- The paper introduces a fully open-source 2B-parameter LLM pretraining pipeline that integrates quantile data benchmarking and multi-phase quality sampling.
- It details a Spark-based processing pipeline with C++ acceleration to ensure numerical stability and reproducibility under constrained hardware.
- The work demonstrates improved benchmark performance and practical efficiency for resource-limited LLM research compared to similar open-weight models.
PCMind-2.1-Kaiyuan-2B: A Fully Open-Source, Resource-Efficient LLM Pretraining Pipeline
Motivation and Scope
The technical report "PCMind-2.1-Kaiyuan-2B Technical Report" (2512.07612) presents a comprehensive fully open-source 2B-parameter LLM, detailing both model release and transparent training methodology. The authors explicitly target the knowledge-production gap between the proprietary practices of industry-scale LLMs and the limited-resource, open-weight initiatives in academia. All assets, including model weights, datasets, and code, are available under Apache 2.0, prioritizing genuine reproducibility and an unrestricted research license.
Central challenges addressed include: (1) systematically comparing and mixing heterogeneous open-source pretraining corpora amidst drastic feature, quality, and label variations, and (2) devising data-efficient methods that maximize the utility of sparse, high-quality data under compute and token constraints. The work emphasizes practical solutions for the broader LLM research ecosystem, especially those constrained to limited clusters and commodity hardware.
Quantile Data Benchmarking: Dataset Comparison with Quality Granularity
To inform curriculum and mixture strategy, the authors introduce "Quantile Data Benchmarking" as a systematic, empirical layer over rule-based dataset curation. Given that open datasets (e.g., DCLM-Baseline, FineWeb-Edu) often provide rule-derived or classifier-based quality scores, this approach benchmarks slices of each dataset stratified by quality-score quantiles, rather than simple global filtering. Reference models are trained and evaluated over subsets near selected quantiles, quantifying true utility along the score spectrum for various downstream tasks.
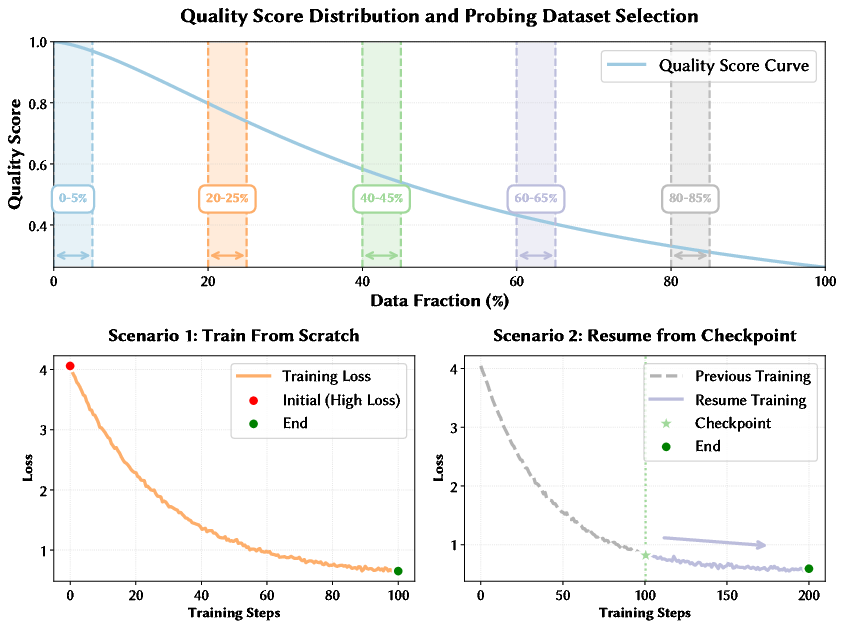
Figure 1: Illustration of the quantile benchmarking process used to probe dataset granularity and guide data selection/mixing policies.
Empirically, this approach reveals marked internal heterogeneity within datasets and capability-dependent superiority (e.g., FineWeb-Edu dominates in knowledge-intensive tasks such as MMLU, while DCLM-Baseline yields higher performance on commonsense/factual benchmarks like WinoGrande).
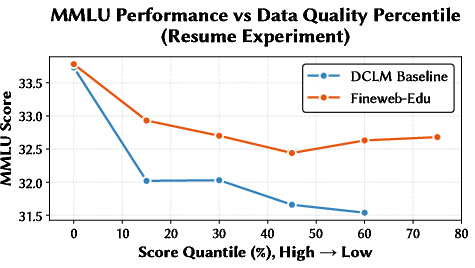
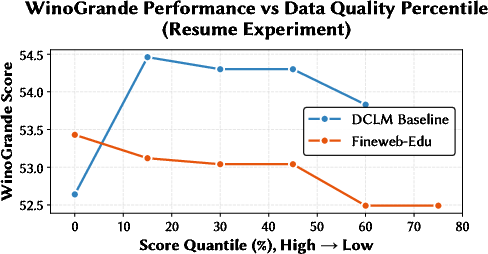
Figure 2: Task-dependent dataset characteristics discovered by quantile benchmarking—FineWeb-Edu is optimal for knowledge benchmarks, DCLM baseline excels at commonsense.
Non-monotonicity is also observed between quality score and final-task performance, motivating reluctance toward naive “higher is always better” sample selection. These results underscore the inadequacy of top-k filtering or singular metric dependence for open-source LLM data curation.
Data Processing Infrastructure and Architectural Stability
Handling the scale and operational diversity of open-source datasets requires robust preprocessing workflows. The report details a Spark-based data processing pipeline (Kai), augmented by native C++ acceleration via Chukonu. This architecture ensures full-yaml pipeline reproducibility, with strong support for deduplication, interleaving, rank-rescaling, and distributed execution.
Under hardware constraints—FP16 clusters with no bfloat16 support—the report carefully addresses numerical instability stemming from pre-norm and residual connection accumulation in standard architectures. As shown in the comparison of activations, unmodified transformer variants suffer from activation explosion and gradient underflow.
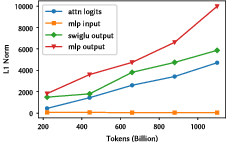
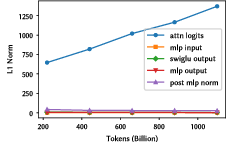
Figure 3: Activation statistics highlight instability in the baseline, motivating FP16-specific architectural interventions.
To ensure stable training, the model stack incorporates sandwich normalization and soft-capping (logits), following recent best practices demonstrated in, e.g., Gemma 2. The result is reliable convergence and prevented numerical over/underflow across curriculum domains (language, code, math).
Multi-Phase, Multi-Domain Curriculum and Strategic Repetition
The model’s core data efficiency gains arise from a phased curriculum. Training proceeds through five phases, transitioning from broad, lower-quality mixtures toward increasing proportions of high-quality, domain-specific, and supervised samples. Each phase involves both domain-level mixture adaptation (e.g., adjusting proportions of Chinese, code, math, SFT), and quality-based selective repetition, where high-quality partitions are repeated more frequently in subsequent phases.
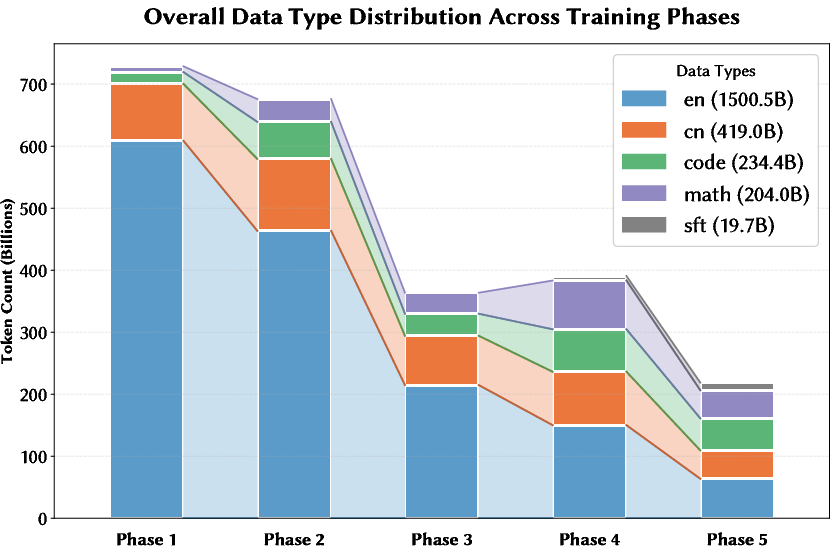
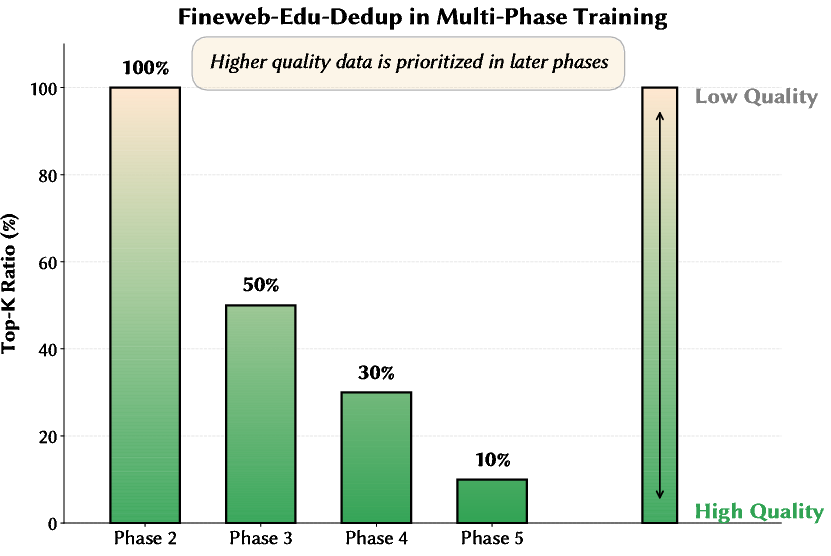
Figure 4: Phase-wise data mixture transitions, showing the curriculum’s progression from broad coverage to focused, high-quality slices.
The multi-dataset curriculum is constructed via a principled rank-rescaling and interleaving process, guaranteeing that quality metrics are preserved across and within datasets, and that mixture ratios respect quantile benchmarking insights.
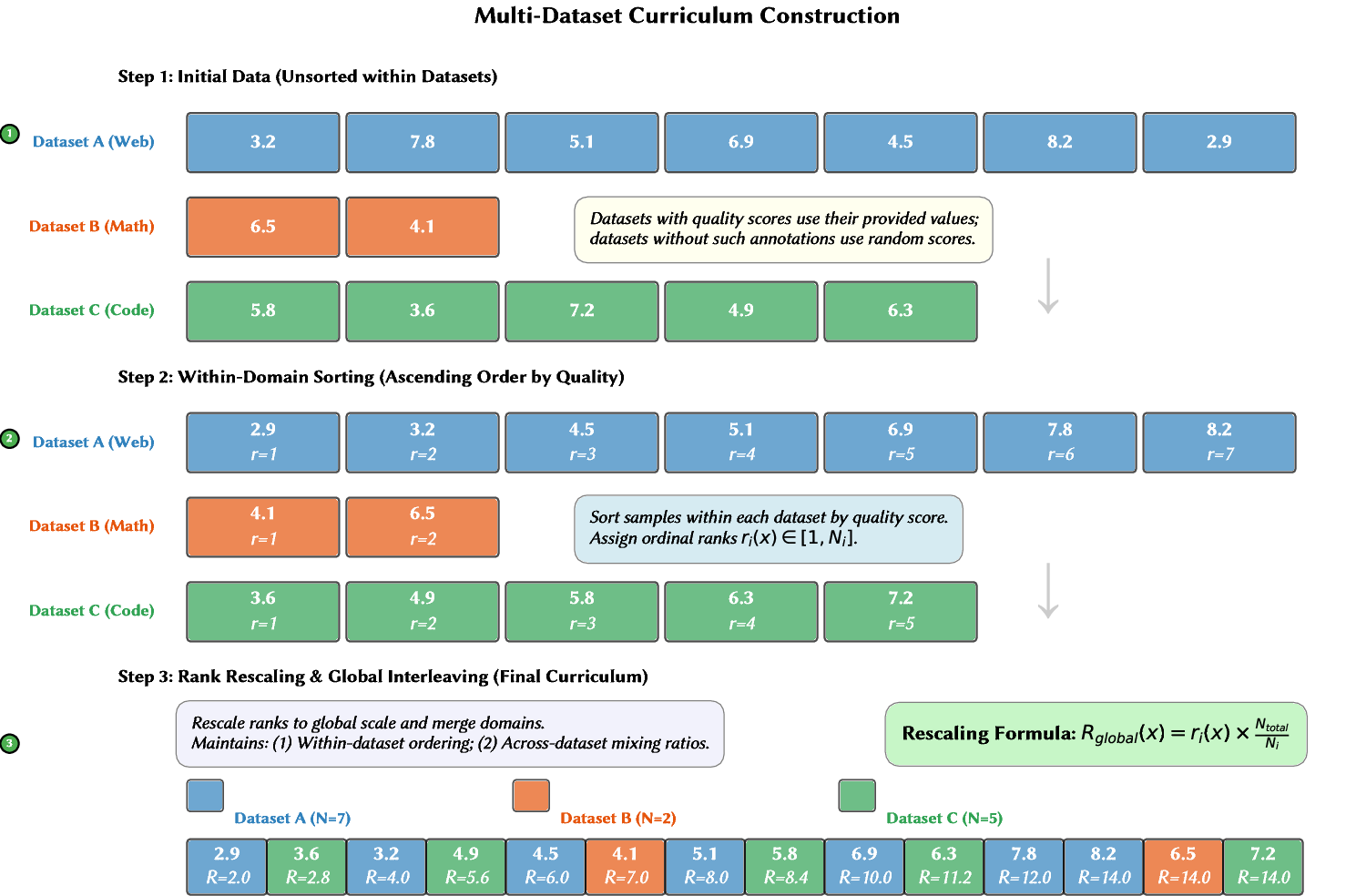
Figure 5: Data flow for curriculum construction—a globally consistent rank is assigned for mixing/shuffling across dataset boundaries.
This curriculum is tightly coupled to an LR schedule optimized for late-phase quality injection, with checkpoint averaging to consolidate gains from the highest-quality steps.
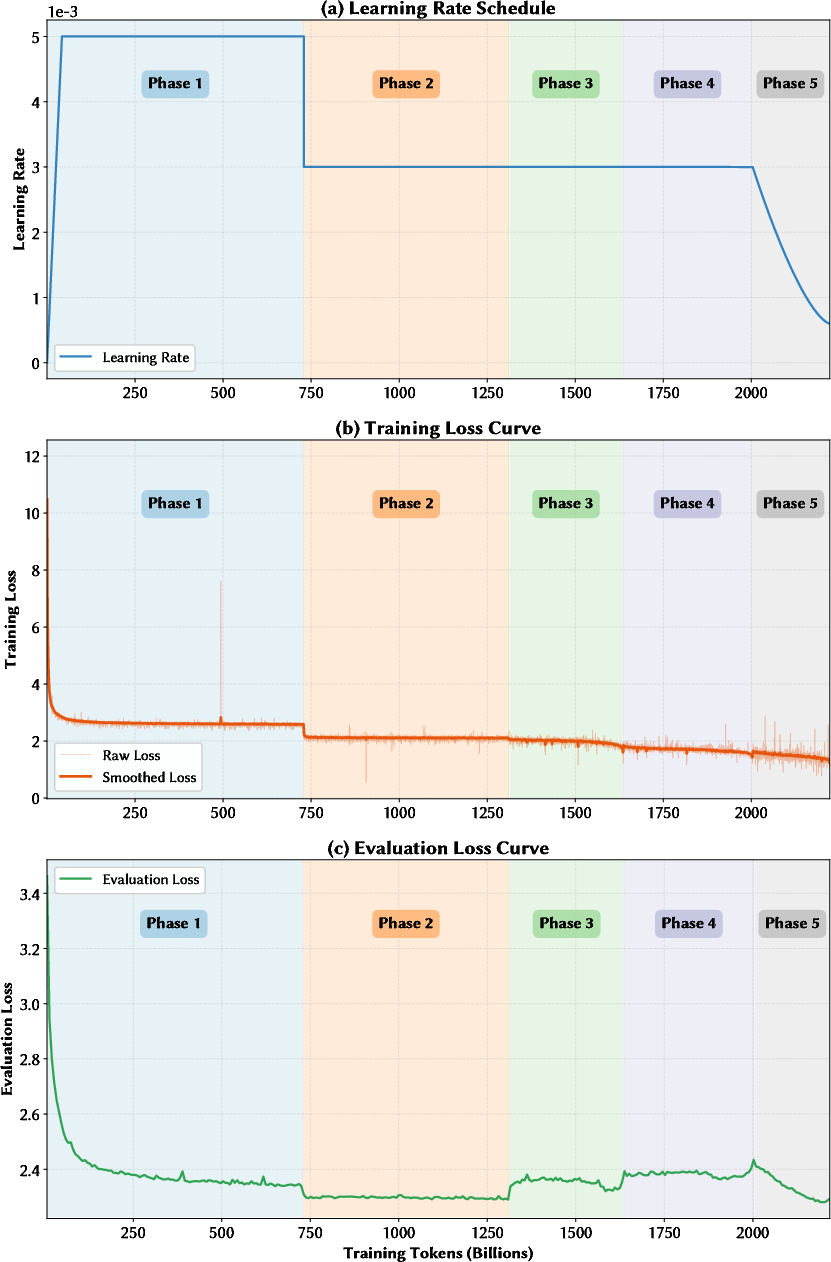
Figure 6: Training dynamics showing phase transitions, LR schedule, and shifts in loss and validation metrics over the curriculum.
Evaluation and Model Positioning
Benchmarks place PCMind-2.1-Kaiyuan-2B ahead of previous fully open-source models at similar parameter scales, and approaching top-tier open-weight models (Qwen2-1.5B, Gemma2-2B, Llama3.2-3B). Strong out-of-domain (Chinese, math, code) and reasoning/knowledge results are reported, especially when considering non-embedding parameter efficiency.
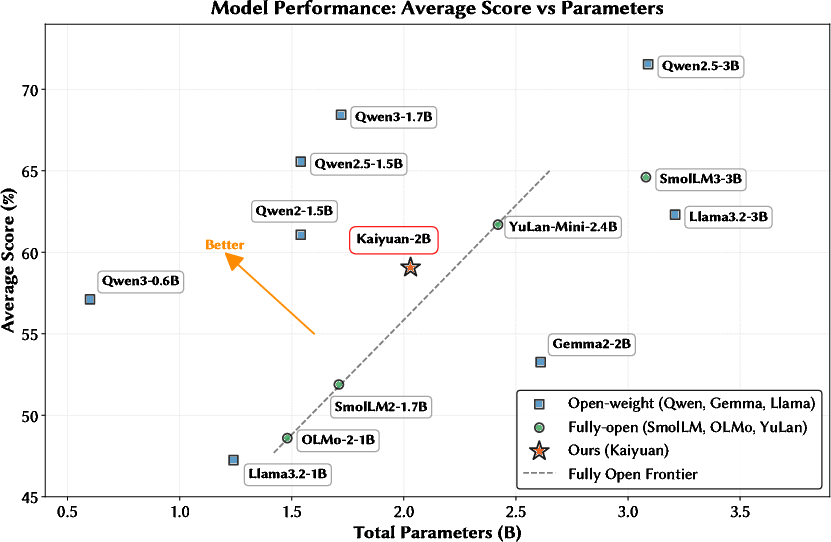
Figure 7: Kaiyuan-2B’s performance advances the open-source model frontier and approaches open-weight baselines of similar size.
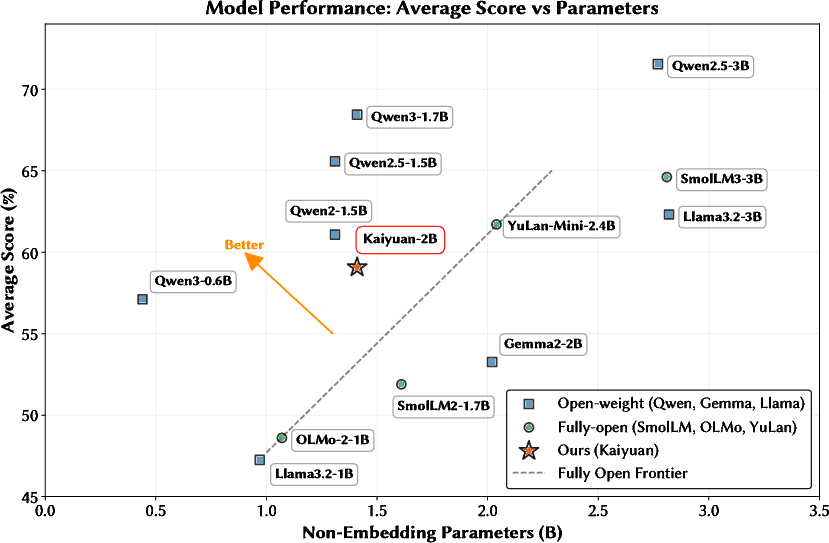
Figure 8: Non-embedding parameter comparison, highlighting architectural and efficiency advantages over open and semi-open competitors.
Notably, for tasks in code synthesis (HumanEval, MBPP), mathematical reasoning (MATH, GSM8K), and Chinese (C-Eval, CMMLU), the model outperforms SmolLM2/3-1.7B/3B and OLMo-2-1B, and approaches or exceeds YuLan-Mini-2.4B despite a considerably smaller data budget.
Practical and Theoretical Implications
Kaiyuan-2B demonstrates that transparent, phased curation, heterogeneity-aware benchmarking, and principled selective repetition offer concrete advances in compute-, data-, and resource-constrained LLM pretraining. The work rejects monolithic, undifferentiated open-data mixing, showing that task-driven benchmarking and dynamic curricula are required to match or approach the efficiency of industry-trained closed models.
Practically, the open-source pipeline enables reproducible, large-scale LLM research on moderate clusters, without access to restricted corpora or proprietary recipes. Theoretically, quantile benchmarking questions the validity of global quality metrics and sets a precedent for capability-specific, empirical dataset utility evaluation.
A natural avenue for future study includes more granular, quantitative frameworks for dataset mixing optimization, theoretical analysis of curriculum/repetition dynamics, and exploration of cross-lingual and low-resource domain adaptation.
Conclusion
PCMind-2.1-Kaiyuan-2B operationalizes a reproducible, fully open-source LLM training pipeline that advances state-of-the-art results at the 2B parameter scale using transparent, resource-efficient strategies. The explicit integration of quantile benchmarking, multi-phase quality-focused sampling, and robust normalization ensures both competitive benchmark performance and credible community reproducibility across computational environments. The model and training pipeline serve as a reference for the next generation of academic LLM exploration and resource-constrained LLM engineering.

