Covenant-72B: Pre-Training a 72B LLM with Trustless Peers Over-the-Internet
Abstract: Recently, there has been increased interest in globally distributed training, which has the promise to both reduce training costs and democratize participation in building large-scale foundation models. However, existing models trained in a globally distributed manner are relatively small in scale and have only been trained with whitelisted participants. Therefore, they do not yet realize the full promise of democratized participation. In this report, we describe Covenant-72B, an LLM produced by the largest collaborative globally distributed pre-training run (in terms of both compute and model scale), which simultaneously allowed open, permissionless participation supported by a live blockchain protocol. We utilized a state-of-the-art communication-efficient optimizer, SparseLoCo, supporting dynamic participation with peers joining and leaving freely. Our model, pre-trained on approximately 1.1T tokens, performs competitively with fully centralized models pre-trained on similar or higher compute budgets, demonstrating that fully democratized, non-whitelisted participation is not only feasible, but can be achieved at unprecedented scale for a globally distributed pre-training run.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about training a very large AI LLM (like ChatGPT) in a new, more open way. Instead of using one giant, expensive computer cluster in a fancy data center, the team trained a 72-billion-parameter model called Covenant-72B using many computers around the world connected over the regular internet. Anyone could join and help—no special permission list—while a system on a blockchain helped keep things fair and secure.
What questions did the researchers ask?
They set out to answer simple but important questions:
- Can a huge AI model be trained by many volunteers over the internet, not just by big tech data centers?
- Can this be done efficiently, even with slow or unreliable connections?
- Can we let anyone join (permissionless) without trusting them, and still get good results?
- Will the final model be as good as models trained in centralized, expensive setups?
How did they do it?
To make this work at scale, they had to solve two big problems: how to communicate efficiently and how to keep things honest.
Training with volunteers over the internet
Think of it like a global study group: each participant (“peer”) has a powerful computer and works on a piece of the training. Every so often, they share what they’ve learned so everyone can stay in sync.
Sending tiny updates (SparseLoCo)
Normally, training requires sending huge amounts of data back and forth. That doesn’t work well over typical internet connections. The team used a method called SparseLoCo to send only the most important parts of each update, and to compress them heavily:
- Top‑k selection: Like highlighting only the most important sentences in a long essay, each peer sends just the strongest parts of their update.
- Error feedback: Anything left out gets remembered and added later—like keeping a to-do list of missed points.
- 2-bit quantization: They represent numbers using only 2 bits (4 levels), similar to rounding to one of four values. This shrinks the data a lot.
Together, these tricks compressed communication by more than 146×, meaning far less internet traffic.
Keeping it fair and safe (Gauntlet)
Because anyone could join, they needed a way to stop cheating or bad updates. They used a blockchain-based system called Gauntlet:
- A “validator” quickly tests each peer’s update on small batches of data to see if it actually helps the model (does the loss go down?).
- Peers are ranked over time (like a running scoreboard), and only the best updates get combined each round.
- It checks that peers train on their assigned data and not just copy others.
- Rewards and selection happen on the Bittensor blockchain, which helps coordinate and incentivize honest work.
The system in practice
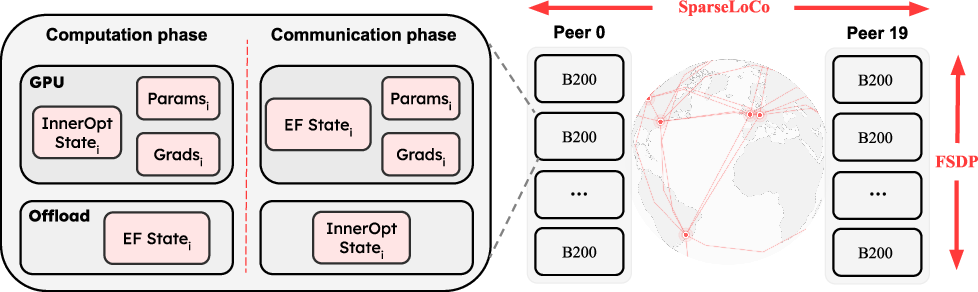
- Each peer typically had 8 powerful GPUs and used a technique called FSDP (a way to split the model’s pieces across GPUs) to fit everything in memory.
- Instead of direct peer-to-peer connections, updates were uploaded to a shared cloud storage (Cloudflare R2)—like using a shared folder—so others could download them easily.
- Peers could join or leave at any time; the system kept going smoothly.
What did they find, and why is it important?
Here are the main results in plain terms:
- Big model, big training: They trained a 72B-parameter model on about 1.1 trillion tokens—one of the largest open, over-the-internet training runs ever.
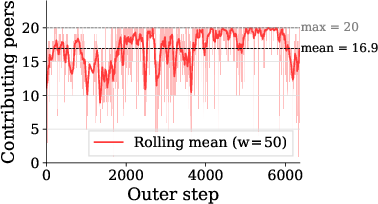
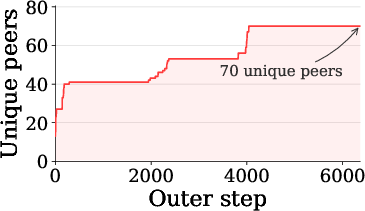
- Open to anyone: Participation was permissionless (no whitelist). At least 70 unique peers contributed over time.
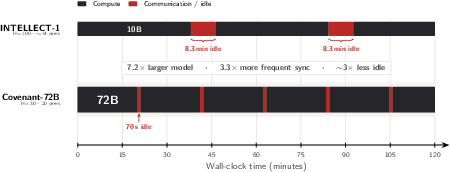
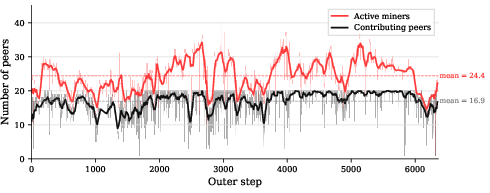
- High efficiency: Each 20-minute compute cycle needed only about 70 seconds for communication—around 94.5% of time was spent actually training (very good).
- Strong performance: The model’s test scores were competitive with models trained in large data centers, like LLaMA-2-70B and K2 (65B), despite using fewer training tokens than some of those baselines.
- Chat version works well: After a short extra training phase (called supervised fine-tuning) with about 14.8B tokens, the chat version (Covenant-72B-Chat) performed competitively on many tasks. It especially stood out in instruction following (IFEval) and math (MATH) compared to similar models.
Why this matters:
- It shows we can train top-tier large models without owning massive centralized infrastructure.
- It lowers the barrier to entry—more people and groups can contribute to and benefit from building powerful AI systems.
- It proves that careful communication tricks and smart coordination can make internet-based training practical at very large scales.
What’s the impact?
This work points to a future where building big AI models isn’t limited to a few huge companies. By:
- Allowing open, global participation,
- Using smart compression to make slow networks workable,
- And enforcing fairness and quality through a blockchain-based referee,
the team demonstrates a practical way to “democratize” AI training. If expanded further, this approach could:
- Reduce costs by pooling worldwide resources,
- Support more diverse contributions and ideas,
- And speed up innovation by making large-scale AI research more accessible.
Final takeaway
Covenant-72B shows that training a giant, high-quality LLM with volunteers over normal internet connections is not only possible—it can compete with traditional, expensive data center training. With efficient communication (SparseLoCo) and a trustless coordination system (Gauntlet on a blockchain), permissionless, global AI training at scale is within reach.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and open questions that remain unresolved and could guide follow-up research.
- Controlled baselines: No head-to-head comparison with a centrally trained 72B model using the same tokenizer, data mixture, token budget, and training recipe, leaving the specific contribution of SparseLoCo/Gauntlet ambiguous.
- SparseLoCo ablations: Lacks sensitivity studies over (inner steps), (outer LR), (error-feedback decay), Top- sparsity level, chunk size, and quantization bits to quantify trade-offs between communication, stability, and final quality.
- Dynamic compression: No exploration of adaptive /bitwidth per layer or per-round (e.g., based on layer sensitivity or network conditions) to optimize bandwidth-quality trade-offs.
- Convergence theory: Absent theoretical guarantees for chunk-wise Top- with error-feedback under 2-bit quantization, heterogeneous data, dynamic participation, and norm-normalized aggregation.
- Robust aggregation: Norm-based scaling is used, but there is no comparison with adversarially robust aggregators (e.g., median, trimmed-mean, Krum, Bulyan) under realistic attack models.
- Byzantine/adversarial robustness: No empirical evaluation of resilience to gradient poisoning, sybil attacks, collusion, or coordinated model-copying; no measurements of validator detection rates, false positives/negatives, or impact on end quality as adversarial share increases.
- Validator bottleneck: The validator computes LossScore on a 72B model, yet no analysis of validator hardware requirements, throughput, queuing delays, or multi-validator consensus to avoid a single point of failure.
- Scoring signal design: Sensitivity of Gauntlet’s selection accuracy to the size/representativeness of scoring batches, the OpenSkill prior, and scoring frequency is unreported.
- Staleness and liveness: Criteria for rejecting stale or desynchronized pseudo-gradients are not quantified; no study of how staleness thresholds affect stability and convergence.
- Participation scaling: The run caps contributors at 20 per round; scalability beyond this (R→100s/1000s) is untested, including validator throughput, Cloudflare R2 fanout/fanin limits, and aggregate bandwidth/latency at p95/p99.
- Heterogeneous peers: Minimal tolerance for hardware/network heterogeneity is shown (≥8×B200 per peer); no evaluation on mixed accelerators (A100/H100/consumer GPUs), variable uplinks, or memory-limited nodes.
- Stragglers and asynchrony: Training is effectively semi-synchronous per round; no experiments with stale-synchronous/asynchronous variants to handle high-latency or flaky peers while preserving quality.
- Tail latency: Reported communication time is an average; no tail (p95/p99) latency measurements, straggler mitigation strategies, or impact of long tails on utilization and round time.
- Communication overheads: Index encoding chosen for simplicity (12 bits/value) without profiling CPU/codec overhead; no ablation comparing more efficient encoders (e.g., Elias/Fano/Golomb) and their end-to-end cost/benefit.
- Offload/swapping overhead: Error-feedback and optimizer state swapping is described but not quantified (GPU memory headroom, swap time, PCIe/NVLink contention), nor validated on lower-memory GPUs.
- Integrity and authenticity: Peers download pseudo-gradients directly from object storage; no cryptographic signing/verification scheme, hash chains, or end-to-end integrity checks are described or evaluated.
- Storage credential security: Participants expose R2 credentials; key scope, rotation, revocation, and abuse prevention (e.g., data exfiltration, bucket poisoning) are not detailed or stress-tested.
- Data assignment enforcement: The “assigned vs. unassigned” LossScore check has no reported false positive/negative rates or adversarial evaluations (e.g., training on mixtures to evade checks, replay attacks).
- Economic incentives: Reward function details, fairness across peers, correlation between reward and contribution quality, sybil-resistance of rewards, and long-term sustainability (e.g., covering egress and storage costs) are not analyzed.
- Fairness and decentralization: With only 20 contributors aggregated per round, the distribution of opportunities/rewards among many potential peers and risk of centralization by high-resource participants are not measured.
- Data governance and contamination: No systematic decontamination analysis versus evaluation sets (ARC, MMLU, etc.), dataset licensing compliance, language/domain composition, deduplication rates, or bias/toxicity audits.
- Evaluation breadth: Limited assessment of long-context abilities beyond 8k (e.g., LongBench/Needle-in-a-Haystack), safety/jailbreak robustness, factuality/hallucination, or multi-turn tool-use/agentic performance.
- SFT ablations: No quantification of the effects of 20% replay, two-stage schedules, or alternative alignment strategies (e.g., RLHF/DPO) on forgetting, safety, and reasoning; no error analysis where the chat model underperforms baselines.
- Long-context pretraining: The base model is pre-trained at 2k context only; the impact of pretraining at longer contexts on SparseLoCo dynamics and final long-context capabilities remains unexplored.
- MoE and other architectures: Applicability and performance of SparseLoCo with mixture-of-experts or multimodal models (and how compression interacts with expert routing/activation sparsity) are untested.
- Dedup across peers/rounds: With pre-tokenized shard downloads, the global deduplication strategy across participants and over time, and its impact on quality/overfitting, are not described or measured.
- Compute and energy accounting: Absent reporting on total GPU hours, energy consumption, carbon footprint, network egress/ingress, and monetary cost versus centralized training baselines.
- Reliability and fault tolerance: No evaluation under Cloudflare outages, validator downtime, blockchain liveness issues, or network partitions; no fallback mechanisms or recovery protocols are described.
- Hyperparameter selection process: Outer LR reduction (from 1.0 to 0.65) and LR flattening decisions are ad hoc; no principled tuning methodology or early-warning signals for instability/plateaus are provided.
- Robustness to norm scaling: The impact of per-submission norm normalization on convergence fairness across peers with different batch sizes/data distributions is not ablated.
- Release reproducibility: While checkpoints are released, the full orchestration code (Gauntlet integration, state offloading, communication stack, validator logic) and exact configs/logs for end-to-end reproducibility are not clearly provided.
- Legal/compliance of permissionless training: Risks from cross-jurisdiction participation (e.g., export controls, data protection), and governance mechanisms to prevent misuse (training on proprietary or harmful data) are not addressed.
Practical Applications
Overview
Below are concrete, real-world applications that follow from the paper’s findings and innovations: permissionless, over-the-internet pre-training of a 72B LLM using the SparseLoCo optimizer (chunk-wise Top‑k + 2‑bit quantization + error feedback), Gauntlet’s trustless validator/reward mechanism on Bittensor, and an object‑storage–based communication fabric that achieved high utilization under commodity internet constraints. Each application is categorized as either an Immediate Application (deployable now) or a Long‑Term Application (requiring further research, scaling, or development). Where relevant, links to sectors, likely tools/products/workflows, and feasibility dependencies are included.
Immediate Applications
These can be deployed now using the paper’s released checkpoints, described system patterns, and engineering practices.
- Boldly decentralized LLM training runs for open communities (software infrastructure, academia, civic tech)
- Use case: Organize permissionless, non‑whitelisted training runs for new base or continued‑pretraining models across volunteers or partner labs, using SparseLoCo for WAN‑efficient sync and Gauntlet‑style validation/incentives to maintain quality under open participation.
- Tools/products/workflows: “Validator-as-a-Service” (LossScore + OpenSkill ranking + norm normalization), object‑storage all‑gather (e.g., R2/S3), PyTorch FSDP2 configs, SparseLoCo compression kernels, runbooks for dynamic participation and state offloading.
- Assumptions/dependencies: Stable object storage and access control; sufficient participating GPUs (heterogeneous acceptable, but recipe tested at ≥8× B200/peer); network caps near ~500 Mb/s down / ~110 Mb/s up; reward rails (Bittensor or equivalent) and sybil resistance.
- Multi‑site enterprise training over the public internet/WAN (software, finance, media, pharma)
- Use case: Pool compute from geographically separated corporate data centers (or subsidiaries) to train large models without expensive low‑latency interconnects, preserving ~94–96% compute utilization with SparseLoCo.
- Tools/products/workflows: WAN‑optimized training orchestrator plug‑in for PyTorch (FSDP + SparseLoCo), S3/R2 artifact exchange, internal validator (without blockchain), scheduling around network quotas and egress costs.
- Assumptions/dependencies: Enterprise identity/authorization in lieu of blockchain; network budgeting; governance for dynamic participant replacement.
- SME/startup cost reduction via “BYO‑GPU” marketplaces (cloud marketplaces)
- Use case: Aggregate small providers’ GPUs into permissionless training pools; reward contributors based on Gauntlet‑like scoring; use compressed pseudo‑gradients to stay within residential/office bandwidths.
- Tools/products/workflows: Marketplace front‑end, validator pool, automated bucket provisioning, contributor SDK (upload pseudo‑gradients, provide credentials, health checks).
- Assumptions/dependencies: Legal/payment rails, contributor KYC/anti‑abuse, pricing that accounts for energy/network costs and cloud egress.
- Academic consortia pooling compute (academia)
- Use case: Cross‑university consortium trains medium/large models on shared public datasets with permissionless participation (or identity‑vetted openness) to democratize LLM training access.
- Tools/products/workflows: Shared object storage, common validator service, course-aligned runbooks for state offloading and phased learning rate schedules.
- Assumptions/dependencies: Network stability across campuses; centralized steering group; adherence to data licenses.
- Rapid domain adaptation using Covenant‑72B checkpoints (software, education, customer support, legal, engineering)
- Use case: Start from Apache‑licensed pretraining and chat checkpoints to build internal assistants or specialty models (e.g., support bots, coding aides, tutoring) through SFT, leveraging the paper’s 4k→8k SFT recipe with replay to avoid forgetting.
- Tools/products/workflows: SFT pipelines (variable‑length sequences, nested tensors, cosine LR with warmup, replay mixing), evaluation harness (ARC, MMLU, IFEval, MATH).
- Assumptions/dependencies: High‑quality domain data; GPU availability for SFT; deployment stack (quantization/serving); model size (72B) implies serious inference hardware or managed serving.
- Object‑storage–based synchronization for distributed training (software infrastructure/MLOps)
- Use case: Replace tight, synchronous collectives (all‑reduce) with object‑storage all‑gather of compressed pseudo‑gradients to run distributed training across unreliable or NAT’d networks.
- Tools/products/workflows: “R2/S3Sync” training backend, resumable uploads/downloads, bucket key rotation, data sharding/pre‑tokenization pipeline.
- Assumptions/dependencies: Acceptable consistency and latency from object storage; storage egress cost planning; robust retry/caching.
- Drop‑in gradient communication compression libraries (ML tooling)
- Use case: Integrate chunk‑wise Top‑k + 2‑bit quantization + error feedback in existing multi‑node training stacks (PyTorch/TensorFlow) to cut WAN bandwidth by >100×.
- Tools/products/workflows: PyTorch extension for chunked Top‑k selection with ~12 bits/value index encoding; EF buffer management utilities; FSDP‑aware sharding of EF state.
- Assumptions/dependencies: Overhead of index encoding stays manageable; clear APIs for optimizer state swap/offload.
- Trustless quality control for crowdsourced compute and data tasks (crowdsourcing, data labeling, decentralized evaluation)
- Use case: Score and rank participants in open networks for tasks beyond training (e.g., RLHF data collection, model evaluation) using a Gauntlet‑like LossScore + OpenSkill pipeline and norm normalization to deter gaming.
- Tools/products/workflows: Lightweight forward‑pass evaluators, per‑round sampling and persistent rankings, fast liveness/sync checks.
- Assumptions/dependencies: Access to small, held‑out evaluation batches; resistance to collusion/sybil attacks; potentially non‑blockchain identity in enterprise settings.
- Teaching and experiential learning at scale (education)
- Use case: Students contribute to live, permissionless training runs, learning distributed systems and ML optimization with real‑time dashboards (e.g., peer counts, compute vs. communication timelines).
- Tools/products/workflows: Course kits, sandbox validators, dashboards tracking contribution, idle time, and sparsity/quantization stats.
- Assumptions/dependencies: Classroom access to GPUs (or cloud credits); controlled, safe datasets; incident response for flaky peers.
- Citizen compute and “earn by contributing” programs (daily life, civic tech)
- Use case: Technically skilled hobbyists with multi‑GPU rigs contribute cycles to open training runs and receive on‑chain rewards.
- Tools/products/workflows: Contributor clients, wallet integration, power/cost calculators, safety checks.
- Assumptions/dependencies: Energy costs and thermal limits; local regulations; clear guidance to avoid misuse or hardware damage.
Long‑Term Applications
These require additional research, scaling, or ecosystem maturation (security, privacy, standards, heterogeneous hardware support).
- Privacy‑preserving cross‑hospital model training (healthcare)
- Use case: Train clinical LLMs across multiple institutions without centralizing PHI by combining WAN‑efficient SparseLoCo with secure aggregation, differential privacy, and byzantine‑robust validators.
- Tools/products/workflows: DP‑aware pseudo‑gradient clipping/noising, secure aggregation protocols, hospital‑controlled validators with auditable logs.
- Assumptions/dependencies: Formal privacy guarantees; regulatory compliance (HIPAA/GDPR); poisoning/Byzantine resilience.
- National/regional public compute cooperatives (policy, public sector, academia/SMEs)
- Use case: Publicly funded, permissionless training networks that allocate rewards/credits for compute contributions to open foundation models, reducing dependency on hyperscalers.
- Tools/products/workflows: Governance and funding frameworks, compute credit tokens, transparent validators, audits.
- Assumptions/dependencies: Policy support, procurement processes, grid/energy planning, carbon reporting.
- Edge‑to‑cloud continual learning with intermittent connectivity (mobile, IoT)
- Use case: Phones/edge GPUs contribute sparse, quantized updates for continual model refinement during off‑peak/charging windows.
- Tools/products/workflows: Lightweight device SDKs, aggressive compression, intermittent upload scheduling, on‑device EF buffering.
- Assumptions/dependencies: Energy constraints, thermal limits, device heterogeneity, incentive mechanisms, robust privacy.
- Cross‑organization training on proprietary data with verifiable trust (finance, pharma, legal)
- Use case: Partners co‑train without sharing raw data, using trustless validators augmented with cryptographic proofs (e.g., ZK proofs, TEEs) of data‑of‑origin or policy compliance.
- Tools/products/workflows: ZK‑friendly LossScore designs, enclave‑based validation, attestations for assigned‑data usage.
- Assumptions/dependencies: Practical ZK/TEE performance for large‑scale validation; legal agreements and auditability.
- Byzantine‑robust decentralized training stacks (software security/AI safety)
- Use case: Production‑grade aggregation resilient to adversarial peers (poisoning, collusion), integrating robust statistics, anomaly detection, and multi‑signal scoring beyond norm normalization.
- Tools/products/workflows: Robust aggregators, cross‑round consistency checks, adaptive contributor capping, peer reputation systems.
- Assumptions/dependencies: New theory/benchmarks; overhead vs. robustness trade‑offs validated at 70B+ scale.
- Interoperable standards for “object‑storage all‑gather” and validator APIs (software standards)
- Use case: Vendor‑neutral specs for compress‑upload‑validate‑aggregate cycles and validator scoring endpoints to enable plug‑and‑play decentralized training across clouds.
- Tools/products/workflows: Open API schemas, reference implementations, conformance suites.
- Assumptions/dependencies: Multi‑stakeholder buy‑in; cloud egress/ingress pricing alignment.
- Decentralized inference fabrics for large models (serving/inference)
- Use case: Extend WAN‑efficient sparsity/quantization ideas to coordinate modular experts or sharded inference across diverse nodes, lowering serving cost via community resources.
- Tools/products/workflows: Router/gating services, low‑bit communication paths, load/latency‑aware scheduling.
- Assumptions/dependencies: Latency tolerance for target use cases; economic incentives for always‑on serving nodes.
- Carbon‑aware, price‑responsive scheduling for permissionless runs (energy/green computing)
- Use case: Shift compute/communication windows to low‑carbon or low‑cost electricity periods; leverage local offloading and dynamic participation to exploit renewable availability.
- Tools/products/workflows: Carbon telemetry integration, scheduler that adapts H (inner steps) and round timing, reward multipliers for green windows.
- Assumptions/dependencies: Reliable carbon intensity data; participant location disclosure (privacy‑preserving); fairness in rewards.
- Provenance and auditability of training contributions (governance, risk/compliance)
- Use case: On‑chain or verifiable off‑chain logs of who contributed which updates, when, and with what quality, forming training provenance trails for audits and model cards.
- Tools/products/workflows: Immutable metadata registries, validator‑signed receipts, contribution fingerprints.
- Assumptions/dependencies: Privacy and IP considerations; legal recognition of cryptographic audit trails.
- Data cooperatives with quality‑weighted rewards (data economy)
- Use case: Communities curate datasets and receive rewards proportionate to validated training impact (LossScore deltas on assigned data), aligning incentives for data quality.
- Tools/products/workflows: Dataset assignment and watermarking, per‑dataset scoring, cooperative governance and payouts.
- Assumptions/dependencies: Data licensing/enforcement; manipulation‑resistant scoring; sustainable funding.
- Internet‑scale model merging and ensemble training (software, research)
- Use case: Train diverse replicas with low‑bandwidth updates and periodically merge/average (e.g., WASH/model merging) to improve robustness and reduce single‑run risk.
- Tools/products/workflows: Sparse update tracking, merge schedulers, layer‑wise or mask‑based merging tools.
- Assumptions/dependencies: Stable convergence with heterogeneous recipes; evaluation to detect regressions post‑merge.
- Sector‑specific foundation models at sub‑hyperscaler budgets (biotech, law, engineering)
- Use case: Industry consortia train high‑quality vertical models (e.g., scientific, legal) by pooling WAN‑connected compute and adopting annealing + SFT recipes.
- Tools/products/workflows: Shared pretraining corpora, annealing to high‑quality domain data, staged SFT with replay to protect base capabilities.
- Assumptions/dependencies: Curated domain datasets; sustained multi‑party coordination; governance of IP and access.
Notes on feasibility across applications:
- Performance/scale: The reported 72B/1.1T‑token run evidences viability at high scale; further heterogeneity (older GPUs, mobile/edge) requires engineering and scheduling research.
- Security/privacy: Permissionless participation is not inherently privacy‑preserving; sensitive domains will require DP/secure aggregation/robust aggregation advances.
- Economics: Object storage egress/ingress and on‑chain costs must be modeled; rewards must reflect energy and hardware depreciation.
- Governance: Open participation benefits from sybil resistance, peer reputation, and transparent validator logic; enterprises may replace blockchain with internal identity and audit systems.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update in Adam. "AdamW's cosine decay schedule uses a peak learning rate of "
- all-gather: A collective communication operation that gathers data from all peers so each has the full set. "which requires an all-gather operation over the small pseudo-gradients"
- all-reduce: A collective operation that reduces (e.g., sums) data across peers and broadcasts the result back. "combining DiLoCo with int8 all-reduce to reduce cross-node communication"
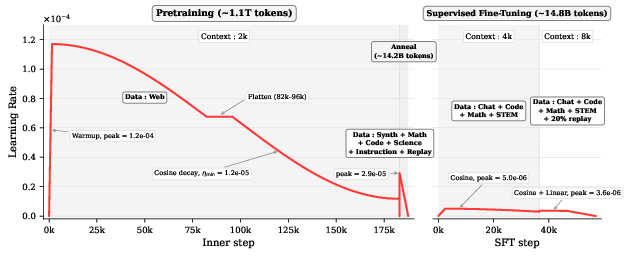
- annealing phase: A later training phase that switches to a higher-quality data mixture to refine the model. "while the annealing phase uses higher-quality data"
- Bittensor blockchain: A decentralized blockchain network used to coordinate and incentivize compute contributors. "run on top of the Bittensor blockchain under Subnet 3."
- chunk-wise Top-: Selecting the top- elements within fixed-size chunks to sparsify updates with lower index overhead. "SparseLoCo instead uses a chunk-wise Top- operator"
- Cloudflare R2: A cloud object storage service used as the communication backbone for uploads/downloads. "we utilize object storage (specifically Cloudflare R2) as the communication backbone."
- compute utilization: The fraction of time spent doing computation (vs. communication/idle) during training. "This corresponds to a compute utilization of for the 72B model."
- cosine decay schedule: A learning-rate schedule that follows a cosine curve from a peak to a minimum. "AdamW's cosine decay schedule uses a peak learning rate of "
- DiLoCo: A distributed low-communication training method using local updates between synchronizations. "outperforming dense baselines (e.g., DiLoCo~\cite{diloco,scalingdiloco})"
- error-feedback: A mechanism that accumulates the untransmitted part of an update to be sent later, mitigating sparsification loss. "uses Top- sparsification, error-feedback, and quantization"
- error-feedback buffer: The state that stores accumulated residuals not transmitted in the current round. "the error-feedback buffer can be offloaded."
- error-feedback decay: A factor controlling how much of the previous error-feedback state is retained each round. "SparseLoCo uses error-feedback decay "
- Fully Sharded Data Parallel (FSDP): A parallelism method that shards model parameters, gradients, and optimizer states across GPUs to save memory. "we use dynamic Fully Sharded Data Parallel (FSDP) across all local GPUs"
- FSDP2: A newer implementation/variant of FSDP used to improve efficiency and scalability. "Training runs in bfloat16 with FSDP2, gradient checkpointing, and torch.compile."
- Gauntlet: A blockchain-coordinated validator/reward mechanism for permissionless training with untrusted peers. "Gauntlet is a mechanism for rewarding peers for contributing compute to the run and incentivizing honest participation."
- gradient checkpointing: A memory-saving technique that recomputes activations during backprop to lower GPU memory usage. "with FSDP2, gradient checkpointing, and torch.compile."
- grouped-query attention (GQA): An attention variant where multiple query heads share key/value projections to reduce memory/compute. "with grouped-query attention (GQA)~\cite{ainslie2023gqa}"
- information-theoretic lower bound: The theoretical minimum number of bits required to encode a given selection or message. "the information-theoretic lower bound for encoding the selected indices is"
- inner optimizer: The optimizer used for local steps on each peer between communication rounds. "runs steps of an inner optimizer (e.g., AdamW)"
- key-value (KV) heads: Attention heads dedicated to key/value projections, often fewer than query heads in GQA. "with 8 key-value (KV) heads"
- LossScore: A validator metric computed from loss improvements to evaluate the contribution of a peer’s update. "The main evaluation signal, , comes from forwarding small batches of data"
- median norm scaling: Normalizing contributions by the median of their norms to prevent any single update from dominating. "Pseudo-gradient contributions are scaled relative to their median norm"
- nested tensors: A data structure for variable-length sequences without packing in PyTorch. "Sequences are variable-length (no packing), handled via nested tensors."
- object storage: A storage model that manages data as objects (blobs) accessible via keys/URLs, suitable for large-scale distribution. "we utilize object storage (specifically Cloudflare R2) as the communication backbone."
- OpenSkill ranking: A skill/rating system used to stabilize participant scores over time under randomness. "maintaining a persistent OpenSkill~\cite{joshy2024openskill} ranking over time to stabilize scores"
- outer optimizer: The optimizer step applied after aggregating peer updates to advance the global model. "a constant learning rate of for the outer optimizer"
- Pareto-optimal: Achieving an optimal trade-off where improving one objective (e.g., communication) worsens another (e.g., performance). "known for its Pareto-optimal performance-communication tradeoff."
- permissionless participation: Open participation without prior approval or whitelisting. "permissionless participation supported by a live blockchain protocol."
- pre-tokenize: To convert raw text into tokens offline before training to reduce runtime overhead. "we pre-tokenize all data and host shards on object storage."
- pre-training replay: Mixing a portion of pre-training data during fine-tuning to prevent forgetting. "and pre-training replay data from natural web text"
- pseudo-gradients: Compressed model updates (parameter differences) treated like gradients for aggregation. "communicates heavily compressed and 2-bit-quantized pseudo-gradients"
- quantization (2-bit): Compressing numerical values to low-bit representations to reduce communication. "and 2-bit quantization of transmitted values."
- Rotary Position Embedding (RoPE): A positional encoding technique that applies rotations to query/key vectors. "Rotary Position Embedding (RoPE) with base frequency "
- SentencePiece tokenizer: A subword tokenization method used to build the model’s vocabulary. "Tokenization uses the Gemma 3 SentencePiece tokenizer"
- sharding: Partitioning large tensors (parameters, gradients, optimizer states) across devices or nodes. "to shard model parameters, gradients, and the inner optimizer state."
- SparseLoCo: A communication-efficient local-update optimizer using sparsification, quantization, and error-feedback. "SparseLoCo is a recently introduced communication-efficient optimizer"
- Subnet (Bittensor): A sub-network within the Bittensor blockchain used to organize tasks/participants. "under Subnet 3."
- Supervised Fine-Tuning (SFT): Post-training on labeled/instruction data to adapt a base model for chat or tasks. "we perform a short B-token Supervised Fine-Tuning (SFT) stage"
- tensor parallelism (TP): Splitting tensor dimensions of a model across multiple devices to scale training. "such as tensor parallelism (TP) and fully sharded data parallelism (FSDP)"
- tied token embeddings: Sharing weights between input token embeddings and the output LM head. "and tied token embeddings and LM head weights."
- Top- sparsification: Keeping only the largest-magnitude elements of an update to reduce communication. "uses Top- sparsification, error-feedback, and quantization"
- trustless compute network: A network where participants need not trust each other due to external validation and incentives. "one of the first to run on a trustless compute network."
- validator: A coordinating node that scores, selects, and broadcasts participant updates each round. "by introducing a validator that scores submitted pseudo-gradients"
- whitelisted participants: Pre-approved contributors allowed to join a training run. "have only been trained with whitelisted participants."
Collections
Sign up for free to add this paper to one or more collections.

