- The paper introduces a method that leverages evaluation rollouts to train verifier functions, enabling inference-time steering without additional costly data collection.
- The methodology employs behavior cloning for initial policy training followed by verifier-guided action selection, resulting in up to a 49% improvement in task success rates.
- Experimental results on simulated and real-world robotic manipulation tasks demonstrate the efficiency and scalability of the approach compared to traditional methods.
Update-Free On-Policy Steering via Verifiers
Introduction
The paper "Update-Free On-Policy Steering via Verifiers" (2603.10282) proposes the Update-Free On-Policy Steering (UF-OPS) methodology to address the brittleness of Behavior Cloning (BC)-based policies, especially in the context of precise robotic manipulation. BC, despite being a widely adopted approach for training manipulation policies from human demonstrations, often fails due to imprecise actions at critical points. This research introduces a novel approach to improve a robot's policy by utilizing its evaluation data through verifier functions, enhancing policy execution without requiring additional costly data collections or fine-tuning.
Methodology
UF-OPS leverages the data generated during a policy's own evaluation, which includes both successes and failures, to train verifier functions. The verifier functions estimate the success likelihood of specific state-action pairs during policy rollouts, allowing for inference-time steering of base policies. This approach relies on a simple procedure:
- Training an Initial Policy: A base policy is initially trained using BC on a dataset of expert demonstrations.
- Policy Evaluation: The policy is evaluated to collect successful and failed rollouts.
- Verifier Function Training: A verifier function is trained on this dataset to score each state-action pair based on its likelihood of leading to task success.
- Inference-time Steering: The verifier guides the base policy in real-time by preferring actions with higher success scores during execution.
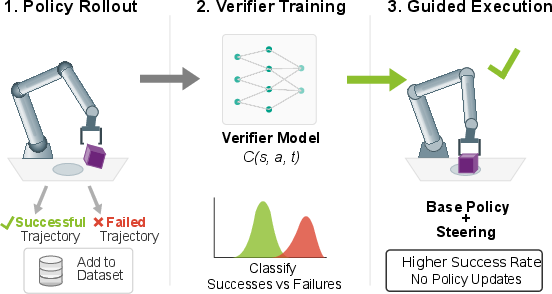
Figure 1: Our method relies on a policy's own evaluation data to improve its performance. Training small verifiers and subsequently, utilizing them via inference-time steering, allows for improved policy performance without costly data collections and resource extensive fine-tuning.
Experiments and Results
The methodology was tested across multiple domains, including simulated tasks from the robomimic task suite and real-world bi-arm manipulation tasks on the Aloha system, showcasing an average improvement of 49% in success rate over the base policy across five tasks. A specific focus was given to ensuring the method was applicable with only a small number of trajectories, reflecting a practical constraint in robotics.
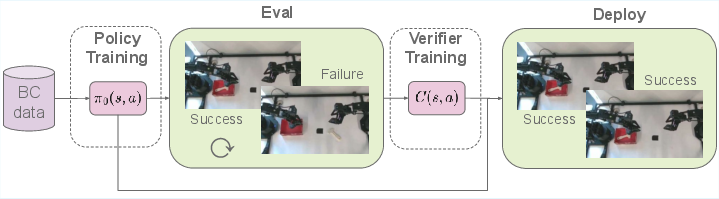
Figure 2: Method overview: Given a base policy trained on a dataset of expert demonstrations, policy evaluation provides successful and failed rollouts. These are used for training a verifier function that scores a transition (s,a) in terms of its success likelihood. Finally, the verifier function is used in combination with a steering strategy, to improve the policy performance.
In simulated environments, UF-OPS demonstrated a clear advantage over existing methods, partly due to its efficiency in utilizing a policy's own failure data—a less common but rich source of information. The implementation on real tasks repeated this success, achieving a significant increase in task completion rates. UF-OPS was able to achieve these improvements with minimal computational overhead, showcasing both its practical applicability and potential for widespread use.

Figure 3: Real tasks on the Aloha bimanual system.
Comparative Analysis
The work aligns with recent efforts targeting policy improvement strategies that do not necessitate updating the core policy weights. Comparisons were made with existing approaches such as SAILOR and DSRL, where UF-OPS demonstrated substantial performance benefits, particularly in smaller data regimes. Unlike methods focused on collecting additional data for fine-tuning, UF-OPS stands out by directly utilizing evaluation rollouts to steer policy actions, ensuring both computational efficiency and a reduction in data collection demands.
Conclusion
UF-OPS introduces an efficient, scalable approach to enhance robotic policies by directly leveraging evaluation rollouts rather than relying on additional demonstrations or intensive fine-tuning. The method's ability to significantly boost performance by steering base policies through computed verifier scores presents a clear advancement in the field of AI-driven robotic control. Future directions could explore multi-task policy applications or further refining verifier training to cater to even broader classes of robotics challenges.

