Tackling Length Inflation Without Trade-offs: Group Relative Reward Rescaling for Reinforcement Learning
Abstract: Reinforcement learning significantly enhances LLM capabilities but suffers from a critical issue: length inflation, where models adopt verbosity or inefficient reasoning to maximize rewards. Prior approaches struggle to address this challenge in a general and lossless manner, primarily because additive penalties introduce a compensatory effect that creates optimization shortcuts, while heuristic gating strategies lack generality beyond binary feedback. To bridge this gap, we present Group Relative Reward Rescaling (GR$3$), which reframes length control as a multiplicative rescaling paradigm, effectively establishing a generalized, continuous, and reward-dependent gating mechanism. To further ensure lossless optimization, we incorporate group-relative regularization and advantage-aware calibration, which dynamically adapt length budgets to instance difficulty and preserve the advantage signal of high-quality trajectories. Empirically, across both RLHF and RLVR settings, GR$3$~maintains training dynamics and downstream performance comparable to standard GRPO while significantly mitigating length inflation, outperforming state-of-the-art length-regularized baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
LLMs often get better when trained with reinforcement learning (RL). But there’s a common problem: after RL, models start writing much longer answers than needed. This “length inflation” wastes time, money, and energy, and sometimes the long answers don’t actually improve quality.
This paper introduces a new method called GR3 (Group Relative Reward Rescaling). It teaches models to stay concise without losing skill. In fact, the authors show the model can get better and shorter at the same time.
What questions the paper tries to answer
- Can we stop LLMs from becoming overly long-winded during RL, without hurting their performance?
- Can we design a general solution that works both when rewards come from humans (RLHF) and when rewards come from automatic checks like math verifiers (RLVR)?
- How can we discourage unnecessary length without giving the model an “easy shortcut” that breaks learning?
How the method works (in everyday terms)
First, a few quick ideas in simple words:
- Reinforcement learning (RL): Like training a pet with treats—give the model “rewards” for good answers so it learns what to do.
- Reward hacking: When the model figures out a trick to get higher reward without actually getting better (e.g., writing longer to look “smarter” to a biased reward).
- Group sampling: For one question, the model tries multiple answers. Then the training compares those answers to each other.
The new method, GR3, has three key pieces:
- Multiplicative rescaling (reward-aware shrinking)
- Instead of subtracting a “length penalty” from the score, GR3 multiplies the reward by a factor that gets smaller when the answer is longer.
- Think of the reward as the “volume,” and the length factor as a “volume knob.” For longer answers, the knob turns down; for shorter ones, it stays up. But crucially, the knob only matters when there’s real reward to amplify—no reward means nothing to amplify. That makes the length control automatically depend on how good the answer is, avoiding silly shortcuts.
- In short: new_reward = reward × shrink_factor. No reward? Shrink factor doesn’t help. Good reward? The factor encourages getting that reward with fewer words.
- Group-relative regularization (compare to peers, not a fixed cap)
- For each question, the model generates a small group of answers. GR3 compares each answer’s length to the group’s average length for that same question.
- Why? Because hard questions might genuinely need more steps, while easy ones shouldn’t. Using “relative length” adapts naturally to difficulty. It avoids rigid, one-size-fits-all length limits (like “never exceed 4,000 tokens”) that can chop off useful reasoning in tough cases.
- Advantage-aware calibration (keep good signals intact)
- RL uses something called “advantage,” which measures how much better an answer is than the group average. If a penalty is too strong, even good answers can look “bad” to the learning algorithm.
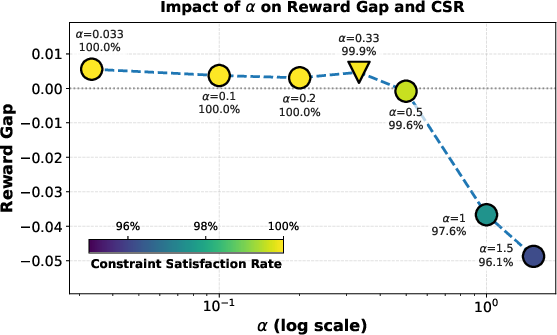
- GR3 chooses the length strength (a single number, α) so that a representative, high-quality, average-length answer still gets a positive training signal. The authors quickly test and pick an α that satisfies this in practice, so learning stays stable.
Why not the old way (subtracting length)?
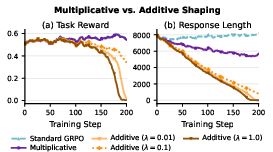
Older methods often did “new_reward = reward − λ × length.” That creates a second goal—be short—that the model can chase even when it’s not getting better at the task. The model can “game” the system by being very brief, hurting performance. GR3 avoids that trap by tying the length control directly to how good the answer is (multiplying by a factor) rather than subtracting a separate penalty.
What the researchers did (methods)
- They integrated GR3 into a popular RL setup called GRPO (Group Relative Policy Optimization), where the model samples multiple answers per prompt and compares them within each group.
- They tested on:
- Math reasoning (RL with verifiable rewards, or RLVR), where solutions can be checked automatically.
- Code generation (also RLVR-like).
- Chat/alignment tasks (RL from human feedback, or RLHF), where a reward model judges quality.
- They compared GR3 against:
- Standard RL training without special length control.
- Length-penalty baselines that used fixed thresholds or subtractive penalties.
- Other group-based length methods.
They measured both performance (accuracy or preference scores) and the number of tokens generated (how long the answers are).
What they found and why it matters
Here are the main takeaways:
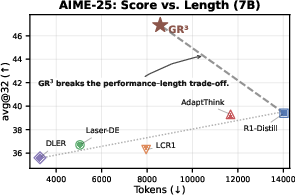
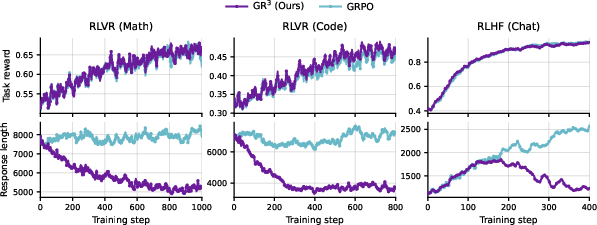
- Shorter answers without losing (and often gaining) performance
- In math benchmarks (like AIME-24/25), GR3 cut token usage by large margins (often over 40%) while matching or improving accuracy compared to standard RL.
- On some tasks, GR3 not only avoided harm—it beat the usual RL baseline in accuracy, while still being shorter.
- Works across different training styles
- GR3 helped both in RLHF (human-judged rewards) and RLVR (auto-verified rewards), showing the approach is general.
- In chat tasks, GR3 improved quality scores like Arena-Hard while keeping answer length near the original model’s length—unlike standard RL, which blew up response length.
- More stable training, fewer shortcuts
- Subtractive penalties (old way) often led the model to chase shortness at the expense of quality.
- GR3’s multiplicative design avoids that “compensation” shortcut, so the model focuses on being both correct and concise.
- Better “signal density”
- When answers are too long, the useful learning signal gets spread over many extra tokens. By trimming unhelpful verbosity, GR3 concentrates learning on the important reasoning steps—helping the model learn more efficiently.
Why this could matter in the real world
- Saves cost and energy
- Shorter answers mean fewer tokens to process. That cuts inference time, server costs, and energy use—good for both budgets and the environment.
- Less reward hacking
- By tying length control to true task success, GR3 helps prevent models from “looking good” just by being verbose. That makes AI systems more aligned with what people actually want: clear, helpful, correct answers.
- Broadly useful
- Because the method is general and simple to plug into RL training, it can be used for math, coding, and chat tasks—and likely beyond.
In summary
GR3 is a new way to control answer length during RL training that doesn’t trade quality for brevity. It multiplies the reward by a smoothly shrinking factor based on relative length, compares lengths within each group so it adapts to difficulty, and carefully sets the penalty strength so good answers keep strong learning signals. The result: models that are both smarter and more concise.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Theoretical guarantees: Despite the “lossless” claim, there is no formal proof that multiplicative rescaling with group normalization preserves (or improves) optimal policy performance relative to standard GRPO across general reward distributions; convergence and monotonic improvement guarantees remain unproven.
- Reward-scale generality: The method assumes non-negative, bounded rewards (e.g., RLHF uses sigmoid-shifted ). It is unclear how GR behaves with negative or unbounded rewards, or when has heavy tails or is multi-modal.
- Sparse/zero-reward regimes: When for most trajectories (e.g., early-stage RLVR on hard tasks), multiplicative shaping yields near-zero shaped reward, potentially suppressing learning signals. The trade-off between “reward-aware” suppression and exploration is not analyzed.
- Interaction with KL control: The interplay between multiplicative rescaling and the KL penalty term (β) is not studied. How does rescaling affect effective KL pressure, policy drift, and stability under different β schedules?
- Group size sensitivity: GR relies on group statistics (mean length ) and group-normalized advantages. The sensitivity to group size (sample efficiency, variance) and minimal for stability/benefit is not reported.
- Robustness of the length statistic: Using the group mean may be sensitive to outliers or heavy-tailed length distributions within a prompt’s samples. Alternatives (median, trimmed mean, winsorization) and their effects are unexplored.
- Dynamic non-stationarity: Advantage-aware calibration selects a fixed via an initial short calibration. As the policy distribution evolves, the constraint satisfaction rate (CSR) may drift; there is no adaptive or theoretically grounded scheme for online re-calibration or automatic scheduling.
- Constraint design: The average-case advantage preservation constraint protects a “representative” high-quality trajectory with length , but may still penalize many correct longer trajectories (especially under high reward density). Criteria that balance protection for a fraction/quantile of high-quality traces remain unexplored.
- Extreme reward-density cases: Groups with all-correct trajectories are filtered out, but the frequency, impact on training signal, and alternatives to filtering (e.g., adaptive scaling, alternate normalization) are not analyzed.
- Applicability beyond GRPO: GR is tailored to group-relative advantage and GRPO. Its transferability to other RL algorithms (PPO with a value function, A2C, off-policy methods, DPO-style objectives) is untested.
- Token-level vs. trajectory-level shaping: Rescaling is applied uniformly at the trajectory level. Whether finer-grained token/segment-level utility estimates (e.g., learned token attribution) could yield better “intelligence per token” than global length penalties is not explored.
- Exploration–exploitation trade-offs: Penalizing long trajectories may hinder exploration of legitimately long reasoning chains early in training or on intrinsically long tasks. A principled mechanism to preserve exploration capacity (e.g., phase-wise or uncertainty-aware penalties) is missing.
- Task domains requiring long outputs: The method is evaluated on math reasoning, code, and chat. Tasks where long outputs are the objective (e.g., creative writing, long-form summarization, multi-turn planning) are not studied; risk of under-thinking/under-explaining remains.
- Generalization across languages/modalities: Robustness to multilingual settings, multimodal reasoning (e.g., VLMs), and long-context inputs is not evaluated.
- Human evaluation in RLHF: RLHF results rely on an automatic reward model and Arena-Hard-Auto. Direct human preference evaluations and robustness to reward-model misspecification or drift are not provided.
- Tail behavior and latency: Only average token counts are reported. Tail metrics (e.g., 95th/99th percentile length), wall-clock inference latency, memory footprint, and energy use are not measured, limiting conclusions about real-world efficiency.
- Fairness and breadth of baselines: Some baselines (e.g., Kimi-k1.5) are reported as unstable without detailed settings; comprehensive hyperparameter searches, ablations, and seed variance reporting for baselines are limited, leaving comparative conclusions partially uncertain.
- Component-wise ablations: While some ablations are referenced, a full factorial study isolating each component—multiplicative rescaling vs. group-relative normalization vs. advantage-aware calibration—across tasks and scales is not fully presented.
- Sensitivity to : The selected is justified via CSR, but a broader mapping from task characteristics to (or automatic tuning rules) is missing. Whether per-prompt or per-group adaptive could outperform a global is open.
- Robustness to decoding strategies: Interaction with inference-time settings (e.g., temperature, top-p, self-consistency, early-exit/verify-then-stop) and whether training-time savings translate under different decoding regimes are not examined.
- Adversarial adaptation: Models might “compress” by obfuscating or densifying information (e.g., terse but less readable code/reasoning). Effects on readability, interpretability, and downstream human usability are unmeasured.
- Safety implications: Shorter outputs might omit safety guardrails or necessary disclaimers in some contexts. No targeted safety or red-teaming evaluation is reported to ensure safety quality is maintained under length pressure.
- Failure modes under distribution shift: The behavior of GR when deployed on out-of-distribution prompts with different length requirements is unknown; dynamic adaptation mechanisms for such shifts are absent.
- Computational overhead: The additional cost of group-level statistics and calibration phases (time, memory) is not quantified; the net training-time efficiency trade-off is unclear.
- Negative interactions with partial-credit rewards: Many RLVR tasks can have graded/partial credit. How multiplicative rescaling interacts with partial credit (e.g., discouraging necessary extra steps for marginal gains) is not analyzed.
- Formal connection to heuristic gating: While the paper motivates multiplicative rescaling as a continuous generalization of gating, a precise characterization of when and how gating and rescaling diverge in optimization behavior (especially under continuous rewards) is not fully developed.
Practical Applications
Immediate Applications
These applications can be deployed with current LLM RL pipelines (GRPO/RLHF/RLVR) and standard infra, leveraging GR3’s multiplicative reward rescaling, group-relative normalization, and advantage-aware calibration.
- Software/AI platforms: drop-in RL training upgrade
- Use case: Integrate GR3 into existing GRPO-style RLHF and RLVR fine-tuning to reduce tokens while preserving or improving task quality.
- Tools/workflows:
- GR3Trainer as a plugin for TRL-like frameworks; hooks for multiplicative shaping and group-relative length S(x,y).
- AutoAlpha calibration routine using CSR (constraint satisfaction rate) at the start of training; logging CSR and reward gap.
- Assumptions/dependencies: Requires group sampling per prompt (G>1), access to reward signals (binary or continuous), and minimal code changes in the PPO/GRPO loop.
- Cost and latency reduction for production assistants
- Sector: customer support, search, productivity suites, developer tools.
- Use case: Fine-tune chatbots and copilots with GR3 to cut average response length (often >30–40%) without losing quality, increasing throughput and reducing inference costs.
- Potential products: “Efficiency-tuned” chat and coding models; QoS tiers offering “same quality, fewer tokens.”
- Assumptions/dependencies: Requires a short RL fine-tuning pass on domain prompts; benefits realized at inference without runtime overhead.
- Code generation assistants with concise outputs
- Sector: software engineering, DevOps, data engineering.
- Use case: Produce shorter, higher-signal generations (e.g., minimal diffs, focused explanations); reduce review time and CICD resource usage.
- Workflows: RLVR with verifiers for unit tests; GR3 reduces overlong chains of thought and extraneous commentary.
- Assumptions/dependencies: Availability of verifiers/test harnesses; training data reflective of desired style.
- Efficient math/STEM tutoring and problem solvers
- Sector: education, edtech platforms.
- Use case: Train reasoning models that retain solution accuracy with concise steps; improve readability for learners and reduce token spend for platforms.
- Workflows: RLVR with math verifiers + GR3; deploy as “succinct solver/tutor” mode.
- Assumptions/dependencies: Task verifiers and prompt distributions similar to training conditions.
- RLHF reward-hacking mitigation in alignment workflows
- Sector: general LLM alignment across industries.
- Use case: Replace additive length penalties with GR3 to prevent verbosity-driven reward hacking and stabilize reward improvements.
- Tools: Reward-model pipelines augmented with multiplicative rescaling; dashboards that track length vs reward to detect exploitation.
- Assumptions/dependencies: Stable reward model; continuous rewards supported by multiplicative gating.
- Efficiency-aware evaluation and monitoring
- Sector: MLOps, evaluation vendors, internal QA.
- Use case: Add “intelligence per token” KPIs (e.g., tokens per solved, Pareto curves) and CSR-based safety checks into model evaluation suites.
- Tools: Efficiency Dashboard tracking reward gap, tokens, CSR, length distributions per dataset.
- Assumptions/dependencies: Access to token accounting, group stats during training, and standardized eval prompts.
- Cloud/AI service providers: cost-optimized post-training
- Sector: cloud AI, model marketplaces.
- Use case: Offer GR3-based post-training as a managed service to cut operational costs for customers while maintaining accuracy.
- Products: “Green RL” post-training SKU; SLAs tied to quality and token budgets.
- Assumptions/dependencies: Multi-tenant training infrastructure; billing that exposes token-level savings.
- Research labs and smaller teams: compute-efficient RL
- Sector: academia, startups, NGOs.
- Use case: Achieve state-of-the-art or better results with fewer tokens and training instability; enable more experiments under fixed budgets.
- Workflows: GR3-enabled GRPO baselines; ablation-friendly calibration step.
- Assumptions/dependencies: Ability to run group sampling; modest code modifications.
- ESG and sustainability reporting for AI operations
- Sector: enterprise policy/ESG teams.
- Use case: Include “tokens saved” and energy reductions attributable to GR3 in environmental reports and procurement.
- Tools: Automated reporting that translates token reductions into carbon and cost estimates.
- Assumptions/dependencies: Organizational adoption of efficiency KPIs and metering.
- User-level verbosity control that preserves quality
- Sector: daily life, consumer apps.
- Use case: Offer a “concise mode” switch that maps to GR3-trained models, preserving answer quality while reducing reading time and data usage.
- Products: Mobile-friendly assistants with lower latency and bandwidth consumption.
- Assumptions/dependencies: Model variants trained with GR3; UX surfaces for verbosity preferences.
Long-Term Applications
These opportunities build on GR3’s principles but may require further research, scaling, standards, or ecosystem adoption.
- Frontier-model post-training standard for efficiency
- Sector: foundation model labs, enterprise AI.
- Use case: Make multiplicative, group-relative rescaling the default for RL post-training across reasoning models to shift the accuracy–cost Pareto frontier at scale.
- Products: “Efficiency-first RL” pipelines; enterprise certifications for efficiency-aware training.
- Dependencies: Validation across broader tasks, large-scale hyperparameter studies, and rigorous safety auditing.
- On-device and edge reasoning with reduced compute
- Sector: mobile, embedded, automotive.
- Use case: Train models that achieve target performance with fewer tokens, enabling local inference on constrained devices.
- Products: Edge copilots, in-car assistants, offline tutors using concise reasoning traces.
- Dependencies: Model compression/quantization synergy; dataset curation for on-device use; memory-aware group sampling for small devices (training still server-side).
- Multimodal and tool-using systems with step-budgeting
- Sector: vision-language, agents, robotics.
- Use case: Extend group-relative rescaling to sequence length proxies beyond text (e.g., number of tool calls, perception steps, or plan length) to avoid overlong plans/chains.
- Products: Agents that minimize tool/API calls per task; VLMs that avoid redundant reasoning frames.
- Dependencies: Well-defined “length” analogs across modalities; verifiers for non-text outputs; stable multi-step reward design.
- Automated alpha scheduling and adaptive constraints
- Sector: RL systems research.
- Use case: Learn dynamic penalty strength tied to prompt difficulty and training phase (curriculum over α), targeting optimal CSR automatically.
- Products: AutoAlpha Calibrator services; “self-tuning efficiency” trainers.
- Dependencies: Robust online estimators; theory for stability guarantees under adaptive constraints.
- Inference-time halting integrated with training-time rescaling
- Sector: inference optimization, serving platforms.
- Use case: Combine GR3-trained policies with verifier-gated early stopping and adaptive max-length policies for further savings.
- Products: Early-exit controllers; dynamic token budget allocators per request.
- Dependencies: Fast verifiers; latency-aware serving frameworks; careful UX when answers are truncated early.
- Reward-model co-design for robustness to verbosity
- Sector: alignment research, model providers.
- Use case: Jointly train length-invariant reward models and GR3 policies to mitigate residual length bias and reward hacking.
- Products: “Bias-hardened” RM+policy stacks; certification tests for length invariance.
- Dependencies: High-quality preference data; diagnostics for residual length leakage; cross-domain transfer studies.
- Policy and standards: efficiency and “intelligence per token” metrics
- Sector: regulators, standards bodies, consortia.
- Use case: Encourage reporting and minimum thresholds for efficiency (tokens per task, tokens per correct) in model disclosures and procurement policies.
- Products: Benchmarks and leaderboards that incorporate Pareto efficiency; green-AI labels tied to measured token savings.
- Dependencies: Community consensus on metrics; third-party auditing; alignment with safety and transparency norms.
- Multi-agent communication efficiency
- Sector: orchestration frameworks, enterprise automation.
- Use case: Apply GR3 to minimize message length and rounds among collaborating agents without hurting task success.
- Products: Cost-aware agent frameworks with communication budgets and multiplicative gating.
- Dependencies: Reliable group stats over inter-agent messages; reward definitions that reflect team success.
- Safety-critical reasoning that is concise yet thorough
- Sector: healthcare, finance, legal.
- Use case: Train models to deliver high-precision, audit-friendly rationales that avoid unnecessary verbosity but preserve essential steps for verification.
- Products: “Clinically concise” or “audit-ready” reasoning modes with controllable budgets.
- Dependencies: Domain-specific verifiers/humans-in-the-loop; strict validation; conservative alpha settings to avoid over-compression risk.
- Green AI certification and carbon accounting integration
- Sector: ESG, sustainability tech.
- Use case: Tie GR3-derived token reductions to standardized carbon metrics; certify models that meet efficiency thresholds.
- Products: Carbon dashboards, third-party efficiency seals for AI services.
- Dependencies: Accepted accounting methodologies; regulator and customer buy-in.
Cross-cutting assumptions and dependencies
- Group sampling and on-policy statistics: GR3 relies on sampling groups per prompt to compute within-group reward and length statistics. Training infrastructure must support this.
- Reward signal quality: For RLHF, multiplicative rescaling mitigates but does not replace the need for well-calibrated reward models; for RLVR, high-quality verifiers are required.
- Calibration: The advantage-aware calibration (CSR-guided α selection) should be run early and monitored to prevent suppressing high-quality trajectories.
- Generalization: Reported gains are demonstrated on math, code, and chat; applying to new domains may require modest re-tuning and validation.
- Governance: Where safety or compliance mandates full reasoning traces, organizations should set conservative α or selectively disable length rescaling for critical prompts.
Glossary
- Advantage-aware calibration: A calibration procedure that tunes the strength of length penalties to preserve the learning signal (advantage) of high-quality trajectories. "Complementing this, we introduce advantage-aware calibration to explicitly control the penalty strength."
- Additive shaping: A reward-shaping approach that adds a length-related term to the reward, which can create compensatory shortcuts unrelated to task success. "A common design adopts additive shaping~\cite{yu2025dapo,team2025kimi}, modifying the objective with an explicit length term (e.g., )."
- Autoregressive policy: A policy that generates each token conditioned on the prompt and previously generated tokens. "an autoregressive policy generates a response"
- Constraint Satisfaction Rate (CSR): The fraction of training groups for which a chosen penalty parameter satisfies a predefined advantage-preservation constraint. "measure the Constraint Satisfaction Rate (CSR)"
- Group Relative Policy Optimization (GRPO): A group-based variant of PPO that uses within-group normalized rewards to compute advantages without a value model. "Group Relative Policy Optimization (GRPO) \cite{shao2024deepseekmath} is widely adopted due to its scalability and its elimination of the need for a separate value model."
- Group Relative Reward Rescaling (GR3): A multiplicative, group-relative length-control framework that mitigates length inflation without sacrificing performance. "Group Relative Reward Rescaling (GR$<sup>{3),</sup> which reframes length control as a multiplicative rescaling paradigm,"</li> <li><strong>Group-normalized advantages</strong>: Advantages computed by normalizing rewards within a sampled group of responses to the same prompt. "The policy is optimized using a PPO-style clipped objective over the group-normalized advantages:"</li> <li><strong>Group-relative regularization</strong>: Length regularization that scales penalties using on-policy, within-group statistics (e.g., average length) instead of fixed global thresholds. "we employ group-relative regularization, which normalizes length against on-policy statistics"</li> <li><strong>Heuristic gating</strong>: A rule-based mechanism that applies length penalties only under certain reward conditions (e.g., only when the trajectory is correct), often limited to binary rewards. "some works propose heuristic gating~\cite{cheng2025optimizinglengthcompressionlarge,arora2025training}, applying penalties only when $R = 1$."
- Importance sampling ratio: The ratio of current-policy to behavior-policy probabilities for each token, used to correct for off-policy sampling in policy gradients. "where the importance sampling ratio is defined as"
- Kullback–Leibler (KL) divergence: A regularization term that penalizes divergence between the current policy and a reference policy to stabilize learning. "-\beta D_{\mathrm{KL}(\pi_\theta\Vert \pi_{\mathrm{ref})"
- Length bias: A systematic preference in reward models or training that favors longer outputs irrespective of quality. "standard GRPO suffers from severe reward hacking under length bias"
- Length inflation: The tendency of RL-trained models to produce unnecessarily long responses, increasing cost without proportional quality gains. "we term length inflation: a tendency for RL-trained models to produce unnecessarily lengthy trajectories"
- Markov Decision Process (MDP): A formal framework modeling decision-making with states, actions, transitions, and rewards; here used at the token level. "LLM generation can be formulated as a token-level Markov Decision Process"
- Multiplicative reward rescaling: A reward-shaping approach that multiplies the task reward by a length-dependent factor, acting as a reward-aware gate. "a multiplicative rescaling paradigm"
- Off-policy bias: A mismatch or bias introduced when fixed thresholds or rules do not adapt to the current policy’s behavior. "a fixed threshold inevitably induces {off-policy bias}:"
- On-policy statistics: Statistics (e.g., mean length) computed from samples generated by the current or behavior policy, used for adaptive regularization. "normalizes length against on-policy statistics rather than rigid thresholds,"
- Pareto frontier: The set of models that represent optimal trade-offs between competing objectives, such as performance and efficiency. "shifting the efficiency–performance Pareto frontier."
- PPO-style clipped objective: An objective that clips the policy update via importance sampling ratios to prevent excessively large policy changes. "The policy is optimized using a PPO-style clipped objective"
- Reference-based sigmoid shaping: A shaping scheme that applies a sigmoid to the difference between a candidate’s reward and a reference response’s reward. "we apply a reference-based sigmoid shaping \cite{fu2025reward} scheme:"
- Reinforcement Learning from Human Feedback (RLHF): An RL paradigm that optimizes policies using rewards predicted by a learned human-preference model. "In RL from human feedback (RLHF)~\cite{ouyang2022training},"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm that uses rewards computed by ground-truth verifiers, rather than learned reward models. "In RL with verifiable rewards (RLVR)~\cite{shao2024deepseekmath},"
- Reward hacking: The exploitation of flaws or biases in the reward function to obtain high reward without genuine task improvement. "leading to reward hacking~\cite{gao2023scaling}"
- Reward model: A learned model that assigns scalar scores to model outputs as proxies for human preferences. "as the reward model."
- Reward shaping: The practice of modifying the reward function (e.g., with length penalties) to guide learning toward desired behaviors. "regularize response length through reward shaping."
- Sigmoid function: A smooth bounded activation function often used to squash scores into [0,1], here used in reward shaping. "s(\cdot) denotes the sigmoid function."
- Threshold-based truncation: A method that enforces a fixed maximum length, cutting off responses beyond a preset token budget. "We include the fixed-threshold truncation method~\cite{hou2025thinkprune} as a minimalist baseline."
- Within-group normalization: Normalizing rewards or lengths using statistics computed over a group of responses sampled for the same prompt. "constructs a group-relative advantage via within-group normalization:"
- Zero-sum structure: A property of group-normalized advantages where increases for some trajectories imply decreases for others within the same group. "Due to the zero-sum structure of group normalization,"
- Reward-dependent gating mechanism: A gating effect where the strength of length regularization scales with task reward, coupling efficiency to success. "establishing a generalized, continuous, and reward-dependent gating mechanism."
Collections
Sign up for free to add this paper to one or more collections.