- The paper presents Astra, a multi-agent system that refines CUDA kernels through specialized agents, achieving a 1.32× speedup over baseline implementations.
- The paper leverages advanced optimization techniques like loop transformations, vectorized memory access, and CUDA intrinsics to improve kernel performance.
- The paper validates optimized kernels via comprehensive testing and profiling, demonstrating scalability across diverse tensor shapes in real-world LLM serving environments.
Astra: Multi-Agent LLM System for GPU Kernel Optimization
Introduction and Motivation
The paper presents Astra, a multi-agent system leveraging LLMs for the optimization of GPU kernels, specifically targeting existing CUDA implementations extracted from SGLang, a production-grade LLM serving framework. Astra is motivated by the persistent challenge of achieving high-performance GPU kernels, which are critical for efficient LLM training and inference. Manual kernel tuning and compiler-based approaches have limitations in scalability, adaptability, and engineering overhead. Prior LLM-driven efforts have focused on code generation from high-level specifications, but Astra directly addresses the optimization of real-world, deployed CUDA kernels.
Astra decomposes the kernel optimization workflow into specialized agent roles—code generation, testing, profiling, and planning—enabling systematic, iterative refinement of kernels. This multi-agent paradigm is designed to overcome the limitations of single-agent approaches, which struggle to balance correctness, performance, and the complexity of the optimization space.
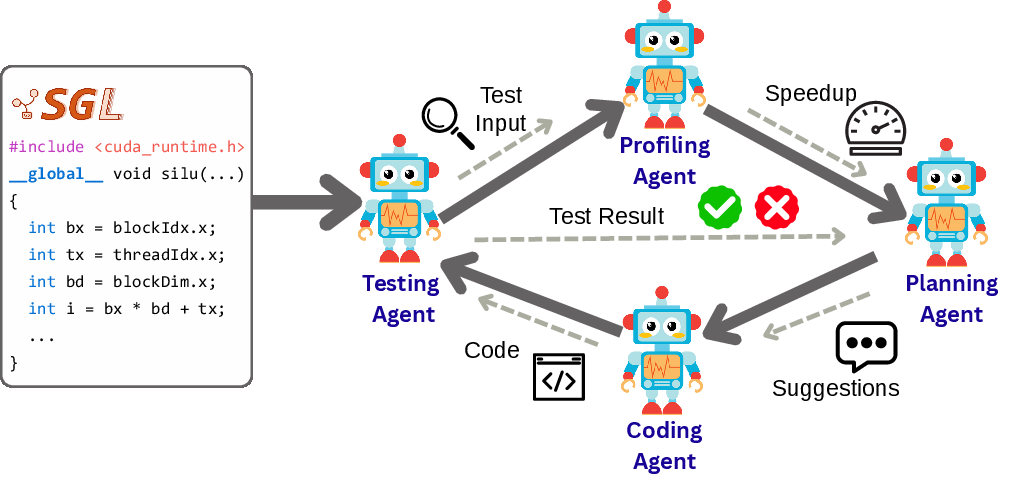
Figure 1: Overview of Astra's multi-agent workflow for GPU kernel optimization, illustrating agent collaboration across code generation, testing, profiling, and planning.
Methodology
Task Definition
Astra formalizes CUDA kernel optimization as the search for an optimized kernel S′ that achieves lower runtime than a baseline S while maintaining functional correctness. Correctness is defined as output equivalence (within a floating-point tolerance) across a diverse test suite, and performance is measured by geometric mean speedup over representative input shapes.
Multi-Agent System Architecture
Astra's architecture consists of four agents:
- Testing Agent: Generates test cases and validates candidate kernels.
- Profiling Agent: Measures execution time and provides performance feedback.
- Planning Agent: Synthesizes correctness and performance signals to propose targeted code modifications.
- Coding Agent: Implements suggested changes to generate new kernel variants.
Agents interact in an iterative loop, with each round producing a candidate kernel, validating correctness, profiling performance, and logging results. The system is implemented using the OpenAI Agents SDK and powered by the o4-mini LLM, with experiments conducted on NVIDIA H100 hardware.
Pre- and Post-Processing
Due to the complexity of SGLang kernels, manual pre-processing is performed to extract and simplify kernels for Astra's input. Post-processing integrates optimized kernels back into SGLang and validates them against the full framework, ensuring drop-in compatibility and accurate performance measurement.
Experimental Results
Astra is evaluated on three representative SGLang kernels: merge, fused, and silu. Across five optimization rounds, Astra achieves an average speedup of 1.32× over the baseline, with all optimized kernels passing correctness validation against manually constructed test suites. Notably, the multi-agent system outperforms a single-agent baseline, which achieves only 1.08× speedup on average. The performance gap widens with kernel complexity, highlighting the efficacy of agent specialization.
Optimization Strategies
Detailed case studies reveal that Astra's agents autonomously apply several advanced optimization techniques:
- Loop Transformations: Hoisting loop-invariant computations to reduce instruction count and improve parallelism.
- Memory Access Optimization: Employing vectorized loads (e.g.,
__half2) to increase memory bandwidth and reduce transaction overhead.
- CUDA Intrinsics: Utilizing warp-level primitives (
__shfl_down_sync) for efficient reductions and register-resident computation.
- Fast Math Operations: Replacing standard library calls with device intrinsics (
__expf, __frcp_rn, __fmul_rn) to lower arithmetic latency.
These strategies collectively contribute to the observed speedups and demonstrate the system's ability to discover non-trivial, hardware-aware optimizations.
Discussion
Impact of Tensor Shapes
Astra's optimizations generalize across diverse tensor shapes, with speedups consistently observed for input dimensions representative of modern LLM workloads. Unlike compiler-based autotuning systems, Astra does not require shape-specific tuning, instead optimizing for general tensor computations.
Limitations and Future Directions
The current evaluation is limited to three kernels and requires manual pre- and post-processing. Automating these steps and extending support to additional frameworks (e.g., vLLM, PyTorch, TorchTitan) are important future directions. Further, integrating training-based methods (e.g., RL fine-tuning) could enhance agent capabilities beyond zero-shot prompting.
Implications and Future Prospects
Astra demonstrates that multi-agent LLM systems can autonomously optimize complex GPU kernels, achieving substantial performance gains without manual intervention or additional training. This paradigm has significant implications for the automation of high-performance code optimization, potentially reducing engineering overhead and accelerating the deployment of efficient ML systems. The approach is extensible to other domains requiring specialized code optimization, such as tensor compilers, DSLs, and hardware-specific libraries.
Theoretical implications include the validation of agent specialization for complex software engineering tasks and the feasibility of LLM-driven, iterative optimization workflows. Practically, Astra's integration with production frameworks like SGLang suggests immediate applicability and impact in large-scale ML serving environments.
Conclusion
Astra introduces a multi-agent LLM system for GPU kernel optimization, directly targeting existing CUDA implementations in production LLM serving frameworks. By decomposing the optimization process into specialized agent roles and leveraging iterative refinement, Astra achieves an average speedup of 1.32× while maintaining correctness. The system autonomously applies advanced optimization strategies, outperforming single-agent baselines and generalizing across diverse tensor shapes. Astra establishes multi-agent LLM systems as a promising paradigm for automated, high-performance code optimization, with broad implications for both research and practical deployment in AI infrastructure.