- The paper introduces a unified spatio-temporal 3D latent scaffold that fuses geometric and semantic cues for dynamic scene reconstruction in driving scenarios.
- The paper employs a dual-branch Gaussian generation, combining point and voxel branches, to robustly complete scenes and eliminate artifacts such as dynamic ghosting.
- The paper demonstrates significant improvements in PSNR and LPIPS on Waymo Open and NuScenes, highlighting strong generalization and efficiency.
UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Introduction and Motivation
Recent advancements in 3D scene reconstruction for autonomous driving rely heavily on feed-forward pipelines to overcome the impracticality of optimization-heavy, per-scene methods in real-time, dynamic, sparse multi-camera setups. Prevailing methods often falter when tasked with fusing sparse, poorly-overlapping views and aggregating information about dynamically evolving scenes. UniSplat addresses these limitations by introducing a unified spatio-temporal 3D latent scaffold, leveraging pretrained foundation models for robust geometry and semantics, and realizing dynamic-aware scene completion through dual-branch Gaussian generation and persistent static memory.
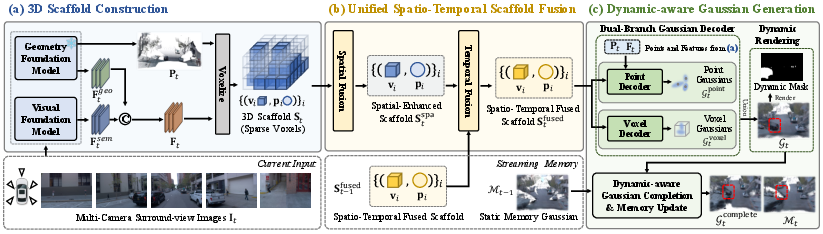
Figure 1: Overview of UniSplat, illustrating its multi-stage pipeline from multi-camera input to dynamic-aware Gaussian primitives, with explicit memory handling for static components.
Framework Architecture and Technical Innovations
3D Latent Scaffold Construction
UniSplat initiates with synchronized multi-camera input and applies cutting-edge multi-view geometric foundation models to predict a dense, globally aligned 3D point cloud. A scale alignment branch refines the metric reliability using LiDAR cross-supervision. Semantic context is injected via features from a visual foundation model, yielding a fused, ego-centric sparse voxel scaffold. This combined geometric-semantic scaffold forms the backbone for subsequent spatial and temporal reasoning.
Unified Spatio-Temporal Fusion
Spatial fusion diverges from conventional 2D image-level cross-attention, instead employing a sparse 3D U-Net to aggregate view-specific features directly in the 3D scaffold space. Temporal fusion capitalizes on known ego-motion, warping cached scaffolds forward in time, and unifying voxel features via sparse tensor addition and a compact convolutional refinement network. This results in a temporally enriched scaffold that supports streaming updates and robust accumulation of scene knowledge.
Dynamic-Aware Gaussian Generation and Memory
A dual-branch decoder synthesizes Gaussian primitives:
- Point Branch: Anchored to fine detail points, locates corresponding voxels in the scaffold, and merges both 3D and 2D features for high-fidelity predictions.
- Voxel Branch: Complements sparsely covered regions by decoding new Gaussian candidates directly from voxel features.
Dynamic attributes (di) computed per Gaussian enable motion-aware filtering, supporting memory-based accumulation of static primitives across frames. This persistent scene completion mechanism is crucial for reconstructing areas outside the current sensor coverage, mitigating occlusion, and avoiding dynamic ghosting.
Experimental Results
Waymo Open: UniSplat achieves marked improvement over established baselines (EvolSplat, MVSplat, DepthSplat, DriveRecon), with input-view PSNR gains (∼28.56–29.58dB) and substantially lower LPIPS error. For novel view synthesis—especially outside observed frustums—UniSplat maintains robustness and fidelity, demonstrating strong generalization and scene completeness.

Figure 2: Qualitative comparisons on the Waymo dataset, showcasing UniSplat's superior geometric detail and consistency relative to prior state-of-the-art methods.
NuScenes: UniSplat advances performance over Omni-Scene and PixelSplat, achieving the highest PSNR (25.37dB) and competitive LPIPS for central and collapsed multi-frame bins.
Dynamic Scene Completion: The explicit dynamic filtering eliminates ghosting of moving objects and coherently fills blind spots, including side and rear regions not covered by current frames.

Figure 3: Scene completion results on Waymo. Top: naive aggregation results in dynamic ghosting; bottom: UniSplat eliminates artifacts and bridges sensor gaps via dynamic-aware Gaussian filtering.
Ablation and Analysis
Ablation studies underscore the significance of scaffold feature composition, unified fusion, and decoder design:
- Omitting semantic features degrades perceptual similarity (LPIPS ↑ 0.05).
- 3D scaffold-based fusion outperforms image-level fusion by +0.36dB PSNR.
- Temporal propagation in latent space yields an additional +0.58dB PSNR.
- Voxel-based Gaussian decoding recovers scene completion where point-only fails (>0.4 PSNR difference).
- Choice of geometry foundation model is not pivotal within the framework; both MoGe-2 and π3 deliver robust results.
Implementation and Deployment Considerations
- Computational Efficiency: Sparse tensor operations and U-Net backbones enable efficient fusion, suitable for deployment on large-scale vehicle fleets.
- Resource Requirements: Training on 16×H20 GPUs and batch sizes of 32 indicate memory-intensive operations but are viable in dedicated datacenter setups.
- Generalization: Feed-forward design and foundation model reliance make UniSplat adaptable to new environments and sensor layouts without retraining from scratch.
Theoretical and Practical Implications
UniSplat’s architecture demonstrates that a unified latent 3D scaffold, constructed from sparse multi-view inputs, and fused in both space and time, can support robust, generalizable, and dynamic-aware scene reconstruction. The persistent accumulation of static primitives opens avenues for lifelong world modeling and interactive 4D simulation. Its success highlights the need for explicit geometric and semantic alignment via large-scale foundation models, rendering implicit prior learning increasingly central to real-world autonomous systems. Future developments may target memory-efficient streaming, multimodal fusion (LiDAR, radar), and extension to non-driving domains requiring dynamic scene modeling.
Conclusion
UniSplat delivers an authoritative feed-forward reconstruction framework tailored for dynamic, sparse-view autonomous driving scenarios. Through unified spatio-temporal fusion in the scaffold domain and dual-branch dynamic-aware Gaussian generation, it consistently surpasses previous methods in both quantitative and qualitative benchmarks. Its principled design and strong generalization capacity position it as a foundational architecture for next-generation dynamic world modeling and scalable self-supervised scene understanding.