CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
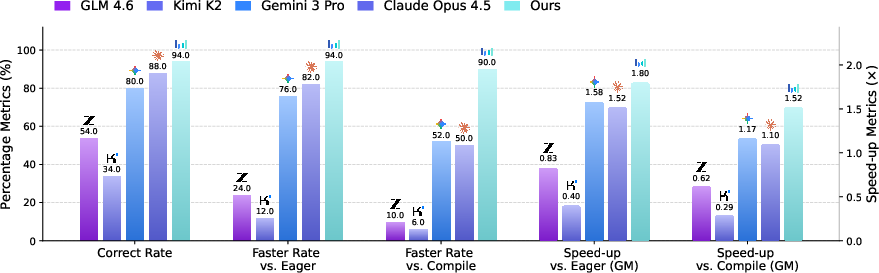
Abstract: GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, LLMs remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching an AI to write super-fast computer code that runs on GPUs (graphics cards). The special kind of code is called a “CUDA kernel,” and it’s used inside deep learning tools to make math run quickly. The authors built “CUDA Agent,” a system that trains an AI to become very good at creating and tuning these kernels so they run faster than standard automatic tools.
Key Questions
The paper asks:
- Can we train an AI to not just write CUDA code, but make it truly high-performance?
- How do we give the AI the right practice problems, tools, and feedback so it learns real optimization skills, not just syntax?
- Will this AI beat popular automatic optimizers like torch.compile and even strong general coding AIs?
Methods and Approach
The project has three main parts: making good training tasks, providing the right environment and tools, and training with reinforcement learning.
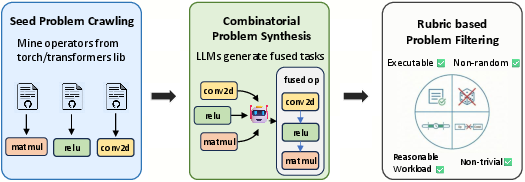
1) Making a big set of practice tasks
Think of CUDA kernels like tiny “workhorses” that do math quickly. The team needed lots of tasks the AI could learn from. So they:
- Gathered basic building blocks (operators) from well-known libraries like PyTorch.
- Combined several operators into single fused tasks. This is like cooking: instead of making each ingredient separately, you prepare parts together so you don’t waste time transferring stuff—in GPU terms, you avoid extra memory moves and can reuse resources.
- Filtered out tasks that were too easy, too random, or too slow to measure reliably, and ensured each task runs correctly both in normal and optimized modes.
This created a 6,000-task training set that covers simple to tricky cases.
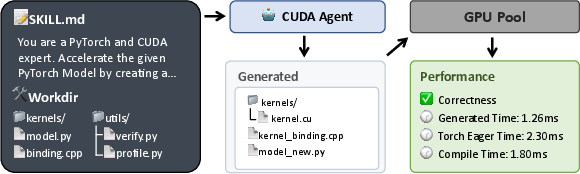
2) Giving the AI a development environment and skills
The AI works in an “agent loop,” which is like a guided workshop:
- It has a set of tools (like a file editor and a profiler) and a step-by-step checklist (“Agent Skills”) for how to find bottlenecks, write custom CUDA kernels, test that the results are correct, and check speed.
- It gets automatic feedback: Did the code compile? Did it produce the right numbers? Is it faster than the baseline?
- It runs in sandboxes that prevent cheating and keep timing fair. For example, the AI can’t edit the testing scripts, can’t fallback to easy built-in functions, must pass correctness on multiple random inputs, and doesn’t have internet access.
All this ensures the AI learns real optimization—not shortcuts.
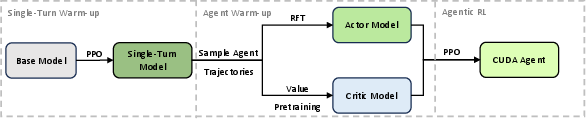
3) Training with reinforcement learning (RL)
Reinforcement learning is like training by trial and error in a video game:
- The “actor” proposes code changes.
- The “critic” estimates how good the current behavior is.
- The system gives rewards for correct and faster solutions, and penalties for wrong ones.
A few key ideas make training stable:
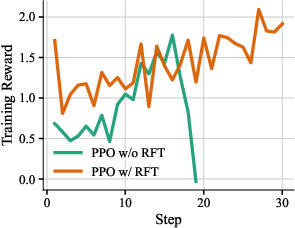
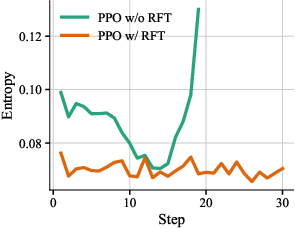
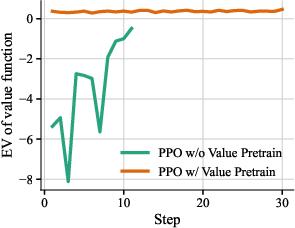
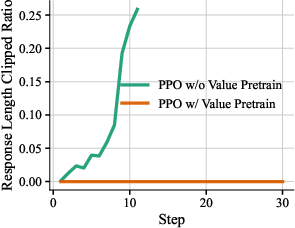
- Warm-up: The authors first did a “single-turn” RL stage so the model gets basic CUDA ability. Then they collected good multi-step agent examples and used them to fine-tune the actor (this is called Rejection Fine-Tuning, keeping only high-quality trajectories). They also pre-trained the critic on these trajectories so it starts with a decent sense of what “good” looks like.
- Careful reward design: Instead of just “how many times faster,” they used tiers (milestones) like “correct,” “faster than normal,” “faster than torch.compile,” etc. This avoids giving misleading rewards for tasks that are too easy or noisy.
- Conservative updates: They used PPO (a popular RL method) that makes sure each training step doesn’t change behavior too wildly, like adjusting knobs carefully rather than slamming them.
Main Findings
The AI learned to produce kernels that are both correct and fast—often faster than strong baselines.
Highlights:
- On a popular benchmark called KernelBench (with three difficulty levels), CUDA Agent was faster than torch.compile on almost all tasks.
- Overall, its solutions ran about 2.11× faster than torch.compile on average (that’s more than twice as fast).
- On Level 2 (operator sequences), it achieved perfect “faster than torch.compile” rate and around 2.80× speed on average.
- Even on the hardest Level 3, it still beat torch.compile with ~1.52× average speedup and was about 40% better than strong general AIs like Claude Opus 4.5 and Gemini 3 Pro on that toughest split.
Why this matters:
- General-purpose AIs can write code, but they often don’t beat specialized compilers. CUDA Agent shows that with the right training and environment, an AI can learn hardware-aware tricks (like better memory layouts and tiling) and reliably outperform static compiler rules.
Implications and Impact
In simple terms, this research suggests we can grow AIs from “good coders” into “performance engineers”:
- It shows that giving an AI a smart toolbox, realistic tests, and fair rewards can teach it real optimization, not just code that looks right.
- It could reduce the need for rare GPU experts to hand-tune every kernel, speeding up AI development.
- The same approach—structured environments plus reinforcement learning—could be used to train AIs to optimize other performance-critical systems (like different GPU architectures or low-level CPU code), making future software faster and more efficient.
Overall, CUDA Agent points to a future where AI doesn’t just write programs—it makes them run brilliantly fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research:
- Hardware generalization: The system is evaluated on NVIDIA H20 GPUs only; it remains unknown how performance and learned policies transfer to other NVIDIA architectures (e.g., A100, H100, RTX), non-NVIDIA GPUs (AMD ROCm), or multi-GPU settings.
- Cross-benchmark robustness: Results are reported for KernelBench only; generalization to other benchmarks (e.g., MultiKernelBench, TritonBench) and real-world model workloads (end-to-end pipelines beyond operator-level) is not assessed.
- Baseline breadth: Comparisons exclude specialized compiler/auto-tuning stacks (e.g., TVM/Ansor, AITemplate, TensorRT, CUTLASS, Triton auto-tuners). It is unclear whether CUDA Agent maintains advantages over these stronger baselines.
- Real-model integration: The paper optimizes operator-level tasks; it does not demonstrate end-to-end speedups when integrating generated kernels into full neural models (e.g., Transformer blocks, CNNs) under realistic training/inference pipelines.
- Portability of generated kernels: The stability and performance of learned kernels under different input shapes, batch sizes, memory layouts (non-contiguous tensors), and dtypes (FP16/BF16/FP32/INT8) are not characterized.
- Dynamic-shape and distribution shift: Correctness and speedup evaluation uses five random inputs per task, but it is unclear whether kernels remain correct and fast over broader or dynamic shape distributions and edge cases (e.g., very small/large dimensions, strides, broadcasting).
- Reward signal sensitivity: The discrete reward schedule (with a 5% speedup threshold) is not analyzed for sensitivity to threshold choices, per-task variability, or hardware noise; alternative reward designs (e.g., percentile-normalized per-task baselines, multi-objective shaping) remain unexplored.
- Hardware-counter-informed rewards: The reward does not use hardware performance counters (e.g., occupancy, memory throughput, bank conflicts) or kernel launch/compile overhead; it is unknown whether including such signals would improve stability or optimization quality.
- Residual reward hacking risks: Although permissions and checks reduce reward hacking, the paper does not systematically test adversarial strategies (e.g., subtle numerical tolerance exploits, uninitialized memory, out-of-bounds reads) or quantify remaining attack surface.
- RL stability and hyperparameter robustness: Stability is demonstrated with one warm-up and PPO configuration; there is no study of robustness to different clip ratios, learning rates, entropy regularization, gamma/λ, precision settings, or random seeds.
- Compute and efficiency accounting: The paper omits wall-clock time-to-solution, GPU-hours, and energy costs for training and for the multi-turn test-time search; sample efficiency and cost-performance trade-offs remain unknown.
- Best-of-trajectory selection bias: Evaluation selects the best solution across up to 200 turns, potentially overestimating practical performance. Expected performance per run, convergence speed, and variance across seeds/rollouts are not reported.
- Data pipeline ablations: There is no quantitative ablation of the data synthesis pipeline (e.g., impact of dataset size, degree of operator fusion, curriculum difficulty) or how each filtering criterion contributes to training effectiveness.
- Dataset representativeness: The 6K dataset is synthesized from PyTorch operators; its similarity to real production kernels, coverage of tricky memory/compute patterns (e.g., irregular access, reductions, warp-synchronous ops), and long-tail behaviors are not evaluated.
- Contamination assurance: While the paper claims to exclude tasks similar to KernelBench, the similarity metrics and thresholds are not detailed; reproducible contamination checks or code for the filtering process are not provided.
- Code quality and maintainability: Beyond performance/correctness, the maintainability, readability, and idiomatic quality of generated kernels (e.g., use of warp intrinsics, shared memory boundaries, register pressure trade-offs) are not analyzed.
- Kernel safety and undefined behavior: The validation focuses on numerical checks; detection of race conditions, UB under rare inputs, NaN/Inf propagation, and memory alignment assumptions is not discussed.
- Multi-objective optimization: Only runtime and correctness are optimized. Open questions remain about jointly optimizing for occupancy, shared memory/register usage, compilation time, kernel launch count, and memory footprint.
- Combining with test-time search: The paper suggests orthogonality to training-free methods (e.g., evolutionary or MCTS search) but does not empirically evaluate whether such test-time scaling further improves CUDA Agent’s outputs.
- Interpretability of learned strategies: There is no qualitative analysis of the optimization tactics the agent learns (e.g., tiling, vectorization, coalesced access, shared-memory tiling), making it hard to verify if learned patterns align with GPU best practices.
- Continual and cross-architecture adaptation: The approach does not address how policies adapt to new GPUs/toolchains or evolving CUDA/driver versions without retraining from scratch.
- Failure-mode taxonomy: The paper reports aggregate metrics but does not categorize failure cases (e.g., frequent reasons for compilation failures, correctness misses, or performance regressions), leaving optimization targets unclear.
- Tooling and reproducibility: It is unclear if the full agent loop, SKILL.md, sandbox scripts, and evaluation harness are publicly released and easily reproducible; lack of these artifacts limits external validation.
- PTX/Triton pathway: The system focuses on CUDA C++; potential benefits or drawbacks of generating PTX directly or using Triton as an intermediate are not explored.
- Robustness to developer constraints: Practical constraints such as limited shared memory, determinism requirements, kernel fusion boundaries enforced by framework backends, or mixed-precision constraints are not modeled in training or reward.
- Scalability of training steps: The paper claims stable training up to 150–200 steps but does not study longer horizons, larger context windows, or more turns, nor the point at which returns saturate or degrade.
- Security of the sandbox: Beyond file permissions and resource isolation, risks from compiling and executing untrusted code (e.g., driver exploits, denial of service, GPU hangs) are not assessed.
- Human-expert comparison: There is no direct comparison against human expert-designed kernels for the same tasks, leaving the gap to hand-tuned production kernels (e.g., cuDNN/cuBLAS) unquantified.
- Deployment readiness: How generated kernels would be packaged, versioned, tested, and integrated into framework backends (with ONNX/Torch extensions) and maintained over time remains an open engineering question.
Practical Applications
Practical, Real-World Applications of “CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation”
Below are actionable, sector-linked applications derived from the paper’s findings, methods, and innovations. They are grouped into immediate versus long-term based on deployability and required maturity. Each item summarizes the use case, the sector(s) it impacts, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
The following applications can be piloted or deployed now by teams with access to NVIDIA GPUs and common ML tooling (e.g., PyTorch, torch.compile), leveraging the CUDA Agent’s skill-integrated environment, robust reward scheme, and sandboxed verification/profiling.
- Automated, profiling-guided CUDA kernel optimization for ML operators
- Sector: Software/AI infrastructure, Cloud, HPC
- Tools/Products/Workflows: “Kernel Optimizer Agent” that profiles PyTorch ops, generates custom CUDA kernels, and validates correctness/speedups against eager and torch.compile; plug-in for PyTorch/TorchInductor/TensorRT pipelines
- Assumptions/Dependencies: NVIDIA CUDA stack; reliable profiling harness and correctness tests; integration into existing build and deployment pipelines
- CI/CD performance gates for new or modified operators
- Sector: Software engineering/DevOps
- Tools/Products/Workflows: CI plugin that triggers CUDA Agent on pull requests; automatic regression checks with speedup thresholds and fallback to torch.compile; artifacts (kernels, bindings, traces) stored per build
- Assumptions/Dependencies: Stable sandbox environments (CPU/GPU decoupled); robust “anti-hacking” protections; reproducible benchmarking setups
- Inference cost and latency reduction for production AI services
- Sector: Cloud, Enterprise SaaS, Consumer AI apps
- Tools/Products/Workflows: Deploy optimized kernels for attention, normalization, fused pre/post-processing; integrate agent-generated kernels into model-serving stacks (e.g., microservices with GPU pools)
- Assumptions/Dependencies: Compatibility with serving frameworks; consistent gains versus torch.compile on production workloads; operational guardrails to ensure correctness across data distributions
- IDE-integrated developer assistant for CUDA kernel writing and debugging
- Sector: Software development tools
- Tools/Products/Workflows: VS Code/JetBrains plugin using Agent Skills and the SKILL.md workflow; local sandboxed compilation, profiling, and test harness
- Assumptions/Dependencies: Secure file-permission model; no external web access during agent runs; large context LLMs for multi-turn workflows
- Targeted operator fusion for performance-critical pipelines
- Sector: ML tooling (vision/NLP), Data engineering pipelines
- Tools/Products/Workflows: Agent suggests and implements fused operators to avoid intermediate materialization and improve memory locality/occupancy; automated fusion candidates via combinatorial synthesis
- Assumptions/Dependencies: Workloads where fusion is beneficial; stable bindings to framework APIs; careful benchmarking to avoid regressions
- Internal library modernization and tuning across CUDA/driver versions
- Sector: Software infrastructure, Platform engineering
- Tools/Products/Workflows: Automated re-tuning of kernels for new architectures (e.g., H100/H200) using the agent loop and reward schedules; migration assistance for PTX-level improvements
- Assumptions/Dependencies: Access to target GPUs; availability of hardware-specific profiling (Nsight, perf counters); validated correctness across drivers
- Benchmarking and dataset reuse for research and model evaluation
- Sector: Academia, Research labs, Framework vendors
- Tools/Products/Workflows: Adopt CUDA-Agent-Ops-6K for training/evaluation; align with KernelBench protocols (multi-input correctness, speedup metrics); reproducible, isolated sandboxes for fair comparisons
- Assumptions/Dependencies: Non-contaminating train/test splits; adherence to standardized measurement practices; open access or managed licensing
- Performance audits of existing CUDA kernels
- Sector: Software quality assurance, Systems performance teams
- Tools/Products/Workflows: Agent reviews kernels, runs profiler, proposes optimizations (tiling, memory access patterns, occupancy); generates directly comparable candidates with reward-backed selection
- Assumptions/Dependencies: High-quality profiling harness; maintainers ready to evaluate and accept changes; safety/lint checks for code reliability
- Teaching and training aid for CUDA programming
- Sector: Education, Workforce development
- Tools/Products/Workflows: Interactive “guided lab” using SKILL.md to scaffold analysis → implement → compile → evaluate loops; students practice agent-supervised optimization tasks
- Assumptions/Dependencies: Access to GPUs in lab settings; curated curricula aligned with agent workflows; monitoring to prevent inappropriate tool use
Long-Term Applications
The following applications require additional research, cross-platform support, broader standards, or scaling to diverse hardware and workloads. They build on the paper’s agentic RL framework, reward design, and anti-hacking mechanisms.
- Cross-platform kernel generation beyond CUDA (ROCm, SYCL/oneAPI, Metal)
- Sector: Software/AI infrastructure, Cloud, HPC
- Tools/Products/Workflows: “Universal Kernel Agent” that targets multiple backends; portability layers integrated with framework compilers (TorchInductor, TVM)
- Assumptions/Dependencies: Robust multi-backend profiling/verification; access to diverse GPUs (AMD/Intel/Apple); backend-specific skill modules and data
- Autonomic compilers that learn optimization policies
- Sector: Compiler/toolchain vendors
- Tools/Products/Workflows: Agent-driven heuristics replacing static fusion/tuning rules; plug-in optimizers for graph compilers; offline/online learning from production traces
- Assumptions/Dependencies: High-quality RL signals in complex graphs; safe integration into compile/runtime phases; certification processes for correctness and stability
- Runtime self-optimizing systems (adaptive kernels under varying loads)
- Sector: Cloud, Edge, Robotics, Real-time systems
- Tools/Products/Workflows: Agents adapt kernels on live telemetry (input sizes, cache hit rates, contention); feedback loops with guardrails and rollback; AIOps for cost-aware optimization
- Assumptions/Dependencies: Low-overhead telemetry; safe hot-swapping of kernels; robust rollback and SLO enforcement; policy constraints for live systems
- Hardware–software co-design via agent exploration
- Sector: Semiconductor, Systems architecture
- Tools/Products/Workflows: Agents explore tiling/memory patterns to reveal hardware bottlenecks; inform future GPU features (SMEM capacity, scheduler hints) and ISA evolutions
- Assumptions/Dependencies: Access to detailed hardware counters; tight collaboration with hardware teams; longitudinal studies across generations
- Formal correctness and certification pipelines for safety-critical domains
- Sector: Healthcare (medical imaging), Finance (risk modeling), Aerospace
- Tools/Products/Workflows: Integrating formal methods, model checking, and adversarial testing into the agent loop; certification workflows for kernel correctness and numeric stability
- Assumptions/Dependencies: Domain-specific standards; extended test suites for edge cases; regulatory adoption and auditing transparency
- Energy- and carbon-aware optimization policies
- Sector: Energy, Cloud sustainability, Policy
- Tools/Products/Workflows: Agents optimize for performance-per-watt; carbon-aware scheduling (time-of-day, grid mix); green AI scorecards tied to kernels
- Assumptions/Dependencies: Reliable power/thermal telemetry; policy frameworks that reward energy-efficiency; data center cooperation
- End-to-end graph optimization across frameworks and model families
- Sector: ML frameworks (PyTorch, TensorFlow, JAX), Model providers
- Tools/Products/Workflows: Agents co-optimize operator graphs (fusion, layout, parallel mapping) across entire models; transferable recipes across architectures
- Assumptions/Dependencies: Unified IRs and stable graph APIs; comprehensive correctness gates; broad benchmark coverage
- Kernel Optimization-as-a-Service (KOaaS)
- Sector: Cloud services, Enterprise platform offerings
- Tools/Products/Workflows: Managed service that takes user ops/models and returns certified, optimized kernels with SLAs; private sandboxes per customer
- Assumptions/Dependencies: Strong multi-tenant isolation; IP/licensing clarity for generated code; service-level verification and support
- Advanced robotics and edge compute acceleration
- Sector: Robotics, Autonomous systems, AR/VR
- Tools/Products/Workflows: Agents optimize real-time perception/control pipelines; tailored kernels for small-batch, low-latency workloads on edge GPUs
- Assumptions/Dependencies: Availability of CUDA-capable edge devices; tight real-time constraints; domain-specific correctness measures
- Curriculum and standards for agentic performance engineering
- Sector: Education, Professional certification
- Tools/Products/Workflows: Standardized SKILL.md-like blueprints; multi-turn RL education modules; accreditation for “AI Performance Engineer”
- Assumptions/Dependencies: Community acceptance; shared datasets/benchmarks; institutional support
- Evaluation and governance standards to prevent reward hacking
- Sector: Policy, Standards bodies, Industry consortia
- Tools/Products/Workflows: Protocols for file-permission controls, multi-input correctness, isolated measurement pools; reproducibility badges (KernelBench/MultiKernelBench compliance)
- Assumptions/Dependencies: Broad adoption by vendors; independent audit tooling; transparent reporting
- Synthesis for domain-specific accelerators (FPGAs/ASICs)
- Sector: Specialized hardware, EDA
- Tools/Products/Workflows: Agents generate accelerator kernels or HDL templates guided by profiling and correctness checks; co-design with compilers and HLS tools
- Assumptions/Dependencies: Mature toolchains and IRs; domain-specific reward functions; extended correctness models beyond GPU execution
- Triton and IR-level reasoning assistants
- Sector: Programming languages, Compiler research
- Tools/Products/Workflows: Agent skills specialized for Triton/MLIR/TVM IR; mixed CUDA/PTX/Triton optimization passes with unified rewards
- Assumptions/Dependencies: Cross-language correctness bridges; IR instrumentation for profiling; community datasets across languages
Each application leverages the paper’s core innovations: a scalable fused-operator data synthesis pipeline, a skill-integrated CUDA development environment with robust anti-hacking and profiling controls, and algorithmic RL techniques (warm-up via single-turn RL, RFT, value pretraining) that enable stable multi-turn, long-context training. Together, these enable practical deployments today while charting a path toward learned, hardware-aware optimization across the software stack and hardware ecosystems.
Glossary
- agent loop: An iterative reasoning–action–observation workflow the agent follows to code, debug, and optimize kernels. "our agent loop (visualized in \cref{fig:agent_loop})"
- Agent Skills: A structured set of tool-augmented instructions and capabilities provided to the agent for specialized tasks. "Inspired by the idea of Agent Skills \citep{anthropic2025equipping}"
- agentic reinforcement learning: Reinforcement learning where a model acts as an autonomous agent interacting with tools and environments across multiple turns. "a large-scale agentic reinforcement learning system"
- BF16: Brain floating point 16-bit; a reduced-precision numeric format used to accelerate training/inference. "BF16 vs FP16"
- Compile mode: PyTorch’s compiled execution path (e.g., via torch.compile) that applies graph-level optimizations. "in both Eager and Compile modes."
- context managers: Python constructs that manage enter/exit behavior to enforce constraints during execution. "using context managers"
- Context window length: The maximum number of tokens the model can process within a single prompt–response context. "Context window length is 32768 for single-turn RL and 131072 for agentic RL."
- CUDA kernel: A GPU function written in CUDA that runs massively parallel on GPU threads/blocks. "CUDA kernel coding"
- device synchronization: Explicit coordination of GPU operations to ensure ordering and accurate timing measurements. "proper device synchronization"
- Docker-based terminal sandbox: An isolated containerized shell environment to safely build and run code. "A Docker-based terminal sandbox handles CPU-centric tasks"
- Eager mode: PyTorch’s immediate execution mode without compilation or graph optimization. "eager mode"
- execution-based rewards: Reward signals derived from actually running code and tests rather than static heuristics. "execution-based rewards"
- Generalized Advantage Estimation: A variance-reduced method for computing advantage estimates in policy-gradient RL. "Generalized Advantage Estimation"
- geometric mean: The multiplicative average used to aggregate speedups across tasks. "the geometric mean of the execution speed-up ratio"
- global-memory materialization: Writing intermediate results to global GPU memory instead of keeping them on-chip, often hurting performance. "intermediate global-memory materialization"
- GPU sandbox: An isolated GPU execution environment used for correctness checks and profiling. "GPU sandbox pool"
- HBM: High Bandwidth Memory; on-package GPU memory with very high throughput. "HBM capacity"
- importance sampling ratio: In PPO-like algorithms, the ratio of new to old policy probabilities used for stable policy updates. "importance sampling ratio between the current and old policies"
- kernel fusion: Combining multiple operations into a single GPU kernel to reduce memory traffic and launch overhead. "patterns for kernel fusion"
- KernelBench: A benchmark evaluating whether LLMs can write efficient GPU kernels across difficulty levels. "KernelBench"
- Mixture-of-Experts (MoE): A neural architecture that routes inputs among multiple expert subnetworks to increase capacity efficiently. "Mixture-of-Experts (MoE)"
- Monte Carlo Graph Search: A search method that explores a graph using stochastic rollouts to guide decisions. "Monte Carlo Graph Search"
- Nsight Compute: NVIDIA’s low-level GPU profiler for analyzing kernel performance bottlenecks. "Nsight Compute profiling"
- occupancy: The degree to which GPU execution resources are utilized (e.g., active warps per SM). "register/SMEM/occupancy constraints"
- OpenHands framework: An open platform for building and evaluating tool-using coding agents. "OpenHands framework"
- operator fusion: Fusing sequential operators to avoid intermediate memory writes and improve performance. "operator fusion"
- parallel mapping: Assigning computation across threads/warps/blocks to exploit parallel hardware efficiently. "a unified parallel mapping"
- policy collapse: A failure mode in RL where the policy becomes degenerate or uninformative during training. "prevents policy collapse."
- PPO: Proximal Policy Optimization; a clipped policy-gradient algorithm for stable RL training. "We employ PPO~\citep{schulman2017proximal} to optimize the actor model"
- profiling pipeline: The engineered process and scripts used to measure and analyze performance reliably. "the profiling pipeline is carefully engineered"
- ReAct: A prompting paradigm interleaving reasoning steps with tool actions and observations. "ReAct-style paradigm"
- rejection sampling: Filtering rollouts by retaining only those that meet specified quality criteria. "Rejection sampling is performed"
- Rejection Fine-Tuning (RFT): Supervised fine-tuning on filtered, high-quality trajectories to stabilize downstream RL. "Rejection Fine-Tuning (RFT)"
- retrieval-augmented framework: A system that augments generation with retrieved artifacts or traces to guide optimization. "retrieval-augmented framework"
- reward hacking: Exploiting loopholes in the evaluation to obtain high rewards without genuinely solving the task. "to prevent reward hacking"
- robust reward schedule: A discretized, normalized reward design intended to reduce noise and bias across tasks. "our robust reward schedule"
- SMEM: On-chip shared memory (CUDA shared memory) accessible to threads in a block. "register/SMEM/occupancy constraints"
- tiling strategies: Decomposing data/computation into tiles to improve locality and parallel efficiency. "tiling strategies that remain inaccessible to static backends."
- torch.compile: PyTorch’s compilation entry point that captures graphs and applies backend optimizations. "torch.compile"
- tree-structured search space: An exploration space where each refinement or decision branches from previous nodes. "tree-structured search space"
- Value Pretraining: Pretraining the critic/value network on trajectories to provide stable advantage estimates before RL. "Value Pretraining"
- value function: A function estimating expected return from a given state (or state–action). "Explained Variation of Value Function."
Collections
Sign up for free to add this paper to one or more collections.