- The paper demonstrates that adversarial attacks exploit interference among superposed features, supported by both theoretical frameworks and empirical experiments.
- It employs synthetic classification tasks and vision transformer models to show that perturbation directions align with predicted latent feature geometry.
- The study finds that shared latent geometric similarities drive high attack transferability, suggesting new directions for semantically-informed defense strategies.
Mechanistic Pathways of Adversarial Vulnerability via Feature Superposition
Introduction
This paper presents a mechanistic interpretability framework for adversarial vulnerability in neural networks (NNs), positing that adversarial examples (AEs) systematically exploit interference between features represented in superposition. The authors argue that adversarial vulnerability is not merely a consequence of non-robust features or decision boundary irregularities, but can arise as a byproduct of efficient information encoding—specifically, when networks represent more features than available dimensions, leading to superposition and feature interference. The work provides both theoretical and empirical evidence, spanning synthetic models and vision transformers (ViTs), to demonstrate that attack patterns are predictable from the geometry of latent feature arrangements and that transferability of attacks is governed by shared interference patterns.
Theoretical Framework: LRH and Superposition
The analysis is grounded in the Linear Representation Hypothesis (LRH), which asserts that NNs encode semantic features as linear directions in activation space. When the number of features M exceeds the layer dimensionality dl, networks employ superposition, packing features into non-orthogonal directions. This induces polysemanticity and interference, where activation of one feature can inadvertently activate others. The superposition hypothesis formalizes this as:
- M>dl
- Non-orthogonal feature directions: ∃i,j:vi⋅vj=0
- Sparse feature activations: Ex[∥a(x)∥0]≪M
This encoding strategy increases representational capacity but introduces interference, which adversarial attacks can exploit.
Empirical Analysis: Synthetic Models
The authors design a synthetic classification task with controlled superposition, enabling precise mapping between input features and latent representations. Inputs are partitioned into groups corresponding to classes, and a bottleneck encoder compresses these into a lower-dimensional latent space. Adversarial attacks are generated using PGD under ℓ∞ and ℓ2 constraints.
Key findings include:
- Attack Mechanism: PGD-generated adversarial perturbations align closely with theoretically optimal directions derived from the superposition geometry, as quantified by cosine similarity (>0.9 across configurations).
- Input Perturbation Profile (IPP): The sign and magnitude of input perturbations are determined by the dot products between input feature directions and the difference of class vectors in latent space.
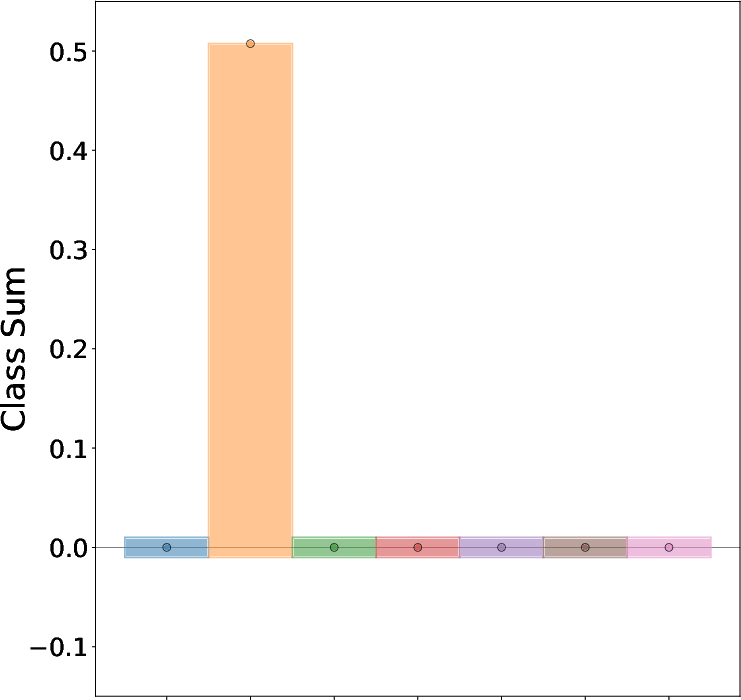
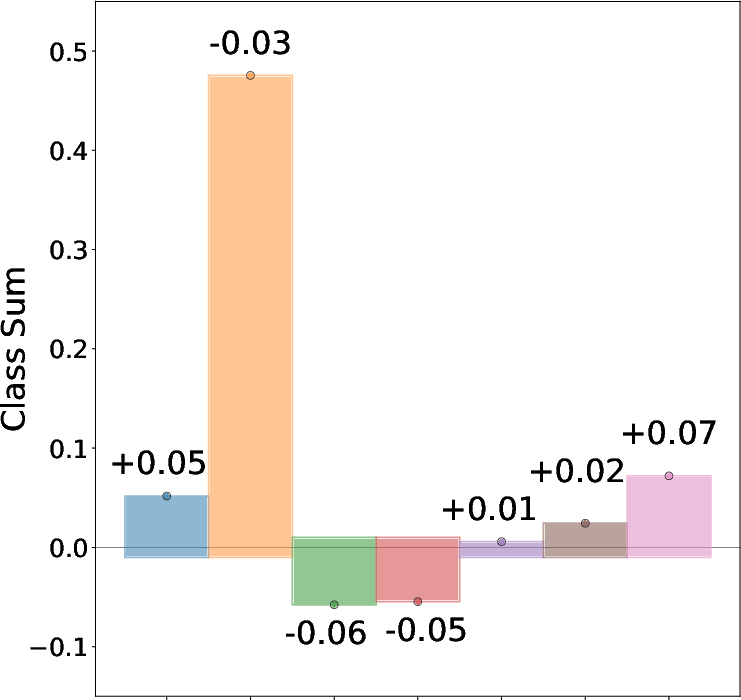
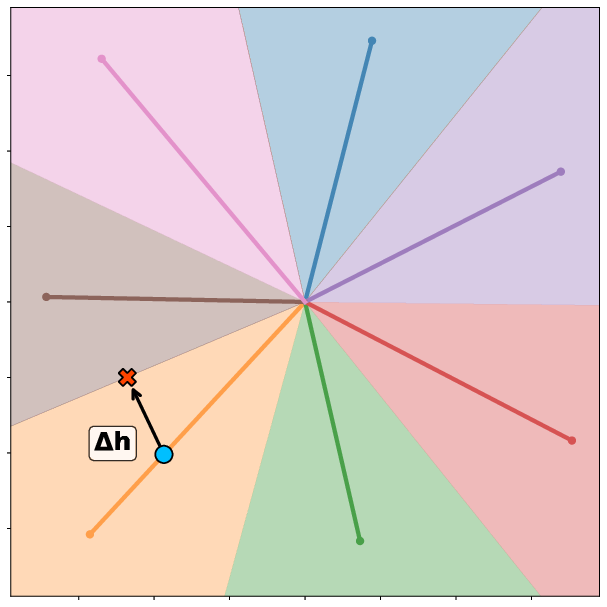

Figure 1: An adversarial attack exploiting superposition geometry, showing the original input, adversarial input, and latent feature activations relative to decision boundaries.
- Interference-Driven Vulnerability: The optimal perturbation for moving a sample from class j to k is δ∝We⊤(vk−vj), directly linking vulnerability to interference between superposed features.
Data Correlations and Attack Transferability
The paper demonstrates that input correlations constrain the geometric arrangement of latent features, which in turn determines interference patterns and attack transferability:
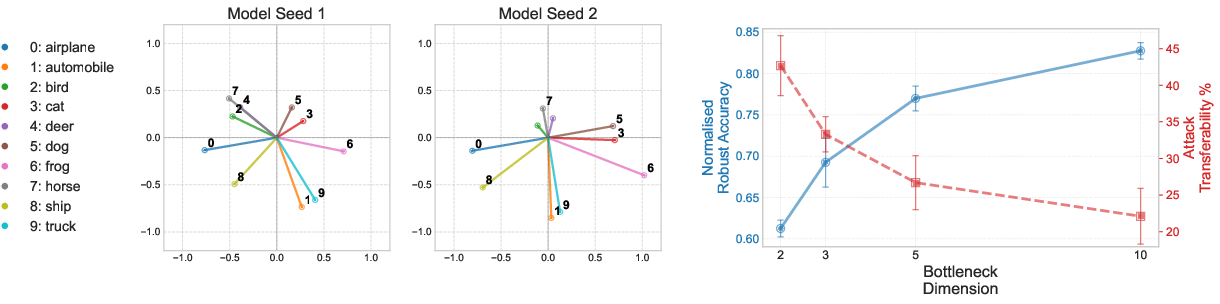
The framework is validated on a ViT trained on CIFAR-10, with an engineered bottleneck to induce superposition:
- Compression Effects: As bottleneck dimension m decreases (increasing superposition pressure), robust accuracy drops and attack transferability rises.
- Consistent Geometry: Class representations in the bottleneck exhibit consistent clustering across seeds, often reflecting semantic class similarities.
- Perturbation Consistency: Adversarial examples generated for bottlenecked models induce similar logit changes in the base ViT, indicating that the attacks exploit shared interference patterns.
Algorithmic Brittleness Beyond Superposition
The authors further show that adversarial vulnerability can arise in models with orthogonal feature representations due to algorithmic brittleness. In a modular addition task, the network learns a trigonometric algorithm with orthogonal sinusoidal features. Attacks constructed via Fourier analysis of the learned key frequencies succeed by corrupting these algorithmic features, even in the absence of superposition. Certified training increases the required perturbation norm but does not eliminate the underlying vulnerability, highlighting the need for semantically-informed defenses.
Implications and Future Directions
The findings have several implications:
- Mechanistic Predictability: Adversarial vulnerability can be predicted and explained by the geometry of feature superposition, enabling principled attack and defense strategies.
- Transferability: Shared interference patterns, driven by data correlations, explain why attacks transfer between models with similar training regimes.
- Defensive Strategies: Robustness certification increases attack budgets but does not address semantic vulnerabilities; defenses should target the specific mechanisms exploited by attacks.
- Scalability: The framework is applicable to large-scale models, with preliminary results indicating that sparse autoencoders (SAEs) can be used to extract and analyze latent features in practical settings.
Conclusion
This work provides a mechanistic account of adversarial vulnerability rooted in feature superposition and interference. By bridging architectural constraints and data semantics, the authors demonstrate that adversarial attacks systematically exploit predictable interference patterns, and that transferability is governed by shared latent geometry. The analysis extends to both synthetic and real-world models, and highlights that superposition is sufficient but not necessary for vulnerability, with algorithmic brittleness providing an alternative pathway. Future research should focus on quantifying the adversarial cost of superposition, understanding accuracy-robustness trade-offs, and developing semantically-informed defenses that target the specific mechanisms underlying adversarial vulnerability.