- The paper demonstrates that LLMs exhibit pronounced overreaction and action bias, leading to inefficient convergence compared to human groups.
- It employs the Group Binary Search paradigm to compare responses under numerical and directional feedback, highlighting differences in adaptation.
- The results underline that LLMs’ lack of cumulative learning and implicit role differentiation calls for architectural innovations.
High Volatility and Action Bias Distinguish LLMs from Humans in Group Coordination
Introduction and Motivation
This paper conducts a systematic evaluation of coordination dynamics in groups of LLM agents vis-à-vis human baselines within a common-interest game, Group Binary Search (GBS). The central objective is to elucidate mechanism-level differences underlying group adaptation, learning, and feedback utilization under imperfect monitoring and absent direct communication. Unlike prior multi-agent LLM studies focusing on communication loops or explicit role assignment, this work targets pure group coordination, leveraging experimental paradigms from social psychology to extract actionable diagnostics for LLM coordination deficits.
The Group Binary Search Paradigm
GBS is an n-player iterative guessing task where each agent independently submits a value per round, with the collective group sum compared to a hidden target number. Only aggregate feedback (either directional—'too high,' 'too low'—or numerical—e.g., 'too low by 25') is provided to all participants, enforcing a decentralized and imperfectly monitored environment. The aim is exact convergence to the target (or 15 rounds cap), with all participants oblivious to each other's guesses and unable to communicate directly.
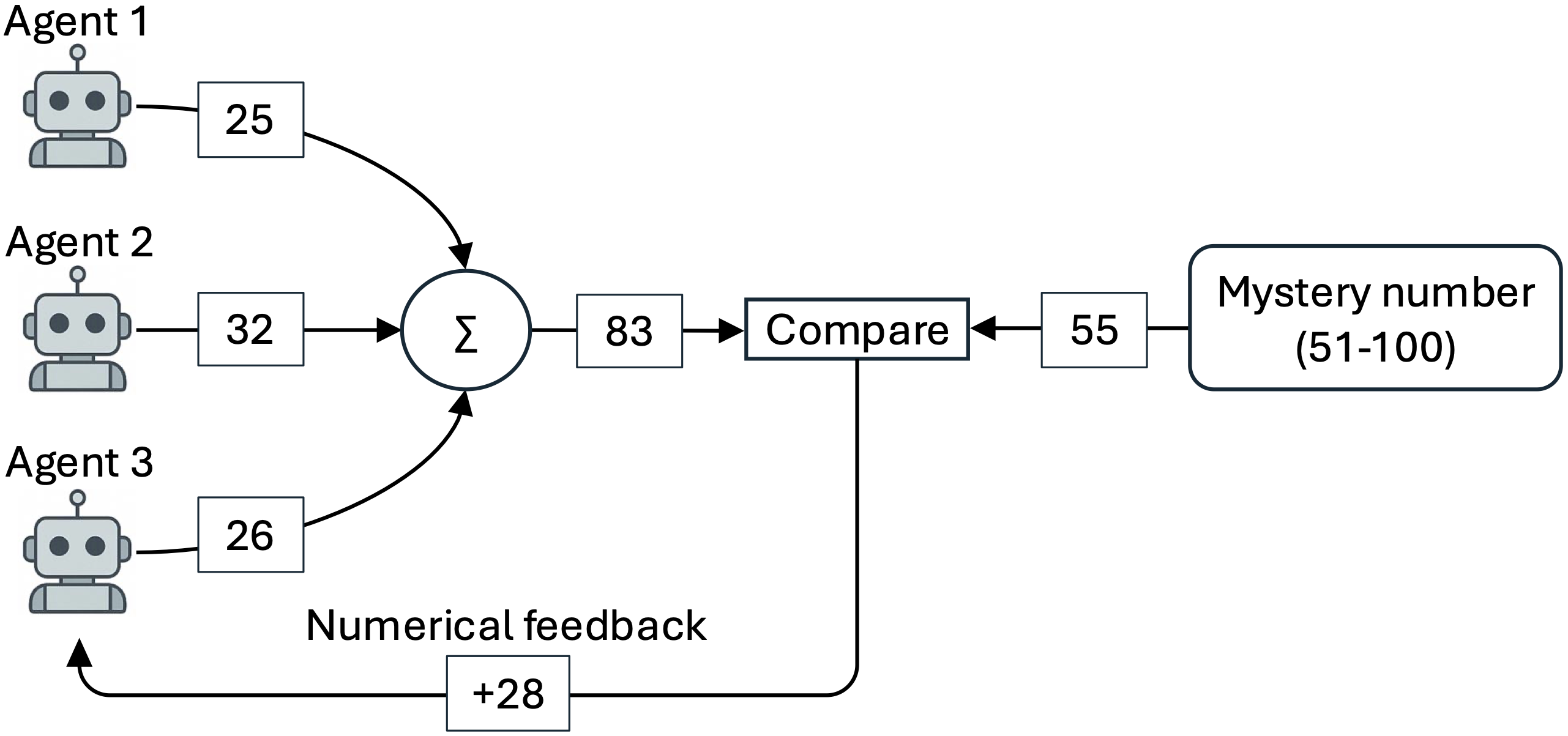
Figure 1: Schematic of a GBS game with three players and numerical feedback, illustrating the feedback loop that drives individual adjustment towards group convergence.
Experimental Methodology
Multiple instances of state-of-the-art LLMs (Deepseek-V3, Deepseek-V3.1-T, Gemini 2.0 Flash, Llama 3.3) were evaluated under two prompting regimes: zero-shot and zero-shot Chain-of-Thought (CoT). Each agent received sequential round histories and feedback within its prompt context. Human group data from prior cognitive science studies [roberts2011adaptive] provide a methodologically aligned baseline. The experiments covered a range of group sizes (2–17 players), feedback types, and prompt conditions.
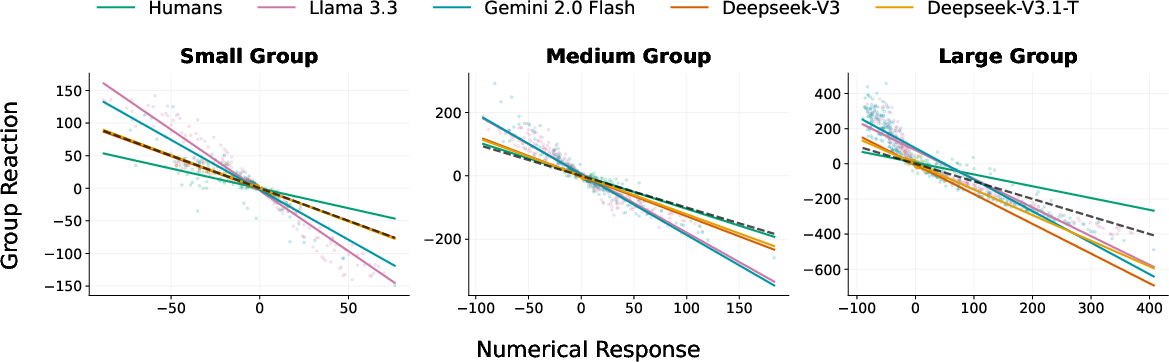
The most decisive empirical divergence occurs in the exploitation of feedback information richness:
- Humans: Exploit numerical feedback for significantly faster convergence compared to directional-only feedback, across all group sizes.
- LLMs: Show negligible improvement—or even degraded performance—under numerical feedback compared to directional feedback, particularly in medium and large groups.
This signals a fundamental limit in LLMs' ability to leverage precise quantitative feedback for adaptive adjustment, in contrast to humans' effective aggregation and distributed interpretation.
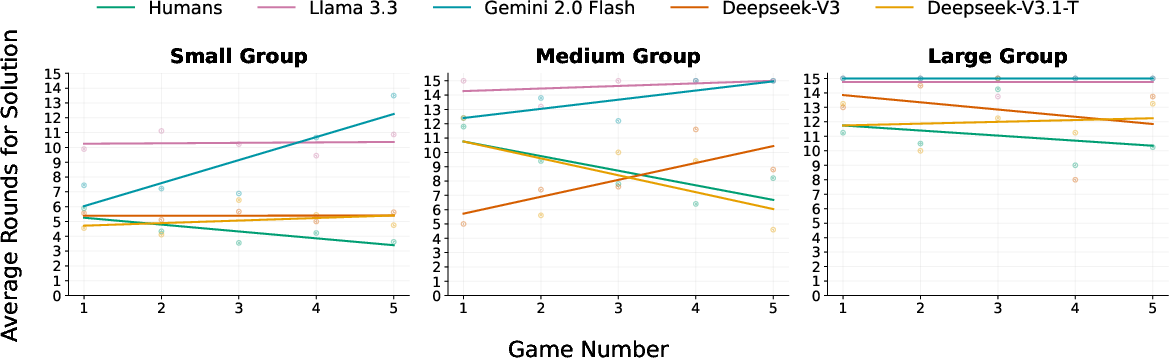
Figure 3: Average number of rounds needed to finish the game with zero-shot CoT prompts under numerical feedback, contrasting LLM groups and human performance.
Human groups adaptively refine their response strategies as games progress, reliably reducing the number of rounds required per game (negative learning curve slopes). LLM groups, however, lack consistent across-game improvement, with slopes close to zero—sometimes even positive—across all tested models and conditions, indicating an absence of effective cumulative learning even within extended context windows.
Dynamics of Coordination: Overreaction and Switching
Quantitative analysis of round-by-round group adjustments reveals:
Crucially, switching behavior compounds this deficit. Human groups, especially for larger n, naturally evolve heterogeneous roles—some members "anchor" on fixed values while others adjust, reducing the effective coordination dimensionality. LLM agents, by contrast, maintain a high action rate: almost every agent changes their guess every round, irrespective of proximity to the target or group size, demonstrating an "action bias" with a lack of spontaneous role differentiation.
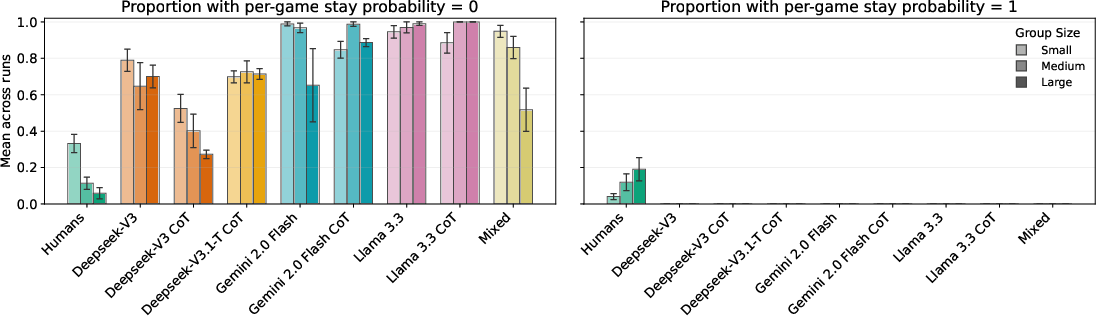
Figure 4: Extreme stay behavior: humans sometimes persist with fixed guesses throughout entire games (stay probability=1), a pattern nonexistent among LLMs, whose agents exhibit either universal switching or homogenous, non-adaptive actions even as group size increases.
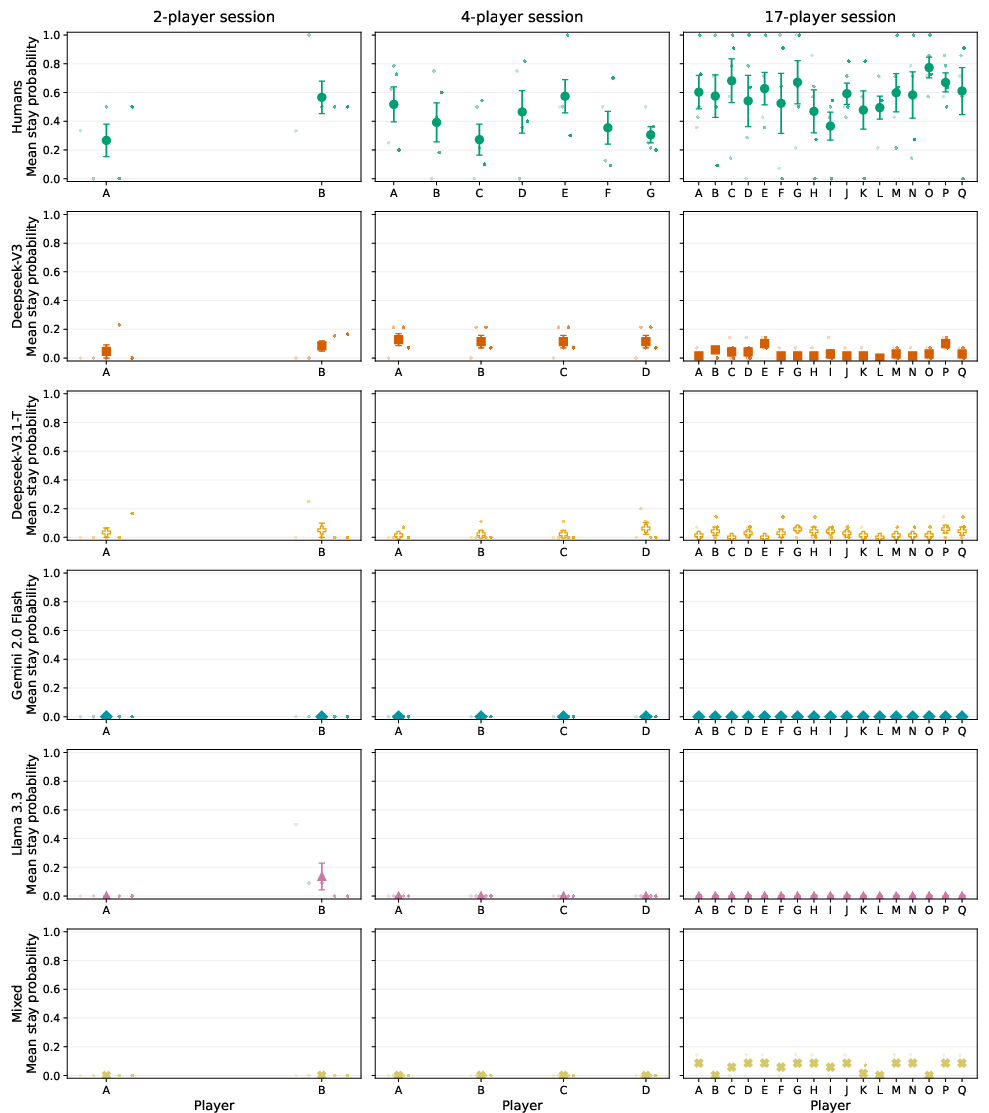
Figure 7: Player-level stay profiles across game sessions reveal greater behavioral separation and lower volatility among humans than LLM groups, which cluster towards high volatility and compressed adaptation trajectories.
Implications for Multi-Agent AI and Future Directions
The observed deficits are robust to prompt augmentation, model mixing, and generation parameter tuning, pointing to inherent architectural limitations in current LLM-based agents under non-communicative, imperfectly monitored coordination pressures. Specifically:
- Lack of implicit role differentiation and stabilization: LLM groups fail to self-organize high-stability, low-dispersion subpopulations that anchor collective estimates, a well-documented human mechanism for large-group coordination.
- Absence of cumulative task adaptation: Reliance on static context-based reasoning, even with extensive history, does not induce the cross-episode learning evident in humans.
- Overreactivity to error signals: LLM groups' action bias and excessive reactivity leads to inefficiency that increases with group size.
These findings suggest that achieving human-like adaptive coordination with LLMs in multi-agent systems may require architectural innovations that enable memory over feedback histories, explicit role negotiation, and meta-level learning mechanisms. Current prompt-based, context-limited approaches are insufficient for robust, scalable group coordination without communication.
In mixed human-LLM settings, the complementary strengths—LLMs' tendency for high exploration and human agents' stabilizing caution—could offer avenues for hybrid architectures that exploit these opposing coordination signatures [patel2019humanai]. However, design of such systems will require deliberate modulation of action bias and feedback reactivity to avoid destabilization.
Conclusion
This study delivers a nuanced empirical and mechanistic comparison of group coordination in LLM and human groups under imperfect monitoring. Key findings are the pronounced lack of adaptation and excessive volatility in LLM groups, particularly when faced with richer feedback or larger group sizes. The work provides clear evidence that while LLMs can track and react to group-level feedback, their persistent overreactivity and uniform action bias fundamentally distinguish their collective behavior from that of humans. Addressing these deficiencies will be central for the next generation of multi-agent LLM systems capable of robust, scalable, human-like group coordination.
References
- (2604.02578)
- Roberts, M. E., & Goldstone, R. L. "Adaptive Group Coordination and Role Differentiation," PLoS ONE, 2011.
- Patel, B. N., et al. "Human–machine partnership with artificial intelligence for chest radiograph diagnosis," npj Digital Medicine, 2019.
- Akata, E., et al. "Playing repeated games with LLMs," Nature Human Behaviour, 2025.