mlx-snn: Spiking Neural Networks on Apple Silicon via MLX
Abstract: We introduce mlx-snn, the first spiking neural network (SNN) library built natively on Apple's MLX framework. As SNN research grows rapidly, all major libraries -- snnTorch, Norse, SpikingJelly, Lava -- target PyTorch or custom backends, leaving Apple Silicon users without a native option. mlx-snn provides six neuron models (LIF, IF, Izhikevich, Adaptive LIF, Synaptic, Alpha), four surrogate gradient functions, four spike encoding methods (including an EEG-specific encoder), and a complete backpropagation-through-time training pipeline. The library leverages MLX's unified memory architecture, lazy evaluation, and composable function transforms (mx.grad, mx.compile) to enable efficient SNN research on Apple Silicon hardware. We validate mlx-snn on MNIST digit classification across five hyperparameter configurations and three backends, achieving up to 97.28% accuracy with 2.0--2.5 times faster training and 3--10 times lower GPU memory than snnTorch on the same M3 Max hardware. mlx-snn is open-source under the MIT license and available on PyPI. https://github.com/D-ST-Sword/mlx-snn
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces “mlx-snn,” a new software library that lets people build and train spiking neural networks (SNNs) fast on Apple computers with Apple Silicon chips (like M1–M3) using Apple’s MLX framework. SNNs are brain-inspired AI models that communicate with quick “spikes” (short signals) instead of smooth, always-on signals. Until now, most SNN tools worked best with NVIDIA GPUs or PyTorch, not natively on Apple hardware. mlx-snn fills that gap.
What were the authors trying to do?
They had three main goals:
- Make a full-featured SNN toolkit that works natively and efficiently on Apple Silicon using MLX.
- Provide familiar tools so people who already use popular SNN libraries (like snnTorch) can switch easily.
- Test whether this Apple-first approach can be both fast and accurate on a standard task (recognizing hand‑written digits in the MNIST dataset).
How did they do it? (In simple terms)
Think of SNNs like a group of people sending short beeps instead of talking nonstop. The timing and number of beeps carry the message. Training them is tricky because “beeps” are like on/off switches, and it’s hard for standard training methods to deal with sharp on/off jumps.
Here’s the approach in everyday language:
- Apple MLX basics:
- Unified memory: The CPU and GPU share the same “desk,” so you don’t waste time passing papers back and forth.
- Lazy evaluation: MLX plans the whole job and then does it in a smart, optimized way—like writing a to-do list first, then completing tasks efficiently.
- Composable transforms: Built-in tools (like mx.grad) automatically calculate how to adjust the network during training.
- Library features (kept simple and flexible):
- Different “neuron types”: Like different ways a “beeping” cell behaves—some “leak” energy over time, some adapt if they beep too much, and some mimic more complex brain behavior.
- Surrogate gradients: A training trick that smooths the sharp on/off spike behavior, so learning still works. Imagine filing down a sharp cliff into a gentle ramp to climb.
- They used a practical workaround (called an STE pattern) to fit MLX’s current limits, so gradients still flow correctly during training.
- Encoding methods: Ways to turn normal data into spikes:
- Rate coding (how often you beep),
- Latency coding (how quickly you beep after a signal),
- Delta modulation (beep only when something changes),
- An EEG-specific encoder for brainwave data.
- A full training pipeline “unrolls over time,” like watching a short video of signals rather than looking at a single photo. This fits how SNNs naturally work, because timing matters.
- Easy to adopt:
- The API (how you code with it) is similar to snnTorch, so moving code over is straightforward.
What did they find?
They tested their library on MNIST, a classic dataset of 28×28 grayscale images of hand-written digits (0–9).
- Performance:
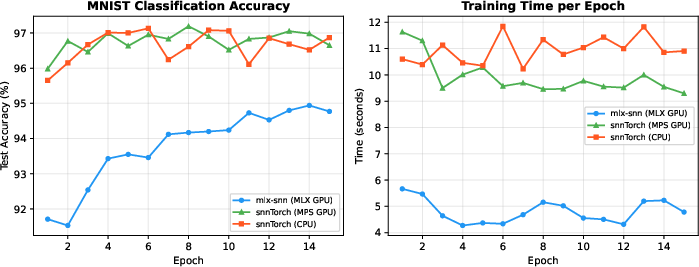
- Accuracy: Up to 97.28% correct on MNIST (best run).
- Speed: Training was about 2.0–2.5× faster per epoch than snnTorch on the same Apple M3 Max laptop.
- Memory: Used 3–10× less GPU memory than snnTorch on the same machine.
- Comparisons:
- snnTorch sometimes had slightly higher accuracy (best around 98%), but mlx-snn was faster and more memory-efficient on Apple Silicon.
- The small accuracy gap (about 0.7–1%) likely comes from the training trick (the surrogate gradient workaround) rather than the hardware.
- Extra checks:
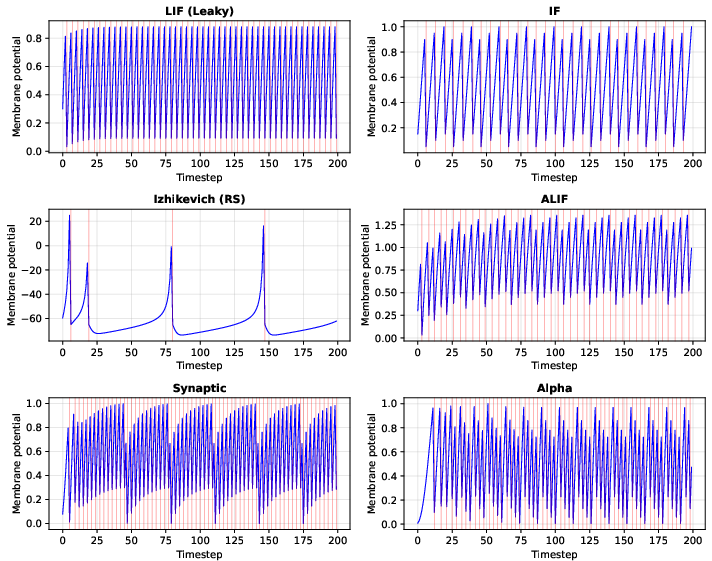
- They also showed that all six neuron models behave as expected over time.
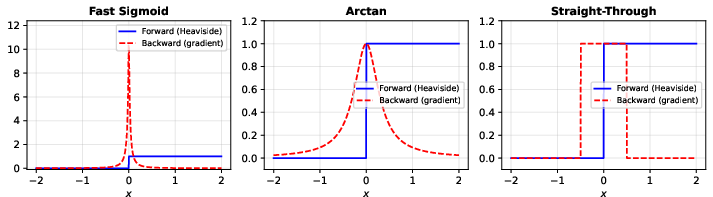
- They compared different surrogate gradient shapes and found that some smooth functions (like fast sigmoid and arctan) work well, while a basic straight-through version works worse unless tuned.
Why is this important?
- Makes SNNs practical on Macs: If you use a MacBook Pro or Mac Studio with Apple Silicon, you can now train SNNs efficiently without needing NVIDIA GPUs or cloud services.
- Energy and timing advantages: SNNs can be more energy-efficient and are good at handling timing-based signals (like sound, events, or EEG data), so this library opens doors for research in areas like wearables, robotics, and brain–computer interfaces.
- Faster experiments: The speed and memory savings mean researchers can try more ideas quickly on their local machines.
What does this mean for the future?
- The library is open-source (MIT license) and on PyPI (you can install it with “pip install mlx-snn”).
- The team plans to add more features (like neuromorphic datasets, just-in-time compilation in more places, and bigger benchmarks).
- As MLX adds more advanced tools for custom gradients, the small accuracy gap should shrink.
- Overall, this work lowers the barrier for students and researchers to explore brain-inspired AI on Apple hardware.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper for future researchers to address:
- Benchmark breadth: Validation is limited to MNIST with a simple 2-layer MLP; no results on larger or more complex datasets (e.g., Fashion-MNIST, CIFAR-10/100, TinyImageNet) or neuromorphic/event datasets (N-MNIST, DVS Gesture, SHD).
- Architecture coverage: No evaluation of spiking CNNs, residual networks, recurrent SNNs, or graph/transformer-style spiking architectures; library support and performance for convolutional spiking layers are not demonstrated.
- Surrogate gradient fidelity: The STE-based surrogate workaround introduces a consistent ~1% accuracy gap vs. snnTorch; it remains unverified whether native custom VJPs in MLX will eliminate this gap and under what conditions.
- Gradient correctness: The claim that the STE construction is “numerically equivalent” to a custom VJP lacks formal proof and thorough empirical validation across tasks and architectures.
- Parameter sensitivity: No systematic study of surrogate gradient hyperparameters (e.g., k, α, s) on convergence, stability, and accuracy; default choices may be suboptimal and dataset dependent.
- Long-horizon training: Stability (vanishing/exploding gradients), memory behavior, and performance for large timesteps (large T) are not analyzed; no support/evaluation of truncated BPTT or checkpointing across time.
- mx.compile integration: JIT compilation is not applied due to Python control flow; it is unknown how to refactor temporal loops to leverage mx.compile (e.g., via static loops, scans) and what speedups are achievable.
- vmap/scan-style transforms: The benefits and feasibility of replacing Python for-loops with MLX transforms (e.g., using functional scans) for better compilation and memory performance are untested.
- Mixed precision and dtypes: No experiments on bfloat16/float16 performance, numerical stability, or memory/throughput trade-offs; dtype support and default precision choices are unspecified.
- Energy and efficiency: Despite highlighting event-driven advantages, there are no energy or power measurements on Apple Silicon (e.g., per-epoch energy, performance-per-watt) or comparisons to CPU/MPS/CUDA baselines.
- Memory metrics comparability: Peak “GPU allocator memory” for MLX (Metal) vs. PyTorch (MPS) may not be directly comparable; methodology for measuring memory and intermediate activation footprint is not standardized.
- Seed control and variance: Results are reported as the best test accuracy per run; variability across random seeds, statistical significance, and confidence intervals are not reported.
- Inference latency and throughput: Only training time per epoch is reported; no measurements of inference latency, throughput, or batch size/T scaling (critical for deployment).
- Real-time/streaming support: The library’s suitability for streaming inputs (e.g., real-time EEG or DVS events), variable-length sequences, and low-latency inference paths is unexamined.
- Dataset loaders: Neuromorphic dataset loaders (N-MNIST, DVS Gesture, SHD) are not implemented; data pipelines for event streams (address-event representation) and augmentation are absent.
- Encoder validation: The EEG-specific encoder and delta modulation encoding are not empirically validated on real EEG or other time-series datasets; robustness to noise and parameterization guidelines are missing.
- Biological features: No support for refractory periods, synaptic delays, conductance-based models, or heterogeneity across neurons/synapses; impact of these mechanisms on performance and training is unexplored.
- Output-layer reset policy: The choice of “no reset” at the output is not compared against other resets; the effect of reset mechanisms on accuracy and gradient flow is not quantified.
- Learnable dynamics: While some dynamics (e.g., β) can be learnable, there is no analysis of identifiability, training stability, or performance impact of learning neuron and synapse parameters.
- Discretization details: Numerical integration details for Izhikevich and other ODE-based models (time step Δt, discretization scheme, stability constraints) are not stated or evaluated for accuracy vs. speed trade-offs.
- API parity: The extent of snnTorch API compatibility (coverage of modules, layers, state handling, delays, recurrent connections, neuron-level regularizers) is not systematically validated with a test suite.
- Comprehensive baselines: Benchmarks against other libraries (Norse, SpikingJelly, Lava) and CUDA backends are missing; comparisons are limited to snnTorch on MPS/CPU.
- Hardware diversity: Performance and memory evaluations are restricted to a single M3 Max configuration; scaling across Apple Silicon generations (M1/M2/M3 variants) and memory sizes is unknown.
- Distributed/multi-device: No discussion of multi-device or distributed training, even if limited on Apple hardware; implications for large-scale training are unaddressed.
- Determinism and reproducibility: Determinism under MLX/MPS (kernel scheduling, randomness) and cross-run reproducibility guarantees are not assessed.
- Regularization and training tricks: Effects of common techniques (dropout in SNNs, weight decay, gradient clipping, noise injection) are not studied; best-practice training recipes are absent.
- Event sparsity exploitation: The implementation does not demonstrate skipping computation on silent timesteps/neuron inactivity; potential performance gains from sparsity-aware kernels remain unexplored.
- Export and deployment: No pathway to export models to CoreML/ONNX or to interface with neuromorphic hardware (e.g., Loihi) or event-driven simulators; deployment guidance is missing.
- Visualization and tooling: Planned visualization utilities are not available; lack of tools for inspecting spikes, membrane traces, and gradients during training hampers debugging and research.
- Numerical equivalence tests: Planned numerical validation against snnTorch outputs is pending; without it, correctness parity across neuron models and edge cases remains uncertain.
- Hyperparameter search: Only a small sweep is reported; no automated tuning (e.g., grid/random/Bayesian search) across T, β, thresholds, encoder parameters, or optimizer settings.
- Batch-size and T scaling: The trade-offs among batch size, time steps, accuracy, and memory/time beyond the reported configurations are not characterized.
- Interaction with MLX immutability: The performance/memory impact of non-in-place updates on long unrolls is not quantified; opportunities for kernel fusion or buffer reuse are not assessed.
- Error handling and edge cases: Behavior under extreme inputs (high/low rates, saturated membranes), gradient NaNs/inf, and numerical stability safeguards are not discussed.
- Licensing/compatibility: While MIT-licensed, compatibility with other MLX ecosystem tools (e.g., mlx-lm, vision/audio libs) and integration patterns are not described.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be acted on today using the library and results described in the paper.
- Boldly accelerate SNN research on Apple Silicon (Academia, Software R&D)
- Description: Use mlx-snn to prototype, train, and benchmark SNNs natively on MacBook Pro/Mac Studio, exploiting 2.0–2.5× faster epochs and 3–10× lower GPU memory than PyTorch-based stacks on the same hardware.
- Potential tools/products/workflows: “mlx-snn baseline suite” for common SNN models; benchmarking scripts for time/memory; template repos with MNIST examples.
- Assumptions/dependencies: Access to Apple Silicon and MLX; tasks comparable in scale to paper (MNIST-size) until larger datasets are validated.
- Port existing snnTorch projects to MLX with minimal code change (Academia, Industry/Software)
- Description: Leverage the snnTorch-compatible API to migrate existing code and immediately run on Apple GPUs without CUDA.
- Potential tools/products/workflows: snnTorch-to-mlx-snn migration guides; auto-linters to replace imports and state handling.
- Assumptions/dependencies: Projects use supported neuron/encoder/loss patterns; gaps may exist for custom PyTorch ops.
- Teach computational neuroscience and neuromorphic computing on Macs (Academia/Education)
- Description: Use six neuron models, four surrogates, and four encoders in classroom labs and workshops with student MacBooks.
- Potential tools/products/workflows: Jupyter-based labs; interactive demos of LIF/Izhikevich dynamics; homework templates covering rate/latency/delta encodings.
- Assumptions/dependencies: Instructors standardize on Apple Silicon; reliance on small to medium tasks given current validation scope.
- Rapid ablations on surrogate gradients and neuron dynamics (Academia)
- Description: Compare fast-sigmoid vs arctan surrogates, and analyze membrane dynamics across neuron types using the provided STE pattern and plotting utilities.
- Potential tools/products/workflows: Ablation dashboards for accuracy vs training time; notebooks comparing gradient choices.
- Assumptions/dependencies: Current STE workaround introduces a small accuracy gap versus native VJP; results should be interpreted accordingly.
- EEG proof-of-concept pipelines on Mac (Healthcare/BCI research)
- Description: Use the EEG encoder to transform multichannel EEG into spikes and build baseline classifiers or neurofeedback prototypes offline on macOS.
- Potential tools/products/workflows: “EEG-to-spike” preprocessing notebooks; small-scale BCI demos using consumer headsets; artifact handling scripts.
- Assumptions/dependencies: Requires labeled EEG datasets and preprocessing; not clinically validated; attention to data privacy and IRB/ethics in research settings.
- Event-driven signal prototypes with delta modulation (Robotics, Audio/IoT)
- Description: Encode audio/IMU streams into spikes using delta modulation and train SNNs for change-detection or keyword spotting prototypes on Mac.
- Potential tools/products/workflows: Streaming adapters to convert audio buffers to time-first spike tensors; simple on-device detectors for rapid R&D.
- Assumptions/dependencies: Real-time streaming glue code needed; inference latency and throughput may require mx.compile optimizations not yet applied.
- Memory- and energy-aware model iteration (Industry/Green AI, Policy-informing evidence)
- Description: Use the measured lower memory footprint to iterate larger SNNs on a single Mac, and report local compute’s benefits for sustainability.
- Potential tools/products/workflows: Internal “Green SNN” scorecards; procurement memos highlighting unified memory gains for SNN workloads.
- Assumptions/dependencies: Benefits measured on specific Apple M3 Max hardware; generalization across workloads should be validated.
- Mac-native app prototypes embedding SNN inference (Software)
- Description: Integrate MLX+mlx-snn inference into macOS utilities (e.g., background event detectors, spike-based filters) for local, private processing.
- Potential tools/products/workflows: Python-based services; wrappers to expose models via REST on-device; developer tools for packaging MLX apps.
- Assumptions/dependencies: Production deployment would need packaging and sandboxing strategies; Core ML does not natively support SNN operators.
- Research reproducibility and open-source contributions (Academia, OSS community)
- Description: Extend mlx-snn with new surrogate gradients and neuron models; replicate MNIST results; submit PRs for doc/tests.
- Potential tools/products/workflows: Contribution guidelines; unit tests aligning with snnTorch outputs; model zoo for spiking MLPs/CNNs.
- Assumptions/dependencies: MLX APIs may change; maintainers’ roadmap cadence.
- Student and hobbyist projects on personal Macs (Daily life/education)
- Description: Run SNN demos (digit classification, simple audio events) offline with privacy, no NVIDIA GPU or cloud.
- Potential tools/products/workflows: “pip install mlx-snn” starter kits; step-by-step tutorials for first SNN.
- Assumptions/dependencies: Users need basic Python/MLX familiarity; external sensors (e.g., microphones, consumer EEG) optional but helpful.
Long-Term Applications
These opportunities become viable as MLX matures, mlx-snn adds features (e.g., mx.compile, dataset loaders, LSM), and larger benchmarks are validated.
- Real-time, on-device spiking inference on Apple platforms (Software/Edge AI)
- Description: Low-latency SNN inference for event-driven tasks (audio, IMU, event camera streams) running natively on macOS, potentially leveraging JIT via mx.compile.
- Potential tools/products/workflows: Mac apps for always-on change detection; developer SDKs wrapping SNN services.
- Assumptions/dependencies: mx.compile integration into temporal loops; sustained throughput testing; OS-level I/O integration.
- Clinical-grade EEG/BCI toolchains (Healthcare)
- Description: Combine the EEG encoder with planned LSM modules and larger datasets for robust EEG classification, neurofeedback, or seizure detection.
- Potential tools/products/workflows: End-to-end pipelines with artifact suppression, online decoding, clinician dashboards.
- Assumptions/dependencies: Regulatory approval, extensive validation on clinical datasets, reliability and latency guarantees, privacy/security compliance.
- Event camera vision and neuromorphic datasets at scale (Robotics, Autonomous systems)
- Description: Train and evaluate SNNs on N-MNIST, DVS-Gesture, SHD once loaders and benchmarks are added; integrate with event cameras for robotics perception.
- Potential tools/products/workflows: Real-time event-vision demos on Mac; dataset loader modules and model zoo for event-based tasks.
- Assumptions/dependencies: Dataset loaders and preprocessing; driver support for event sensors; performance tuning with mx.compile.
- Train-on-Apple, deploy-on-neuromorphic hardware workflows (Hardware/Energy)
- Description: Use mlx-snn for training with surrogate gradients, then export/convert to neuromorphic chips (e.g., Loihi) for ultra-low-power deployment.
- Potential tools/products/workflows: Export/conversion tools; validation suites comparing MLX simulations with hardware behavior; quantization/threshold mapping utilities.
- Assumptions/dependencies: Conversion toolchain and operator parity; constraints on neuron/synapse models; access to hardware.
- Accuracy parity via custom VJP once MLX matures (Academia/Software)
- Description: Replace the STE workaround with native custom VJPs to close the ~1% accuracy gap observed on MNIST and stabilize training on larger tasks.
- Potential tools/products/workflows: Surrogate-gradient registry with VJP implementations; automated tests for gradient correctness.
- Assumptions/dependencies: Resolution of MLX’s shape inconsistency; API stability for custom autograd.
- mx.compile-optimized training and inference loops (Software performance)
- Description: JIT compilation for time-unrolled SNNs to achieve further speed and memory wins, enabling larger models/datasets on a single Mac.
- Potential tools/products/workflows: Compiled model artifacts; benchmarking harnesses for JIT vs eager comparisons.
- Assumptions/dependencies: Refactoring Python control flow for JIT compatibility; robustness across model variants.
- Standardized SNN benchmarks and reproducibility suites on Apple Silicon (Academia, Policy)
- Description: Establish reproducible baselines across datasets, with time/memory/energy metrics to inform research and “Green AI” policy.
- Potential tools/products/workflows: Public leaderboard; energy reporting scripts; reproducibility badges for papers.
- Assumptions/dependencies: Community adoption; verified measurement methodology; diverse datasets.
- Hybrid ANN–SNN systems on MLX (Software/Research)
- Description: Compose spiking front-ends (event encoders, LIF layers) with conventional MLX models (vision/audio) for energy-aware pipelines.
- Potential tools/products/workflows: Libraries for ANN–SNN interop; profiling tools to attribute compute/energy by module.
- Assumptions/dependencies: Stable interop APIs; quantifying energy benefits on Apple GPUs/NPUs; operator support across stacks.
- Edge robotics using Mac Mini/Studio as event-driven compute nodes (Robotics/Industrial automation)
- Description: Deploy SNN-based controllers/perception on Apple desktops for lab robots or small industrial cells where low-latency and local processing are preferred.
- Potential tools/products/workflows: ROS nodes wrapping mlx-snn; event-driven perception packages; long-running service management.
- Assumptions/dependencies: Stable ROS/driver integrations on macOS; real-time performance; maintainability for production use.
Glossary
- Adaptive LIF (ALIF): A leaky integrate-and-fire neuron extended with an adaptive threshold that increases based on recent spiking activity. "Extends LIF with a spike-frequency adaptation mechanism~\citep{bellec2018long}:"
- Alpha (neuron model): A synapse model using two cascaded exponential filters to produce a rise-then-decay post-synaptic current. "A dual-exponential synapse model cascading two first-order filters for a rise-then-decay post-synaptic current profile:"
- Arctan (surrogate): A smooth surrogate function for spikes that uses the arctangent to enable gradient flow during training. "Arctan: "
- Backpropagation-through-time (BPTT): A training method that unrolls temporal dynamics to compute gradients across timesteps. "a complete backpropagation-through-time training pipeline."
- Composable function transforms: MLX features that allow composing transformations like automatic differentiation, vectorization, and compilation. "MLX provides composable function transforms --- mx.grad for automatic differentiation and mx.compile for just-in-time compilation ---"
- Custom VJP (vector-Jacobian product) definitions: Manually specified backward rules for custom operations to control gradient computation. "MLX's current limitations with custom VJP definitions."
- Delta modulation: A change-based spike encoding that emits spikes when the signal change exceeds a threshold. "Delta modulation: Change-based encoding that generates spikes when , suitable for temporal signals."
- Dual-exponential synapse: A synaptic current model formed by cascading two exponential filters to shape the impulse response. "A dual-exponential synapse model cascading two first-order filters for a rise-then-decay post-synaptic current profile:"
- EEG encoder: An encoder tailored to multi-channel electroencephalography signals with rate, delta, and threshold-crossing methods. "EEG encoder: A medical-signal-specific encoder supporting rate, delta, and threshold-crossing methods for multi-channel EEG data."
- Event-driven computation: Processing based on discrete spike events, potentially improving energy efficiency. "event-driven computation with potential energy savings"
- Heaviside step function: A discontinuous function used to generate spikes by thresholding membrane potential. "Spike generation applies the Heaviside step function $\Theta(U - V_{\text{thr})$, which has zero gradient almost everywhere."
- Integrate-and-Fire (IF): A spiking neuron model that integrates input perfectly without leak until reaching threshold. "A non-leaky variant with , providing perfect temporal integration."
- Izhikevich (neuron model): A two-variable nonlinear spiking neuron model capturing diverse biological firing patterns. "The two-dimensional Izhikevich model~\citep{izhikevich2003simple}:"
- Just-in-time (JIT) compilation: Runtime compilation to optimize performance of pure functions. "mx.compile for just-in-time compilation"
- Latency coding: A spike encoding where larger input values produce earlier spikes, often via time-to-first-spike. "Latency coding: Time-to-first-spike encoding where larger values produce earlier spikes. Supports linear and exponential mappings."
- Leaky Integrate-and-Fire (LIF): A canonical spiking neuron with a decaying membrane potential and threshold-based spiking. "The standard first-order LIF neuron~\citep{gerstner2002spiking} with discrete-time update:"
- Liquid State Machine (LSM): A reservoir computing framework using spiking networks for temporal processing. "Liquid State Machine (LSM) with configurable reservoir topology, excitatory/inhibitory balance, and EEG classification examples."
- Membrane potential: The internal voltage state of a neuron that evolves over time and determines spike emission. "where is membrane potential, is input current, is the output spike, is the decay factor, and $V_{\text{thr}$ is the threshold."
- Metal Performance Shaders (MPS) backend: Apple’s GPU compute backend used by PyTorch on Apple Silicon. "PyTorch MPS backend (Apple Silicon GPU)"
- mx.compile: An MLX API to compile pure functions for performance gains. "mx.compile can JIT-compile pure functions for additional performance."
- mx.custom_function: An MLX API for defining custom operations with user-specified forward and backward behavior. "MLX's mx.custom_function VJP mechanism"
- mx.grad: An MLX transform for automatic differentiation of functions. "MLX's mx.grad transform computes gradients of arbitrary functions"
- mx.stop_gradient: An MLX operation that prevents gradients from flowing through part of a computation. "We adopt a straight-through estimator (STE) pattern using mx.stop_gradient:"
- mx.vmap: An MLX transform for vectorizing functions across batch dimensions. "composable function transforms (mx.grad, mx.vmap, mx.compile)"
- Neuromorphic hardware: Specialized hardware inspired by neural computation for efficient event-driven processing. "natural compatibility with neuromorphic hardware"
- Neuromorphic processor: A processor designed for spiking and event-driven computation, such as Intel’s Loihi. "targets Intel's Loihi neuromorphic processor."
- Poisson spike trains: Spike sequences generated by a Poisson process, often used in rate encoding. "Input images are rate-encoded into Poisson spike trains over timesteps."
- Rate coding: A spike encoding where firing probability reflects input magnitude. "Rate coding: Poisson spike generation where each input value is interpreted as a firing probability per timestep."
- Spike encoding: Methods for converting continuous signals into spike trains for SNN inputs. "mlx-snn provides four spike encoding methods:"
- Spike-frequency adaptation: A mechanism where a neuron’s threshold or excitability changes with recent spiking. "Extends LIF with a spike-frequency adaptation mechanism~\citep{bellec2018long}:"
- Straight-through estimator (STE): A training trick that uses a non-differentiable forward pass but a smooth surrogate in the backward pass. "We adopt a straight-through estimator (STE) pattern using mx.stop_gradient:"
- Surrogate gradient: A smooth approximation used in the backward pass to enable gradient-based training of spiking neurons. "Surrogate gradient methods~\citep{neftci2019surrogate, zenke2021remarkable} replace the backward pass with a smooth approximation , enabling gradient-based optimization."
- Synaptic (neuron model): A neuron model with an explicit synaptic current state that filters inputs before affecting membrane potential. "A two-state model with explicit synaptic current filtering:"
- Threshold-crossing (encoding method): An encoding that emits spikes when the signal crosses a set threshold. "threshold-crossing methods"
- Unified memory architecture: A hardware design where CPU and GPU share physical memory, eliminating explicit data transfers. "Its unified memory architecture eliminates CPU--GPU data transfers,"
Collections
Sign up for free to add this paper to one or more collections.