-to-Video (I2V) diffusion model, CogVideoX-5B-1.0~\cite{cogvideox}."
- Inbetweening: The task of generating intermediate frames between keyframes or anchor views to form smooth video. "To effectively perform the inbetweening task, we build upon a pretrained Image-to-Video (I2V) diffusion model"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large diffusion models. "we add LoRA~\cite{lora} layers to both the image diffusion model and ControlNet"
- Monocular depth estimator: A model that infers depth from a single RGB image, used for evaluation/training. "and depth maps estimated by a monocular depth estimator from the corresponding synthesized videos"
- Multi-view diffusion models: Diffusion models that condition on multiple views/poses, often for 3D-consistent image generation. "SEVA~\cite{seva} leverages multi-view diffusion models with Plucker embeddings to condition the camera trajectory."
- MUSIQ: A no-reference image quality assessment metric used to evaluate visual quality. "Image aesthetics (CLIP-A) and quality (MUSIQ) are compared"
- MVSplat360: A video/scene generation method that constructs an intermediate 3D Gaussian Splatting representation from sparse views. "MVSplat360~\cite{mvsplat360} builds a coarse 3D Gaussian Splatting~\cite{3dgs} via feedforward prediction to guide video generation."
- Optical flow: The per-pixel motion field between frames/views used for warping and motion control. "we compute the optical flows using RAFT~\cite{raft}"
- Plucker embeddings: A representation of 3D lines used to condition camera trajectories in multi-view diffusion. "SEVA~\cite{seva} leverages multi-view diffusion models with Plucker embeddings to condition the camera trajectory."
- PSNR-D: Peak Signal-to-Noise Ratio computed on depth maps to measure structural fidelity. "For structural fidelity, we compute PSNR between the GT depth maps ... (PSNR-D)."
- RAFT: A state-of-the-art optical flow estimation network used to compute motion between frames. "we compute the optical flows using RAFT~\cite{raft}"
- SDS-based image prior: A guidance prior based on Score Distillation Sampling, used to steer generative models. "the former produces blurry results due to the limited guidance from the SDS-based image prior"
- SEVA: A multi-view diffusion-based few-shot 3D reconstruction/generation method used as a baseline. "SEVA~\cite{seva} leverages multi-view diffusion models with Plucker embeddings to condition the camera trajectory."
- Semantic proxy geometry: Simplified, semantically labeled geometry used as proxy conditioning for scene generation. "scene-scale 3D generation methods conditioned on semantic proxy geometry."
- Sparse Anchor-view Generation (SAG): The anchor-view synthesis module that ensures high-quality, cross-view-consistent start/end frames. "Specifically, our framework consists of a Sparse Anchor-view Generation (SAG) and a Geometry-guided Generative Inbetweening (GGI) module."
- Sparse Appearance-guided Sampling: A sampling strategy that injects warped appearance from one view into another to enforce cross-view consistency. "To generate the end view while maintaining cross-view consistency with , we propose a Sparse Appearance-guided Sampling strategy"
- SSIM: Structural Similarity Index; a perceptual metric for image/video similarity. "To measure visual fidelity, we use PSNR, SSIM, and LPIPS~\cite{lpips}."
- Subject Consistency (SC): A metric measuring the consistency of the main subject across frames. "as well as Subject Consistency (SC) and Background Consistency (BC) \cite{vbench++}"
- Temporal coherence: The property of maintaining consistent appearance over time across frames in a generated video. "maintain temporal coherence across video frames."
- VACE: A structure-conditioned video generation framework used as a baseline. "Structure-conditioned video generation methods~\cite{vace,cosmos-transfer} provide a simple baseline"
- VAE encoder: The encoder part of a variational autoencoder used to encode frames into latent space for conditioning. "we encode the start and end frames and using the VAE encoder ."
- Warped noise volume: A spatiotemporal noise tensor warped frame-to-frame with optical flow to encode motion in diffusion sampling. "we obtain a warped noise volume, denoted as , that implicitly encodes the camera motion."
- Zero-valued latents: Latent tensors filled with zeros for frames without direct image conditioning. "Zero-valued latents are used for the intermediate frames"
Collections
Sign up for free to add this paper to one or more collections.