- The paper demonstrates that adversarial examples stem from an exponential misalignment between the high-dimensional neural perceptual manifolds and the low-dimensional human-recognizable manifolds.
- Its methodology employs Participation Ratio and Two Nearest Neighbor metrics to rigorously quantify and compare the intrinsic dimensionality of models across diverse architectures.
- The results indicate that reducing perceptual manifold dimensions correlates with increased adversarial robustness, highlighting dimensional compression as a promising strategy for robust AI.
Exponential Misalignment as the Root Cause of Adversarial Vulnerability
Introduction
The persistence of adversarial examples—imperceptible perturbations that cause neural networks to misclassify with high confidence—remains a central failure mode in machine learning, particularly in image classification. The paper "Solving adversarial examples requires solving exponential misalignment" (2603.03507) establishes a geometric framework linking adversarial robustness to the high intrinsic dimensionality of the perceptual manifolds (PMs) defined by neural networks. The key thesis is that adversarial examples, as well as broader machine misalignment issues, fundamentally originate from an exponential misalignment between machine and human perception: neural networks’ PMs for any semantic class encapsulate an exponentially larger set of inputs than the corresponding human-recognizable manifold.
This essay provides a technical summary and analysis of the paper, focusing on the definition and measurement of perceptual manifolds, quantitative evidence of exponential misalignment across diverse architectures, and the demonstrated correlations between PM dimensionality, adversarial robustness, and perceptual alignment. The implications for both adversarial defenses and general AI alignment are also discussed.
Perceptual Manifolds and Dimensionality
The perceptual manifold for a class c is defined as the set of all points in the ambient input space [0,1]D that a network classifies as c with confidence above a threshold (typically p0=0.9). This manifold is sampled using projected gradient ascent, initializing from uniform random noise and ascending the class log-probability until the desired confidence threshold is reached. Two principal metrics are used to estimate dimensionality:
- Participation Ratio (PR): An effective dimension based on the eigenvalue spectrum of the covariance of sampled PM points.
- Two Nearest Neighbor (2NN): An estimator of intrinsic dimension relying on neighbor distance statistics; values represent lower bounds due to sampling limitations in high dimensions.
PM dimensionality can be systematically compared to the intrinsic dimension of natural images for the same class, typically estimated using PR and 2NN on the empirical data distribution.
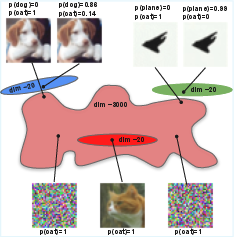
Figure 1: Visualization of the main argument—machine PMs (large red) occupy nearly all input dimensions, in contrast to the low-dimensional (≈20D) manifolds of human perception (blue, green, bright red); this indicates exponential misalignment underlying adversarial vulnerability.
Empirical Evidence of Exponential Misalignment
The paper presents extensive quantitative comparisons of PM dimensionality across non-robust and robust neural networks, as well as foundational models such as CLIP, using both CIFAR-10 and ImageNet. The results are consistent and striking: machine PMs are 2–4 orders of magnitude higher in dimension than the corresponding natural image manifolds, regardless of model architecture or training regime.
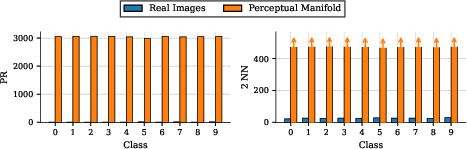
Figure 2: PM dimensionality (PR and 2NN) of WideResNet-28-10 (robust accuracy 0%) versus natural images; machine PMs are 2-3 orders of magnitude larger, signaling exponential misalignment.
Non-robust models (clean accuracy ~95%) typically yield PM PRs of ~3000 (CIFAR-10, 3072 ambient dims), while natural images have PRs of ~10. For ImageNet (ambient dimension >150,000), PRs for ResNet-50 PMs are ≳130,000, compared to ≈20 for natural images.
In CLIP, the phenomenon manifests identically: even with a strict similarity threshold, the PM’s dimension is orders of magnitude greater than that of the human concept, and this holds even for nonsensical text prompts.
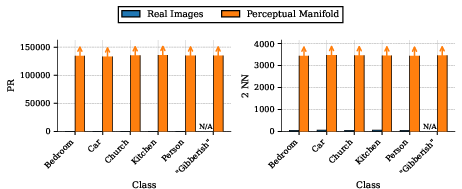
Figure 3: Dimensionality comparison for CLIP (PR and 2NN); both meaningful and gibberish prompts yield machine PMs with vastly higher dimension than natural images.

Figure 4: Samples from CLIP's PM for both valid (e.g., "a bedroom") and gibberish descriptions—visually indistinguishable from noise, reflecting the misalignment.
These empirical results show that, for all networks evaluated, the PM occupies an exponentially larger portion of the input space than the human-concept corresponding manifold.
Geometric Link Between Misalignment and Adversarial Fragility
A theoretical toy model demonstrates that for high-dimensional PMs nearly filling the ambient space, any input—even one drawn at random—is very close (in L2 or L∞ sense) to the PM of any target class. This implies that adversarial examples should generically exist and be easy to find, as the geometric proximity between classes in input space is functionally determined by PM dimension.
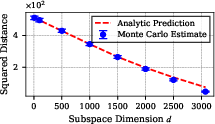
Figure 5: Monte Carlo estimate of the squared distance from random points to a d-dimensional ellipsoid (modeling the PM); as the manifold dimension increases, expected distance sharply decreases, confirming the geometric intuition.
Empirically, robust models (with lower PM dimensionality) exhibit increased distances between random inputs and PMs; this trend aligns with improved adversarial robustness.
Robustness Correlates with Dimensional Compression
A central prediction is that as the PM dimension decreases, robust accuracy increases, and the typical distance from arbitrary inputs to the PMs increases. This is validated using 18 diverse networks from RobustBench, across both CIFAR-10 and ImageNet.
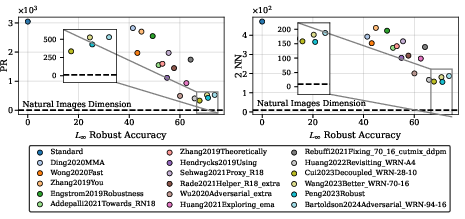
Figure 6: PM dimensionality (PR and 2NN, averaged over classes) versus L∞ robust accuracy on CIFAR-10—clear negative correlation, with robustness increasing as PM dimension drops.
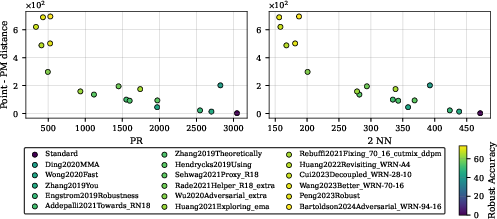
Figure 7: Typical squared Euclidean distance from random initialization to the PM increases as PM dimension drops; robust networks have higher minimum distances, indicating less vulnerability.
Critically, even the most robust CIFAR-10 models (robust accuracy >70%) maintain PM PRs ≳ 250—still much greater than that of natural images.
Persistent Misalignment and Semantic Alignment
Further analysis, including eigenvalue spectrum and power spectral density of PM samples, reveals significant geometric and statistical discrepancies between the robust model PMs and human concepts, even at high robust accuracy. Alignment at the level of visual semantics emerges only when PM dimensionality is reduced to near that of natural images.
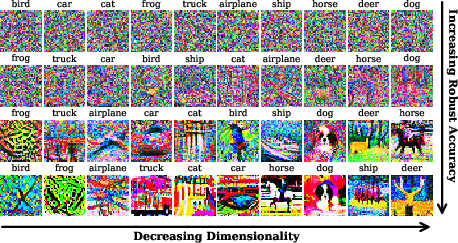
Figure 8: Samples from PMs of 4 models (increasing robustness top to bottom); human-recognizable images only appear when PM dimensionality approaches natural levels in the most robust networks.
Sparks of semantic alignment (i.e., network samples that resemble actual class images) are only observed for the lowest-dimensional PMs within the most robust models, and predominantly for select classes.
Implications and Future Directions
The theoretical and empirical findings jointly argue that adversarial vulnerability is fundamentally due to exponential misalignment in PM dimensionality: machine representations systematically overextend class concepts to encompass vast swathes of input space unrelated to the corresponding human perception. Robustness improvements are tightly coupled to PM dimensionality reduction, not mere regularization or boundary smoothing.
This insight has both practical and theoretical implications:
- For adversarial defenses: Future methods must induce dimensional compression of PMs to within the regime of the natural data manifold, potentially via explicit regularization or novel architectural constraints.
- For alignment more broadly: The phenomena described are not limited to vision; analogous misalignment almost certainly underpins failures of LLMs and other modalities, as suggested also by recent investigations into LLM adversarial prompting [Yamamura2024-wf]. The "curse of dimensionality" presents a major roadblock for achieving alignment in broader AI systems.
- Theoretical questions: What is the minimal architecture and regularization necessary to enforce low-dimensional PMs for arbitrary concepts, and how can such dimensionality be measured or induced in practice? Are current scaling laws for adversarial robustness ultimately constrained by this geometric effect?
Conclusion
The study systematically establishes that solving adversarial examples is equivalent to solving exponential misalignment in perceptual manifolds between machines and humans. Current approaches, including adversarial training and robustness regularization, have only been partially successful, as evidenced by the persistent high dimensionality of networks’ PMs. The paper provides compelling geometric, statistical, and phenomenological evidence that only by achieving dimensional alignment between machine PMs and human concepts can adversarial vulnerability be eliminated. This paradigm offers a concrete, measurable goal for future robust and aligned AI development.