- The paper introduces plan-guided synthetic SFT that overcomes exploration bias in tool use, improving F1 scores by up to 6%.
- It details a four-stage synthetic data pipeline, including cue-injection and trajectory filtering, to enhance plan diversity and exploration depth.
- The approach leverages GRPO and multi-turn reasoning to establish a new SOTA across seven multi-hop and web QA benchmarks.
Introduction
SynPlanResearch-R1 addresses the persistent challenge in training text-based research agents to effectively interleave multi-turn tool use and internal reasoning for open-domain queries. Despite progress in end-to-end reinforcement learning with verifiable rewards (RLVR), empirical results reveal a consistent failure of RLVR to induce deep exploration: research agents terminate too early and exhibit strong biases toward certain tools, notably over-using web_search and under-utilizing crawl_webpage. This exploration deficit, rooted in suboptimal policy initialization, fundamentally stalls the ability of RL to discover sophisticated evidence acquisition strategies.
SynPlanResearch-R1 introduces a plan-guided synthetic data pipeline to induce deep and diverse tool-use exploration during cold-start supervised fine-tuning (SFT). This initialization is shown to be critical for subsequent RLVR, yielding a higher ceiling for policy improvement.
Methodology
The agent operates within a ReAct framework, i.e., alternating cycles of > → <tool_call> → <tool_response>. The action space comprises web_search and crawl_webpage, plus outputting the final answer. Structured annotation enforces adherence to format and provides scaffolding for both training and inference.
Synthetic Data Pipeline
The core innovation is a four-stage plan-driven data synthesis:
- Tool-Plan Generation: For each question, randomized tool-use action plans of length L∼U[Lmin,Lmax] are sampled. The leading action is always web_search; subsequent actions are sampled equiprobably from the available set.
- Cue-Injected Multi-Step Reasoning: At each "think" step, manually curated tool-specific cues are injected as thought prefixes to softly bias the generation toward following the tool plan, while preserving natural ReAct structure.
- Trajectory Filtering: Only trajectories with correct answers and strict format compliance are retained.
- Thought Rewriting: To remove artifacts from synthetic cue injection and enforce linguistic fluency, Claude-based rewriting paraphrases each thought, enhancing data quality for SFT.
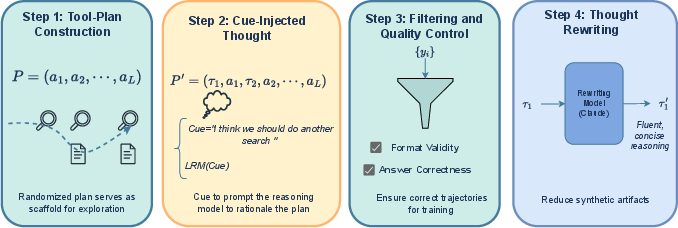
Figure 1: The data synthesis pipeline is driven by randomized tool plans, soft cue injection at each reasoning step, and strict filtering plus thought rewriting.
RL with Group Relative Policy Optimization (GRPO)
The model initialized from plan-guided SFT is further refined with GRPO, a value-network-free policy optimization method. The reward is outcome-based (F1 with ground truth) with additional penalties for format violations. RL training includes several stability tricks: masking policy loss for void (truncated) trajectories, and immediately penalizing tool call schema errors.
Experimental Results
Benchmarks and Setup
Experiments span seven multi-hop and web-intensive question answering benchmarks, including HotpotQA, 2WikiMultihopQA, MuSiQue, Bamboogle, GPQA, WebWalkerQA, and GAIA. Both 8B and 4B Qwen3 models serve as student backbones; synthetic data is generated by a Qwen3-32B LRM.
Main Quantitative Findings
SynPlanResearch-R1 sets a new SOTA across all evaluation suites:
- Qwen3-8B: Average macro-F1 of 0.580, a gain of up to +6.0% over the strongest prior baseline.
- Qwen3-4B: Average macro-F1 of 0.529, outperforming previous best by +5.8%.
Performance increases are consistent across both multi-hop QA and open-domain web tasks, with especially large gains on harder, longer-horizon datasets (e.g., GAIA and WebWalkerQA). Crucially, SynPlanResearch-R1 provides substantial improvements over strong SFT+RL and high-quality hand-curated SFT datasets, demonstrating the specific effectiveness of guided tool plan diversity in overcoming exploration bias.
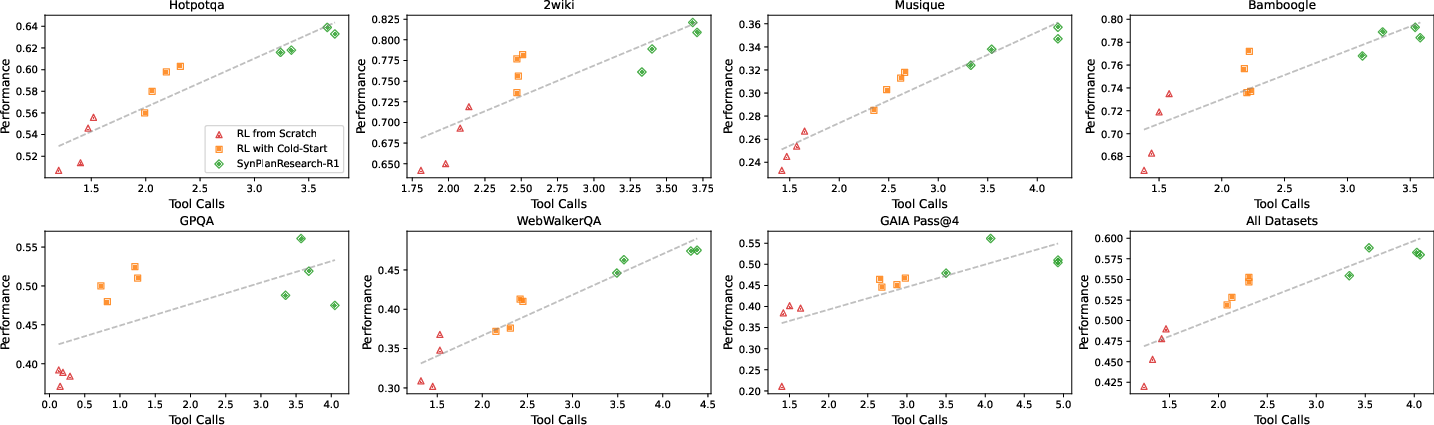
Figure 2: A clear correlation between average tool calls and task performance; deeper exploration (more tool calls) yields higher performance, and only SynPlanResearch-R1 achieves both high exploration and success.
SynPlanResearch-R1 agents consistently make more tool calls per query than RL-from-scratch or vanilla SFT+RL, confirming that the diversity of synthetic trajectories imprints a strong exploration prior. On web-based tasks requiring evidence chaining beyond snippet retrieval, dynamic allocation of exploration budget is observed.
Policy Entropy and Training Dynamics
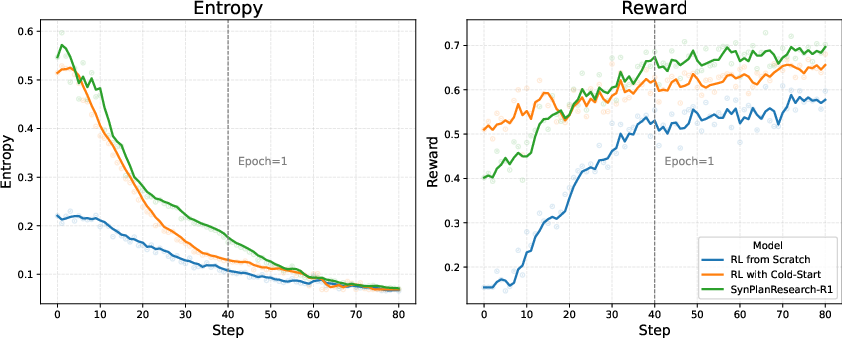
Figure 3: SynPlanResearch-R1 maintains elevated policy entropy and achieves superior long-term reward compared to other RL initialization strategies.
Higher policy entropy under SynPlanResearch-R1 leads to more robust and varied tool use, systematically surpassing baselines, which plateau early due to limited initial diversity.
Ablation Results
- Reducing the tool-use budget or decoding temperature at RL time sharply degrades performance, illustrating the dependence of final success on both deep and diverse exploration.
- Removing cue-injection during plan-based synthesis yields the greatest drop in results, underscoring cues as essential for reliable plan adherence and effective exploration priors.
- Eliminating access to crawl_webpage dramatically reduces accuracy on tasks requiring deeper retrieval, demonstrating the critical role of multi-tool composition.
Effects of Prompting Strategies
Adding plan specification to the ReAct prompt increases tool call diversity, but only cue-injection reliably achieves high plan-following accuracy (76.9%) and robust exploration; plan specification alone is insufficient for consistent protocol execution.
Practical and Theoretical Implications
SynPlanResearch-R1 demonstrates that robust policy initialization is essential for unlocking the capacity of RLVR on tool-using web agents. Deep, plan-driven synthetic SFT trajectories act as a structural prior for exploration, overcoming local minima induced by weak or biased cold-start protocols. This result is strongly aligned with recent work emphasizing the interplay between entropy, exploration, and sample efficiency in long-horizon agentic RL.
Practically, SynPlanResearch-R1 provides a blueprint for constructing robust LLM-driven research agents with minimal handcrafted data, and is readily compatible with scalable RL closures such as GRPO or PPO. The pipeline can be extended to more complex tool sets and instantiated for other domains requiring compositional tool use.
Theoretically, the work suggests that RL-driven skill acquisition in LLMs is fundamentally constrained by the diversity and task-aligned structure of their initial demonstration distribution. Sufficient plan diversity paired with soft action guidance (rather than hard trajectory specification) is critical for transferring exploration capacity into downstream RL improvement.
Conclusion
SynPlanResearch-R1 establishes that tool-plan-guided synthetic data is critical for robust web research agent policy learning. It systematically overcomes the premature convergence and tool-use bias prevalent in RLVR by imprinting deep and compositional exploration priors into cold-start SFT, verified by both quantitative and ablation results. The approach advances the state-of-the-art in multi-turn, tool-using agents and provides principled insight into the components necessary for effective RL in this regime. Future directions include extension to richer, domain-specific toolsets and automated plan generation to further improve agent generality and robustness.