Real-World Point Tracking with Verifier-Guided Pseudo-Labeling
Abstract: Models for long-term point tracking are typically trained on large synthetic datasets. The performance of these models degrades in real-world videos due to different characteristics and the absence of dense ground-truth annotations. Self-training on unlabeled videos has been explored as a practical solution, but the quality of pseudo-labels strongly depends on the reliability of teacher models, which vary across frames and scenes. In this paper, we address the problem of real-world fine-tuning and introduce verifier, a meta-model that learns to assess the reliability of tracker predictions and guide pseudo-label generation. Given candidate trajectories from multiple pretrained trackers, the verifier evaluates them per frame and selects the most trustworthy predictions, resulting in high-quality pseudo-label trajectories. When applied for fine-tuning, verifier-guided pseudo-labeling substantially improves the quality of supervision and enables data-efficient adaptation to unlabeled videos. Extensive experiments on four real-world benchmarks demonstrate that our approach achieves state-of-the-art results while requiring less data than prior self-training methods. Project page: https://kuis-ai.github.io/track_on_r


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to “track a point” in real videos. Imagine you pause a video at one moment, pick a tiny dot on a person’s sleeve, and then ask the computer to follow that same dot as the video plays, even if the arm moves fast, goes behind something, or the lighting changes. That’s called point tracking.
The authors show a new way to make point tracking work better in the real world by adding a smart helper, called a verifier, that knows when to trust different tracking systems and when not to.
What questions were they trying to answer?
- How can we make point tracking in real, messy videos more reliable without paying people to hand-label thousands of frames?
- If different trackers are good at different moments, can we build a system that decides, frame by frame, which tracker to trust?
- Can this smarter “trust-chooser” help the main tracker learn from unlabeled videos and improve faster with less data?
How did they do it?
Think of tracking like a group project:
- Several “teacher” trackers each give their best guess about where the dot is in every frame. Sometimes one teacher is right, sometimes another.
- The new piece, the verifier, is like a referee. For each frame, it looks at all the teachers’ guesses and decides which guess is most likely to be correct.
Here’s how the pieces work in everyday terms:
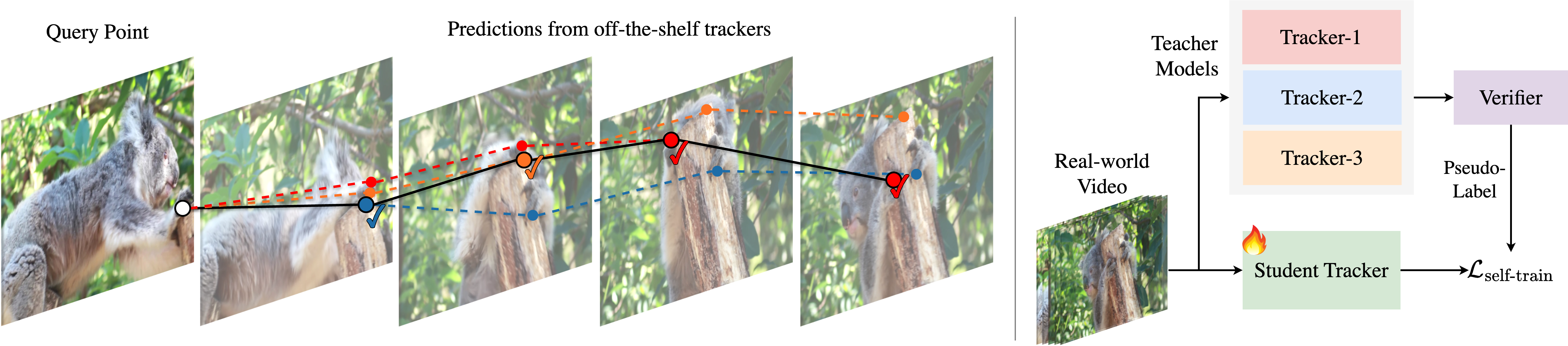
- Multiple guesses per frame: The system runs several pre-trained trackers on the same video. This gives a set of different point paths (candidate trajectories) for the same dot.
- The verifier (the referee): It looks closely at the picture around the original dot you selected and compares it to the picture around each tracker’s guessed location in later frames. If the appearance matches well and stays consistent over time, that guess gets a higher “trust score.”
- Training the verifier without real labels: They train the verifier on synthetic (computer-generated) videos where the true dot positions are known. To teach it what mistakes look like, they deliberately add “fake errors” (like drift or jumps) to the correct tracks. The verifier learns to rank good guesses higher than bad ones.
- Pseudo-labeling to learn from real videos: In real videos (which don’t have labels), the verifier picks the most trustworthy guess at each frame. Those chosen guesses become “pseudo-labels” (fake-but-usable answers) that the main tracker can practice on. Over time, this makes the main tracker better at real-world videos.
- Bonus: Ensemble at test time: Even when you’re just running the system (not training it), the verifier can still choose the best tracker per frame, combining their strengths automatically.
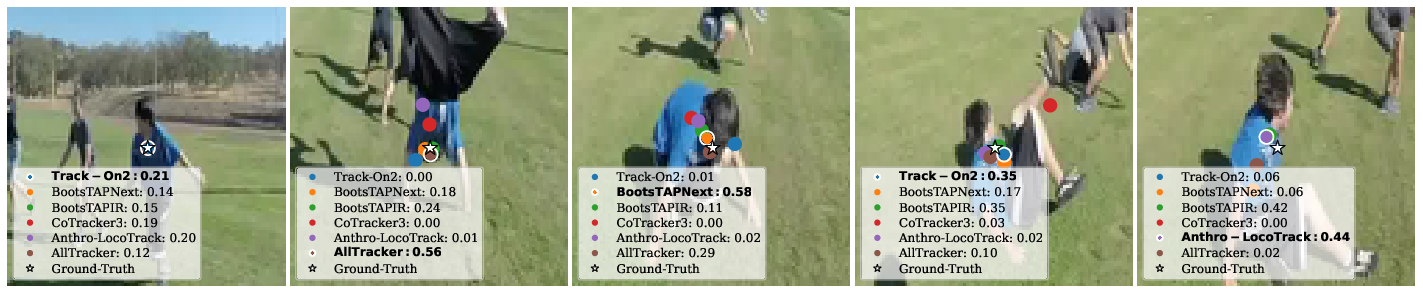
Analogy: Imagine five friends trying to follow a speck of dust in a windy room. Each friend points to where they think it is. A sixth friend, the verifier, checks who’s probably right each second by comparing what the speck looked like at the start to what it looks like now. The verifier then says, “Trust Jamie this second, now switch to Alex, now back to Jamie,” keeping the overall trace accurate.
What did they find?
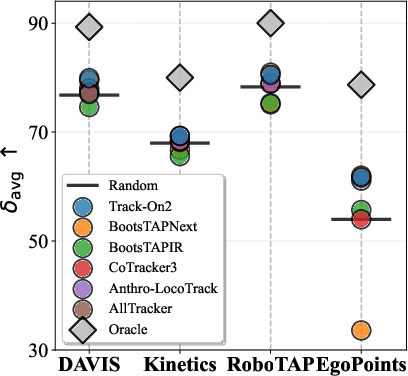
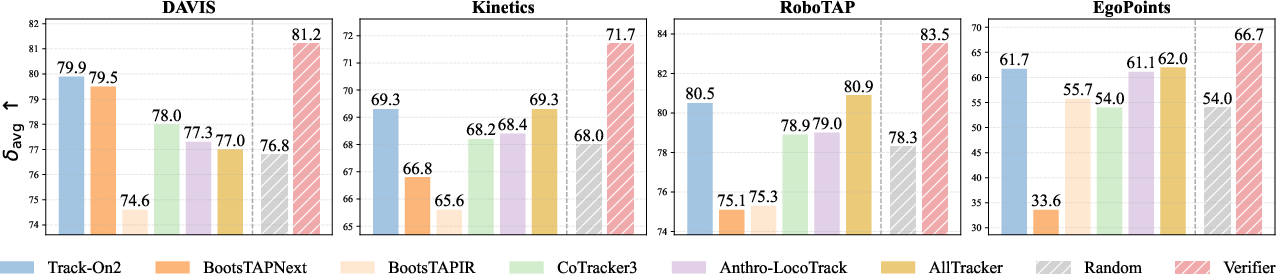
- Picking the best teacher per frame helps a lot: The authors show there’s a big gap between any single tracker and an “oracle” that always picks the best tracker for each frame. Their verifier moves closer to that oracle by switching choices over time.
- Better accuracy on real video benchmarks: On four challenging test sets (including everyday videos, robot videos, and egocentric/body-cam videos), their method reached state-of-the-art results. It tracked points more accurately and more consistently than previous methods.
- Learns with less data: Because the verifier throws out bad guesses and keeps the good ones, the main tracker trains on cleaner signals. This makes learning from unlabeled real videos more efficient than older “self-training” approaches.
- More stable visibility decisions: The system also improved the ability to tell if the point is visible or hidden at each frame.
- Works as a smart team: Even if one tracker struggles with fast motion and another struggles with occlusion, the verifier blends their strengths by choosing the right one at the right time.
Why this matters: In long, real videos, lighting, motion, and occlusions constantly change. No single tracker is best everywhere. A smart selector that adapts frame by frame gives more stable, accurate results.
Why does this matter and what’s the impact?
- Practical improvements without labels: You can adapt to real-world videos at scale without paying for manual annotations. That saves time and money.
- Better tools for creative and scientific tasks: More reliable point tracking helps in:
- Video editing (keeping effects stuck to moving objects)
- Robots (grasping and tracking objects accurately)
- 4D scene understanding (how things change over time)
- Medical analysis (following key points in scans or procedures)
- General idea: “Learn when to trust” can be reused: The verifier is a general strategy for choosing among multiple AI models on the fly, which could help in other tasks beyond tracking.
A simple note on limits: The verifier can only choose among the trackers it has. If all the teachers are weak in some situations, the verifier can’t invent perfect answers. Also, the better and more diverse the real videos you train on, the better the system becomes.
Overall, the paper shows a practical, clever way to make point tracking more reliable in the real world by adding a learned “referee” that selects the best predictions at every moment.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a verifier-guided pseudo-labeling framework for real-world point tracking. The following unresolved issues highlight concrete directions for future research:
- Training–inference mismatch in candidate distributions: the verifier is trained on synthetic perturbations of ground-truth trajectories but applied to real teacher outputs; quantify and reduce the gap between simulated errors and actual teacher failure modes (e.g., drift, identity switches, reappearance errors).
- No abstention mechanism: the verifier always selects a teacher per frame even when all candidates are wrong; develop a “none-of-the-above”/defer-to-student option with confidence thresholds or reject/abstain policies.
- Visibility estimation via majority vote: visibility labels are derived by simple voting across teachers; evaluate and design principled visibility/occlusion estimation (e.g., forward–backward consistency, occlusion-aware features, learned visibility classifiers).
- Per-frame argmax selection may introduce temporal jitter: switching teachers frame-by-frame can create discontinuities; investigate temporal smoothing, hysteresis, or Viterbi-style sequence decoding to enforce trajectory continuity.
- Lack of weighted fusion: the approach chooses a single teacher per frame rather than blending candidates; test reliability-weighted fusion or Kalman/filtering approaches that combine multiple predictions with uncertainty.
- Limited modeling of long-term consistency and loop closure: selection is local in time; explore mechanisms that enforce consistency over long horizons (e.g., cycle consistency, loop closure constraints, global optimization over entire tracks).
- No “track reset/recovery” strategy: when all teachers drift during prolonged occlusion, the verifier still commits to a candidate; incorporate explicit re-detection/re-initialization and reappearance modeling.
- Calibrated uncertainty: the verifier’s softmax scores are used as relative rankings, but their calibration is unassessed; measure and improve calibration (e.g., temperature scaling, proper scoring rules) to support thresholding and abstention.
- Sensitivity to teacher set composition: results depend on which teachers are available; characterize performance when adding/removing teachers, unseen teacher types, or when all teachers share correlated errors.
- Upper-bound dependence on teacher quality (acknowledged by authors): explore verifier training that leverages synthetic “oracle” trajectories, self-training of teachers, or meta-learning to lift the ceiling when teachers are weak.
- Frozen visual encoder from a specific tracker (CoTracker3): assess how the verifier’s performance depends on the chosen backbone, and whether end-to-end training or domain-adaptive encoders improve robustness.
- Generalization beyond the training domain of the verifier: the verifier is trained on K-EPIC synthetic data; evaluate robustness on domains with low light, severe motion blur, rolling shutter, heavy compression, or sensor artifacts unseen in K-EPIC.
- Query sampling bias: queries are drawn from SIFT and simple motion-salient heuristics; analyze how this selection biases pseudo-labels (e.g., toward high-texture regions) and track performance on low-texture surfaces or thin structures.
- Resolution and scaling effects: all evaluations (except EgoPoints resizing) are at 256×256; quantify how resizing affects sub-pixel accuracy, small-object tracking, and generalization at native/high resolutions.
- Computational cost and latency: the verifier adds per-frame cross-attention over M candidates and L frames; report and optimize runtime/memory overhead for real-time or embedded scenarios and long videos.
- Effect of sequence length: test scalability to very long sequences (thousands of frames) where per-frame selection and feature extraction may become prohibitive; explore chunking or hierarchical temporal models.
- No analysis of failure cases: provide qualitative/quantitative taxonomy of verifier failure modes (e.g., wrong selection during motion blur, repetitive textures, specularities) to guide robustness improvements.
- Visibility supervision from synthetic data only: OA gains are attributed to synthetic labels; investigate learning better visibility on real videos (self-supervised cues, multi-view consistency, auxiliary detectors).
- Self-training stability and confirmation bias: examine whether verifier-guided pseudo-labels create feedback loops that reinforce specific teacher biases; explore multi-round training, data reweighting, or consistency regularization.
- Lack of assessment of pseudo-label noise vs. performance: measure how pseudo-label error rates correlate with student improvements and identify thresholds where adaptation harms performance.
- Domain shift in teachers: teachers are themselves trained on particular distributions; analyze how teacher domain biases propagate through verifier selection and student fine-tuning.
- No use of teacher-provided confidences: if teachers output uncertainty/confidence, these are ignored; test integrating per-teacher confidences or learned teacher priors into the verifier.
- Single-point reasoning only: the verifier evaluates one query at a time; extend to multi-point joint reasoning (spatial consistency across neighboring points) to suppress outliers and enforce rigidity/non-rigidity priors.
- Handling scene cuts and camera edits: robustness to shot changes is not discussed; add cut detection and track invalidation/restart policies.
- Limited benchmarks and conditions: evaluate on additional real-world datasets (e.g., mobile phone, sports, driving at night, underwater) and under controlled degradations (blur, noise, compression) to stress-test generalization.
- Impact of teacher diversity level M: explore how performance scales with different numbers and types of teachers, and diminishing returns vs. compute cost.
- Trajectory stitching vs. framewise selection: consider selecting and stitching sub-trajectories from different teachers with overlap consistency checks rather than per-frame switching.
- Reappearance and long occlusion modeling: although perturbations simulate reappearance, there is no explicit module for reappearance detection; add explicit reappearance hypotheses and verification.
- Training augmentations for candidates: the perturbation strategy details are truncated; systematically benchmark different perturbation families and their realism relative to teacher errors.
- Robustness to adversarial or systematically biased teachers: test scenarios where one or more teachers are consistently wrong (e.g., domain-specific failure) and design safeguards (e.g., outlier teacher downweighting).
- Effect of mixing synthetic and real during fine-tuning: beyond simple schedules, study curriculum/selection strategies (e.g., easy-to-hard pseudo-labels, sample difficulty estimation) for more stable adaptation.
- Statistical significance and variability: provide confidence intervals over runs/seeds and sensitivity to hyperparameters (temperature, number of candidates, loss weights) for more rigorous conclusions.
- Release and reproducibility of real-video selection: the paper filters TAO/OVIS/VSPW to 4,864 sequences; publish the exact list and selection scripts to ensure reproducibility and facilitate fair comparison.
- Extension beyond 2D point tracking: investigate whether the verifier transfers to lines, regions, or 3D tracks (e.g., integrating depth estimates or multi-view geometry) to broaden applicability.
- Integration with physical priors: explore adding motion models (e.g., constant-velocity priors), epipolar constraints, or scene flow cues to further improve selection under fast motion or low texture.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that leverage the paper’s verifier-guided pseudo-labeling and inference-time ensemble selection. Each item lists sectors and key dependencies/assumptions that affect feasibility.
- Production-ready point tracking with per-frame model selection
- Sectors: software/media (VFX, post-production), advertising, sports broadcasting, AR/VR
- What: Use the verifier as a plug-and-play ensemble module to automatically pick the best tracker output each frame, reducing drift and identity switches in long shots without re-annotating data.
- Tools/workflows:
- A “Tracker Ensemble Adapter” that runs multiple off-the-shelf trackers, feeds outputs to the verifier, and returns a composite trajectory.
- Video editing plugins (e.g., After Effects, Nuke, DaVinci) for robust point attachment across long shots.
- Assumptions/dependencies:
- Access to multiple teacher trackers and GPU capacity to run them.
- Latency budget: ensemble inference is heavier than a single tracker; batch/offline use is straightforward, real-time requires pruning or lightweight teachers.
- Data-efficient adaptation to in-house video with no labels
- Sectors: robotics (industrial, warehouse, logistics), media companies, AR/VR platforms, surveillance/infrastructure providers
- What: Fine-tune an existing tracker to the organization’s real video streams using verifier-selected pseudo-labels, cutting annotation costs and improving domain performance.
- Tools/workflows:
- “Verifier-Guided Self-Training” pipeline: sample queries (e.g., SIFT + motion cues), run teacher ensemble, generate pseudo-labels per frame, mix with synthetic batches, fine-tune student.
- Assumptions/dependencies:
- Unlabeled video availability and rights to use for training.
- Compute resources for multi-teacher pseudo-label generation.
- Improvements are bounded by the best teacher among the ensemble.
- Reliability scoring and human-in-the-loop QA for video correspondence
- Sectors: media QC, annotation vendors, autonomous systems validation, research data curation
- What: Use the verifier’s per-frame reliability scores to flag uncertain segments, route them to human reviewers, or trigger re-tracking with different settings.
- Tools/workflows:
- Dashboard showing reliability timelines and auto-segmentation of “risky” spans for review.
- Assumptions/dependencies:
- Calibrated thresholds tuned to task tolerances.
- Human review bandwidth and integration with annotation tools.
- Improved tracking for sports analytics and telestration
- Sectors: sports tech, broadcast
- What: More stable long-term attachment of annotations, arrows, and highlights on players/equipment across fast motion and occlusion.
- Tools/workflows:
- A broadcast overlay pipeline with verifier-based ensemble selection and frame-by-frame confidence gating.
- Assumptions/dependencies:
- Camera angles and motion types covered by teacher trackers.
- Offline processing preferred for long clips; online feasible with optimized teacher set.
- Robust AR stickers and effects in consumer and creator apps
- Sectors: mobile apps, social media, AR filters
- What: Longer, more reliable attachment of effects to scene points under occlusion and lighting changes.
- Tools/workflows:
- On-device “lite” verifier with 2–3 compressed teachers; cloud-side processing for longer videos.
- Assumptions/dependencies:
- Model compression/distillation to meet mobile constraints.
- Battery/latency trade-offs if run live.
- Enhanced SLAM/Structure-from-Motion (SfM) seeding and long-term correspondences
- Sectors: robotics, drones, mapping, XR
- What: Use verifier-selected point tracks to seed SLAM/SfM with fewer outliers, improving robustness in low-texture or dynamic scenes.
- Tools/workflows:
- ROS node that exports verified tracks/visibility for downstream estimators.
- Assumptions/dependencies:
- Synchronization with SLAM front ends; frame rates compatible with real-time constraints.
- Industrial inspection and monitoring from video feeds
- Sectors: manufacturing, energy, utilities
- What: Long-term tracking of reference points on machinery or infrastructure to detect drift, misalignment, or repeatable motion anomalies.
- Tools/workflows:
- Scheduled batch runs on time-lapse or surveillance video; alerting when track stability deviates beyond thresholds.
- Assumptions/dependencies:
- Camera placement stable enough for point tracking; variability within teacher capabilities.
- Academic tooling for correspondence research
- Sectors: academia, R&D labs
- What: A reference implementation for meta-level reliability estimation and ensemble selection for point tracking benchmarks.
- Tools/workflows:
- Open-source “VerifierKit” with scripts for teacher orchestration, pseudo-label export, and reproducible ablations.
- Assumptions/dependencies:
- Availability/licensing of teacher checkpoints; consistent evaluation protocols.
- Privacy-aware dataset creation with fewer labels
- Sectors: policy-adjacent data governance, public-sector labs
- What: Build pseudo-labeled video datasets using internal or publicly licensed footage to reduce manual labeling.
- Tools/workflows:
- An internal pipeline that logs provenance, consent metadata, and uses verifier confidence to govern what data is kept or discarded.
- Assumptions/dependencies:
- Compliance with data rights and usage policies; audit trails for pseudo-label provenance.
- Medical video for training and skills assessment (non-diagnostic)
- Sectors: healthcare education, surgical training
- What: Track instruments/tissue landmarks in endoscopy/surgical videos to support training analytics without extensive labels.
- Tools/workflows:
- Offline domain adaptation using unlabeled OR videos to produce pseudo-labeled tracks for training curricula and feedback.
- Assumptions/dependencies:
- Strict privacy/consent; domain shift may require specialized or fine-tuned teachers; not for clinical diagnosis without validation.
Long-Term Applications
These use cases are plausible but require further research, scaling, optimization, or regulatory validation before widespread deployment.
- Real-time, on-device verifier ensembles for AR glasses and mobile robotics
- Sectors: consumer XR, service robotics, wearables
- What: Per-frame selection across compact teacher models to keep persistent anchors stable over hours of usage.
- Dependencies/assumptions:
- Efficient distillation/quantization of teachers and verifier; hardware acceleration; latency under tight budgets.
- Energy constraints and thermal limits.
- Foundation-scale video learning via verifier-guided pseudo-labels
- Sectors: AI platform companies, academia
- What: Train large video correspondence/backbone models on massive unlabeled corpora using high-quality pseudo-labels to bridge sim-to-real gaps.
- Dependencies/assumptions:
- Scalable orchestration for multi-teacher inference; data governance at scale; robustness to domain/biases.
- Improved teachers raise the verifier’s performance ceiling.
- Autonomous driving and ADAS: persistent scene point tracking for object permanence
- Sectors: automotive
- What: Complement detection/flow with long-term point trajectories for occlusion handling, motion priors, and map consistency.
- Dependencies/assumptions:
- Multi-camera, adverse-weather robustness; safety validation; tight real-time budgets; integration with sensor fusion stacks.
- Deformable object manipulation and contact-rich control
- Sectors: robotics (manufacturing, household, agriculture)
- What: Use verified long-term points as state for feedback control when manipulating cloth, cables, or food items.
- Dependencies/assumptions:
- Closed-loop latency; resilience to occlusions and self-similarity; task-specific training data.
- Dynamic 4D scene reconstruction and video-centric NeRFs
- Sectors: 3D content, digital twins, AEC
- What: Feed cleaner long-term correspondences into dynamic reconstruction pipelines for more stable geometry and texture over time.
- Dependencies/assumptions:
- Harmonization of track visibility with non-rigid modeling; robustness to long sequences and lighting changes.
- Medical diagnostics and monitoring with regulatory approval
- Sectors: healthcare
- What: Track lesions/catheters/cardiac landmarks in ultrasound, endoscopy, or microscopy for quantitative diagnostics.
- Dependencies/assumptions:
- Domain-specific teacher models; extensive clinical validation and regulatory approvals; bias and safety assessments.
- Wildlife/ecology monitoring and sports biomechanics at scale
- Sectors: environmental science, sports medicine
- What: Long-term tracking of anatomical landmarks or tags to infer behavior and biomechanics without dense labeling.
- Dependencies/assumptions:
- Camera variability, occlusion by environment; ethical guidelines and permits.
- Policy and standards: reliability-aware pseudo-labeling guidelines
- Sectors: standards bodies, public agencies
- What: Define benchmarks and best practices for using per-frame reliability in dataset creation and model auditing.
- Dependencies/assumptions:
- Consensus on metrics; transparent reporting of pseudo-label provenance and uncertainty.
- Energy and infrastructure: predictive maintenance from thermal/visible video
- Sectors: energy, utilities, transportation
- What: Persistent tracking of hotspots and structural points for early fault detection under varying conditions.
- Dependencies/assumptions:
- Domain-adapted teachers for thermal/spectral video; stable camera placement or registration.
- Finance/retail security analytics with low false alarms
- Sectors: security, retail operations
- What: Reliability-gated tracking to reduce false positives in event detection pipelines.
- Dependencies/assumptions:
- Privacy compliance; camera variability; integration with existing VMS/alert systems.
Cross-cutting dependencies and assumptions
- Upper bound limited by teachers: The verifier cannot exceed the best available candidate per frame; stronger or more diverse teachers yield better results.
- Compute and latency: Multi-teacher inference is expensive; real-time and edge deployments need model compression and careful selection of teachers.
- Data governance: Using unlabeled real videos for training must respect licenses, consent, and privacy; logging and audit trails are recommended.
- Domain shift: Some domains (e.g., medical microscopy, thermal imaging) may require specialized teachers or pre-adaptation.
- Integration complexity: Downstream systems (SLAM, control, editors) need interfaces to ingest tracks and visibility with reliability scores.
- Evaluation and safety: Safety-critical uses (healthcare, automotive) demand rigorous validation, calibration, and monitoring before deployment.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient update, commonly used for training deep neural networks. "Optimization uses AdamW~\cite{Loshchilov2019ICLR} on 32A100 (64\,GB) GPUs with mixed-precision training."
- annotation-free adaptation: Adapting models to new (target) data without requiring human-provided annotations. "This unified approach turns model diversity into a strength, yielding annotation-free adaptation, improved robustness to distribution shift, and better long-term coherence."
- Average Jaccard (AJ): A tracking evaluation metric that combines localization and visibility performance into a single score. "{Average Jaccard (AJ)}, a combined measure of localization and visibility."
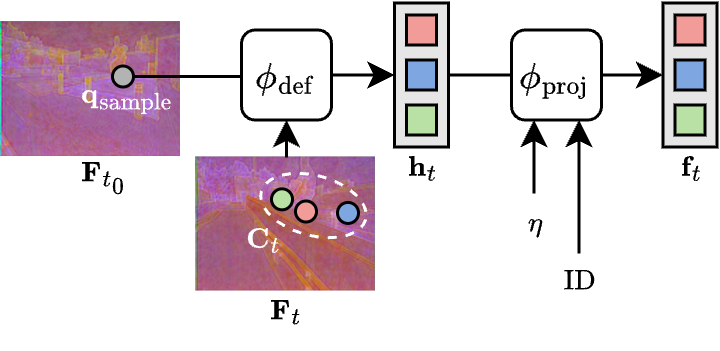
- bilinear sampling: A feature sampling method that interpolates values from a grid (e.g., feature map) at non-integer coordinates using bilinear interpolation. "We first obtain this reference embedding by bilinearly sampling the feature map at :"
- causal tracking: A tracking setup where predictions at any time use only past and current information, not future frames. "Models are evaluated in the {queried-first} setting, corresponding to the causal tracking scenario:"
- contrastive objective: A learning objective that encourages distinguishing correct examples from incorrect (or corrupted) ones by comparing similarities. "using a contrastive objective to rank correct versus corrupted alternatives."
- cosine decay schedule: A learning-rate scheduling strategy that follows a cosine curve from an initial maximum down to a minimum. "The learning rate follows a cosine decay schedule with 1\% warmup and peaks at ."
- cosine similarity: A similarity measure between two vectors computed from the cosine of the angle between them. "Formally, for each frame , we compute a temperature-scaled softmax over cosine similarities between the decoded query feature and the candidate features :"
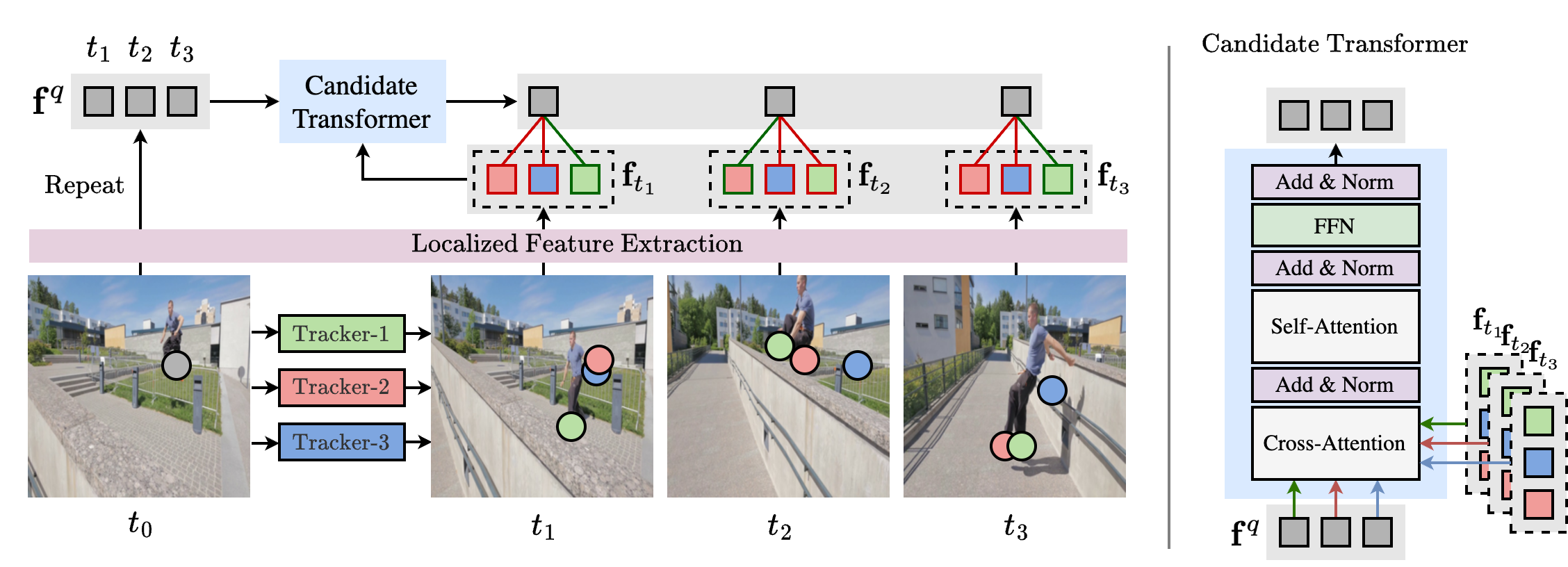
- cross-attention: An attention mechanism where a set of query embeddings attends to a different set of key–value embeddings (e.g., queries attending to candidate features). "consists of restricted cross-attention, where each frame-level query attends only to its corresponding candidates"
- cross-entropy loss: A loss function used for classification, measuring the difference between predicted probabilities and target distributions. "The predicted reliability scores are supervised using a cross-entropy loss"
- deformable attention: An attention mechanism that samples from learned offset positions to focus on relevant local regions in feature maps. "deformable attention is applied at both the query and candidate locations"
- deformable attention decoder: A stack of layers that applies deformable attention to decode localized features for target positions. "a three-layer deformable attention decoder that extracts localized descriptors around query and candidate positions."
- domain gap: A discrepancy between training and deployment domains (e.g., synthetic vs. real), causing performance degradation. "differences in texture, illumination, motion, and occlusion patterns introduce a domain gap, potentially leading to degraded performance."
- ensemble learning: Combining multiple models’ predictions to improve robustness and generalization. "ensemble learning~\cite{Freund1996ICML, Breiman1996ML} combines predictors to improve generalization."
- Euclidean distance: The straight-line (L2) distance between points in Euclidean space, often used to measure localization error. "computes the Euclidean distance from each candidate to the ground truth"
- identity switches: Tracking errors where the tracked identity of a target swaps to a different object over time. "others handle occlusion better but suffer from identity switches or jitter."
- inference-time ensemble: Combining multiple model predictions during inference (test time) to improve performance. "Verifier as inference time ensemble."
- jitter: Small, rapid, and undesired fluctuations in predicted positions over time. "others handle occlusion better but suffer from identity switches or jitter."
- majority voting: Aggregation strategy that selects the outcome predicted by the majority of models. "Visibility is estimated via majority voting across teacher predictions."
- meta-model: A model that operates on the outputs of other models (e.g., scoring their reliability) rather than directly on raw inputs. "introduce verifier, a meta-model that learns to assess the reliability of tracker predictions and guide pseudo-label generation."
- occlusion: A phenomenon where the tracked point/object becomes partially or fully hidden from view. "maintaining fine-grained correspondences under motion, occlusion, and reappearance."
- Occlusion Accuracy (OA): A metric measuring the accuracy of visibility (occlusion) predictions. "{Occlusion Accuracy (OA)}, visibility prediction accuracy;"
- oracle: An idealized selector that, with access to ground truth, picks the best prediction at each instance for upper-bound performance. "we construct an oracle that, at each time step, selects the prediction closest to the ground truth"
- pseudo-labels: Automatically generated labels (from model predictions) used as supervision for unlabeled data. "Self-training via pseudo-labels is an attractive path forward:"
- pseudo-labeling: The process of creating and using pseudo-labels to train or adapt a model. "verifier-guided pseudo-labeling substantially improves the quality of supervision"
- query point: The initial point provided to a tracker from which the trajectory is to be estimated across frames. "(Left) Given a query point in a real-world video, multiple off-the-shelf trackers produce alternative trajectory hypotheses."
- self-attention: An attention mechanism where elements in a sequence attend to other elements within the same sequence, enabling contextual reasoning. "Each layer consists of localized cross-attention, temporal self-attention, and a feed-forward network"
- self-distillation: A training strategy where a model (or its ensemble/temporal variants) supervises itself or a student model using its own predictions. "BootsTAPIR~\cite{Doersch2024ARXIV} applies large-scale self-distillation"
- self-training: Adapting a model using its own (or a teacher’s) predictions as supervision on unlabeled data. "Self-training on unlabeled videos has been explored as a practical solution"
- sim-to-real discrepancy: The mismatch between synthetic training data and real-world deployment that harms generalization. "models often inherit a sim-to-real discrepancy: appearance statistics, nonrigid motion, occlusion patterns, lighting changes, and sensor artifacts in natural footage degrade reliability over extended sequences."
- sinusoidal embedding: A positional encoding scheme using sinusoidal functions to represent spatial or temporal positions. "we apply a sinusoidal embedding to displacement vectors"
- softmax: A function that converts a vector of scores into a probability distribution, often used for classification or selection. "We define the per-frame target reliability distribution as a softmax over the negative distances"
- spatio-temporal cues: Information that combines spatial and temporal evidence to improve decision making over time. "select reliable labels via spatio-temporal cues."
Collections
Sign up for free to add this paper to one or more collections.