- The paper introduces GWTF, a decentralized framework that tolerates node churn and optimizes LLM training through flow-based microbatch routing.
- It employs a novel local-knowledge optimization algorithm using simulated annealing, achieving up to 45% training time reduction and 30% throughput gains.
- The framework demonstrates near-optimal performance compared to centralized schemes, minimizing GPU waste even under crash conditions.
Churn-Tolerant Decentralized Training of LLMs with GWTF
Introduction and Motivation
The paper introduces GWTF (Go With The Flow), a decentralized framework for training LLMs on heterogeneous, crash-prone volunteer nodes. The motivation stems from the prohibitive cost and resource requirements of centralized LLM training, which restricts participation to well-funded organizations. GWTF addresses the challenges of node churn, network instability, and resource heterogeneity, enabling collaborative training across globally distributed clients with partial system knowledge.
GWTF operates in a partially synchronous network of nodes, each with individual memory and communication constraints. Nodes can act as data holders or relays, and may join, leave, or crash at any time, including during critical forward or backward passes. The core objective is to maximize throughput and minimize training time under churn and heterogeneity, without sacrificing convergence.
The training process is modeled as a minimum cost flow problem, where each microbatch is routed through a sequence of nodes (stages), and the cost of a flow between nodes i and j is defined as:
di,j=2ci+cj+2λi,j+λj,i+βi,j+βj,i2⋅size
where ci is computation time, λi,j is network latency, and βi,j is bandwidth.
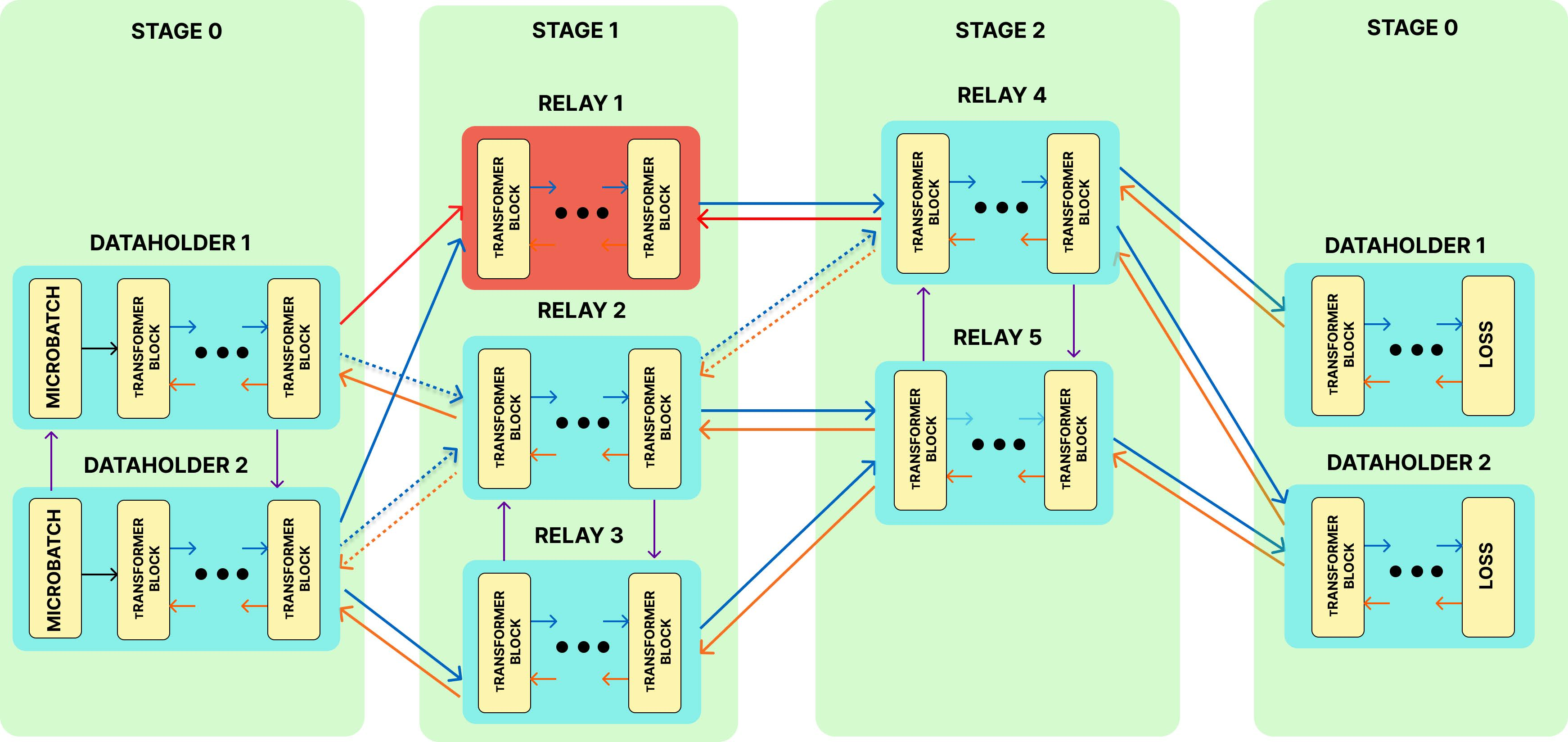
Figure 1: Crash-recovery during decentralized training of an LLM with GWTF, illustrating rerouting and microbatch exchanges after relay node failure.
Decentralized Flow Optimization
GWTF employs a novel decentralized flow algorithm that leverages only local knowledge to construct and optimize microbatch pipelines. The algorithm iteratively minimizes the maximum cost of flows between nodes, adapting to dynamic membership and resource availability. Key subprocedures include:
- Request Flow: Nodes with available capacity request flows from downstream peers, preferring those that minimize cumulative cost.
- Request Change: Nodes in the same stage may swap downstream peers if it reduces the objective function (max cost).
- Request Redirect: Nodes opportunistically reroute flows through themselves if it yields lower cost.
Simulated annealing is used to escape local minima, accepting cost-increasing changes with probability e(costcurrent−costnew)/T, where T is a temperature parameter.
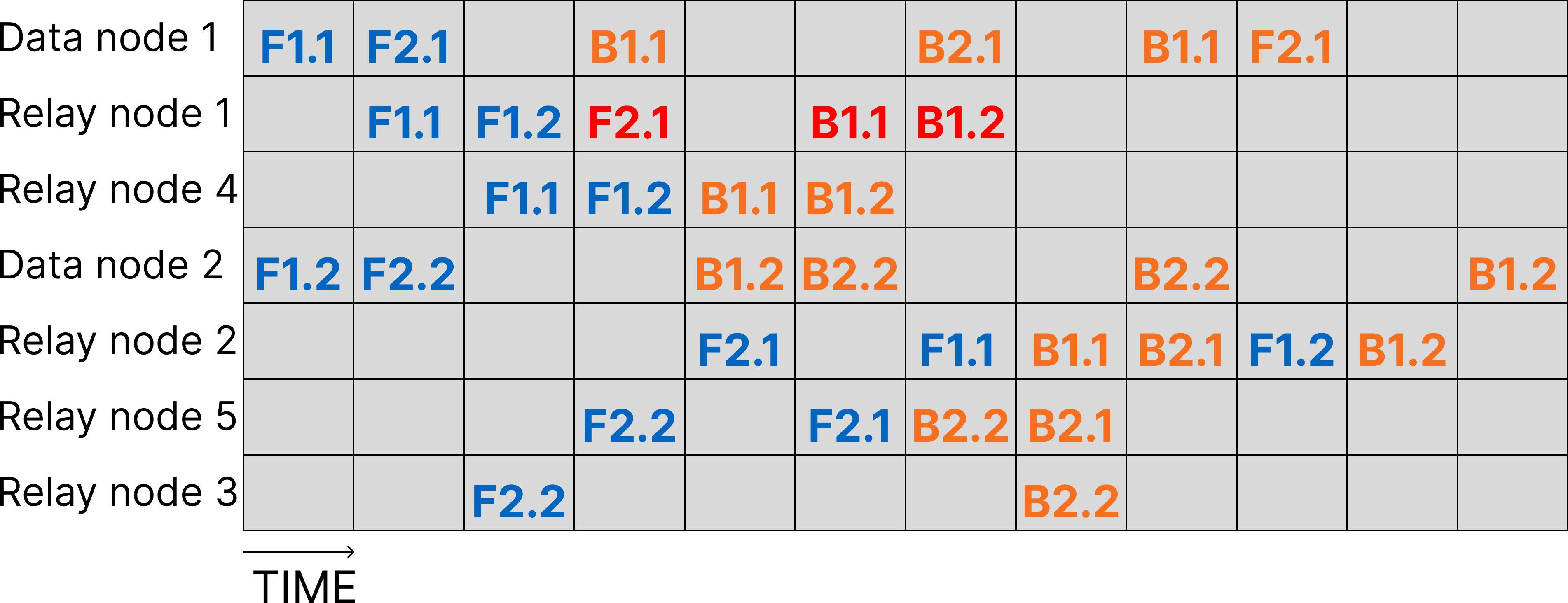
Figure 2: Execution scenario of decentralized LLM training, showing forward and backward passes and the impact of node crashes.
Node Addition and Bottleneck Expansion
GWTF dynamically assigns joining nodes to the most utilized (bottleneck) stage, as determined by a leader elected among data nodes. The leader ranks stages by utilization and incorporates new nodes with the highest capacity into the most constrained stages, thereby expanding throughput.
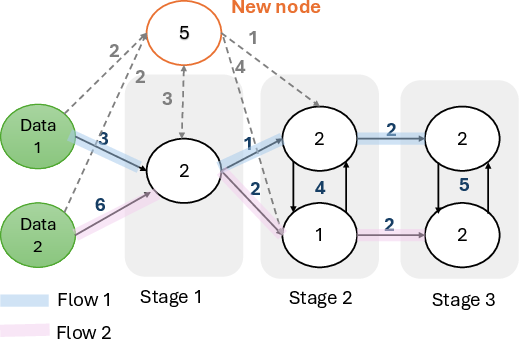
Figure 3: A joining node being added to the bottleneck stage, increasing system throughput and shifting the bottleneck downstream.
Crash Tolerance and Recovery
GWTF provides robust crash recovery for both forward and backward passes. Forward pass failures trigger immediate rerouting to alternative peers, while backward pass failures utilize stored microbatch paths to restore the pipeline with minimal recomputation. This contrasts with prior work (e.g., SWARM), which requires full pipeline recomputation after backward failures, resulting in significant resource waste.
Training-Aggregation Synchronization
To ensure parameter consistency, GWTF synchronizes training and aggregation phases across nodes. Aggregation is initiated by a leader and propagated through the network, with nodes broadcasting and collecting model weights within their stage. The transition between phases is signaled via CAN TAKE messages, enabling efficient iteration management.
Empirical Evaluation
Experiments were conducted on LLaMa- and GPT-like models (300M–7B parameters) using a private cluster simulating geo-distributed nodes with heterogeneous capacities and network conditions. Key findings include:
- Training Time Reduction: GWTF achieves up to 45% reduction in training time under 10% crash rates compared to SWARM.
- Throughput Improvement: Throughput increases by up to 30% in heterogeneous settings.
- Resource Utilization: GWTF wastes almost zero GPU time, whereas SWARM incurs significant waste due to pipeline recomputation.
- Model-Agnosticism: Comparable gains are observed for both LLaMa and GPT architectures.
- Near-Optimality: GWTF approaches the performance of centralized, communication-optimal schedules (DT-FM), with only a 13% gap in end-to-end training time, but with vastly superior scalability and decentralization.
(Figure 4)
Figure 4: Loss convergence of GWTF matches centralized training, confirming theoretical guarantees.
(Figure 5)
Figure 5: Average cost per microbatch in flow tests, demonstrating GWTF's superiority over greedy baselines in heterogeneous settings.
Implications and Future Directions
GWTF demonstrates that decentralized, crash-tolerant LLM training is feasible and efficient, even under high churn and resource heterogeneity. The framework is extensible to other architectures requiring pipeline or data parallelism, such as Vision Transformers and large CNNs. However, several open challenges remain:
- Byzantine Fault Tolerance: The current model does not address adversarial nodes; future work must incorporate robust aggregation and validation mechanisms.
- Decentralized Checkpointing: Efficient checkpointing without stable central nodes is an unsolved problem in this context.
- Incentive Mechanisms: Integrating blockchain-based rewards could further democratize participation.
- Generalization to Other Domains: The flow-based approach is applicable beyond LLMs, potentially benefiting large-scale collaborative training in other modalities.
Conclusion
GWTF provides a practical, scalable solution for decentralized LLM training, leveraging flow optimization and robust crash recovery to maximize throughput and minimize resource waste. The framework achieves strong empirical results, approaching centralized optimality while tolerating high churn and heterogeneity. GWTF lays the groundwork for democratized, collaborative model development, with broad applicability and significant potential for future research in decentralized AI systems.

