- The paper proposes a transformer-based paradigm that integrates geometric priors using semantic-aware injection, ensuring accurate metric scale predictions.
- The methodology employs modular token representations and a dedicated metric-scale head that improves depth and point map estimations across diverse datasets.
- Empirical evaluations demonstrate superior performance and generalization on benchmarks like KITTI, ScanNet, and ETH3D, enabling robust robotic perception.
UniScale: Unified Metric 3D Reconstruction with Semantic-Aware Prior Injection for Robust Robotic Perception
Introduction and Motivation
Accurate, robust, and scalable 3D scene reconstruction is a central challenge for robotic perception. Prevailing multi-view neural methods have achieved notable progress by leveraging feed-forward models to jointly predict depth, pose, and point clouds from image streams. However, most existing unified pipelines face limitations regarding metric-scale ambiguity, inflexible integration of geometric priors, and challenges maintaining calibration accuracy across operational contexts. The paper "UniScale: Unified Scale-Aware 3D Reconstruction for Multi-View Understanding via Prior Injection for Robotic Perception" (2602.23224) introduces a modular, scale-aware, and semantically controllable 3D reconstruction paradigm specifically designed to address these deficiencies in the context of multi-sensor robotic platforms. The method centers on a feed-forward, transformer-based network capable of integrating auxiliary geometric priors (e.g., camera intrinsics and extrinsics) in a semantically routed manner, recovering metric scale and providing improved generalizability for downstream robotic tasks.
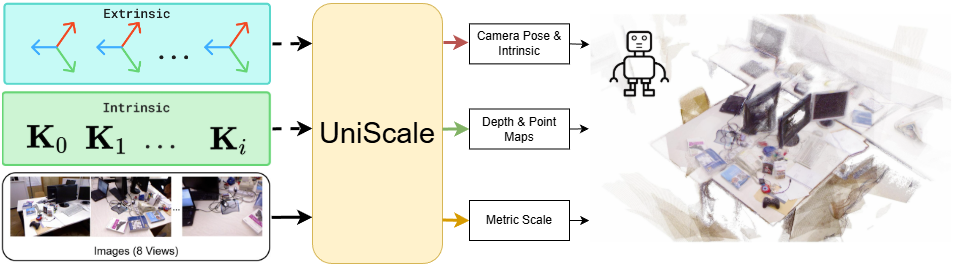
Figure 1: UniScale architecture overview, illustrating end-to-end prediction of depth, point maps, and metric-scale from multi-view imagery, with optional integration of camera intrinsic/extrinsic information.
Architecture and Methodology
UniScale builds on the transformer-based VGGT backbone and extends it with multiple key innovations: a dedicated metric-scale head for absolute scene scale prediction, a semantic-aware prior injection module allowing targeted incorporation of auxiliary cues, and a modular design supporting real-time operation and easy integration into existing robotic perception stacks.
Modular Token-Based Representation
Multi-view image inputs are patchified via a DINOv2 backbone and augmented with class tokens (global scene context), learnable camera tokens (for camera parameters), and register tokens (model stability). These tokens undergo cross-frame and frame-level attention for both global and intra-frame geometric reasoning. The resulting per-frame features are handled by specialized heads: one for camera intrinsics/extrinsics, a DPT-based dense prediction head for depth and point map estimation (scale-invariant), and a dedicated metric-scale head for global scale inference.
Semantic-Aware Prior Injection
Rather than undifferentiated or brute-force prior concatenation, UniScale employs two specialized encoders: an MLP-based pose encoder with 6D continuous parameterization (providing superior optimization properties over quaternions), and a raymap encoder for intrinsics as origin-free ray-images. Pose embeddings are routed to the camera tokens and scale head; ray embeddings are routed to patch tokens, maximizing contextual relevance while minimizing representational noise.
Dedicated Metric-Scale Head
The metric-scale head fuses normalized class, camera, and (downsampled) patch tokens, optionally conditioned on prior embeddings. Adaptive token weighting is achieved through a pseudo-attention module. The final metric scale is inferred via an MLP, with predictions averaged across views for stability.
Training Paradigm
Joint multi-task training employs Huber loss for camera parameters, aleatoric uncertainty-weighted MSE for depth/point map, and log-space L2 loss for metric scale, with selective masking depending on dataset ground-truth scale availability. Probabilistic prior injection ensures robustness to missing priors, supporting universal deployment.
Empirical Evaluation
Multi-View Metric and Dense Reconstruction
UniScale is benchmarked on challenging datasets (KITTI, ScanNet, ETH3D, ScanNet++) and evaluated under varying prior configurations:
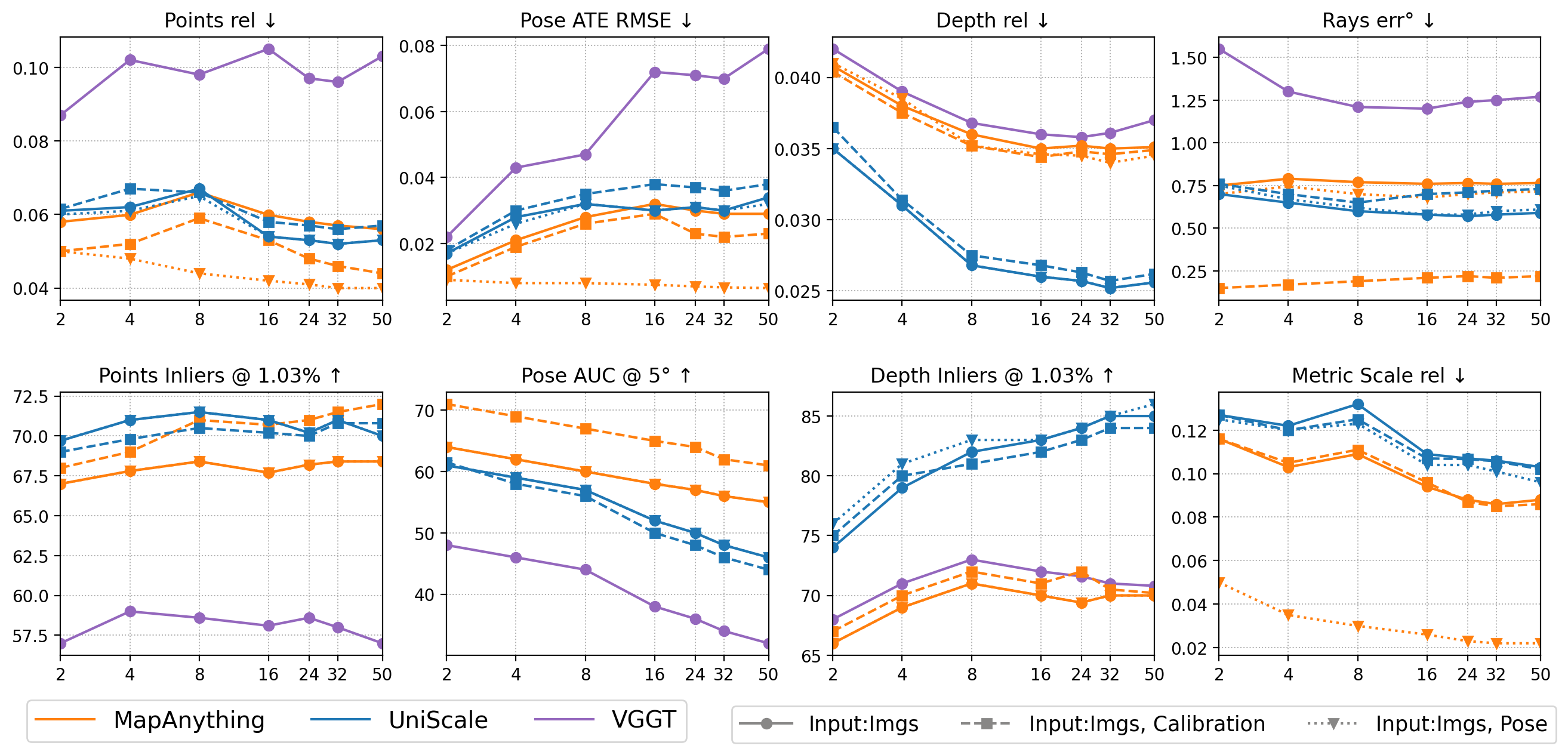
Figure 2: UniScale surpasses or matches state-of-the-art dense multi-view reconstruction across varying input set sizes on the dense-N-view benchmark.
- Metric Prediction: UniScale achieves the lowest error on image-only and image-plus-prior settings, outperforming baselines such as MapAnything and VGGT, and yielding statistically superior scores for both the relative error (rel) and scale-threshold (τ) metrics.
- Median-aligned Evaluation: Proven robust even with aligned tasks, the method yields competitive or best results alongside specialized models like π3.
- Dense-N-View Scaling: Maintains superior reconstruction error and geometric consistency as N increases, highlighting architectural scalability.
Generalization to Unseen Real-World Data
Qualitative and quantitative validation on datasets such as EuRoC MAV, TUM RGBD, and Oxford Spires reveal high-quality, geometrically coherent reconstructions, with clear improvements over MapAnything, VGGT, and DepthAnything3, especially in scene completeness and alignment.
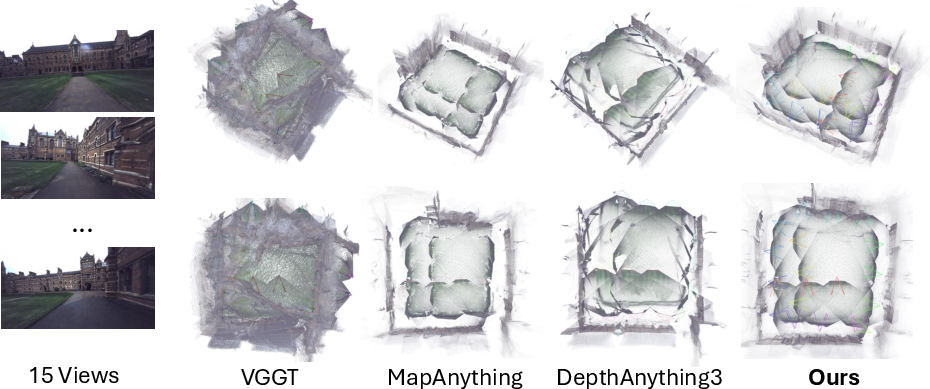
Figure 3: Qualitative comparisons demonstrate UniScale’s superior geometric completeness on the Oxford Spires outdoor dataset.

Figure 4: End-to-end dense 3D reconstructions using UniScale on the EuRoC MAV in-the-wild sequence.
Ablative Analysis
Comprehensive ablations confirm that inclusion of all three token types (camera, class, aggregated patch) in the metric-scale head is necessary for optimal performance. Conditioning the scale head on explicit priors (and using 6D pose encoding over quaternions) yields consistently measurable improvements.
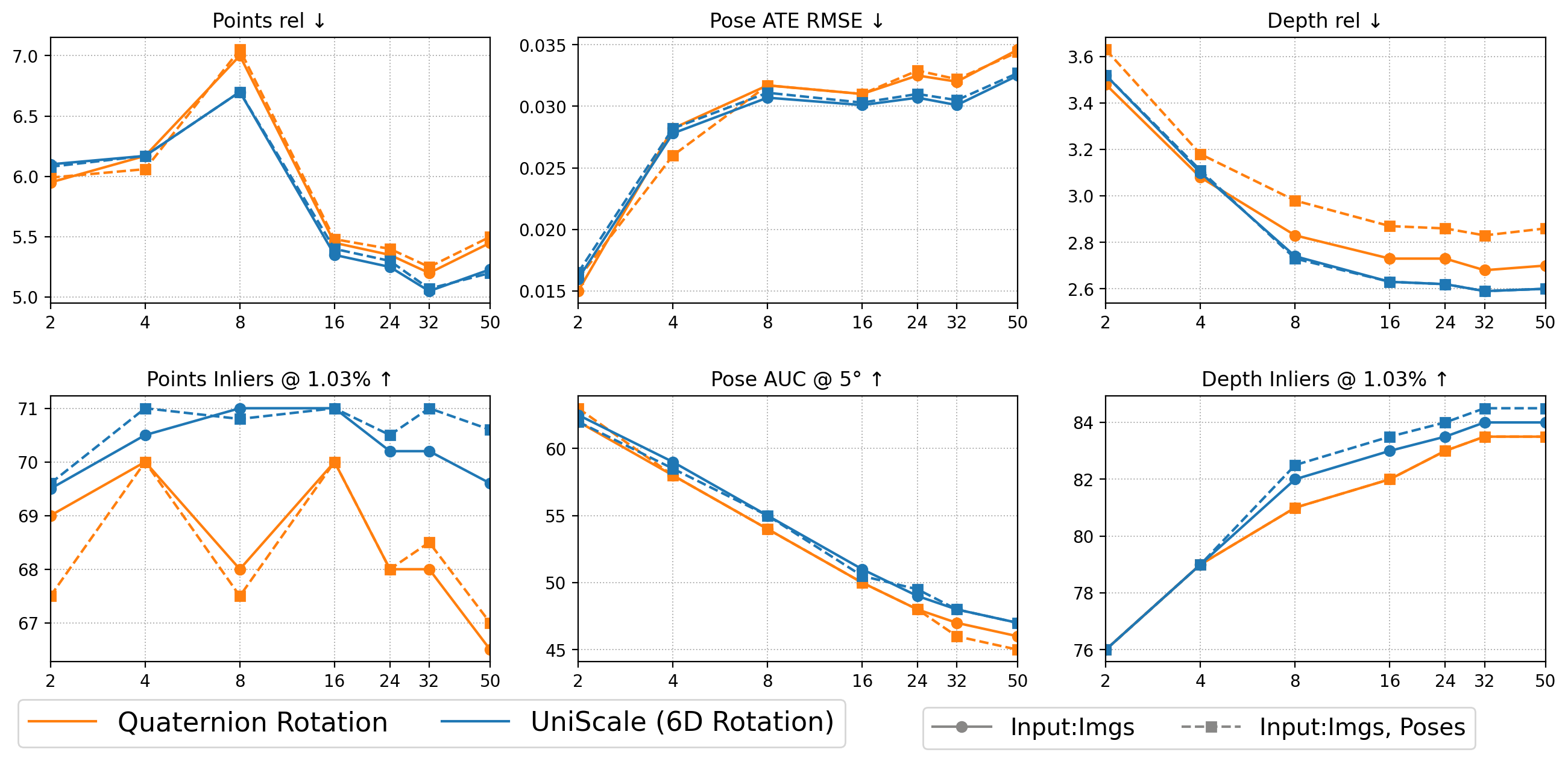
Figure 5: 6D encoding of extrinsics outperforms quaternion representation in multi-view scaling, especially as the number of views increases.
Implications, Limitations, and Future Directions
UniScale demonstrates that modular, semantically-targeted prior injection materially advances metric-aware feed-forward 3D perception, overcoming scale normalization limitations inherent to earlier transformer-based methods. The results show robust generalization to diverse and previously unseen environments, and the method is adaptable to scenarios with partial or missing calibration data. Practically, this enables deployment in heterogeneous, resource-constrained robotic teams, and supports a variety of downstream tasks requiring reliable metric estimation—ranging from autonomous navigation to manipulation and mapping.
The separation of structured geometric cues from image features, combined with flexible training under mixed-prior regimes, provides a blueprint for future hybrid visual-geometric systems. The dedicated scale head—trained only on metric data—acts as a regularizer, further improving depth and point map prediction under partial supervision.
Potential future directions suggested include extending the methodology to pure single-view robotics (by leveraging self-supervision and additional modalities), integration with event-based or inertial data for even broader applicability, and direct adaptation to SLAM and active exploration frameworks.
Conclusion
UniScale offers a methodologically rigorous and empirically validated solution to unified metric 3D reconstruction from multi-view imagery. Its architectural innovations—semantic prior injection, continuous pose parameterization, and a dedicated metric-scale prediction head—collectively yield strong, generalizable performance across evaluation protocols and datasets, making it a valuable foundation for both theoretical advancement and practical, real-world robotic perception.

