Improving Search Agent with One Line of Code
Abstract: Tool-based Agentic Reinforcement Learning (TARL) has emerged as a promising paradigm for training search agents to interact with external tools for a multi-turn information-seeking process autonomously. However, we identify a critical training instability that leads to catastrophic model collapse: Importance Sampling Distribution Drift(ISDD). In Group Relative Policy Optimization(GRPO), a widely adopted TARL algorithm, ISDD manifests as a precipitous decline in the importance sampling ratios, which nullifies gradient updates and triggers irreversible training failure. To address this, we propose \textbf{S}earch \textbf{A}gent \textbf{P}olicy \textbf{O}ptimization (\textbf{SAPO}), which stabilizes training via a conditional token-level KL constraint. Unlike hard clipping, which ignores distributional divergence, SAPO selectively penalizes the KL divergence between the current and old policies. Crucially, this penalty is applied only to positive tokens with low probabilities where the policy has shifted excessively, thereby preventing distribution drift while preserving gradient flow. Remarkably, SAPO requires only one-line code modification to standard GRPO, ensuring immediate deployability. Extensive experiments across seven QA benchmarks demonstrate that SAPO achieves \textbf{+10.6\% absolute improvement} (+31.5\% relative) over Search-R1, yielding consistent gains across varying model scales (1.5B, 14B) and families (Qwen, LLaMA).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about training “search agents” — AI models that can look things up online, think through several steps, and then answer questions. The authors found a common training problem that makes these agents suddenly stop learning well (a “collapse”), and they propose a tiny fix (just one line of code) that makes training much more stable and improves the agents’ accuracy on many question‑answering tasks.
The main questions the researchers asked
The study focuses on three simple questions:
- Why do search agents sometimes train well at first and then suddenly get worse or stop improving?
- What exactly goes wrong inside the training process when the model’s behavior drifts too far from its earlier behavior?
- Can we add a very small change to the training formula to keep learning stable and make results better?
How they tried to solve it (methods in everyday terms)
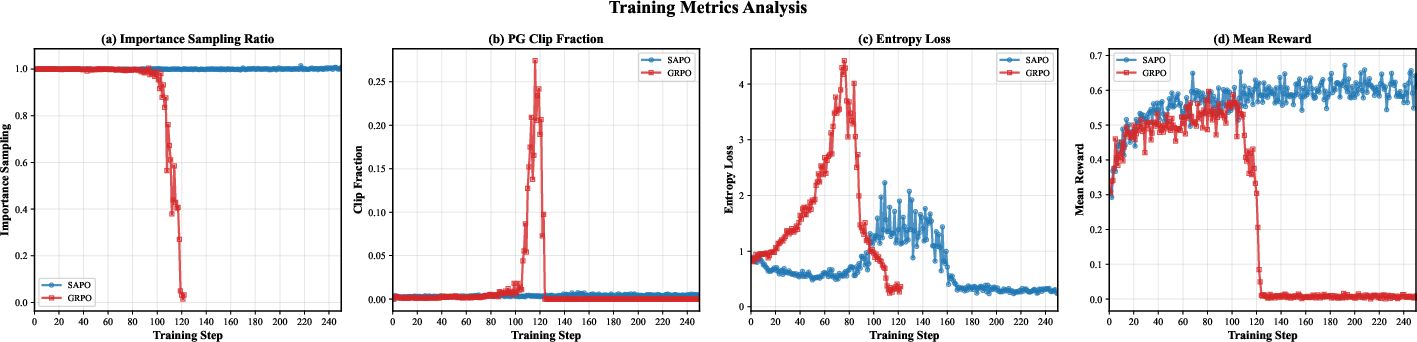
Think of training like coaching a team using last week’s plays. The coach compares what the players (the new model) do now with what they did before (the old model) and gives credit based on that. If the new plays are too different from the old ones, the coach’s scoring rule can accidentally give almost zero credit even to good moves — so the team stops learning from successes. This is the core problem the paper calls “Importance Sampling Distribution Drift” (ISDD).
A few key ideas, in plain language:
- What is GRPO? It’s a training method that scores a whole answer and then gives the same score to every word/token in that answer. That’s like giving every person the same grade in a group project, even if some parts were great and others were mistakes. This can confuse learning.
- What is ISDD? When the new model’s choices become too different from the old model’s choices, a “similarity weight” shrinks toward zero. Then the learning signal disappears — even for helpful steps — and training can crash.
- The paper’s fix (SAPO): Add a gentle, token‑level “stay-close” penalty only when it matters.
- Instead of harshly clipping updates (which cuts learning to zero for some tokens), SAPO softly nudges the model back toward its previous behavior.
- Crucially, it only nudges when:
- 1) the token was part of a “good” answer (it helped), and
- 2) the model is starting to make that good token very unlikely now.
- This protects helpful steps from being forgotten while still allowing exploration.
- Why “one line of code”? In practice, SAPO is implemented as a small, conditional KL penalty term added to the usual training loss. That’s a standard ingredient in many AI training setups, so it’s easy to drop in.
Analogy: Imagine lane-assist in a car. Hard clipping is like slamming the brakes every time you drift a bit — you stop moving. SAPO is like a gentle steering correction only when you drift out of your lane on important turns, keeping you safe without blocking progress.
What they found and why it matters
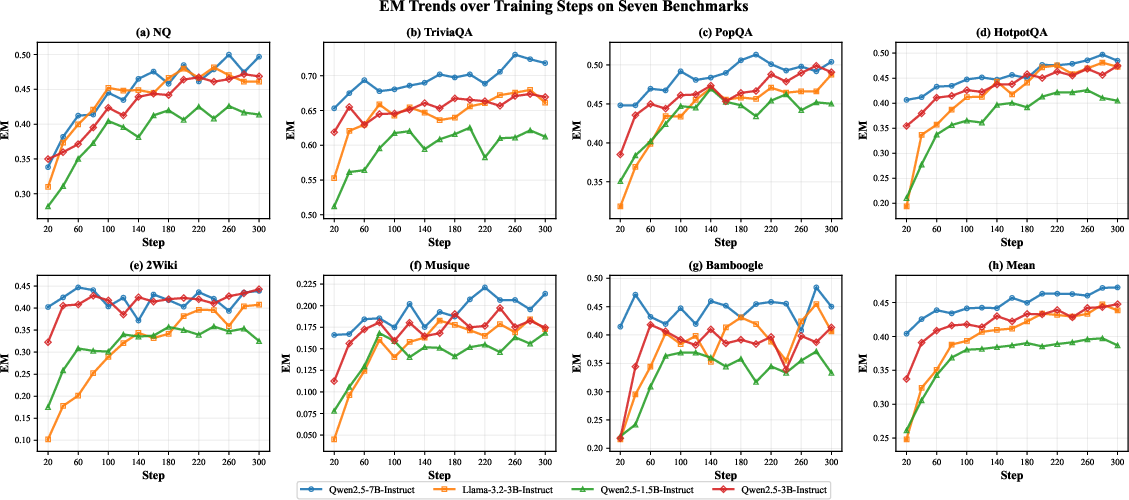
The authors tested SAPO on seven question‑answering benchmarks, including both simple look‑ups (single‑hop) and complex problems that need several steps of thinking and searching (multi‑hop). They used popular open models (like Qwen and LLaMA) of different sizes.
Main results:
- Big accuracy gains: On average, SAPO improved exact‑match accuracy by +10.6 percentage points over a strong baseline called Search‑R1 (about +31.5% relative improvement).
- Especially good on multi‑step problems: SAPO showed some of its largest boosts on tasks that require several rounds of searching and reasoning.
- More stable training: Measurements that track training health (like the “importance sampling ratio” and entropy) stayed in a healthy range with SAPO, instead of collapsing later in training.
- Works across models and sizes: The improvements held from small (1.5B) to larger (14B) models and across model families (Qwen, LLaMA), showing the idea is general.
Why this matters:
- More reliable search agents: Models that use tools (like search engines) can keep learning without “forgetting” helpful steps.
- Better performance with minimal effort: Because the change is tiny in code, it’s easy for teams to adopt and see immediate gains.
What this could mean going forward
- Smarter, steadier AI assistants: Systems that need multi‑turn reasoning (research assistants, fact‑checkers, study helpers) can become more dependable and accurate.
- A useful training pattern for tool‑using AI: The “only penalize when it hurts good behavior” idea could help other AI agents that rely on external tools, not just search.
- Faster progress in practice: Since it’s a small, plug‑and‑play change, many projects can try SAPO quickly, speeding up improvements in real‑world applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Missing theoretical guarantees and bias analysis
- No formal convergence guarantees or analysis of asymptotic optimality for SAPO under off-policy updates when the conditional KL penalty is applied only to tokens with and .
- Unquantified bias introduced by conditioning the penalty on group-level advantages (identical for all tokens in a response), which may misclassify token-specific contributions and distort gradients.
- Proposition assuming log-normality of importance ratios and stronger drift for action tokens is not proven or empirically validated; correlation and non-stationarity across timesteps are ignored.
- The “KL” penalty is implemented as a sampled log-ratio rather than a true distributional KL; the consequences of this approximation versus a full KL penalty are not studied.
- Non-differentiable gating and implementation ambiguity
- The gradient derivation includes indicator functions and a Dirac delta term; how this is implemented in practice (e.g., stop-gradients, soft gates) and its effect on stability and bias is not specified.
- The “one-line code” claim is not accompanied by a precise code-level description; reproducibility and exact integration into GRPO (e.g., where gating is applied, batching, mixed precision) are unclear.
- Token-level credit assignment remains unresolved
- Although the paper highlights that GRPO assigns identical advantages to all tokens, SAPO does not change advantage estimation; the efficacy of combining SAPO with token-level credit assignment (e.g., retrospective critics or per-step rewards) is untested.
- No analysis decomposes which token types (e.g., tool-call/action vs. reasoning tokens) trigger the penalty, despite the central claim that action tokens are the main failure mode.
- Limited exploration of hyperparameters and adaptivity
- Only narrow sensitivity for the ratio threshold is presented; no systematic study of the penalty coefficient , adaptive schedules (e.g., PPO-penalty–style annealing), or coupling with entropy regularization.
- No investigation of how group size , rollout count, and context length affect ISDD and SAPO’s stability.
- No early-warning detection framework for ISDD (e.g., thresholds on distributions, KL growth, or gradient norm collapse) is provided to guide practitioners.
- Incomplete baselines and comparative algorithmic analysis
- Lacks comparisons to trust-region or off-policy algorithms that directly address distribution shift (e.g., PPO-penalty/TRPO, V-trace, IMPALA, conservative policy iteration, or recent group-sequence optimizers like GSPO).
- No head-to-head tests with token-level penalty variants (e.g., symmetric KL, reverse KL, JS divergence) or dynamic penalty schemes (e.g., adaptively targeting action tokens).
- Does not compare against modern critic-based methods for fine-grained credit assignment beyond referencing external works.
- Evaluation scope and external validity limitations
- Training is restricted to NQ+Hotpot and evaluations are on seven QA benchmarks with a fixed retriever and Wikipedia corpus; generalization to open-web tasks (dynamic pages, latency, errors) and non-Wikipedia domains is untested.
- No experiments vary retrieval settings (retriever model, top-k, negative sampling, index freshness); the interaction between retriever quality and ISDD/SAPO is unexplored.
- Maximum turns and top-3 documents per query are fixed; SAPO’s behavior on longer-horizon interactions, deeper tool-use chains, or larger action spaces is unknown.
- Results lack statistical robustness reporting (multiple seeds, variance, confidence intervals); stability improvements could be confounded by run-to-run variance.
- Reward design and robustness gaps
- The rule-based outcome reward (F1) is sparse and noisy for multi-turn agents; robustness of SAPO to reward misspecification, delayed credit, or dense/token-level rewards is not studied.
- No experiments stress-test SAPO under reward noise or adversarial reward shaping to assess whether conditional penalties anchor the policy to suboptimal behavior when “positive” sequences are mislabeled.
- Exploration–exploitation trade-offs not quantified
- Conditional penalties may over-anchor to the old policy and suppress necessary exploration; the paper does not quantify exploration capacity (e.g., entropy trends after stabilization, novelty of actions) or adaptation under distribution shift.
- No ablation on how SAPO affects coverage/diversity of search queries, tool-call strategies, or trajectory variability.
- Diagnostics for ISDD remain coarse
- ISDD is defined via compounded but the paper provides no concrete operational thresholds (, ) or standardized diagnostics (e.g., drift scorecards) that practitioners can monitor.
- No distributional plots (e.g., per-token histograms, per-turn drift) or token-level failure analyses are provided to validate that SAPO targets the intended failure modes.
- Compute, efficiency, and scaling details are missing
- Sample efficiency, wall-clock training time, and compute cost versus GRPO are not reported; it is unclear whether gains stem from better optimization or incidental hyperparameter choices.
- Scaling analysis is briefly shown for Qwen models but lacks details on training budgets, stability at larger scales (e.g., ≥30B), and interactions with tokenizer/context window scaling.
- Safety, reliability, and downstream behavior unassessed
- The paper does not evaluate effects on hallucination rates, calibration, or evidence attribution quality—critical for information-seeking agents.
- No analysis of failure cases (e.g., harmful content retrieval, misleading sources) or how SAPO influences robustness to noisy/contradictory evidence.
- Generality beyond GRPO is unproven
- Although framed as a drop-in for GRPO, it is unclear how SAPO performs with other TARL pipelines (e.g., DPO-style objectives, supervised finetuning with tool traces, multi-agent settings, or memory-augmented agents).
- The claim of immediate deployability would benefit from results on varied agent frameworks and toolkits (e.g., web browsers, APIs, code executors).
- Reproducibility and artifacts
- The paper does not state code/data release, exact training scripts, or environment details; some equations appear malformed in the text, which can hinder precise replication.
- Dataset splits, filtering, and potential data contamination checks are not documented, which complicates fair benchmarking.
Practical Applications
Overview
This paper introduces SAPO (Search Agent Policy Optimization), a one-line modification to GRPO for tool-based agentic reinforcement learning. By adding a conditional, token-level KL penalty applied only to low-probability positive tokens, SAPO mitigates Importance Sampling Distribution Drift (ISDD), preventing training collapse and improving performance for multi-turn, retrieval-augmented search agents. Below are practical applications derived from the method, findings, and reported results.
Immediate Applications
These applications can be deployed now, leveraging existing GRPO-style training stacks with minimal engineering changes.
- Industry — Search/RAG agent training stabilization (Software/AI)
- Use case: Upgrade existing GRPO-based training pipelines (e.g., Search-R1-like agents) with SAPO to prevent collapse in long, multi-turn trajectories and increase EM/F1 on knowledge-intensive tasks.
- Sectors: Software, cloud AI platforms, MLOps.
- Tools/products/workflows:
- “SAPO Optimizer” as a drop-in option in RL libraries (e.g., TRL/HF, Ray RLlib, custom PPO/GRPO trainers).
- Training dashboards tracking IS ratio, clip ratio, entropy, and reward; alerts for ISDD risk.
- Recipe: retain old policy; compute group advantages; apply conditional KL with γ≈0.1 and τ≈1.0; keep standard tool masking and retrieval.
- Assumptions/dependencies: Access to the old policy during updates; GRPO-style advantage computation; a functioning retriever/vector store; sufficient compute for RL fine-tuning; curated rewards (e.g., F1-based, exact match).
- Enterprise knowledge assistants (Legal, Finance, Compliance, Healthcare)
- Use case: Fine-tune internal search agents on proprietary document repositories to answer multi-hop queries with citations (policies, contracts, clinical guidelines).
- Sectors: Legal, finance, healthcare, compliance.
- Tools/products/workflows:
- Domain-adapted RAG agents with SAPO-trained policies for complex policy lookup, e-discovery triage, and compliance checks.
- Workflow: Ingestion → retrieval (e.g., E5 embeddings) → SAPO-trained agent for multi-step search/planning → answer + evidence pack → human review queue.
- Assumptions/dependencies: Secure retrieval stack; PII/compliance controls; domain-specific reward proxies (e.g., exact citation matching); data access policies.
- Customer support copilots (CX)
- Use case: Multi-turn support agents that interleave clarifying questions and KB searches to resolve complex tickets with fewer escalations.
- Sectors: SaaS, telecom, consumer electronics.
- Tools/products/workflows:
- SAPO-enhanced training on historical tickets + KB; guardrails to handle tool failures; agent produces resolution plus article links.
- Assumptions/dependencies: High-quality, up-to-date KB; robust tool APIs; latency budgets; evaluation harness for resolution rates.
- Newsroom/OSINT and market intelligence (Media, Security, Sales)
- Use case: Investigative research agents that reliably stitch together facts from multiple sources with lower drift in long sessions.
- Sectors: Media, cybersecurity, GTM/sales ops.
- Tools/products/workflows:
- SAPO-trained agents integrated with web search/scrapers; deduplication and evidence bundling; stance/credibility scoring add-ons.
- Assumptions/dependencies: Web access and scraping policies; bias/credibility filters; source whitelists.
- Academic literature review assistants (Academia/Pharma)
- Use case: Agents that conduct multi-hop literature searches, extract key findings, and assemble structured summaries with citations.
- Sectors: Academia, biotech/pharma R&D.
- Tools/products/workflows:
- SAPO-trained agents over PubMed/semantic scholar indices; question decomposition; evidence aggregation; Zotero/Notion integration.
- Assumptions/dependencies: Access to bibliographic APIs; domain reward design (e.g., citation recall/precision); handling paywalled content.
- Developer productivity — code, API, and log search (Software Engineering)
- Use case: Agents that query codebases, issue trackers, and runbooks over multiple steps to propose fixes with relevant references.
- Sectors: Software, DevOps/SRE.
- Tools/products/workflows:
- SAPO-trained code-search agents; chain-of-retrieval across repos/issues/logs; output includes diffs and linked evidence.
- Assumptions/dependencies: Up-to-date code embeddings; repository permissions; CI test hooks for reward signals (e.g., “fix attempts compiled and tests passed”).
- Education/tutoring with sources (EdTech)
- Use case: Source-grounded tutors that interleave search with explanations to answer multi-step questions and cite materials.
- Sectors: Education, corporate L&D.
- Tools/products/workflows:
- SAPO-trained agents over curricula and OER; per-step evidence cards; formative assessment pipelines based on EM/F1 rewards.
- Assumptions/dependencies: Licensed content access; age-appropriate safety filters; assessments aligned to curricular goals.
- Security and threat intelligence triage (Cybersecurity)
- Use case: Multi-turn agents that gather indicators across intel feeds, vendor advisories, and CVE databases to produce actionables with references.
- Sectors: Cybersecurity, IT.
- Tools/products/workflows:
- SAPO agents coordinating across threat feeds; IOC consolidation; SOC ticket drafts with cited sources.
- Assumptions/dependencies: Real-time feeds; false-positive control; policy for sensitive data handling.
- MLOps/ModelOps guardrails for RL training
- Use case: Monitoring and controlling ISDD during RL fine-tuning to prevent collapse.
- Sectors: AI/ML platforms.
- Tools/products/workflows:
- “ISDD Sentinel” module watching IS ratios, clip ratios, entropy, reward; adaptive γ/τ schedulers; early-stop hooks; checkpoint rollbacks.
- Assumptions/dependencies: Telemetry from trainers; policy snapshotting; autoscaling; reproducible seeds and logs.
- Data generation/labeling acceleration (AI data ops)
- Use case: SAPO-trained agents generate harder multi-hop QA with evidence for training and evaluation datasets.
- Sectors: Data vendors, research labs.
- Tools/products/workflows:
- Synthetic multi-hop Q/A with supporting docs; automatic verification via EM/F1; human adjudication pipelines.
- Assumptions/dependencies: Verification tooling; anti-leakage controls; diversity sampling.
Long-Term Applications
These applications are promising but may require further research, scaling, domain adaptation, or additional safety/regulatory frameworks.
- Regulated-domain decision support (Healthcare, Finance, Legal)
- Use case: Evidence-tracing agents for clinical guideline synthesis, financial regulatory interpretation, or case law analysis with consistent multi-step provenance.
- Why long-term: Requires domain-specific rewards beyond EM/F1, rigorous validation, and regulatory oversight for deployment.
- Dependencies: High-precision retrieval; medically/legally verified reward shaping; robust audit trails; human-in-the-loop governance.
- Autonomous web agents for complex workflows (E-gov, Enterprise operations)
- Use case: Agents that navigate websites, fill forms, schedule appointments, and reconcile information across portals.
- Why long-term: Extending SAPO beyond QA to diverse tools (browsers, schedulers, forms) with long horizons and sparse rewards.
- Dependencies: Tool APIs and sandboxing; hierarchical rewards; robust action-space abstractions; safety constraints for transactions.
- Software engineering copilots that plan, search, execute, and verify (SE/DevOps)
- Use case: Multi-tool code agents that search, propose changes, run tests, inspect logs, and iterate with minimal drift across long sessions.
- Why long-term: Requires integration with execution rewards (tests, benchmarks), environment simulators, and secure tool use.
- Dependencies: Sandboxed execution; reliable signals (pass/fail metrics); repository-scale retrieval; secret management.
- Multi-agent research teams (Science/Innovation)
- Use case: Coordinated agent collectives that divide research tasks, cross-verify evidence, and merge findings with drift-aware training to prevent coordination collapse.
- Why long-term: Needs stable credit assignment across agents, communication protocols, and new group-level rewards.
- Dependencies: Multi-agent RL scaffolding; inter-agent KL/consensus penalties; conflict resolution mechanisms.
- Robotics and embodied tool use (Robotics, Manufacturing)
- Use case: Applying SAPO’s “recover low-probability positive actions” principle to long-horizon, sparse-reward control where occasional successful action sequences should not be forgotten.
- Why long-term: Requires bridging from language-token policies to continuous control and sensorimotor tokens; new reward designs and sim-to-real pipelines.
- Dependencies: High-fidelity simulators; safe exploration; tokenization of actions/states compatible with KL constraints.
- Safety/alignment improvements via drift-aware optimization (Cross-sector)
- Use case: Reduce hallucinations and mode collapse in long dialogs by penalizing divergence on verified-positive steps; combine with preference learning and citation verification.
- Why long-term: Needs unified frameworks combining SAPO-like penalties with RLHF/DPO, dynamic penalty schedules, and formal guarantees.
- Dependencies: Preference datasets; verifier models; curriculum schedules; safety audits.
- Cross-lingual and low-resource search agents (Global education and gov)
- Use case: Reliable multi-hop agents operating across languages and sparse corpora.
- Why long-term: Retrieval quality and tokenization issues; domain shift across languages; scarce evaluation signals.
- Dependencies: Multilingual retrievers; cross-lingual rewards; culturally-aware evaluation.
- Standards and policy for RL training stability (Public sector, Procurement)
- Use case: Auditable criteria for RL-based AI procurement, requiring monitoring of IS ratios, clipping, entropy, and drift penalties to ensure training robustness and reproducibility.
- Why long-term: Requires consensus among standards bodies, benchmarks beyond QA, and reporting templates.
- Dependencies: Shared metrics schemas; third-party audits; reproducible training artifacts.
- On-device or cost-constrained fine-tuning (Edge AI)
- Use case: Lightweight SAPO-like constraints for small models adapted to domain corpora with limited compute.
- Why long-term: Needs efficient approximations of old-policy storage, streaming KL estimates, and compact retrievers.
- Dependencies: Distillation strategies; memory-efficient policy snapshots; quantized retrievers.
Notes on feasibility and transfer
- Method readiness: SAPO is designed as a one-line change to GRPO’s objective and demonstrated on multiple backbones (Qwen, LLaMA) and QA benchmarks, indicating strong portability.
- Reward design: Many domains require moving beyond EM/F1 to domain-specific, verifiable reward signals (e.g., citation correctness, test pass rates, compliance rule hits).
- Retrieval quality: Gains depend on retriever coverage/precision (e.g., E5 or domain embeddings) and corpus freshness.
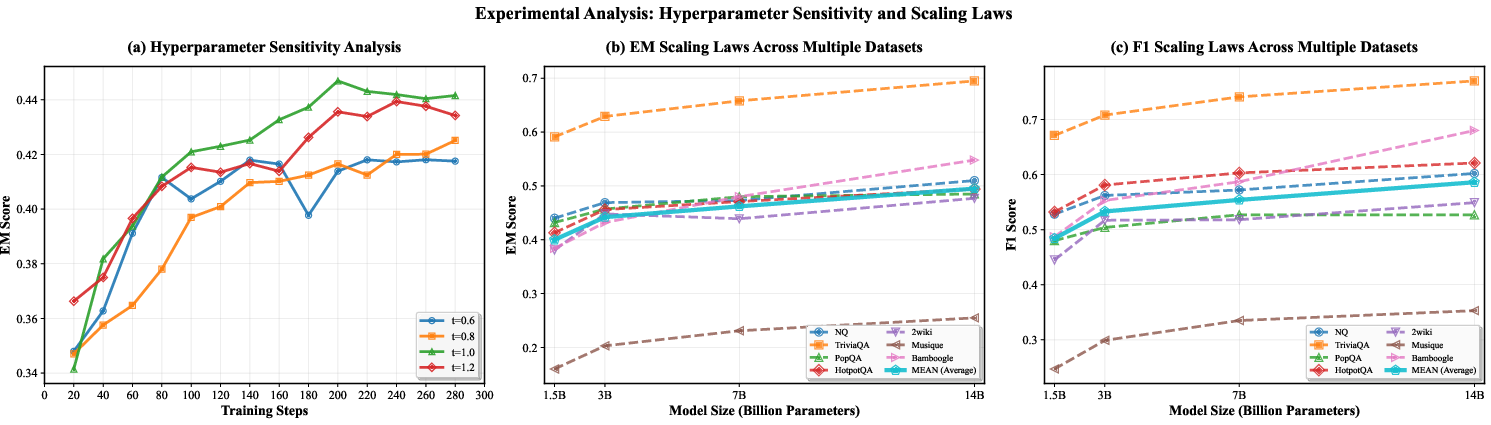
- Hyperparameters: Reported defaults (γ≈0.1, τ≈1.0) work well for QA; other tasks may require sensitivity tuning and adaptive schedules.
- Safety and governance: For high-stakes use, integrate human review, provenance tracking, and robust evaluation to mitigate residual errors and reward hacking.
Glossary
- Advantage function: A signal estimating how much better an action is than a baseline at a given timestep, used to weight policy gradients. "while represents the advantage function."
- Chain-of-Thought: A prompting/reasoning technique where models generate intermediate reasoning steps to improve final answers. "IRCoT \cite{trivedi2022ircot}, which interleaves retrieval with Chain-of-Thought;"
- Clip ratio: The proportion of tokens for which PPO’s clipping is activated during optimization, indicative of how often updates are constrained. "the clip ratio exhibits a pronounced spike in the latter stages."
- Clipped surrogate objective: PPO’s objective that clips the importance sampling ratio to limit policy updates and enforce a local trust region. "PPO introduces a clipped surrogate objective that imposes a local trust region:"
- Conditional KL penalty term: A KL-based regularizer that is applied only under certain conditions (e.g., positive advantage and excessive drift) to stabilize training without hindering exploration. "Following PPO_KL ~\cite{schulman2017ppo}, SAPO introduces a conditional KL penalty term to enforce a token-level constraint on the distributional divergence"
- Dirac delta function: A generalized function that is zero everywhere except at a single point, where it is infinite and integrates to one; appears when differentiating indicator functions. "where denotes the Dirac delta function, arising from the differentiation of ."
- Exact Match (EM) accuracy: An evaluation metric that measures whether the predicted answer matches the ground-truth answer exactly. "We employ Exact Match (EM) accuracy as the evaluation metric across all datasets."
- F1-score: The harmonic mean of precision and recall, often used to assess answer overlap with ground truth. "this is an outcome-oriented reward calculated using the F1-score between the predicted and ground-truth answers."
- Group Relative Policy Optimization (GRPO): A policy optimization method that removes the value critic by using group-based advantage estimation across multiple sampled responses. "Group Relative Policy Optimization (GRPO)~\cite{guo2025deepseekr1} eliminates the need for a value function critic by employing group-based advantage estimation."
- Hard clipping: A strict truncation of the importance sampling ratio in PPO-like methods that zeroes gradients beyond bounds, potentially ignoring useful signals. "Unlike hard clipping, which ignores distributional divergence,"
- Importance Sampling (IS) ratios: Ratios of action probabilities under current versus old policies, used to correct for off-policy data in policy gradient updates. "tracking the Importance Sampling (IS) ratios, clip ratio, entropy, and reward."
- Importance Sampling Distribution Drift (ISDD): A failure mode where the distribution shift causes IS ratios to collapse, leading to vanishing gradients and training instability. "we identify a critical training instability that leads to catastrophic model collapse: Importance Sampling Distribution Drift (ISDD)."
- Indicator function: A function that evaluates to 1 if a condition is true and 0 otherwise, used to gate penalties or terms. "Here, is the indicator function and is the threshold to identify drifting tokens."
- KL divergence: A measure of how one probability distribution differs from another, used to regularize policy updates. "SAPO selectively penalizes the KL divergence between the current and old policies."
- Log-normal distribution: A distribution of a random variable whose logarithm is normally distributed; used to model IS ratio behavior. "Let the IS ratios follow a log-normal distribution "
- Off-policy updates: Learning updates that use data collected from a different (older) policy than the one currently being optimized. "PPO facilitates stable training by utilizing IS for off-policy updates while constraining the deviation between the current and old policies."
- Policy entropy: A measure of randomness in a policy’s action distribution; higher entropy implies more exploration. "Similarly, policy entropy rises substantially at the beginning,"
- Policy gradient: A class of reinforcement learning methods that optimize policies by ascending the gradient of expected returns. "In GRPO, the policy gradient is weighted by IS ratios:"
- Proximal Policy Optimization (PPO): A robust policy gradient algorithm that uses clipping (or KL penalties) to constrain policy updates and improve stability. "Proximal Policy Optimization (PPO) ~\cite{schulman2017ppo} is one of the most prominent policy gradient methods in reinforcement learning (RL)"
- PPO_clip: The clipped variant of PPO that bounds the importance sampling ratio to limit overly large policy updates. "have adopted PPO_clip~\cite{schulman2017ppo} to restrict the deviation between current and old policies."
- PPO_KL: A PPO variant that uses an explicit KL penalty instead of (or in addition to) clipping to maintain a trust region. "Following PPO_KL ~\cite{schulman2017ppo}, SAPO introduces a conditional KL penalty term"
- Retrieval-Augmented Generation (RAG): A paradigm where external documents are retrieved and fed to a model to ground its generation in factual knowledge. "RAG systems enhance this process by retrieving knowledge from an external corpus "
- Scaling laws: Empirical relationships describing how model performance predictably improves with increases in scale (data, parameters, compute). "aligning with established scaling laws ~\cite{kaplan2020scalinglaw}."
- Sequence-level reward: A reward assigned to an entire generated sequence (response) rather than individual tokens or steps. "the advantage is computed by normalizing the sequence-level reward against the group statistics."
- Soft trust region constraint: A gentle constraint (often via KL penalties) that keeps the current policy near the reference policy while allowing adaptive updates. "Consequently, SAPO functions as a soft trust region constraint: instead of hard-clipping, we softly penalize large IS ratios,"
- Trust region: A neighborhood around a reference policy within which updates are permitted to maintain stability. "standard GRPO introduces Importance Sampling Distribution Drift (ISDD) when the policy shifts outside the trust region."
- Value function critic: The component that estimates value functions to reduce variance in policy gradients; some methods avoid it via alternative advantage estimation. "eliminates the need for a value function critic by employing group-based advantage estimation."
Collections
Sign up for free to add this paper to one or more collections.