More than the Sum: Panorama-Language Models for Adverse Omni-Scenes
Abstract: Existing vision-LLMs (VLMs) are tailored for pinhole imagery, stitching multiple narrow field-of-view inputs to piece together a complete omni-scene understanding. Yet, such multi-view perception overlooks the holistic spatial and contextual relationships that a single panorama inherently preserves. In this work, we introduce the Panorama-Language Modeling (PLM)paradigm, a unified $360\circ$ vision-language reasoning that is more than the sum of its pinhole counterparts. Besides, we present PanoVQA, a large-scale panoramic VQA dataset that involves adverse omni-scenes, enabling comprehensive reasoning under object occlusions and driving accidents. To establish a foundation for PLM, we develop a plug-and-play panoramic sparse attention module that allows existing pinhole-based VLMs to process equirectangular panoramas without retraining. Extensive experiments demonstrate that our PLM achieves superior robustness and holistic reasoning under challenging omni-scenes, yielding understanding greater than the sum of its narrow parts. Project page: https://github.com/InSAI-Lab/PanoVQA.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “More than the Sum: Panorama-LLMs for Adverse Omni-Scenes”
1. What is this paper about?
This paper is about teaching AI to understand full 360-degree images, like the kind you get from a camera on top of a car that sees all around it. The authors argue that looking at the whole scene in one panoramic picture helps the AI understand more than if it looked at several small, separate pictures. They build a new kind of model and a big dataset to test this idea, especially in hard driving situations like occlusions (things blocking your view) and accidents.
2. What questions did the researchers ask?
The authors focused on a few clear questions:
- Can an AI understand a whole 360-degree scene better than stitching together many normal, narrow photos?
- How can we help today’s vision-LLMs (AIs that read images and answer questions) handle panoramic images that are stretched and wrapped like a world map?
- Will a model that “sees everything at once” be more reliable in tricky driving scenes—like when objects are hidden, or during accidents?
3. How did they do it? (Methods explained simply)
The team did two main things: they built a new dataset and designed a new AI “attention” method.
First, the dataset:
- They created PanoVQA, a giant collection of 360-degree driving images paired with questions and answers (about 653,000 pairs).
- It includes three types of scenes:
- Normal driving (finding objects, where they are, and how they relate to the car).
- Occlusions (thinking about objects that are partly hidden and what might happen next).
- Accidents (judging risk, severity, how to avoid danger, and conditions like weather).
- They stitched multi-camera images into a single 360-degree “equirectangular” panorama, which is like flattening a globe into a map. This can stretch things at the top and bottom, just like how Greenland looks huge on some world maps.
- They used a mix of automatic tools and human checks to write and clean questions. They also stored simple, useful facts about each object (like its type, direction, distance, and visibility) so questions could be precise.
Second, the model:
- They propose a Panorama-LLM (PLM) that plugs into existing vision-LLMs so they don’t have to be rebuilt from scratch.
- The core idea is a new attention mechanism called Panoramic Sparse Attention (PSA).
- Think of attention like a flashlight that decides which parts of the image to focus on.
- “Sparse” means the flashlight doesn’t shine everywhere at once—it picks the most important spots to look at, saving time and energy.
- The model uses two “ways of looking” at the image:
- Sliding Window Attention (local): like reading the scene block by block to catch small details nearby.
- Panoramic Sparse Attention (global): like quickly jumping to the most relevant distant spots (front and back, left and right), so the model understands the full 360-degree context, including the wrap-around edges.
- This combo helps the AI handle panoramic distortions and long-distance relationships in the scene while staying efficient.
4. What did they find, and why does it matter?
Key results:
- The panorama approach beats the multi-camera approach. In tests, a single 360-degree image gave better answers than using six separate camera views. The full context helps the AI know, for example, where a van is relative to the car (like “front-left”) without getting confused.
- Their PLM with Panoramic Sparse Attention outperformed many popular vision-LLMs on their new PanoVQA benchmark across normal, occluded, and accident scenarios.
- The new attention method was both effective and efficient: by focusing on the most important parts of the image, the model learned better without wasting computation.
Why it matters:
- In driving, missing a small detail or mixing up left and right can be dangerous. A model that truly “sees the whole scene” can spot risks earlier and reason more like a careful human driver.
- Stronger performance under occlusions and accidents suggests better reliability in the real world, not just in easy cases.
5. Why is this important for the future?
- Safer autonomy: Self-driving cars and delivery robots can make better decisions if they understand the entire surroundings at once.
- Better tools for AR/VR and robotics: 360-degree understanding improves immersive experiences and helps robots navigate complex spaces.
- A reusable add-on: The attention module can be attached to many existing AI models, helping them handle panoramas without starting all over.
- A community resource: The PanoVQA dataset gives researchers a common, challenging testbed to push progress in real-world scene understanding.
In short, the paper shows that “seeing everything together” gives AI a clearer, safer, and smarter understanding of the world—especially when things get messy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address:
- Plug-and-play claim vs. practice: The paper claims the PSA module enables existing VLMs to process panoramas “without retraining,” yet all reported gains come from full-parameter supervised fine-tuning on Qwen2.5-VL. It remains untested whether PSA can be inserted into diverse VLMs for true zero-shot panoramic use (no tuning), or with minimal adaptation (e.g., adapter-only or vision-only fine-tuning).
- Limited baseline coverage: Comparisons omit strong panoramic/spherical alternatives (e.g., SphereNet/PanoFormer-style spherical transformers, cube-map pipelines, multi-projection fusion) and BEV-reasoning VLMs/agents (e.g., ChatBEV). A fair benchmark should include these to disentangle projection vs. attention design advantages.
- ERP wrap-around handling: The method does not explicitly implement circular padding/windowing or spherical positional encodings to respect left–right seam continuity in equirectangular projection. It is unclear how much PSA implicitly learns wrap-around and whether explicit periodic encodings would improve performance.
- Positional encodings on the sphere: The gate uses learnable position embeddings without geodesic awareness. The benefit of spherical/geodesic positional encodings (vs. ERP pixel coordinates) and rotary embeddings adapted to periodic ERP remains unexplored.
- Projection alternatives: No study contrasts ERP with cube-map, equal-area, or learned projections. Whether PSA’s gains persist or improve under different panoramic projections is unknown.
- Top-K sparse attention scaling: The Top-K is fixed (e.g., K=512) without analysis of how K should scale with input resolution/token count or how sensitive performance is to K under varying scene complexities.
- Latency and memory: The paper reports parameter counts but provides no wall-clock latency, throughput, or peak memory usage on high-resolution panoramas. Practical deployability and efficiency trade-offs vs. dense attention or other sparse schemes remain unquantified.
- Comparison to other sparse attention designs: There is no direct comparison to established sparse mechanisms (e.g., Longformer, BigBird, deformable attention variants). It’s unclear whether PSA’s gating and selection outperform or complement these alternatives on panoramas.
- Ablations on hybrid design: The specific contributions of SWA vs. PSA vs. their parallel combination (PHA) are only partially ablated. A systematic ablation isolating each component and their interactions across tasks and image resolutions is missing.
- Edge-seam sensitivity: Objects crossing ERP seams pose unique challenges. The paper does not measure error rates for seam-adjacent objects or evaluate boundary-aware enhancements (e.g., window wrap-around).
- Dataset stitching artifacts: The “first hit wins” panoramic stitching for multi-camera datasets ignores seam blending, parallax, time offset between cameras, and exposure/color differences. The impact of these artifacts on VQA performance and failure modes is unmeasured.
- Occlusion annotation heuristic reliability: Occlusion ordering is derived via 2D polygon overlaps and y-coordinate heuristics, which can be unreliable under ERP distortion and perspective effects. There is no validation against 3D ground truth to quantify occlusion label noise.
- Depth/distance estimation quality: Distances for occlusion tasks depend on a monocular depth model (DA2). The accuracy of these distances (especially near ERP poles or with heavy distortion) and their effect on QA correctness are not evaluated.
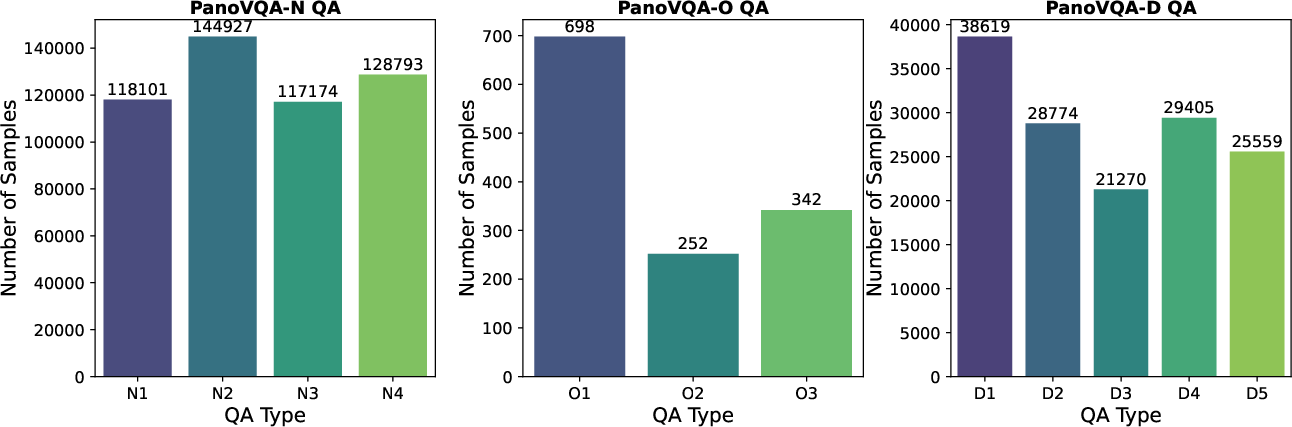
- Category imbalance and limited occlusion data: PanoVQA-O has very few samples (e.g., O1: 698; O2: 252; O3: 342), leading to severe imbalance across categories. The impact of this skew on learning and generalization to occlusion reasoning is unknown.
- Temporal reasoning gap: Risk and time-to-collision tasks are framed from a single image, with speed/distance injected into the question text due to lack of temporal cues. This sidesteps true visual motion reasoning. Extending PLM to panoramic video and learning speeds/TTC from frames is an open direction.
- Safety-critical validity of answers: Tasks like “Action Avoidance” and “Severity Assessment” rely on LLM-generated ground truths and LLM-as-judge scores without validation against traffic rules, expert annotations, or standardized protocols. Clinical/safety validity is unverified.
- LLM-as-judge reliability: All benchmarks use a proprietary judge (gpt-4o-mini). There is no correlation study with human raters, inter-rater agreement, or sensitivity analysis to verbosity/bias. Reproducibility across judges/models remains uncertain.
- Statistical significance and variance: Reported gains (e.g., 1-Pano vs. 6-Cam) are small and lack confidence intervals, multiple seeds, or significance tests. The robustness of conclusions is unclear.
- Generalization across domains: The model is evaluated only on driving panoramas (largely NuScenes/BlendPASS/DeepAccident). Cross-domain tests (e.g., different cities, adverse weather/night, VR/AR indoor panoramas, WildPASS/mmWalk) are absent.
- Catastrophic forgetting: Panoramic fine-tuning could degrade performance on standard pinhole VQA or general vision-language tasks. The paper does not test retention of prior capabilities.
- Pretraining for panoramas: The vision backbone is not pre-trained on panoramic data. The gains from panoramic pretraining (contrastive/captioning) vs. only SFT remain unexplored.
- Multi-sensor integration: Real autonomous systems use LiDAR/radar. Whether adding multi-modal inputs improves occlusion and accident reasoning in PLM is untested.
- Language and multilinguality: The dataset and evaluations appear English-only. How PLM performs in multilingual settings or with code-switching in safety-critical contexts is unaddressed.
- Resolution and token budget limits: Panoramas can be extremely high-resolution. The paper does not examine how performance scales with image size, whether token pruning/merging helps, or how PSA behaves under memory-constrained settings.
- Reproducibility of QA generation: QA pairs are produced with “GPT-5-mini” (non-public/ambiguous). Full prompts, generation settings, and a public replication pathway are needed to ensure dataset reproducibility.
- Benchmark breadth and fairness: The evaluation omits planning-centric or map-centric VLM agents and omits ablations that control for question leakage (e.g., when speeds/distances are supplied in the prompt). A more rigorous, partitioned benchmark design is needed.
- Ethical and privacy considerations: Accident imagery may include sensitive content and identifiable individuals. The paper does not discuss de-identification, consent, or usage restrictions for deployment and dataset sharing.
Practical Applications
Immediate Applications
The following opportunities can be deployed now by leveraging the paper’s plug-and-play panoramic sparse attention (PSA), the PanoVQA dataset, and the panorama-language modeling (PLM) workflow with existing VLMs.
- Automotive (driver analytics, dashcams)
- Use case: Upgrade existing dashcam/telematics analytics to understand 360° video with natural-language querying and reporting (e.g., “Is there a van approaching from front-left?”), including occlusion-aware descriptions and risk narratives.
- Tools/products/workflows: PSA module integrated into current VLM-based pipelines; ERP (equirectangular) pre-processing pipeline; “360 Dashcam Copilot” that summarizes trips and flags risks.
- Assumptions/dependencies: 360° camera availability; speed/distance cues either from CAN bus/GNSS or a motion estimator (paper’s D-tasks sometimes provide speed in the question); edge/cloud compute; human-in-the-loop for safety-critical outputs.
- Autonomous driving R&D (perception and reasoning)
- Use case: Benchmark and fine-tune driving VLMs for omni-scene reasoning under normal, occlusion, and accident conditions using PanoVQA; stress-test models on wrap-around and long-range dependencies.
- Tools/products/workflows: PanoVQA-based evaluation suites; internal model selection gates; curriculum learning on occlusion/accident subsets; PSA-enabled base VLMs (e.g., Qwen-VL, LLaVA).
- Assumptions/dependencies: Dataset license/compliance; domain gap handling (geography, sensors); reproducible stitching or native ERP inputs.
- Fleet operations and tele-operations
- Use case: “Query-the-scene” interfaces for remote operators to get instant situational summaries across 360° feeds (e.g., “Who is about to enter from the right?”).
- Tools/products/workflows: Web console integrating PLM; prioritized event summarization and spatial localization (N- and O-tasks).
- Assumptions/dependencies: Sufficient uplink bandwidth; latency constraints; operator training.
- Insurance and claims triage
- Use case: Post-incident summarization from 360° dashcam footage—describe environment/weather, relative directions, and plausible actions to avoid accidents (D1–D4 tasks).
- Tools/products/workflows: Claim intake assistant that auto-drafts incident narratives and extracts structured facts (category, direction, distance, visibility).
- Assumptions/dependencies: Legal admissibility and audit trails; human verification; clear disclaimers on model uncertainty; privacy compliance.
- Public safety and smart intersections
- Use case: Natural-language analytics of 360° intersection cameras to detect near-misses, occlusion-heavy risks, and multi-agent interactions.
- Tools/products/workflows: PSA-enhanced VLM nodes in VMS (video management systems); dashboards with query and alert capabilities.
- Assumptions/dependencies: Camera calibration and placement; privacy-by-design; municipal approvals; compute budgets.
- Mobile robotics (security/inspection/warehouse)
- Use case: 360° scene narration and hazard warnings for robots that rely on panoramic cameras; better left-right/back-front reasoning and occlusion awareness.
- Tools/products/workflows: PSA-equipped perception module; voice or text “explain-what-I-see” overlays for telepresence; object-to-object and ego-to-object spatial queries (N3/N4).
- Assumptions/dependencies: Multi-sensor fusion (depth, odometry) to stabilize distance/speed estimates; latency and power constraints for on-board compute.
- AR/VR content pipelines
- Use case: Auto-captioning and Q&A for 360° media (tours, training videos), including direction-aware descriptions and scene-wide context.
- Tools/products/workflows: Offline PLM batch captioning for ERP content; creator tools that add spatially grounded narration.
- Assumptions/dependencies: Tolerance for offline processing; scope limited to exteriors (dataset bias toward driving scenes).
- Accessibility (pilot deployments)
- Use case: Assistive narration for 360° outdoor scenes (e.g., campus shuttle environments), highlighting directions, obstacles, and actions to avoid.
- Tools/products/workflows: Mobile app that streams 360° frames to cloud PLM and returns spatially grounded, concise audio.
- Assumptions/dependencies: Safety guardrails; restricted deployments where traffic complexity and liability can be managed; careful UX design.
- Mapping and asset inventory
- Use case: Query 360° street-level imagery for asset detection and localization (signage, poles) with language interfaces and direction cues.
- Tools/products/workflows: Back-office PLM-assisted QA for map updates; structured outputs using the quadruple (category, direction, distance, visibility).
- Assumptions/dependencies: Geotagging and calibration; domain adaptation for new geographies.
- Software/ML tooling
- Use case: Add 360° capability to existing VLM products without full retraining using PSA; evaluate new models with PanoVQA; adopt the panoramic stitching pipeline.
- Tools/products/workflows: PSA layer drop-in; ERP-aware tokenization; PanoVQA-based CI benches; sparse-attention hyperparameter templates (Top-K, bottleneck dims).
- Assumptions/dependencies: Base VLM compatibility; GPU kernels optimized for sparse attention; open-source license alignment.
Long-Term Applications
The following opportunities require further research, scaling, domain adaptation, real-time optimization, or regulatory approval.
- Advanced driver assistance (L2+/L3) and in-vehicle copilots
- Use case: Real-time 360° reasoning that proactively warns about occluded hazards, predicts collision risks and time-to-collision, and suggests avoidance actions.
- Tools/products/workflows: On-vehicle PLM with PSA, fused with radar/LiDAR and vehicle CAN; HMI that surfaces concise and reliable alerts.
- Assumptions/dependencies: Functional safety certification; rigorous failure mode analysis; low-latency on-device inference; robust speed/distance estimation beyond static cues.
- Autonomous driving planning integration
- Use case: PLM-derived scene reasoning feeding into planners and prediction stacks, particularly for wrap-around contexts and occlusions.
- Tools/products/workflows: Hybrid BEV + PLM architectures; PHA (SWA+PSA) extended to temporal sequences; closed-loop evals.
- Assumptions/dependencies: Tight multi-sensor fusion; large-scale temporal 360° datasets; interpretability and verifiability in safety-critical loops.
- Regulatory benchmarks and policy tooling
- Use case: PanoVQA-style regulatory tests for omni-scene perception; standardized evaluation of occlusion and accident reasoning for vehicle certification or municipal camera deployments.
- Tools/products/workflows: Public test suites, scoring protocols beyond LLM-as-a-judge (ground truth/human panels), audit logs.
- Assumptions/dependencies: Cross-industry and regulator consensus; reproducible conditions; fairness/privacy considerations.
- City-scale “queryable” 360° camera networks
- Use case: Natural-language analytics for traffic flow, incidents, and near-misses across city-wide 360° deployments.
- Tools/products/workflows: Edge PLM nodes with privacy filters; federated analytics; operator dashboards with spatiotemporal search.
- Assumptions/dependencies: Governance, privacy-preserving compute (on-edge redaction); scalable sparse-attention acceleration; funding.
- Automated insurance adjudication and reconstruction
- Use case: Evidence-based liability assessment from 360° footage, with standardized severity and risk scoring.
- Tools/products/workflows: Claims adjudication engines integrating PLM outputs with telematics; standardized incident schemas.
- Assumptions/dependencies: Legal acceptance of AI-generated narratives; robust anti-fraud measures; consensus on scoring criteria.
- General-purpose 360° embodied agents (indoor and outdoor)
- Use case: Service robots with holistic scene understanding in warehouses, hospitals, and campuses, handling occlusions and long-range dependencies.
- Tools/products/workflows: Domain-adapted PLM trained on indoor 360° datasets; closed-loop navigation and manipulation policies guided by language.
- Assumptions/dependencies: New datasets for indoor omni-scenes; cross-modal grounding with depth/SLAM; safety validation.
- Wearable AR for cyclists and micromobility
- Use case: Multi-camera rigs synthesizing a 360° view for heads-up warnings about vehicles from blind spots and occluded cross-traffic.
- Tools/products/workflows: Low-power PLM variants with PSA; on-device accelerators; predictive alerts tied to user intent.
- Assumptions/dependencies: Lightweight sparse-attention kernels; battery constraints; acceptable false-positive/false-negative trade-offs.
- Cross-modal, multi-frame 360° reasoning
- Use case: Robust risk and intent estimation via PSA fused with temporal memory, GPS/IMU, and other sensors.
- Tools/products/workflows: PHA extended to streaming inputs; memory-efficient sparse attention across time; self-supervised pretraining.
- Assumptions/dependencies: Long-horizon datasets; efficient temporal kernels; careful handling of drift and wrap-around.
- Simulation-to-real training pipelines
- Use case: Scale training for rare, adverse 360° events using synthetic omni-scenes; transfer to real-world deployments.
- Tools/products/workflows: Domain adaptation frameworks; procedural generation of occlusions/accidents; counterfactual augmentation.
- Assumptions/dependencies: Bridging sim-to-real gaps; labeling and validation at scale; bias control.
- Retail/enterprise 360° surveillance analytics
- Use case: Ceiling-mounted fisheye/ERP feeds with occlusion-aware reasoning for loss prevention and safety monitoring.
- Tools/products/workflows: Privacy-preserving PLM deployed on-prem; natural-language querying for incident forensics.
- Assumptions/dependencies: High precision requirements; acceptable miss/false rates; worker privacy safeguards.
- Disaster response and inspection with 360° drones
- Use case: Rapid 360° situational assessment (collapsed structures, blocked roads), with language-based triage and direction-aware instructions.
- Tools/products/workflows: Drone payloads streaming ERP to edge/cloud PLM; mission-control interfaces with query capability.
- Assumptions/dependencies: Regulatory approvals; robust connectivity; adversarial weather and low-light robustness.
- Hardware and systems acceleration
- Use case: Specialized kernels and accelerators for Top-K sparse attention and panoramic token layouts to achieve real-time performance.
- Tools/products/workflows: CUDA/Triton kernels for PSA; hardware IP for sparse ops; model compression/distillation for PLM.
- Assumptions/dependencies: Vendor support; maintenance of accuracy under compression; standardization of panoramic tokenization.
Notes on feasibility and risks (cross-cutting)
- Domain shift: PanoVQA focuses on driving scenes; indoor/retail/industrial deployments will need additional domain-specific data and tuning.
- Sensor dependencies: Certain reasoning tasks (e.g., speed, precise distance, time-to-collision) need fused signals (radar/LiDAR/CAN/IMU) for reliability.
- Evaluation: The paper’s GPT-as-a-judge metric is useful for benchmarking but insufficient for safety-critical validation; human/ground-truth evaluation is necessary.
- Safety and liability: For any real-time, safety-relevant use (automotive, public safety, robotics), human oversight and rigorous certification are required.
- Privacy and governance: City-scale and enterprise surveillance applications must implement privacy-first design and comply with local regulations.
Glossary
- Bird's-Eye-View (BEV): A top-down planar representation of the scene commonly used in autonomous driving perception and mapping. "A parallel track, dominant in autonomous driving, projects sensor data into a Bird's-Eye-View (BEV)."
- counterfactual trajectory reasoning: Planning or reasoning by imagining alternative, hypothetical motion paths to evaluate decisions or outcomes. "use counterfactual trajectory reasoning,"
- deformable attention: An attention mechanism that adaptively samples from spatially flexible locations to handle distortions and object deformations. "PSA utilizes patch-wise deformable attention and gating mechanisms to effectively handle the object distortion and filter out uninformative areas inherent in panoramic images."
- equirectangular projection (ERP): A spherical-to-2D mapping used for panoramas that introduces characteristic distortions near the poles. "In the context of panoramic scenes, a primary challenge is the severe geometric distortion in ERP."
- gating mechanism: A learned control function that modulates or filters attention connections based on content and position. "which enhances SSA by using a dynamic gate network."
- Graph VQA: A visual question answering formulation that represents entities and their relations as a graph to support structured reasoning. "DriveLM introduced Graph VQA to model driver reasoning."
- Intersection over Union (IoU): A metric measuring the overlap between two regions, often used for visibility or detection evaluation. "based on the Intersection over Union (IoU) region."
- lift-splat: A BEV projection method that lifts image features into 3D space and then splats them onto the bird’s-eye plane. "LSS introduced the 'lift-splat' method for this projection."
- LLM as-a-judge: An evaluation paradigm where a LLM scores or validates model outputs against ground truth. "following LLM as-a-judge paradigm"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that injects low-rank updates into pretrained weights. "using LoRA"
- Mamba-based state space model: A sequence modeling approach using the Mamba architecture to capture long-range dependencies via state-space formulations. "using a Mamba-based state space model."
- Multi-Head Self-Attention (MSA): A Transformer mechanism that computes attention across multiple heads to capture diverse relationships among tokens. "Each Transformer block contains a Multi-Head Self-Attention (MSA) and a Feed-Forward Network (FFN)."
- non-causal score matrix: A selection matrix computed without respecting temporal order, allowing each token to consider all others for attention. "a non-causal score matrix"
- Panoramic Hybrid Attention (PHA): A combined attention design that runs local sliding-window and global sparse attention in parallel for panoramas. "We define Panoramic Hybrid Attention (PHA) as the parallel combination of SWA and PSA."
- Panoramic Sparse Attention (PSA): A dynamic sparse attention mechanism that selects Top-K relevant tokens globally to model long-range panoramic dependencies efficiently. "The global head is implemented by Panoramic Sparse Attention (PSA)"
- pinhole imagery: Standard narrow field-of-view camera images modeled by a pinhole camera; typical in conventional vision datasets and models. "Existing vision-LLMs (VLMs) are tailored for pinhole imagery"
- plug-and-play (module): A component designed to be inserted into existing systems with minimal changes or retraining. "we develop a plug-and-play panoramic sparse attention module"
- Scaling laws: Empirical relationships describing how model performance scales with factors like data size or parameter count. "supported by established research on scaling laws"
- Simplified Sparse Attention (SSA): A fixed-pattern sparse attention variant that reduces computational cost at the risk of missing important connections. "While Simplified Sparse Attention (SSA) has proposed to reduce cost"
- Sliding Window Attention (SWA): Local attention computed within fixed windows to reduce quadratic complexity by limiting token interactions. "The local head is implemented using Sliding Window Attention (SWA)"
- spatiotemporal transformers: Transformer architectures that jointly model spatial and temporal dependencies for video or sequential perception tasks. "BEVFormer advanced this with spatiotemporal transformers"
- supervised fine-tuning (SFT): Training a pretrained model on labeled data by updating weights using task-specific supervision. "conduct full-parameter supervised fine-tuning (SFT)"
- Top-K (selection): Selecting the K most relevant items (e.g., keys for attention) based on a scoring criterion to enforce sparsity. "we identify the set of Top-K key indices"
- Vision-LLM (VLM): A model that integrates visual and textual modalities to perform tasks like VQA, captioning, and reasoning. "Existing vision-LLMs (VLMs) are tailored for pinhole imagery"
- Vision Transformer (ViT): A Transformer-based vision model that operates on image patches as tokens. "The original Vision Transformer (ViT) processes an image by first dividing it into a sequence of non-overlapping, fixed-size patches."
- wrap-around (nature of panoramas): The property that the left and right edges of a 360° panorama are contiguous, forming a continuous field of view. "the crucial 'wrap-around' nature of panoramas"
Collections
Sign up for free to add this paper to one or more collections.

