- The paper introduces a novel feed-forward latent posing model that leverages transformer-based latent regression to achieve high-fidelity 3D humanoid animation.
- It employs dense cylinder-based skeleton encoding and latent-space supervision to ensure robust pose conformance and identity preservation even with topological imperfections.
- Its adaptive token completion module efficiently reconstructs plausible geometry in newly exposed regions, outperforming traditional auto-rigging and pose-conditioned methods with significant speed gains.
Feed-Forward Latent Posing Model for High-Fidelity 3D Humanoid Animation
Introduction and Motivation
The paper "Make-It-Poseable: Feed-forward Latent Posing Model for 3D Humanoid Character Animation" (2512.16767) introduces a feed-forward framework for 3D humanoid character posing, aiming to circumvent the limitations intrinsic to traditional auto-rigging and pose-conditioned generation paradigms. Prior approaches have suffered from inaccurate skinning, topological inflexibility, and suboptimal pose conformance, particularly for AI-generated meshes that often have fused parts or non-standard topologies. Iterative generative models, while expressive, manifest slow inference and inconsistent identity preservation across motion sequences.
By conceptualizing character posing as a regression problem in 3D latent space, this work adapts transformer-based modeling to yield efficient, topology-aware articulation, obviating the need for explicit skinning and enabling mesh reconstruction directly from latent representations.
Framework Overview
The core workflow is as follows: given a source mesh and source/target skeletons, both are encoded into latent representations via parallel shape and skeleton encoders. The latent posing transformer then maps these representations into the target pose’s latent tokens, which are decoded to the output mesh. The framework incorporates latent-space supervision and an adaptive completion module for generating plausible geometry in regions revealed by articulation (such as armpits during arm lifts).
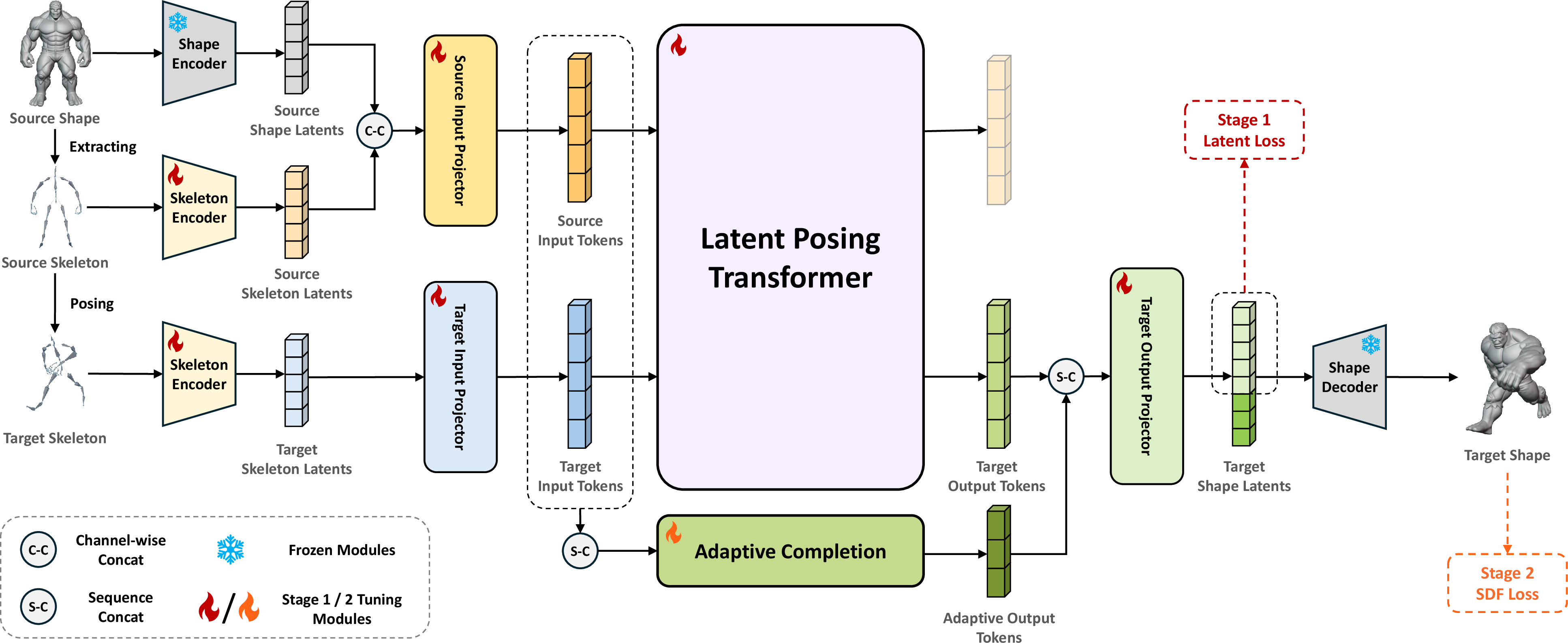
Figure 1: Pipeline depicting latent encoding, transformer-based posing, and adaptive geometry completion for 3D character re-posing.
Technical Contributions
Latent Posing Paradigm
Instead of deforming mesh vertices or relying on skinning weights, the system reconstructs target poses by directly manipulating latent VecSet representations derived from a variational autoencoder (VAE). This decouples geometry manipulation from specific mesh topology, granting robustness to topological defects and complex deformations.
Skeleton Encoder with Dense Pose Representation
A transformer-based skeleton encoder produces per-point pose representations, projecting mesh surface samples onto bone-associated cylinders. This achieves one-to-one correspondence between skeletal and shape latents, facilitating fine-grained dense conditioning. Experiments show that this dense encoding markedly improves pose conformance and semantic tracking compared to sparser, line-based approaches.
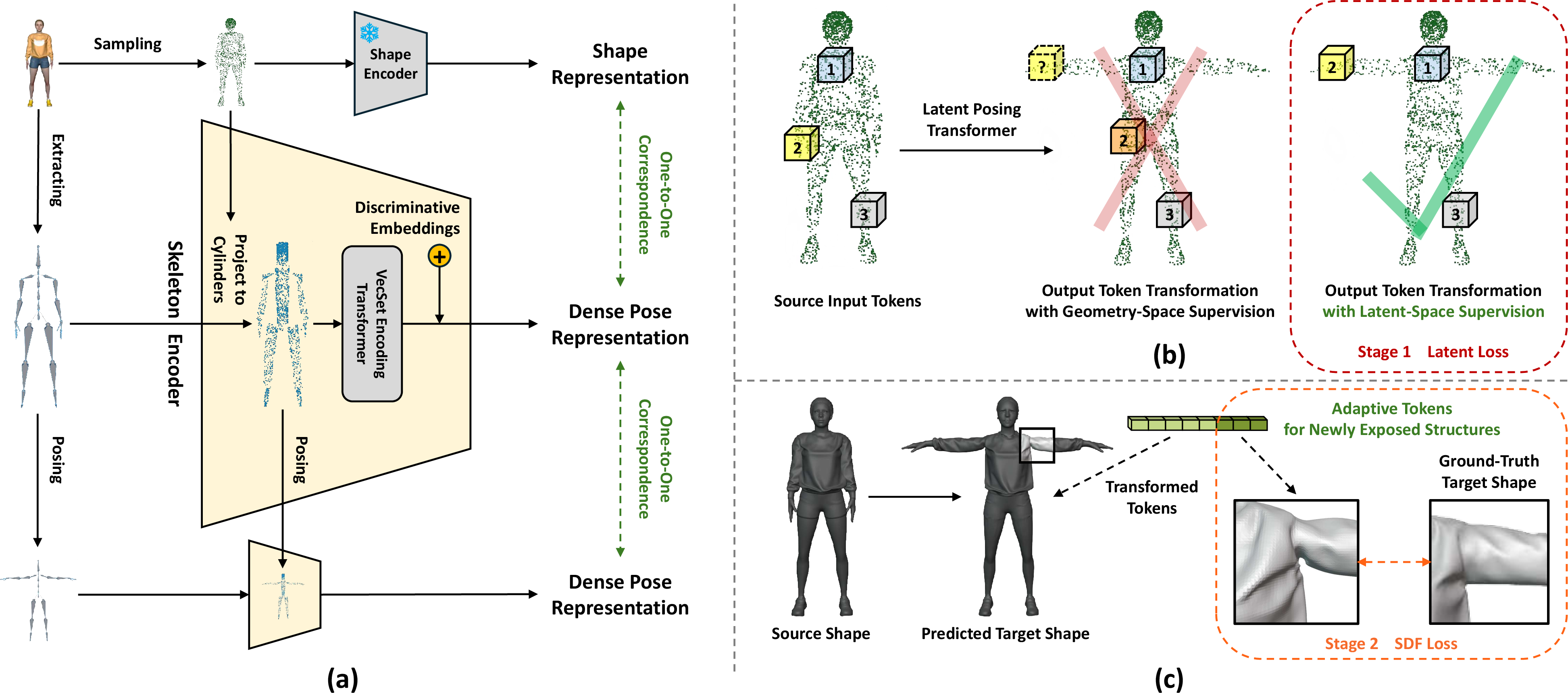
Figure 2: Key design elements, distinguishing the dense pose/skeleton encoder and embedding strategies for latent correspondence.
Latent-Space Supervision
To resolve the permutation ambiguity of latent VecSets, the model employs a canonical, latent-level supervision regime: it explicitly matches output tokens to semantically corresponding regions in the source mesh. This preserves high-frequency geometry and enables detailed, identity-preserving animation. A set of randomly swapped learnable embeddings further discriminates local regions, reinforcing correspondence consistency.
Adaptive Completion for Topological Exposure
Some pose transitions reveal surfaces absent from the source mesh (e.g., newly visible armpits). The adaptive completion module synthesizes new tokens for these regions, guided by contextually aware in-context attention. Finetuning with an SDF loss on remeshed data enables this module to plausibly generate geometry for newly exposed structures.
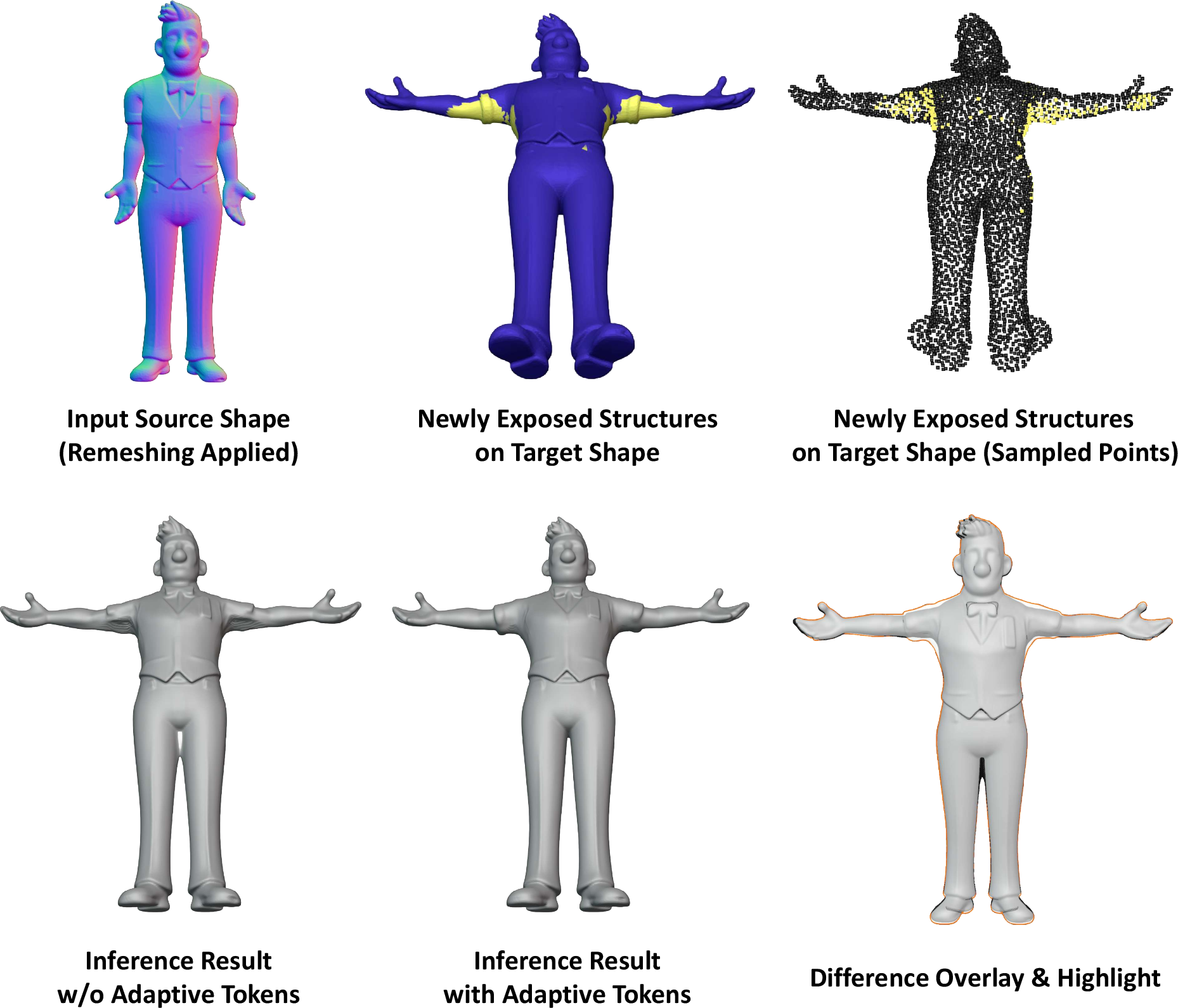
Figure 3: Visualization of reconstruction for newly exposed structures; adaptive tokens enable plausible filling of missing geometry.
Empirical Evaluation
Quantitative and Qualitative Results
Experiments on Mixamo and HumanRig datasets, coupled with in-the-wild assets generated via Hunyuan3D-2.1, demonstrate that Make-It-Poseable significantly surpasses auto-rigging (MIA) and pose-conditioned generation (HY3D-Omni) baselines. The model achieves Chamfer Distance an order of magnitude lower than MIA and 50x faster inference than HY3D-Omni, while maintaining superior F-score and IoU.
Qualitatively, the method robustly handles close-proximity limbs and topological imperfections—scenarios where skinning-based methods exhibit leakage and spiking artifacts. Generative models struggle to preserve identity or fine structure; the latent posing approach consistently yields accurate, high-fidelity shapes.

Figure 4: Qualitative comparison across diverse characters and poses, highlighting fidelity and robustness to input challenges.
Applications and Extensions
Beyond standard re-posing, the framework supports advanced tasks such as part segmentation, replacement, and refinement through skeletal manipulation. In zero-shot settings, parts can be exchanged or enhanced by adjusting bone configurations and masked latent tokens, enabling flexible iterative editing.
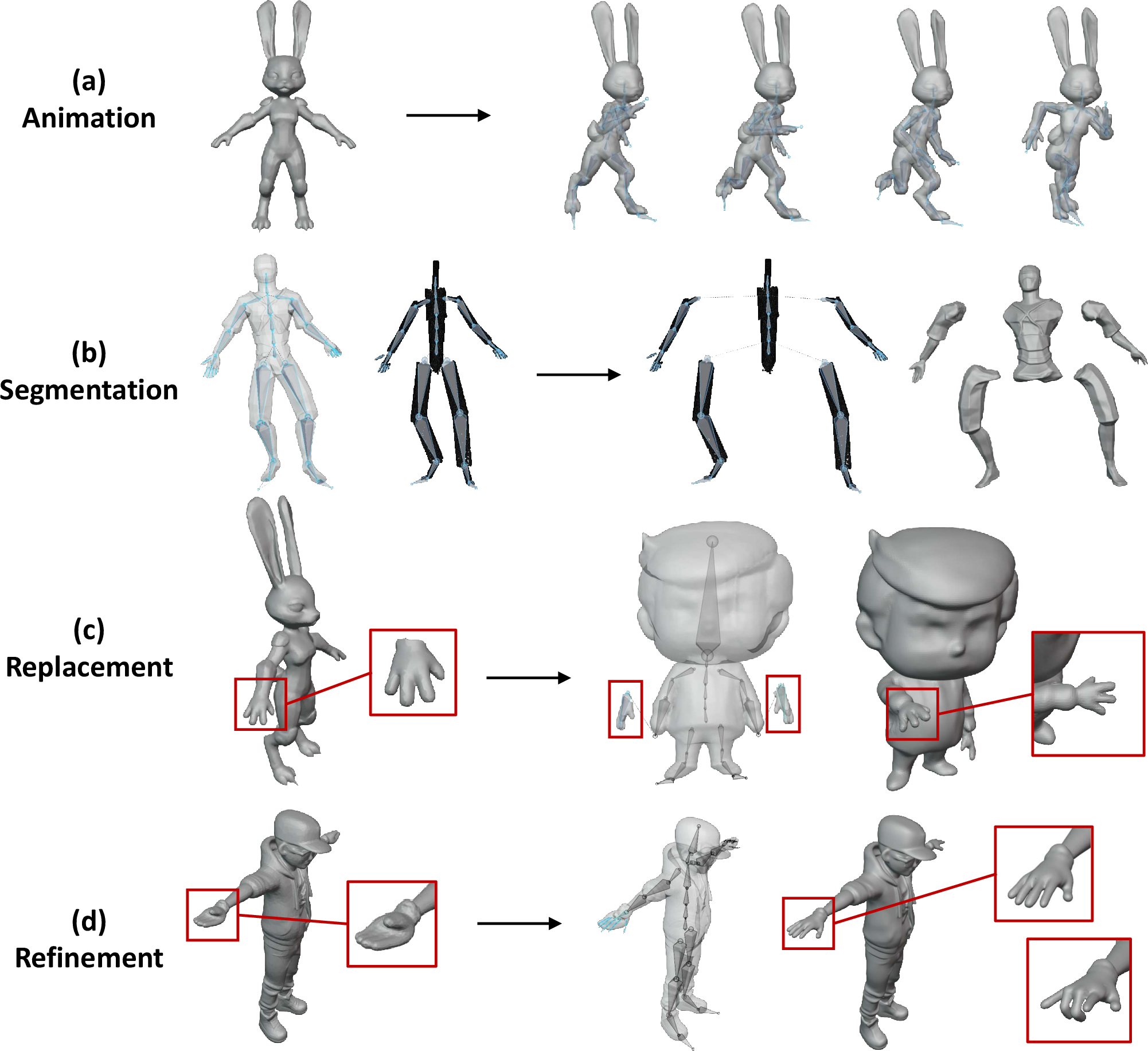
Figure 5: Applications including direct animation, segmentation, part replacement, and geometry refinement.
Ablation Studies
Comprehensive ablations substantiate the criticality of (i) dense cylinder-based skeleton encoding, (ii) unique latent embeddings, (iii) latent-space supervision, and (iv) adaptive token finetuning. Removing or modifying these components results in pronounced degradation of surface detail, pose accuracy, and the ability to handle newly exposed regions.
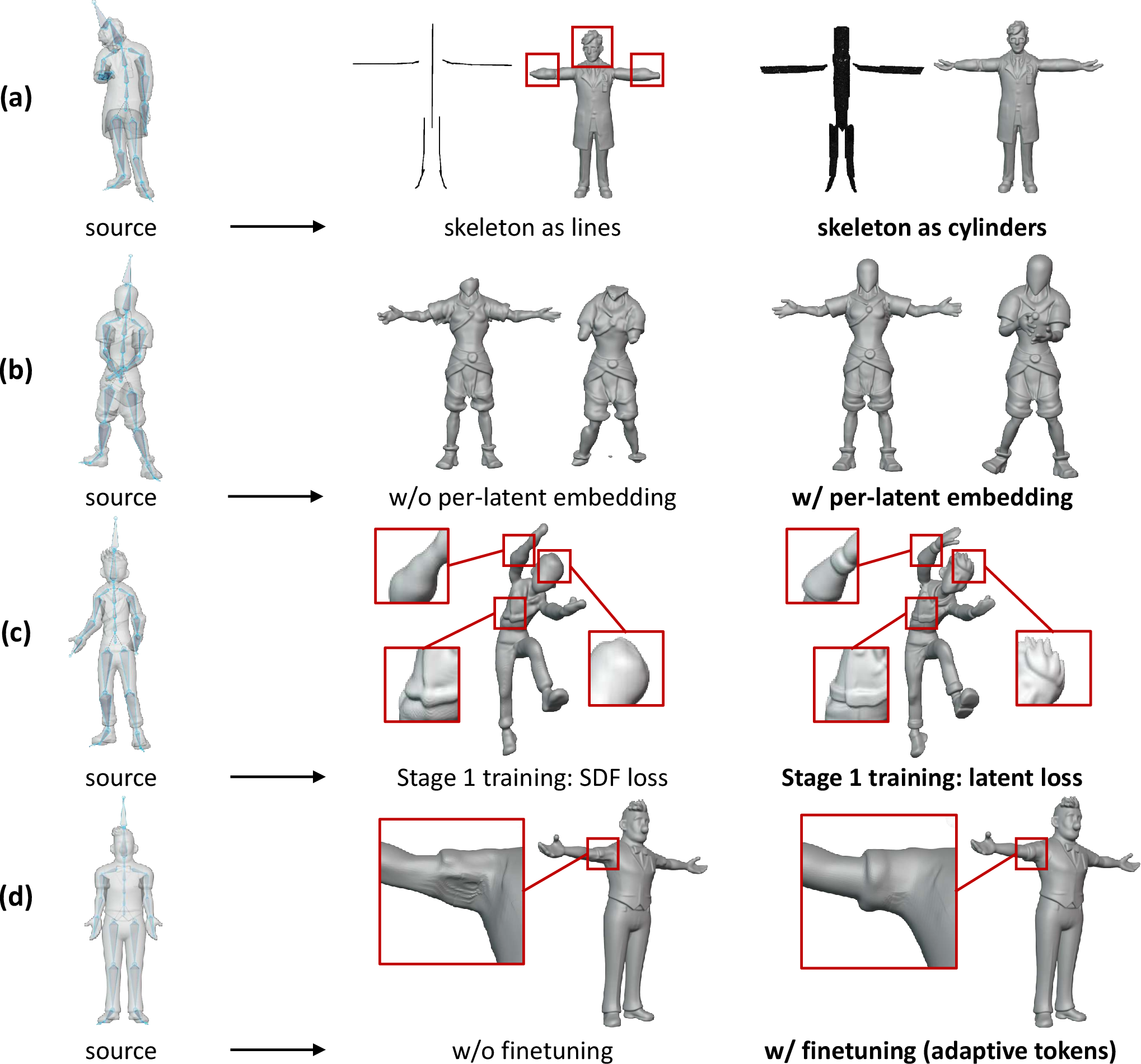
Figure 6: Ablation results demonstrating the impact of design choices on pose ambiguity, correspondence, and detail preservation.
Theoretical and Practical Implications
This feed-forward latent posing paradigm demonstrates that 3D animation can be cast as transformer-based latent regression, avoiding the intrinsic limitations of vertex-space skinning and mesh topology. The approach is skeleton-agnostic and could, in principle, generalize to non-humanoid articulated objects given appropriate data.
Extension to richer representations (e.g., flexible or generative latent spaces), joint shape-appearance modeling, and multimodal conditioning (such as text or reference images) are promising directions. The framework is particularly advantageous for AI-generated assets where topological noise and nonstandard limb configurations are frequent. The potential for fast, high-fidelity batch processing and seamless integration into animation pipelines is significant.
Conclusion
Make-It-Poseable establishes a new feed-forward latent-space paradigm for 3D character animation, achieving state-of-the-art fidelity and robustness to topology and pose complexity. By leveraging transformer-based representations and dense skeletal conditioning, it provides fine-grained control and natural extension to editing applications. Future work may generalize the framework to broader object categories, incorporate richer generative modalities, and unify geometry with appearance for fully realized animated avatars.