DA$^2$: Depth Anything in Any Direction
Abstract: Panorama has a full FoV (360$\circ\times$180$\circ$), offering a more complete visual description than perspective images. Thanks to this characteristic, panoramic depth estimation is gaining increasing traction in 3D vision. However, due to the scarcity of panoramic data, previous methods are often restricted to in-domain settings, leading to poor zero-shot generalization. Furthermore, due to the spherical distortions inherent in panoramas, many approaches rely on perspective splitting (e.g., cubemaps), which leads to suboptimal efficiency. To address these challenges, we propose $\textbf{DA}$${\textbf{2}}$: $\textbf{D}$epth $\textbf{A}$nything in $\textbf{A}$ny $\textbf{D}$irection, an accurate, zero-shot generalizable, and fully end-to-end panoramic depth estimator. Specifically, for scaling up panoramic data, we introduce a data curation engine for generating high-quality panoramic depth data from perspective, and create $\sim$543K panoramic RGB-depth pairs, bringing the total to $\sim$607K. To further mitigate the spherical distortions, we present SphereViT, which explicitly leverages spherical coordinates to enforce the spherical geometric consistency in panoramic image features, yielding improved performance. A comprehensive benchmark on multiple datasets clearly demonstrates DA${2}$'s SoTA performance, with an average 38% improvement on AbsRel over the strongest zero-shot baseline. Surprisingly, DA${2}$ even outperforms prior in-domain methods, highlighting its superior zero-shot generalization. Moreover, as an end-to-end solution, DA${2}$ exhibits much higher efficiency over fusion-based approaches. Both the code and the curated panoramic data will be released. Project page: https://depth-any-in-any-dir.github.io/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DA² (Depth Anything in Any Direction), a computer system that can look at a single 360-degree photo and figure out how far away every part of the scene is. Think of it like giving a virtual reality panorama the missing 3D information it needs. DA² is designed to work well even on new, unseen scenes (“zero-shot”), and it runs end-to-end, meaning it doesn’t rely on slow, complicated steps or splitting the image into multiple parts.
Key Objectives
Here are the main goals of the research, described in simple terms:
- Build a fast and accurate tool that can estimate distance everywhere in a full 360-degree picture.
- Make it work well on many different types of scenes without retraining on each new dataset (strong “zero-shot” generalization).
- Solve the problem of curved, stretched shapes in 360 images (like how world maps distort the poles) so the 3D results look right.
- Create a large, high-quality training set for 360-degree images by transforming regular photos into panoramas.
How They Did It
The team combined two big ideas: a smart way to create training data and a sphere-aware neural network.
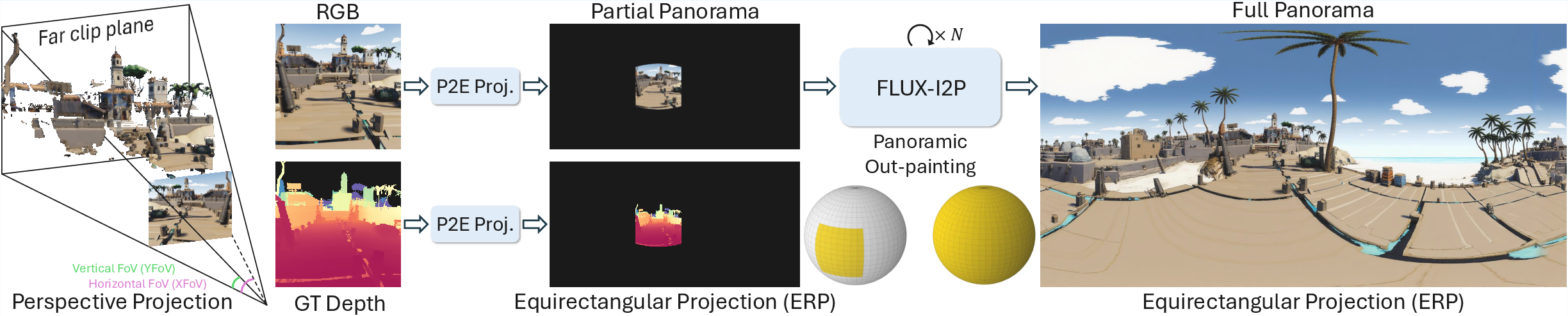
A panoramic data curation engine (turning regular photos into 360 data)
- Problem: There aren’t many 360 images with ground-truth distance data, so training is hard.
- Solution: Take lots of high-quality regular images that already have depth, “project” them onto a sphere, and then “out-paint” the missing parts to make a complete 360 panorama.
- Projection: Imagine wrapping a flat photo onto a globe using known camera angles. This fills only a slice of the sphere (like a small patch on the globe).
- Out-painting: Use a powerful image model (FLUX-I2P) to fill in the missing parts of the 360 image. It’s like finishing a jigsaw puzzle using hints from the surrounding picture.
- Important detail: They only out-paint the RGB image (the color picture), not the depth values, to avoid errors in the 3D measurements.
This process scaled the training data to about 607,000 panoramic image pairs (around 543,000 converted from regular images plus about 63,000 native panoramas).
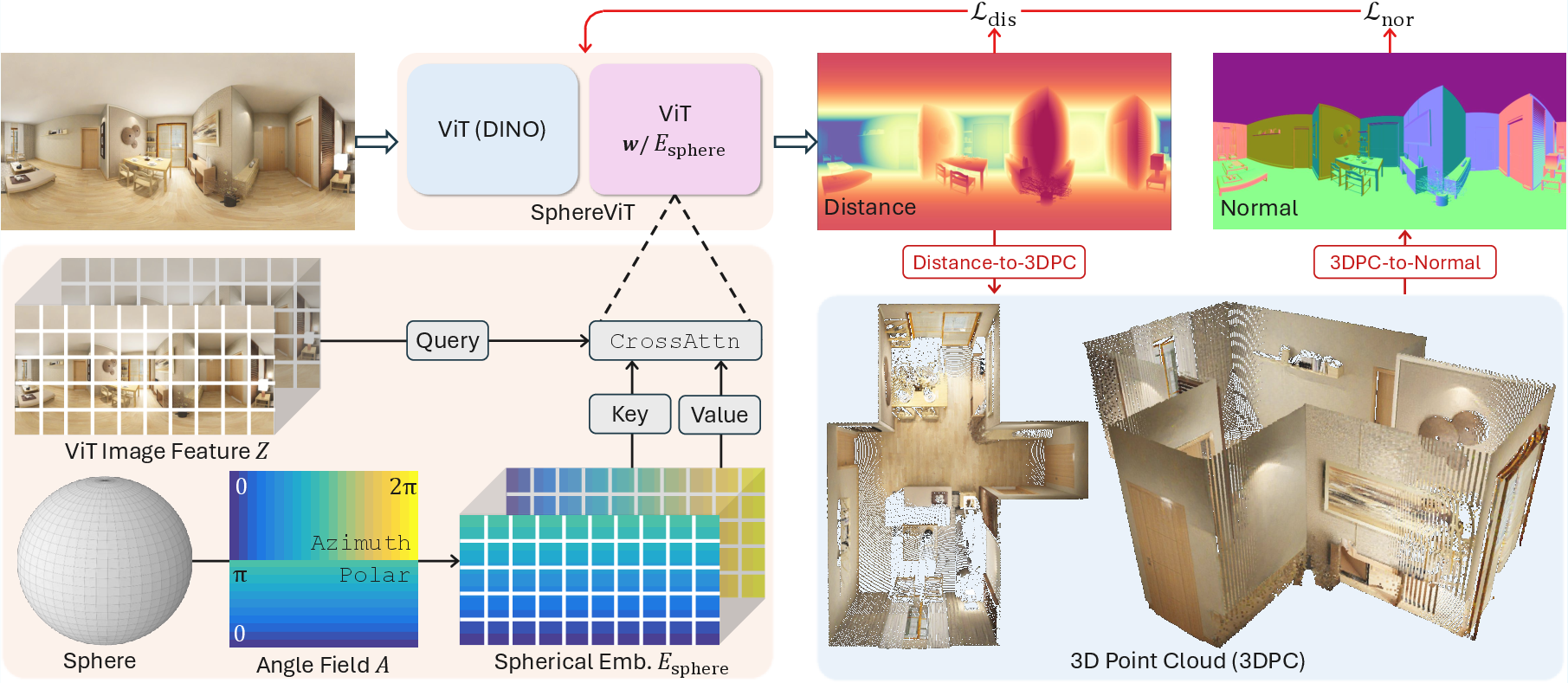
SphereViT (a sphere-aware Vision Transformer)
- Problem: A 360 panorama is stored as a rectangle (called equirectangular projection), but that rectangle distorts the sphere—especially near the top and bottom, just like world maps.
- Solution: Teach the network about the sphere’s geometry.
- The model computes the spherical angles (longitude and latitude) for each pixel in the panorama.
- It turns those angles into a “spherical embedding,” a kind of guidance signal that tells the network where each pixel really lies on the globe.
- Instead of ordinary self-attention, the image features “look up” the spherical embedding using cross-attention. In simple terms, the picture’s features ask the sphere map, “Where am I on the globe?” This helps the model handle distortions correctly.
Training signals (what the model learns from)
- Distance loss: Encourages the model to predict correct distances to the camera center for each pixel. They use scale-invariant training, which means the model learns “how far things are relative to each other,” even if overall scale changes.
- Normal loss: Encourages smooth, sharp surfaces by learning surface directions (normals). This helps avoid wobbly walls or rough edges in the 3D output.
Main Findings
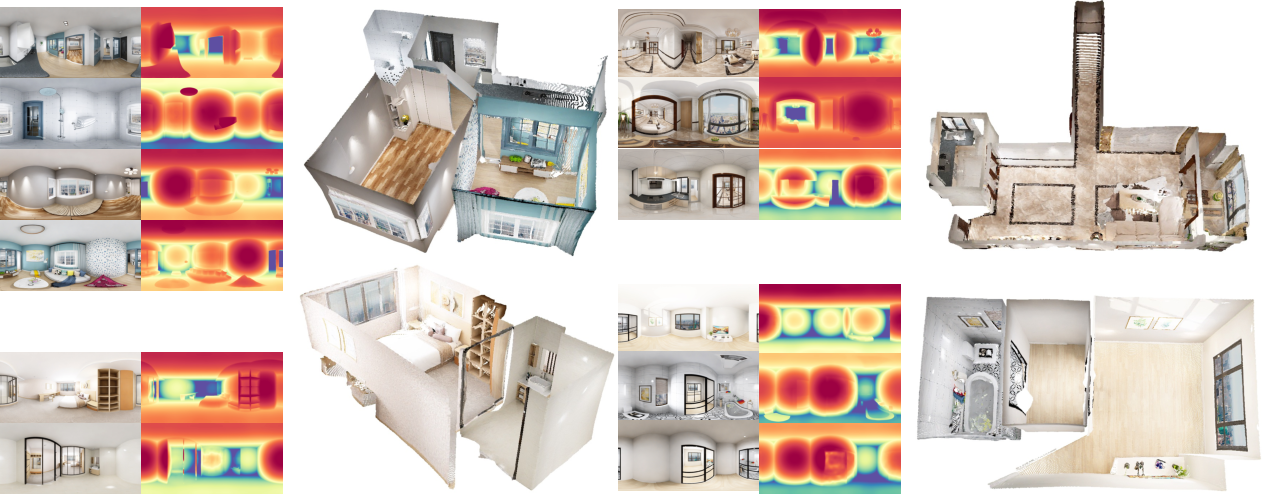
The paper reports strong results on several standard 360-degree benchmarks, and here’s why it matters:
- Better accuracy: On average, DA² improves a key error metric (AbsRel) by about 38% compared to the strongest previous zero-shot method.
- Strong generalization: Even without being specifically trained on the test domains, DA² beats earlier methods that were trained directly on those domains.
- Efficiency: DA² is end-to-end and does not need to split panoramas into cubes or fuse multiple views, making it faster and simpler than fusion-based approaches.
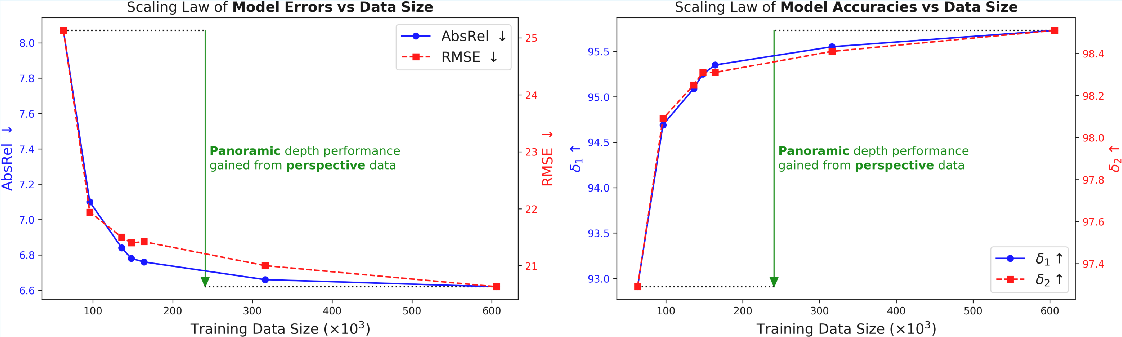
- Scaling helps: As they added more curated panoramic data from regular photos, performance steadily improved, showing a clear “scaling law.”
Why It Matters
DA² makes 360-degree images truly 3D-aware, which opens the door to many applications:
- AR/VR and immersive experiences: More realistic and interactive environments.
- 3D scene creation and reconstruction: Turning panoramas into detailed 3D spaces.
- Robotics and simulation: Robots can better understand and plan in indoor spaces.
- Home design and visualization: Accurate room measurements and layouts from a single panorama.
Limitations to keep in mind:
- Current training resolution (1024×512) can miss fine details.
- In some cases, seams can appear where the left and right sides of the panorama meet.
Overall, DA² shows that two things—building a big, high-quality 360 dataset from regular images and designing a model that truly understands spherical geometry—can dramatically improve 360-degree depth estimation. The team plans to release the code and curated data, which could help many others build on this work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Lack of supervision in out-painted regions: curated RGB panoramas are out-painted but the corresponding depth is not; the model never receives ground-truth supervision for large swaths of the sphere, leaving an unquantified reliance on generative hallucinations in those regions.
- Bias from RGB–depth inconsistency: training pairs combine out-painted RGB with only partially valid GT depth; the impact of this mismatch on learned priors, boundary sharpness, and metric consistency is not analyzed.
- Quality control of out-painted data: no automatic filtering or scoring of out-painted panoramas is described; a pipeline to detect artifacts (e.g., seams, structural implausibility) and exclude low-quality samples is missing.
- Sensitivity to inaccurate or unknown FoVs: the data curation engine assumes known XFoV/YFoV for perspective data; many datasets lack precise calibration—robustness to FoV errors and methods to estimate/correct FoVs are not studied.
- Choice of out-painting model and training details: dependence on FLUX-I2P is not ablated against alternative generators, nor are the LoRA fine-tuning data, objectives, or potential overfitting/leakage risks reported.
- No metric-depth recovery: the system targets scale-invariant distance; strategies to recover absolute scale (e.g., with height priors, IMU/altimeter cues, multi-view constraints) remain unexplored.
- Uncertainty estimation: the model does not output confidence or uncertainty maps, which could guide seam blending, post-processing, or integration with downstream 3D pipelines.
- Limited evaluation domains: benchmarks cover primarily indoor datasets; generalization to outdoor panoramas, large-scale urban/landscape scenes, and extreme lighting/weather is not evaluated.
- Resolution limitations: training at 1024×512 leaves open whether multi-scale training, higher-resolution models (2K/4K), or super-resolution depth heads reduce missed fine details and improve edge fidelity.
- Persistent seam artifacts: left–right boundary seams are acknowledged as a limitation; seam-aware architectures, cyclic padding, or circular attention mechanisms are not investigated.
- Assumption of full FoV ERP: the approach assumes 360×180 ERP; robustness to partial panoramas, cylindrical projections, fisheye/equidistant models, or mixed camera rigs is untested.
- Orientation and horizon alignment: the method presumes consistent spherical coordinates; robustness to unknown roll/pitch, horizon tilt, or arbitrary panorama rotations (and rotation-equivariant designs) is not analyzed.
- Planarity and straight-line fidelity: while qualitative issues like curved walls are shown, no quantitative metrics (e.g., planarity error, line straightness across latitudes) or pole-specific error analyses are reported.
- Loss design at discontinuities: normal L1 supervision may be ill-posed near depth discontinuities; edge-aware or occlusion-aware losses, and their impact on boundary crispness, are not explored.
- D2N operator details and stability: the distance-to-normal computation used for supervision is not specified (e.g., filters, neighborhood size), nor is its sensitivity to noise, missing pixels, or pole distortions.
- Data mixture and domain balance: beyond sampling probabilities, there is no systematic study of domain shift, cross-domain weighting, or curriculum strategies to mitigate overrepresentation of synthetic or indoor content.
- Robustness to dynamic objects: curated datasets include moving objects; how motion-induced inconsistencies (after projection/out-painting) affect training and predictions is not evaluated.
- Cross-view consistency training: despite multi-view applications, the model is trained per image; explicit cross-view consistency objectives or pose-aware training to improve global coherence are not attempted.
- Architectural alternatives to SphereViT: no comparisons with spherical CNNs, icosahedral grids, HEALPix tessellations, or rotary/relative positional encodings adapted to spherical geometry are provided.
- Fixed spherical embedding design: the choice of frequencies, dimensionality, and cross-attention (vs additive or learned embeddings) is not systematically ablated; optimal encoding for different resolutions/latitudes remains open.
- Model capacity and compute scaling: scaling laws are presented for data size but not for model size, depth/width, token count, or training compute; the trade-off between accuracy and efficiency is not characterized.
- Runtime and memory profiling: claims of higher efficiency lack comprehensive benchmarks (throughput, latency, memory) across resolutions and hardware, compared to fusion-based baselines.
- Handling of invalid/sky regions: policies for masking sky/void and other invalid pixels across diverse domains (especially outdoor) are not detailed; the effect of mask strategy on performance is unknown.
- Data licensing and release scope: legal constraints and licensing of derived out-painted panoramas (built from third-party datasets) are not discussed; the extent and form of released data (masks, quality flags) is unclear.
- Generalization to real 360 sensors: aside from the listed benchmarks, robustness to real sensor artifacts (stitching errors, chromatic aberrations, rolling shutter) is not measured.
- Post-processing and refinement: no exploration of simple seam-blending, spherical filtering, or test-time augmentations (e.g., cyclic shifts) to reduce artifacts.
- Metric choice breadth: evaluation uses AbsRel/RMSE/δ; additional 3D-aware metrics (surface normal error, plane recall/precision, edge accuracy, geodesic or spherical-latitude–conditioned errors) would diagnose failure modes more precisely.
- Calibration of curated camera poses: the selection and distribution of (φc, θc) for P2E placement are not specified; biases in view-center sampling may skew learning and should be audited.
- Self-supervised or semi-supervised signals: opportunities to leverage photometric consistency, stereo panoramas, or unlabeled 360 videos to supervise out-painted regions are not pursued.
- Robustness to noise and compression: impact of real-world noise, JPEG artifacts, or HDR ranges on depth accuracy and normal stability is unreported.
- Downstream task validation: claimed benefits for AR/VR, robotics, and reconstruction are illustrated but not quantitatively evaluated (e.g., navigation success, reconstruction completeness), leaving practical utility unmeasured.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can leverage the paper’s findings and released tools right away.
- AR/VR content production (sector: entertainment, software)
- Use DA² to generate dense, scale-invariant depth from single 360° panoramas to enable occlusion-aware AR overlays, relighting, and volumetric effects in immersive experiences.
- Tools/products/workflows: Unity/Unreal plugin that ingests ERP panoramas → DA² depth → point cloud/mesh → AR occlusion and spatial effects; Blender add-on for 360° compositing; web API for panorama-to-depth conversion.
- Assumptions/dependencies: Input must be a 360° panorama in ERP; depth is scale-invariant (needs simple scale calibration for metric uses); seams and fine detail may degrade results at 1024×512; scene consistency can be affected near poles and reflective surfaces.
- Real estate virtual tours and property visualization (sector: real estate, AEC)
- Produce navigable 3D representations from single-room panoramas; align multi-room panoramas via simple translation to form coherent multi-room point clouds (as shown by Pano3R).
- Tools/products/workflows: “Panorama-to-PointCloud” pipeline for listing pages; multi-room alignment service for apartments/houses; export to CAD/BIM viewers.
- Assumptions/dependencies: Depth is relative; for accurate measurements, add scale via known dimensions (e.g., a measured wall) or multi-view capture; occasional left–right seam artifacts may need post-processing.
- Interior design and furniture visualization (sector: retail, home improvement)
- Generate layered 3D reconstructions for “empty/simple/full” room states to preview design options and furniture placement with consistent background geometry.
- Tools/products/workflows: Online retailer “see-it-in-your-room (360)” preview; interior design apps using DA² point clouds for staging; instant panorama-based occlusion masks for realistic placement.
- Assumptions/dependencies: Scale calibration for fit/clearance; clutter and specular surfaces may cause local artifacts; higher resolution improves furniture-edge fidelity.
- Robotics simulation environments (sector: robotics)
- Build quick, realistic 3D indoor environments from panoramas for manipulation, navigation simulation, and benchmarking.
- Tools/products/workflows: “Panorama-to-SimWorld” generator to import DA² point clouds into Gazebo/Isaac/Unity Simulation; use DA² normals for smoother collision surfaces.
- Assumptions/dependencies: Depth is not metric; add scale via known objects or sensor fusion; dynamic scenes require updated panoramas; seams and lower resolution may affect collision accuracy.
- Facility management and space auditing (sector: operations, FM)
- Rapidly capture rooms and produce relative 3D models to plan layout changes, minor retrofits, or maintenance workflows.
- Tools/products/workflows: Mobile 360° capture → DA² depth → coarse floor-plan inference; inventory placement checks via relative geometry.
- Assumptions/dependencies: For compliance-grade measurements, add scale calibration or multi-view refinement; ERP input and image quality impact accuracy.
- Insurance claims and documentation (sector: finance/insurance)
- Convert post-incident 360° panoramas into 3D evidence to assess damage extent and relative spatial relationships.
- Tools/products/workflows: Claims portal that accepts panoramas and returns annotated 3D views; overlay adjuster notes and measurements.
- Assumptions/dependencies: Relative depth requires simple scaling; fine-detail limitations at current resolution may miss small defects; privacy handling for indoor data.
- Cultural heritage and museum digitization (sector: culture, education)
- Create immersive walkthroughs and room-level 3D reconstructions from existing 360° captures.
- Tools/products/workflows: Panorama-to-depth service for curators; layered reconstructions for exhibit planning.
- Assumptions/dependencies: Non-metric outputs; lighting variations may affect geometry fidelity.
- Academic datasets and teaching (sector: academia/education)
- Use the panoramic data curation engine to synthesize large, diverse panoramic training sets from perspective datasets; teach spherical projection, ERP distortions, and cross-attention with spherical embeddings in CV courses.
- Tools/products/workflows: Open-source scripts for P2E projection and FLUX-I2P outpainting; SphereViT backbone for panoramic tasks; lab assignments on distortion-aware embeddings.
- Assumptions/dependencies: FLUX-I2P availability; licensing of source perspective datasets; outpainted RGB introduces content priors but no GT depth (depth outpainting intentionally avoided).
- Media post-production for 360° footage (sector: media/film)
- Extract relative depth maps from 360° stills for compositing, smoke/fog volumetrics, and shot planning.
- Tools/products/workflows: Nuke/After Effects integration for ERP inputs; DA²-based matte generation for depth-aware effects.
- Assumptions/dependencies: Accurate alignment of ERP frames; temporal stability requires per-frame processing and lightweight temporal smoothing.
- Daily-life measurement helpers (sector: consumer apps)
- Provide rough room-scale measurements from a single panorama for DIY projects (painting, décor placement).
- Tools/products/workflows: Smartphone app capture → DA² depth → guided scale calibration using a known height/width to return approximate dimensions.
- Assumptions/dependencies: Requires one known reference for scaling; not survey-grade accuracy; seams and resolution impact edges.
Long-Term Applications
The following applications are promising but will benefit from further research, scaling, metric calibration, higher-resolution models, or real-time deployment improvements.
- Real-time 360° perception for robots and drones (sector: robotics, autonomy)
- Deploy DA²-like models onboard robots with 360° cameras for navigation, obstacle avoidance, and semantic scene understanding.
- Tools/products/workflows: Hardware-accelerated SphereViT variants; scale recovery via sensor fusion (IMU/LiDAR/stereo/SLAM); temporal consistency modules for 360° video.
- Assumptions/dependencies: Metric depth required; low-latency inference on edge devices; robust handling of motion blur and dynamic scenes.
- 360° video depth and temporal reconstruction (sector: software, media)
- Extend from single panoramas to stable, temporally coherent 360° video depth; enable live broadcasting with depth-aware effects.
- Tools/products/workflows: Video-aware SphereViT with temporal attention; seam-aware stabilization; streaming inference pipelines.
- Assumptions/dependencies: Computational budget for real-time; temporal artifacts must be mitigated; higher-resolution training data needed.
- One-shot floor-plan and BIM integration (sector: AEC, digital twins)
- Automatically infer floor-plans and room semantics from one panorama per room, and align rooms into a building-level Digital Twin.
- Tools/products/workflows: Panorama-based plane/line extraction → top-down layout inference → semantic labeling → export to IFC/Revit; scale via multi-view or anchor measurements.
- Assumptions/dependencies: Accurate plane detection and metric calibration; robust multi-room alignment beyond pure translation; edge cases in non-rectilinear spaces.
- Compliance and safety analytics (sector: policy, public safety)
- Use 360° reconstructions to pre-check egress routes, accessibility, and code compliance in complex indoor environments.
- Tools/products/workflows: Rule engine over 3D models to flag violations (e.g., corridor width, door clearances); inspector dashboards.
- Assumptions/dependencies: Metric depth and semantic understanding; standardized data formats; policies governing indoor scanning and storage.
- Digital-twin operations for facilities (sector: energy, operations)
- Feed panorama-derived 3D models into building management systems for energy audits, retrofit planning, and asset tracking.
- Tools/products/workflows: Integration with IoT/BMS platforms; change detection from periodic panoramas; energy modeling using approximate geometry.
- Assumptions/dependencies: Metric calibration; regularized capture protocols; robust handling of moving objects and seasonal changes.
- Physics-consistent outpainting and geometry completion (sector: software, research)
- Advance panoramic outpainting to jointly predict RGB and physically plausible depth/geometry for unseen regions.
- Tools/products/workflows: Co-trained generative pipelines (e.g., DiT + geometry heads) with physical priors; uncertainty estimation and editable completions.
- Assumptions/dependencies: High-quality joint supervision; generalization across diverse domains; user-in-the-loop validation.
- SphereViT extensions to other panoramic tasks (sector: software, robotics, geospatial)
- Apply spherical embeddings and cross-attention to panoramic semantic segmentation, optical flow, 3D scene generation, and NeRFs on 360° inputs.
- Tools/products/workflows: Panoramic segmentation models for hazard detection; 360° NeRF/GS pipelines using DA² depth priors; spherical-aware feature extractors for downstream CV tasks.
- Assumptions/dependencies: Task-specific datasets; training at higher resolutions; evaluation benchmarks for panoramas.
- Standardization and privacy frameworks (sector: policy, industry consortia)
- Establish benchmarks, best practices, and privacy-by-design protocols for panoramic depth datasets of indoor spaces.
- Tools/products/workflows: Open benchmark suites for ERP tasks; guidelines for anonymization, storage, and sharing; property owner consent workflows.
- Assumptions/dependencies: Multi-stakeholder governance; legal compliance across regions; interoperability standards.
- Consumer-grade “scan-less” 3D home modeling (sector: consumer apps, real estate)
- Build an app that creates a basic 3D home model from one panorama per room with automatic scale recovery using device sensors (ARCore/ARKit) and learned calibration.
- Tools/products/workflows: Guided capture with pose hints; sensor fusion for metric scale; room semantics and furniture fitting.
- Assumptions/dependencies: Reliable device sensor access; robust alignment across rooms; UX to handle calibration and edge cases.
- Emergency and disaster response planning (sector: public safety)
- Rapidly construct 3D situational awareness from 360° images captured on-site to plan ingress/egress and resource placement.
- Tools/products/workflows: Field capture kits; immediate panorama-to-3D processing; incident command visualization.
- Assumptions/dependencies: Metric scale and semantic layers; resilient capture under adverse conditions; secure data handling.
Cross-cutting assumptions and dependencies
- Scale-invariant outputs: DA² predicts relative distance; metric use cases need simple calibration (known dimensions), sensor fusion (IMU/LiDAR/stereo/SLAM), or multi-view normalization.
- Input format: Requires 360° panoramas (ERP). Quality of input (exposure, motion blur, reflections) impacts geometry fidelity.
- Artifacts and resolution: Current training at 1024×512 may miss fine details and introduce left–right seam artifacts, especially near poles.
- Data curation: FLUX-I2P outpaints RGB only (not depth). While it improves model generalization, outpainting introduces learned priors; GT depth remains P2E-projected.
- Compute and deployment: Real-time or high-resolution applications will need model optimization, quantization, or hardware acceleration.
- Privacy and compliance: Indoor panoramas can contain sensitive information; data governance and consent are essential for industry and policy workflows.
Glossary
- AbsRel: Absolute relative error metric for depth estimation evaluating proportional difference between prediction and ground truth. "38% improvement on AbsRel over the strongest zero-shot baseline."
- Affine-invariant alignment: Evaluation alignment that is invariant to both scale and shift (affine transformations). "Affine-invariant alignment (scale and shift-invariant)"
- Azimuth: The longitude angle on a sphere measuring rotation around the vertical axis. "the azimuth (longitude) and polar (colatitude) angles"
- Colatitude: Polar angle on a sphere measured from the positive y-axis (complement to latitude). "polar (colatitude)"
- Cross-attention: Attention mechanism where queries attend to separate keys/values rather than self-tokens. "SphereViT uses cross-attention: image features are regarded as queries and the spherical embeddings as keys and values."
- Cubemap: Projection that represents a spherical view as six perspective images on the faces of a cube. "ERP (1 panorama) and cubemap (6 perspectives) projections"
- Cylindrical projection: Mapping that wraps the horizontal field of view around a cylinder; suitable for less than full vertical coverage. "cylindrical projection can be used"
- D2N (distance-to-normal operator): Operator that converts a distance (depth) map into per-pixel surface normals. "distance-to-normal operator D2N"
- Delta accuracy (δ1, δ2): Threshold-based accuracy metrics counting pixels within multiplicative error bounds. "using 2 error metrics (AbsRel, RMSE), and 2 accuracy metrics (, )."
- Diffusion Transformer (DiT): Transformer architecture for diffusion models handling image generation tasks. "Diffusion Transformer (DiT)"
- Equirectangular projection (ERP): Latitude–longitude mapping from the sphere to a 2D image used for panoramas. "Panoramas typically use equirectangular projection (ERP)"
- Field of View (FoV): Angular extent of the observable world captured by a camera. "Panorama has a full FoV (360180)"
- FLUX-I2P: A LoRA-tuned FLUX model for image-to-panorama out-painting. "using an image-to-panorama out-painter: FLUX-I2P"
- Icosahedral mesh (spherical): Geodesic tessellation of the sphere using subdivided icosahedra for uniform sampling. "spherical icosahedral meshes"
- LoRA: Low-Rank Adaptation technique for parameter-efficient fine-tuning of large models. "LoRA fine-tuned FLUX model"
- Median alignment: Scale normalization aligning predicted depth to ground truth via matching medians. "Median alignment (scale-invariant) is adopted by default."
- Möbius transformation: Conformal mapping used for data augmentation on spherical images. "M$\ddot{\text{o}$bius transformation}-based data augmentation for self-supervision."
- Normal loss (ℒ_nor): Training loss encouraging accurate surface normals for geometric smoothness and sharpness. "a normal loss $\mathcal{L}_{\text{nor}$"
- Out-painting (panoramic): Generative completion that fills missing regions to produce full 360° panoramas. "panoramic out-painting will be performed"
- Perspective-to-Equirectangular (P2E) projection: Mapping from a perspective image to its spherical ERP coordinates. "Perspective-to-Equirectangular (P2E) projection"
- Positional embeddings (PE): Encodings that inject spatial coordinate information into transformer features. "positional embeddings in Vision Transformers (ViTs)"
- RMSE: Root Mean Squared Error; depth error metric measuring average squared deviation. "using 2 error metrics (AbsRel, RMSE)"
- Scale-invariant distance: Distance/depth representation normalized for unknown global scale, enabling consistent comparisons. "scale-invariant distance"
- SphereViT: Distortion-aware ViT backbone that injects spherical geometry via a spherical embedding and cross-attention. "we present SphereViT"
- Spherical distortion: Non-uniform stretching/compression introduced when projecting a sphere onto a plane. "spherical distortions inherent in panoramas"
- Spherical embedding: Feature embedding constructed from per-pixel spherical angles (azimuth, polar) to guide attention. "spherical embedding "
- Spherical harmonics: Basis functions on the sphere used to represent signals or geometry on spherical domains. "spherical harmonics."
- Surface normal: Unit vector perpendicular to a local surface element, derived from depth/distance maps. "Then the surface normals can be obtained"
- Vision Transformer (ViT): Transformer architecture adapted for images using patch tokens and attention. "Vision Transformers (ViTs)"
Collections
Sign up for free to add this paper to one or more collections.