CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning
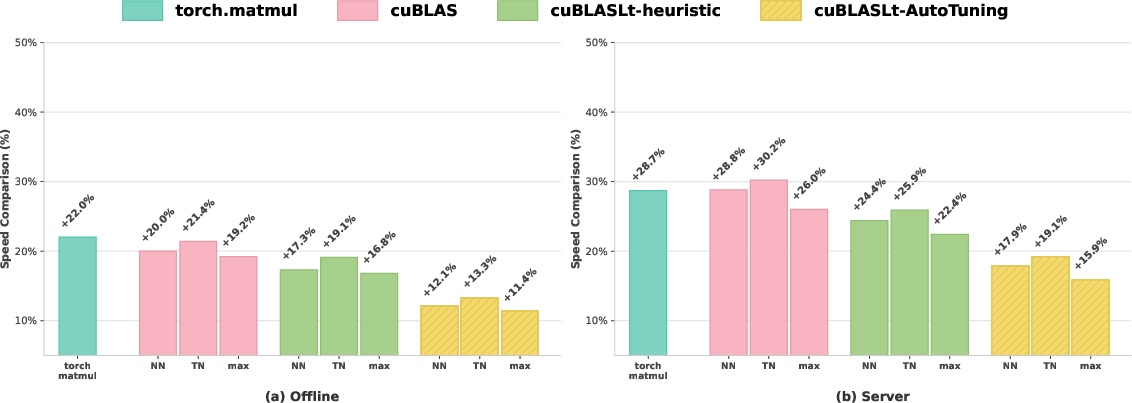
Abstract: In this paper, we propose CUDA-L2, a system that combines LLMs and reinforcement learning (RL) to automatically optimize Half-precision General Matrix Multiply (HGEMM) CUDA kernels. Using CUDA execution speed as the RL reward, CUDA-L2 automatically optimizes HGEMM kernels across 1,000 configurations. CUDA-L2 systematically outperforms major matmul baselines to date, from the widely-used {\it torch.matmul} to state-of-the-art Nvidia's closed-source libraries, i.e., {\it cuBLAS}, {\it cuBLASLt}. In offline mode, where kernels are executed consecutively without time intervals, CUDA-L2 yields +22.0\% over {\it torch.matmul} on average; +19.2\% over {\it cuBLAS} using the optimal layout configuration (normal-normal NN and transposed-normal TN); +16.8\% over {\it cuBLASLt-heuristic}, which queries {\it cuBLASLt} library and selects the algorithm based on the heuristic's suggestion; and +11.4\% over the most competitive {\it cuBLASLt-AutoTuning} model, which selects the fastest algorithm from up to 100 candidates from {\it cuBLASLt}'s suggestions. In server mode, where kernels are executed at random intervals simulating real-time inference, the speedups further increase to +28.7\%, +26.0\%, +22.4\%, and +15.9\% for {\it torch.matmul}, {\it cuBLAS}, {\it cuBLASLt-heuristic}, and {\it cuBLASLt-AutoTuning} respectively. CUDA-L2 shows that even the most performance-critical, heavily-optimized kernels like HGEMM can be improved through LLM-guided RL automation by systematically exploring configuration spaces at scales impractical for humans. Project and code can be found at github.com/deepreinforce-ai/CUDA-L2

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning”
Overview
This paper is about speeding up a core math operation used in AI models called matrix multiplication. Think of a matrix as a big grid of numbers. Multiplying two matrices is like combining rows from one grid with columns from another to make a new grid. This operation is everywhere in modern AI, especially LLMs.
The authors built a system called CUDA-L2 that uses an AI model (a LLM) plus a training method called reinforcement learning to automatically write super-fast code for matrix multiplication on NVIDIA GPUs. Their code often runs faster than the best official NVIDIA libraries (cuBLAS and cuBLASLt), which are already highly optimized by experts.
Key Objectives and Questions
Here are the main goals the paper tries to achieve:
- Can an AI system automatically write GPU code for matrix multiplication that beats expert-tuned libraries?
- Can it handle many different matrix sizes (1,000 combinations) that show up in real LLMs?
- Will it stay correct (give the right answers) while getting faster?
- How well does it work in two real-world scenarios: nonstop heavy use (offline) and on-demand requests (server)?
Methods and Approach (in everyday terms)
The team combined a code-writing AI with reinforcement learning (RL). Reinforcement learning is like training by trial and error: the AI writes a piece of code, runs it, gets a score based on how fast it is (and how correct), and then tries again, learning to improve.
Here’s how they made it work:
- They trained their AI on lots of CUDA (GPU) code, not just one small benchmark. This gives it broader “coding instincts.”
- They trained in stages: first on many general GPU tasks, then focusing more narrowly on matrix multiplication.
- They used a “speed reward”: faster code gets a higher score. If the code is wrong or suspicious, the score gets penalized.
- They checked correctness carefully. For example, they compared results against a trusted CPU version and used tests that force exact answers for certain inputs.
- They prevented cheating in timing measurements (so the AI can’t fake being fast) and used standard GPU timing tools.
- They tested across 1,000 different matrix sizes (M, N, K picked from common sizes used in LLMs) and two usage modes:
- Offline mode: run kernels back-to-back nonstop (like an assembly line that never stops).
- Server mode: run kernels at random times (like orders arriving at a restaurant—sometimes busy, sometimes quiet).
- They also included deep performance data (like memory speed and how busy the GPU cores are) to help the AI learn smarter optimizations.
Main Findings and Why They Matter
Big picture: CUDA-L2 beat strong baselines, including NVIDIA’s cuBLAS/cuBLASLt. Here are the headline numbers (average improvements across 1,000 matrix sizes):
- In offline mode:
- About 22% faster than PyTorch’s torch.matmul.
- About 19% faster than cuBLAS (using the best layout).
- About 17% faster than cuBLASLt using its heuristic pick.
- About 11% faster than cuBLASLt AutoTuning (which tries up to ~100 algorithm variants).
- In server mode (on-demand requests), the gains are even bigger:
- About 29% faster than torch.matmul.
- About 26% faster than cuBLAS.
- About 22% faster than cuBLASLt heuristic.
- About 16% faster than cuBLASLt AutoTuning.
Why this matters:
- These libraries are already extremely optimized by experts. Beating them suggests AI-guided automation can push performance further by exploring huge design spaces that are impractical for humans to search by hand.
- Faster matrix multiplication means faster and cheaper AI inference (answering queries) and training. That can save money, reduce energy use, and unlock smoother real-time experiences.
Extra observations:
- The speed advantage is largest for smaller matrices. As matrices get very big, the GPU becomes fully loaded, leaving less room for improvement.
- If users can choose the fastest of either CUDA-L2 or the baseline per case, they get even more speed overall.
Implications and Potential Impact
- Automating performance tuning: CUDA-L2 shows that AI plus reinforcement learning can discover clever GPU tricks—like better memory layouts, smarter prefetching (loading data before it’s needed), and more efficient pipelines—across many matrix sizes.
- Real-world benefit: Faster kernels help make LLMs and other AI models run quicker and cheaper, especially under real server conditions.
- Broader reach: The current system targets NVIDIA A100 GPUs, but the approach is designed to extend to other GPU families (Ada, Hopper, Blackwell, etc.).
- Future promise: As AI-driven optimization improves and covers more hardware types, developers may rely less on manual tuning and more on automated systems that continually adapt and improve.
In short, this paper shows that AI can write high-performance GPU code that beats top expert libraries for a critical AI operation. That’s a big step toward smarter, faster, and more efficient AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could address:
- Architecture generalization: results are limited to A100; evaluate portability and required re-tuning on RTX 3090/4090 (Ampere/Ada), H100 (Hopper), and B200 (Blackwell), with consistent driver/CUDA versions and clocks/ECC settings.
- Precision and accumulator coverage: extend beyond FP16 inputs and C=AB (α=1, β=0) to BF16, TF32, FP32, INT8, and mixed-precision accumulators (FP16 vs FP32); quantify accuracy–performance trade-offs.
- GEMM forms and epilogues: support nonzero α/β, fused epilogues (bias, activation, scaling), strided/batched/Grouped GEMM; measure end-to-end gains in LLM layers (attention, MLP).
- Shape generalization: test irregular, non-power-of-two sizes (e.g., 3072, 6144, 12288±256), very small (<64), extreme aspect ratios; report whether the learned policies generalize or require per-shape specialization.
- Layout coverage: include NT and TT layouts and column-major inputs; account for data-layout conversions and measure their end-to-end cost.
- Padding strategy details: specify how zero-padding is implemented (masked loads vs memory reallocation), how extra rows are discarded, and its impact on memory footprint and allocator behavior in real frameworks.
- Automatic kernel selection: provide a low-overhead runtime policy to choose between CUDA-L2 and baselines per configuration; quantify selection accuracy, overhead, and guardrails against regressions.
- Framework integration: demonstrate drop-in use in PyTorch/TensorRT/TVM with CUDA Graph capture; report model-level throughput/latency improvements on representative LLM inference/training pipelines.
- Server-mode realism: define the arrival process (distribution, load), concurrency (multi-stream/multi-tenant), batching, and scheduling; include intervals in end-to-end latency and test cache/clock dynamics under realistic workloads.
- Concurrency restrictions: forbidding additional CUDA streams prevents overlap; explore timing methods that remain robust without disabling streams and evaluate performance under multi-stream overlap.
- Compilation/JIT cost: report kernel generation/compile times, binary size, caching strategy, and cold-start penalties; investigate PTX/SASS JIT or runtime specialization to reduce deployment overhead.
- Correctness robustness: expand tests to random real-valued inputs, NaNs/Infs, denormals, extreme magnitudes; verify determinism and backprop correctness; use compute-sanitizer racecheck/synccheck in addition to memcheck.
- Numerical error policy: justify deviation thresholds with relative/ULP metrics; compare accuracy against cuBLAS/cuBLASLt across accumulator choices; expose accuracy–latency trade-offs.
- Component ablations: quantify the individual impact of continued pretraining, contrastive RL, NCU metric conditioning, and retrieval augmentation; analyze interactions and necessity of each piece.
- Training efficiency and cost: disclose RL episodes per configuration, wall-clock time, compute budget, and sample efficiency; study scaling laws with number of configurations and architectures.
- Reward shaping sensitivity: analyze the effects of code-length and deviation penalties on performance; ensure brevity bias does not suppress necessary optimizations; provide tuning guidelines.
- Profiling-in-the-loop overhead: detail how NCU metrics are collected (frequency, subset), instrumentation cost, and whether profiling perturbs training/evaluation; consider lightweight proxies.
- Benchmark fairness and coverage: verify optimal cuBLAS/cuBLASLt settings (workspace, math modes); add baselines from tuned CUTLASS kernels, Triton, TVM/Ansor, and recent RL/LLM kernel generators (e.g., AI CUDA Engineer); include Grouped GEMM.
- Thermal/power rigor: control and report power states, clocks, ECC/MIG, ambient; provide confidence intervals and statistical significance; measure energy efficiency (performance per watt).
- Resource/portability constraints: report shared memory/register usage and occupancy; assess portability to GPUs with different SM/shared memory limits; add launch guardrails and fallbacks.
- Data movement accounting: include costs for transposes/memory-format conversions required by each layout in end-to-end measurements.
- Maintainability and safety: assess readability and long-term stability of generated code under CUDA/toolchain upgrades; incorporate static analysis, unit tests, and sanitizers into the pipeline.
- Beyond matmul: evaluate transferability of the RL pipeline to other production-critical kernels (attention, softmax, layernorm, activations, reductions) at scale.
- Deployment/versioning: define how architecture-specific kernels are versioned, validated, and updated across driver/CUDA changes under a unified interface.
- Max(CUDA-L2, baseline) overhead: quantify runtime probing/selection cost and cold-start impact; propose lightweight predictors to avoid measurement-based selection on the critical path.
- Reproducibility: release the full benchmarking harness, exact environment specs (driver/CUDA/NCCL, clocks, ECC), random seeds, and per-configuration results with confidence intervals.
- Novelty validation: distinguish “discovered” techniques (e.g., staggered prefetch, ping-pong buffering) from existing CUTLASS/CuTe patterns; provide citations or empirical novelty analyses.
Practical Applications
Applications of CUDA-L2: Practical, Real-World Uses
Below are the practical applications derived from the paper’s findings, methods, and innovations. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring additional research, scaling, or development). Each item includes sectors, likely tools or products, and assumptions or dependencies that may affect feasibility.
Immediate Applications
- Drop-in acceleration of LLM inference on A100-based services — Replace existing HGEMM paths with CUDA-L2 kernels to reduce latency and increase throughput for attention and FFN layers commonly used in Qwen, Llama, DeepSeek.
- Sectors: software/cloud, AI infrastructure
- Tools/workflows: PyTorch custom ops, TensorRT plugin, ONNX Runtime EP, dynamic runtime selection “max(CUDA-L2, baseline)” for each (M,N,K)
- Assumptions/dependencies: FP16 HGEMM; A100 GPUs; target shapes among the 1,000 MNK configurations; integration and correctness validation in the hosting framework
- Lower compute costs and energy consumption for AI serving — Use server-mode speedups (+15.9% vs cuBLASLt-AutoTuning, +28.7% vs torch.matmul) to cut GPU-hours and power bills for real-time inference endpoints.
- Sectors: energy, finance, cloud operations
- Tools/workflows: cost/performance dashboards, power telemetry, autoscaling policies adjusted to improved throughput
- Assumptions/dependencies: workloads dominated by matmul; benefits greatest for small-to-mid matrix sizes; datacenter uses A100
- High-availability, low-latency consumer AI experiences — Faster chatbots, search assistants, coding copilots, and customer support agents due to better server-mode matmul performance under sporadic request arrivals.
- Sectors: consumer software, e-commerce, customer service
- Tools/workflows: model serving platforms (NVIDIA Triton Inference Server, Ray Serve, SageMaker endpoints), traffic-aware kernel selection
- Assumptions/dependencies: end-to-end latency is matmul-bound; integration preserves numerical tolerances required by application
- Throughput boosts for batch jobs and micro-batch inference — In offline mode, exploit +11–22% average gains to process more requests or larger contexts per unit time.
- Sectors: cloud batch processing, content moderation, data labeling
- Tools/workflows: pipeline schedulers (Airflow, Argo), batch drivers tuned for CUDA-L2 kernels
- Assumptions/dependencies: batch jobs utilize FP16 matmul; shapes align with optimized configurations; diminishing gains for very large matrices
- On-prem AI acceleration for robotics and industrial automation — Improve perception and planning model inference on A100 servers in factories and labs.
- Sectors: robotics, manufacturing, logistics
- Tools/workflows: ROS-based AI nodes, real-time inference runtimes, CUDA-L2-backed HGEMM ops in perception stacks
- Assumptions/dependencies: precision requirements aligned with FP16; deterministic correctness bounds acceptable
- “Max-of-portfolio” kernel selection in production runtimes — Implement an automated fallback to whichever kernel (CUDA-L2 or cuBLAS/cuBLASLt) is fastest per MNK triplet with caching.
- Sectors: software, AI infrastructure
- Tools/workflows: heuristic selector, caching of per-shape winners, startup warmup to precompute winners
- Assumptions/dependencies: shape distribution is stable or cache refreshed; selector overhead negligible
- CI-driven performance engineering — Integrate CUDA-L2’s evaluation harness (Nsight Compute metrics + correctness tests) into CI to catch regressions and auto-tune new shapes seen in production traces.
- Sectors: software engineering, MLOps
- Tools/workflows: Nsight Compute integration, speedup/variance gates, correctness (binary-input exact match and baseline-bounded deviation) checks
- Assumptions/dependencies: access to representative traces; CI runners with A100; tolerance thresholds defined per product
- Academic teaching and reproducible systems research — Use the open repository to teach LLM-guided RL for systems optimization, including timing safeguards and profiling-driven context.
- Sectors: academia
- Tools/workflows: course labs, research projects benchmarking CUDA-L2 vs. cuBLAS/cuBLASLt; GRPO training demonstrations
- Assumptions/dependencies: A100 access; curricula covering CUDA/CuTe/CUTLASS; safe sandboxing for kernel generation/execution
- Vendor-neutral benchmarking augmentation — Emulate MLPerf-like offline/server distinctions and correctness gates to evaluate matmul kernels in realistic scenarios.
- Sectors: benchmarking, standards organizations
- Tools/workflows: offline vs server test harness, random-order execution, warmup behavior capture; public reporting of win rates and speedup distributions
- Assumptions/dependencies: agreement on methodologies; hardware availability; governance for benchmark updates
- Library contributions and kernel portfolio hardening — Feed discovered techniques (e.g., double-buffered fragments, staggered prefetch, direct wide epilogue copies, block swizzle choices) back into CuTe/CUTLASS and internal codebases.
- Sectors: software tooling, open-source ecosystems
- Tools/workflows: PRs to CUTLASS/CuTe, internal kernel repos with per-architecture variants
- Assumptions/dependencies: maintainers accept contributions; methods validated across edge cases and numerics
Long-Term Applications
- Cross-architecture portability and scale-out — Extend CUDA-L2 to Ada, Hopper, Blackwell, and consumer Ampere; maintain per-architecture RL tuning with retrieval-augmented contexts reflecting hardware characteristics.
- Sectors: software/cloud, semiconductor ecosystems
- Tools/workflows: multi-arch build/test pipelines, per-GPU kernel catalogs, automated feature flagging
- Assumptions/dependencies: access to diverse GPUs; architecture-specific instruction sets and memory hierarchies; reward functions adapted per arch
- Generalization beyond HGEMM — Apply the LLM+RL pipeline to other performance-critical ops (BF16 GEMM, INT8 GEMM, convolutions, attention kernels, reductions, embeddings).
- Sectors: deep learning frameworks, HPC
- Tools/workflows: operator registries, per-operator RL training datasets, cross-op correctness suites
- Assumptions/dependencies: reference implementations; precision/quantization nuances; larger search spaces and reward design
- Online, adaptive auto-tuning in production — Continuously learn and update kernels from live traffic (shape distributions, cache temperature, power/thermal telemetry) and deploy improvements safely with canarying.
- Sectors: cloud, MLOps
- Tools/workflows: online RL or bandits, canary rollout, rollback triggers, telemetry-driven reward shaping
- Assumptions/dependencies: safe exploration budgets; robust anti-hacking timing measures; governance for correctness regressions
- Compiler and framework integration — Embed RL-discovered schedules into nvcc, CUTLASS/CuTe templates, or PyTorch JIT passes; co-design with autotuners to pick schedules at compile-time or install-time.
- Sectors: compilers, ML frameworks
- Tools/workflows: schedule databases, intermediate representation (IR) hooks, installer-time shape probing
- Assumptions/dependencies: compiler extensibility; IR stability; license and IP considerations
- Energy-aware kernel selection and carbon budgeting — Choose kernels optimizing performance-per-watt or meeting power caps; integrate with datacenter sustainability targets and carbon reporting.
- Sectors: energy, policy, cloud sustainability
- Tools/workflows: power telemetry, per-kernel energy models, SLOs blending latency and energy
- Assumptions/dependencies: accurate power sensing; standardized reporting; multi-objective optimization policies
- Formal verification and safety envelopes for numerics — Strengthen correctness with formal methods (beyond baseline-bounded deviation) for healthcare imaging, autonomous driving, and finance risk models.
- Sectors: healthcare, automotive, finance
- Tools/workflows: SMT-based checks for floating-point properties, tolerance-aware acceptance tests, regulatory audit trails
- Assumptions/dependencies: domain-specific correctness definitions; regulator acceptance of floating-point variability bounds
- Hardware–software co-design feedback loops — Use CUDA-L2’s learned strategies (e.g., bank conflict swizzles, multi-stage pipelines) to inform future GPU microarchitectural features and memory subsystem designs.
- Sectors: semiconductor, systems research
- Tools/workflows: simulation harnesses, joint design reviews, synthetic kernels emphasizing bottlenecks
- Assumptions/dependencies: vendor collaboration; non-disclosure constraints; alignment with silicon roadmaps
- Distributed and grouped GEMM optimization — Extend tuning to multi-GPU and grouped GEMM scenarios (e.g., tensor-parallel attention blocks) to maximize speedups across pipeline/model-parallel topologies.
- Sectors: large-scale training/inference
- Tools/workflows: NCCL-aware scheduling, collective-optimized matmul variants, topology-aware swizzle/prefetch strategies
- Assumptions/dependencies: interconnect characteristics (NVLink/PCIe), synchronization overheads, grouped GEMM shape distributions
- Standards and procurement guidelines — Encourage adoption of server-mode benchmarks and anti-timing-hack practices in industry standards; guide procurement to prioritize systems with automated kernel optimization.
- Sectors: policy, enterprise IT
- Tools/workflows: updated benchmark specs, RFP criteria including automated optimization capabilities
- Assumptions/dependencies: consensus in standards bodies; clear vendor disclosures; measurable compliance
- Consumer benefits via cost pass-through — As infra costs drop, offer lower-priced AI subscriptions or higher quotas; enable richer real-time features in consumer apps.
- Sectors: consumer software, education
- Tools/workflows: pricing models reflecting lower GPU-hours, feature rollouts leveraging lower latency
- Assumptions/dependencies: cloud providers pass savings downstream; user demand aligns with latency-sensitive features
Notes on feasibility across all applications:
- Speedups are largest for small-to-mid matrix sizes; gains diminish for very large matrices that already saturate GPU compute.
- Current implementation targets FP16 HGEMM on A100; porting to other precisions (BF16/FP32) and architectures requires additional engineering.
- Integration must maintain numerical correctness within application-tolerated bounds; formal guarantees are advisable in safety-critical domains.
- Reward and timing safeguards (e.g., disallowing extra streams, .cu-only kernels, synchronizations) should be preserved in any extended optimization pipeline.
Glossary
- A100: NVIDIA data center GPU model from the Ampere generation, commonly used for AI workloads. "While the current version of CUDA-L2 only focuses on A100 GPUs"
- Ada Lovelace: NVIDIA GPU architecture generation (e.g., RTX 4090) succeeding Ampere. "including Ada Lovelace, Hopper and Blackwell."
- Ampere: NVIDIA GPU architecture generation (e.g., A100) with FP16 Tensor Cores. "with the {\it CUBLAS_GEMM_DEFAULT_TENSOR_OP} operation to enable Ampere FP16 Tensor Cores"
- bank conflict: A shared memory access hazard where multiple threads target the same memory bank, causing serialization. "Shared memory with bank conflict avoidance, which uses a swizzle pattern to reorganize data layout, preventing conflicts from multiple threads accessing the same memory bank."
- Baseline-Bounded Deviation: A correctness criterion that bounds numerical error by the maximum deviation among trusted baselines. "Baseline-Bounded Deviation"
- Blackwell: NVIDIA GPU architecture generation (e.g., B200) succeeding Hopper. "Blackwell (e.g., B200)."
- block swizzle: A thread-block scheduling/reordering technique to improve L2 cache locality and hit rates. "Block swizzle is parameterized by {\it swizzle_stride}, which determines the stride pattern used to reorder block indices."
- CUBLAS_GEMM_DEFAULT_TENSOR_OP: cuBLAS operation mode that enables Tensor Core usage for GEMM. "with the {\it CUBLAS_GEMM_DEFAULT_TENSOR_OP} operation to enable Ampere FP16 Tensor Cores"
- compute-sanitizer: NVIDIA tool to detect GPU memory errors and other issues. "{\it compute-sanitizer --tool memcheck} is used to check for memory access violations."
- cublasGemmEx: cuBLAS API for GEMM supporting various data types and Tensor Core configurations. "We use the {\it cublasGemmEx} function offered by NVIDIA’s {\it cuBLAS} library"
- cublasLtMatmulAlgoGetHeuristic: cuBLASLt API that returns heuristic-ranked GEMM algorithm candidates. "uses NVIDIA's {\it cublasLtMatmulAlgoGetHeuristic} API"
- CUDA: NVIDIA’s parallel computing platform and programming model for GPUs. "CUDA-L2, a system that combines LLMs and reinforcement learning (RL) to automatically optimize Half-precision General Matrix Multiply (HGEMM) CUDA kernels."
- cuBLAS: NVIDIA’s high-performance GPU-accelerated BLAS library for linear algebra operations. "NVIDIA’s {\it cuBLAS} library provides a strong optimized baseline"
- cuBLASLt: A lower-level, tunable interface to NVIDIA’s GEMM implementations, exposing algorithm choices. "{\it cuBLASLt} provides a lower-level, more controllable interface to NVIDIA’s optimized GEMM kernels"
- cuBLASLt-AutoTuning: Exhaustive selection process in cuBLASLt to choose the fastest GEMM algorithm among many candidates. "and +11.4\% over the most competitive {\it cuBLASLt-AutoTuning} model"
- cuBLASLt-heuristic: cuBLASLt setup that picks the top heuristic-recommended GEMM algorithm. "+16.8\% over {\it cuBLASLt-heuristic}, which queries {\it cuBLASLt} library and selects the algorithm based on the heuristic's suggestion"
- CUTLASS: NVIDIA’s CUDA templates for GEMM and related operations, used to build high-performance kernels. "such as newer {\it CUTLASS} versions"
- CuTe: CUTLASS’s “Cute” library providing abstractions for tiled MMA and pipeline operations. "the {\it CuTe} library"
- epilogue: Final kernel phase that writes accumulated results from registers back to memory. "Finally, in the epilogue phase, the accumulated results are written back from registers to shared memory, and then from shared memory to global memory."
- FFN: Feed-Forward Network layers in transformer architectures. "used in attention and FFN layers of widely open-sourced models like Qwen, Llama and DeepSeek."
- FP16: 16-bit floating-point precision (“half”), often accelerated by Tensor Cores. "accumulator precision, where using FP16 versus FP32 accumulators (both valid choices for FP16 inputs) leads to different register pressure"
- FP32: 32-bit floating-point precision used for higher numerical accuracy. "accumulator precision, where using FP16 versus FP32 accumulators (both valid choices for FP16 inputs) leads to different register pressure"
- GEMM: General Matrix Multiply, core linear algebra operation used in deep learning. "{\it cuBLASLt} provides a lower-level, more controllable interface to NVIDIA’s optimized GEMM kernels"
- GRPO: Reinforcement learning optimization method used for updating LLM parameters. "GRPO \cite{guo2025deepseek, shao2024deepseekmath} is adopted for LLM parameter updates."
- Grouped GEMM: Batch of smaller GEMMs executed together for throughput improvements. "This is evidenced by the 13\% speedup from targeted Grouped GEMM optimizations for the deepseek-R1 model"
- HGEMM: Half-precision GEMM specialized for FP16 inputs. "Half-precision General Matrix Multiplication (HGEMM) is one of the most widely used matmul kernels in current LLMs."
- Hopper: NVIDIA GPU architecture generation (e.g., H100). "Hopper (e.g., H100)"
- L2 cache: On-GPU cache level used to buffer global memory data and improve access locality. "which improves L2 cache hit rates by reordering thread block execution"
- MLPerf: Industry-standard benchmark suite for measuring machine learning performance. "Following MLPerf \cite{mattson2020mlperf, reddi2020mlperf}, a widely-used benchmark criteria for machine learning performance"
- NCU (NVIDIA Nsight Compute): NVIDIA profiler providing detailed kernel metrics like occupancy and throughput. "including more comprehensive NCU (NVIDIA Nsight Compute) profiling metrics (e.g., memory throughput, SM occupancy, cache efficiency)"
- NN layout: GEMM layout where both A and B are in “normal” (row-major) form. "Comparing TN (transposed-normal) and NN (normal-normal) layouts, the NN layout slightly outperforms TN across all libraries."
- offline mode: Benchmark scenario with back-to-back kernel execution without pauses. "(a) Offline scenario: kernel executed consecutively without time intervals."
- PTX: NVIDIA’s intermediate assembly language for CUDA kernels. "CUDA C/C++, CuTe, inline PTX assembly, CUDA intrinsics, and CUTLASS templates can be used"
- register pressure: Resource constraint when kernels use many registers, potentially reducing occupancy and performance. "leads to different register pressure and thus different optimization strategies."
- reinforcement learning (RL): Learning paradigm optimizing kernel performance using rewards (e.g., speed). "we propose CUDA-L2, a system that combines LLMs and reinforcement learning (RL) to automatically optimize matmul CUDA kernels."
- retrieval-augmented context: Technique to enrich model inputs with external documents or code for better decisions. "incorporating retrieval-augmented context to accommodate new knowledge or architectural characteristics not covered in the foundation model."
- server mode: Benchmark scenario with random intervals simulating real-time inference. "(b) Server scenario: kernel executed at intervals, simulating real-time inference."
- shared memory: On-chip memory used to stage tiles and reduce global memory accesses. "Tiles of size BM × BK from A and BK × BN from B are loaded from global memory into shared memory"
- SM occupancy: Fraction of active warps per Streaming Multiprocessor indicating execution parallelism. "including more comprehensive NCU (NVIDIA Nsight Compute) profiling metrics (e.g., memory throughput, SM occupancy, cache efficiency)"
- swizzle pattern: Address permutation strategy to avoid shared memory bank conflicts or improve cache locality. "Shared memory with bank conflict avoidance, which uses a swizzle pattern to reorganize data layout"
- tensor cores: Specialized GPU units for fast matrix multiply-accumulate on low-precision data. "Once in registers, tensor cores perform the actual matrix multiply-accumulate operations."
- torch.matmul: PyTorch high-level matrix multiplication API that dispatches to backend libraries. "PyTorch's {\it torch.matmul} naturally constitutes a baseline."
- Triton: Python-based DSL for writing GPU kernels. "Therefore, CUDA C/C++, CuTe, inline PTX assembly, CUDA intrinsics, and CUTLASS templates can be used, but not Python-based DSLs like Triton."
- WMMA: Warp Matrix Multiply Accumulate intrinsics for Tensor Core operations. "For smaller matrices, it generates lightweight kernels directly using raw WMMA."
- warp occupancy: Measure of how many warps are active on an SM, affecting throughput. "such as memory throughput, compute utilization, warp occupancy, and cache hit rates"
Collections
Sign up for free to add this paper to one or more collections.

