Tool Building as a Path to "Superintelligence"
Abstract: The Diligent Learner framework suggests LLMs can achieve superintelligence via test-time search, provided a sufficient step-success probability $γ$. In this work, we design a benchmark to measure $γ$ on logical out-of-distribution inference. We construct a class of tasks involving GF(2) circuit reconstruction that grow more difficult with each reasoning step, and that are, from an information-theoretic standpoint, impossible to reliably solve unless the LLM carefully integrates all of the information provided. Our analysis demonstrates that while the $γ$ value for small LLMs declines superlinearly as depth increases, frontier models exhibit partial robustness on this task. Furthermore, we find that successful reasoning at scale is contingent upon precise tool calls, identifying tool design as a critical capability for LLMs to achieve general superintelligence through the Diligent Learner framework.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: Can today’s LLMs reliably solve long, multi-step problems if they search carefully and check their work at test time? The authors focus on one key number, called gamma (γ), which is the chance that a model picks the correct next step in a reasoning chain. They build a special test (a benchmark) to measure γ at each step and see how it changes as problems get deeper and harder.
What questions are the authors trying to answer?
- Does an LLM’s chance of picking the right next step (γ) stay reasonably high as the number of steps grows?
- Are there tasks where γ collapses (drops a lot) the deeper you go?
- Can models avoid “shortcuts” (like guessing from patterns) and actually combine what they’ve already figured out with new evidence?
- Do tools (like small programs the model can call) help keep γ high over long reasoning chains?
How did they test this?
Think of the task like a careful puzzle that must be solved step by step:
- Each puzzle has a secret rule made from tiny on/off bits (0s and 1s). This is called a Boolean circuit. The rule can be written as an “XOR of pieces” (XOR is like adding bits but without carrying—1+1 becomes 0). In math land, this is called GF(2), but you can think of it as “everything is 0 or 1, and we combine them with a special kind of addition.”
- At each step, there is exactly one correct next piece to add. No guessing paths. No multiple answers.
- To find the next piece, the model is given: 1) The prefix: what it has already discovered so far (the known pieces), and 2) New evidence: fresh examples that look random unless you use the prefix to interpret them.
The clever part is how the new evidence is generated. It’s “masked” by the prefix—like a message written with a secret key. If you ignore the prefix, the data looks like noise; if you ignore the new data, the prefix alone won’t tell you the next piece. You must use both together. This design blocks shortcuts and forces true step-by-step reasoning.
They then measure γ at different depths (how many steps into the puzzle you are). They test:
- Simple “estimators” (programs with limited information),
- Smaller LLMs,
- Frontier models (very advanced LLMs), and they also compare cases with and without tool use (letting the model run small helper programs).
What did they find, and why does it matter?
Main results:
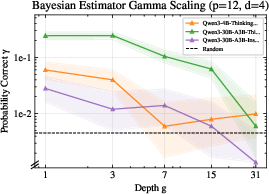
- γ shrinks with depth for smaller models: As problems get deeper, small LLMs’ chance of getting the exact next step right drops a lot—sometimes down to random guessing. This suggests they struggle to keep track of what they’ve found and to correctly combine it with new evidence over many steps.
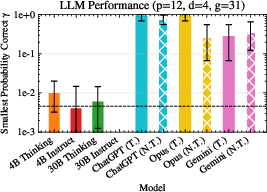
- Frontier models hold up much better, especially with tools: Larger, top-tier models keep γ high even at much greater depths when they are allowed to make precise tool calls (e.g., run a small calculation or check). Without tools, even these models can see γ drop more as the puzzle gets longer.
- Tool design matters: The models that used tools well had the most stable performance. Tools help by letting the model focus on deciding what to do next, while the tool handles the exact computations and bookkeeping.
Why it matters:
- The Diligent Learner idea says: If γ stays above some healthy level as you go deeper, then test-time search (trying different next steps, checking, and backtracking if needed) can scale to very hard problems without blowing up in cost.
- This benchmark shows that whether γ stays high depends on the model and on its ability to use tools. In other words, building and using the right tools could be a crucial path toward much more general, reliable reasoning—what some people call “superintelligence.”
So what’s the big takeaway?
- Good multi-step reasoning isn’t just about thinking hard; it’s about thinking in a way that can consistently get the next step right.
- The paper introduces a tough, fair test that forces a model to combine “what I know so far” with “what the new data says” at every step.
- Smaller models tend to “forget” or fail to combine these pieces over long chains, causing γ to collapse.
- Bigger models, especially when they use tools, keep γ high—even far into the problem—showing that tool use can stabilize long-horizon reasoning.
- Bottom line: To build truly capable AI problem solvers, we may need models that are not only smart but also skilled at creating and using tools to keep their reasoning solid over many steps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s theory, benchmark design, and experiments. Each item is framed to guide concrete follow-up research.
- External validity of the benchmark: Does performance on the synthetic GF(2) ANF reconstruction task predict multi-step reasoning on real domains (e.g., math proofs, code, planning) where structure, noise, and semantics differ substantially?
- Unique-next-step assumption: The benchmark enforces a single valid continuation per depth. How should be defined and measured when multiple “good” next steps exist (as in realistic reasoning), and how does this affect validator design and search efficiency?
- Perfect validator/backtracking idealization: Results assume a validator that never admits wrong steps and obviates learned backtracking. What happens to search efficiency and effective when validators are imperfect and backtracking must be learned?
- Metadata leakage: The prompt reveals the active address bit (), the partition boundary , and the degree . How does change when these are withheld and the model must also infer them?
- Distributional assumptions: Theoretical separations rely on supports sampled i.i.d. uniformly with replacement and payloads sampled at a fixed Hamming weight making . How robust are conclusions if:
- supports are sampled without replacement or with correlations;
- payloads follow different (or noisy) distributions;
- cannot be tuned near ;
- supports/payloads drift across depths?
- Evidence size sensitivity: The experiments largely use samples per step. What are the sample complexity curves and the minimal needed to maintain a target across depths?
- Parameter scaling coverage: Most LLM tests use , . How do scaling laws for change across a broader grid of , including larger payloads, higher degrees, and deeper horizons?
- Context-length and memory confounds: Depth increases enlarge the prompt. To what extent is collapse in small models due to attention/window limits or recency bias rather than reasoning per se? Test with state compression, retrieval/memory tools, or structured state representations.
- Output-format confounds: A regex-based parser mitigates format errors but may still mis-score correct solutions. Quantify the fraction of failures due to formatting and enforce structured output (e.g., tool-returned JSON) to isolate reasoning errors.
- Tool-use standardization and auditing: “Tools” are not standardized across models and Opus sometimes used tools despite “no-tools” instructions. Define a common, transparent tool suite, log tool invocations, and enforce compliance to enable fair comparisons.
- Causal effect of tools: Conduct controlled A/B tests within the same model (identical prompts, compute budgets) to isolate the causal impact of tools on . Ablate tool correctness, latency, and API granularity to find the minimal toolset needed for stability.
- Effective-prefix utilization: The “effective-prefix” fits (e.g., ) are referenced but not detailed. Specify the fitting procedure and goodness-of-fit criteria, validate across more models, and test interventions (e.g., explicit running-cancellation tools) that increase effective use of the prefix.
- Robustness to noise and ambiguity: Introduce label noise, prefix corruption, or deliberately ambiguous steps to probe how degrades under realistic uncertainty and whether tools mitigate this.
- Full search evaluation: Current measurement is single-step exact-next accuracy. Evaluate end-to-end validator-guided DFS/ToT with multiple proposals per step (e.g., self-consistency), learned backtracking, and measure total path success vs. depth and compute budget.
- Horizon and statistical power limits for frontier models: Frontier results use only 60 queries and max depth due to cost. Expand sample sizes and depths to establish reliable confidence intervals and identify failure horizons.
- Degree heterogeneity and support collisions: Allow variable-degree monomials and repeated supports to test solver ambiguity and the impact on uniqueness of continuation and validator complexity.
- Metadata minimization and invariances: Randomize or hide , , , variable ordering, and naming to remove possible cues; assess whether persists under such invariances.
- Encoding/tokenizer effects: Compare different table formats, spacing, and encodings across tokenizers to ensure results are not artifacts of model-specific tokenization behavior.
- Decoding-policy sensitivity: Report and systematically vary decoding hyperparameters (e.g., temperature, top-), and measure how the policy’s stochasticity alters and the effective proposal distribution.
- Training-time interventions: Explore finetuning on reconstruction curricula or tool-use instruction-tuning and quantify how much and horizon depth improve, including transfer to unseen distributions.
- Mechanistic understanding: Perform interpretability analyses to identify whether and how models implement prefix-conditioned cancellation, and how tool use shifts computation from implicit execution to constraint specification.
- Validator design beyond ANF: Develop polynomial-time validators for richer concept classes (e.g., CNF/DNF, higher-arity operations, GF()), including cases with multiple valid continuations, to broaden where can be measured.
- Reproducibility with proprietary models: Provide complete prompts, seeds, decoding settings, tool code, and invocation logs—especially for frontier systems—to enable independent verification.
- Theory beyond i.i.d. assumptions: Extend the masking lemmas to non-uniform priors, dependence across steps, and settings where is not near ; model the decay of data-only advantage and predict under realistic deviations.
- Empirical link to DL search bounds: Connect measured to the Diligent Learner’s search budget formula and verify whether observed values support polynomial-time search at practically relevant depths with realistic validators and backtracking.
Practical Applications
Immediate Applications
The following items can be deployed now using the paper’s released code, established agent patterns, and existing tool ecosystems, to improve evaluation and reliability of LLM-based reasoning.
- Industry (software/AI): Quantify model reasoning depth with the GF(2) stepwise benchmark
- Use case: Add exact-next step-success measurement (γ_g) to model QA, red-teaming, and release gates to detect depth-induced collapse.
- Tools/products/workflows: Gamma Profiler (γ_g scorer), Reasoning Depth Dashboard in MLOps CI; integrate the paper’s GitHub dataset into eval pipelines; validator-guided DFS harness.
- Assumptions/dependencies: Availability of long-context inference; stable parsing/validation; benchmark generalization to target domains.
- Industry (software/AI): Tool-centric agent design to stabilize γ_g
- Use case: Externalize execution (algebra, search, table ops) and keep the LLM focused on constraint specification; adopt “Think → Tool → Verify” loops.
- Tools/products/workflows: Tool orchestrator (SAT/linear algebra/GF(2), data-frame ops), argument-schema validators, scratchpads, self-check prompts; enforce precise tool calls via schema validation.
- Assumptions/dependencies: Reliable APIs and sandboxes; robust argument extraction and error handling; latency/cost budgeting for tool calls.
- Healthcare, finance, legal: Validator-first reasoning to reduce high-stakes errors
- Use case: Gate each step of a recommendation with programmatic checks and domain calculators (dosage, risk scores, compliance rules), rather than pure CoT.
- Tools/products/workflows: Stepwise Validator Engine; Policy/Compliance Checkers; Clinical Calculators; action-specific verifiers woven into agent loops.
- Assumptions/dependencies: High-quality domain validators; data governance, audit logging, and provenance; human-in-the-loop review.
- Education/EdTech: Assessment and training that require prefix+evidence integration
- Use case: Assignments that mask shortcuts and require students (or tutors) to combine accumulated context with new data to reach unique next steps.
- Tools/products/workflows: Diligent Reasoner assessments; adaptive curricula exploiting the obfuscation oracle; analytics on γ_g to diagnose reasoning gaps.
- Assumptions/dependencies: Task alignment to curriculum; accessibility/fairness; instructor adoption.
- HR/AI procurement: Model and candidate screening using γ_g scorecards
- Use case: Evaluate models (or human problem-solvers) on controlled out-of-distribution reasoning where each continuation is unique.
- Tools/products/workflows: γ_g scorecards; procurement checklists with minimum γ_g thresholds at specified depths; benchmark-in-the-loop RFPs.
- Assumptions/dependencies: Agreement on task relevance; standardized reporting; reproducibility across vendors.
- Software engineering: Code agents with unit-test validators and precise tool calls
- Use case: For SWE tasks (e.g., SWE-bench), require unit-test-driven validators at each repair step; offload analysis (static/dynamic) to tools; measure γ_g across multi-step patches.
- Tools/products/workflows: “Fix → Test → Verify” loops; toolkits for static analysis, dependency resolution, GF(2)-like logic checks; regression guards.
- Assumptions/dependencies: Sufficient test coverage; environment reproducibility; access to build systems.
- MLOps: Continuous γ_g monitoring and alerting
- Use case: Track γ_g trajectories over time and across versions to catch regressions in multi-step reasoning robustness (especially OOD).
- Tools/products/workflows: Scheduled γ_g evals in CI/CD; Bayesian confidence intervals on γ_g for release gating; telemetry on tool-call precision.
- Assumptions/dependencies: Compute budgets; test-set rotation to avoid overfitting; proper statistical baselining.
- Consumer assistants (daily life): Reliability layer with stepwise verification
- Use case: Use calculators, calendars, and data tools with validator checks for multi-step tasks (budgeting, travel planning, homework help).
- Tools/products/workflows: Trust Layer (validator-gated actions); transparent tool-use logs; fail-safe backtracking.
- Assumptions/dependencies: High-quality consumer tools/APIs; clear UX for verification and corrections; privacy controls.
Long-Term Applications
The following items require further research, scaling, domain validators/tools, or standardization to realize their full impact.
- AI research: Generalized tool-building as a route to superintelligence
- Use case: Architect agents that can invent, select, and compose tools to maintain non-vanishing γ across long horizons.
- Tools/products/workflows: Meta-tool builder; Thinking-to-Program compiler; learned tool discovery; neural-symbolic integration with validator-guided search.
- Assumptions/dependencies: Advances in meta-learning, program synthesis, and safe tool invention; robust execution sandboxes.
- Policy/regulation: Standardize γ_g reporting for high-stakes AI systems
- Use case: Require disclosure of stepwise success (at defined depths and OOD tasks) and tool-use precision as part of certification.
- Tools/products/workflows: γ_g benchmarks for regulated domains; audit protocols; minimum-threshold standards; public registries.
- Assumptions/dependencies: Cross-sector consensus on metrics; domain-relevant task suites; third-party auditors.
- Scientific discovery platforms: Propose–verify loops with domain tools
- Use case: Automate hypothesis generation and validation via external simulators, statistical packages, and data-cleaning tools to preserve γ across research workflows.
- Tools/products/workflows: Lab assistant orchestration; experiment planners with validator gates; provenance-tracked pipelines.
- Assumptions/dependencies: Domain-specific validators (e.g., physics simulators, bioinformatics tools); reliable datasets; compute for large-scale search.
- Healthcare: Validator-orchestrated diagnostic agents
- Use case: Multi-test diagnostic reasoning with stepwise gates (guidelines, calculators, contraindications) to maintain γ in long clinical workflows.
- Tools/products/workflows: EHR-integrated validators; medical guideline engines; dosage/drug–interaction tools; audit trails.
- Assumptions/dependencies: Clinical validation; regulatory approval; robust data integration and privacy.
- Robotics/automation: Long-horizon planners with validator-guided DFS
- Use case: Combine symbolic planners and simulation-based validators to sustain γ in complex tasks (assembly, navigation).
- Tools/products/workflows: Planner–critic architectures; environment validators; tool-call precision monitoring; recovery/backtracking policies.
- Assumptions/dependencies: Accurate simulators; hardware–software co-design; safety certification.
- Finance/compliance: Stepwise audit and policy-proof agents
- Use case: Multi-step reasoning for audits, reporting, and compliance checks with formal validators and external calculation tools.
- Tools/products/workflows: Compliance DSLs with validators; risk-score calculators; traceable reasoning chains.
- Assumptions/dependencies: Formalization of rules; regulator cooperation; secure data access.
- Security and evaluation: Anti-shortcut benchmarks across domains
- Use case: Adapt the statistical obfuscation oracle to other tasks (e.g., reverse engineering, binary analysis) to defeat pattern shortcuts and measure true state integration.
- Tools/products/workflows: Obfuscation-based benchmarks; adversarial evidence generators; chance-level baselines for partial-information solvers.
- Assumptions/dependencies: Domain-specific oracle design; careful leakage analysis; community adoption.
- Runtime architectures: Memory and execution systems optimized for γ
- Use case: Build agents with explicit prefix tracking, persistent state, and low-friction tool execution to prevent context-induced decay.
- Tools/products/workflows: Prefix Memory Manager; Argument Verifier; Execution Sandboxes; deterministic validator APIs.
- Assumptions/dependencies: Efficient long-context management; robust schema enforcement; cost-effective orchestration.
- Curriculum learning for reasoning: Progressive depth training regimes
- Use case: Train models on tasks that gradually increase reasoning depth with unique next steps and enforced prefix+evidence fusion.
- Tools/products/workflows: Depth curricula; γ-aware training signals; synthetic task generators with oracle masking.
- Assumptions/dependencies: Scalable data generation; alignment with downstream tasks; avoidance of shortcut leakage.
- New products/ecosystems: End-to-end “Diligent Reasoner” stacks
- Use case: Commercial platforms that combine γ_g evaluation, tool orchestration, validators, and reporting for enterprise deployments.
- Tools/products/workflows: Validator DSLs; Tool registries; γ telemetry; policy templates; plug-in adapters for domain tools.
- Assumptions/dependencies: Vendor ecosystem; interoperability standards; sustained maintenance and security.
Across both categories, a recurring dependency is the availability of precise, high-quality validators and tool APIs. The paper’s key finding—that γ remains high at scale only when models make precise tool calls—implies that feasibility depends on robust tool selection, argument construction, error handling, and safe execution environments.
Glossary
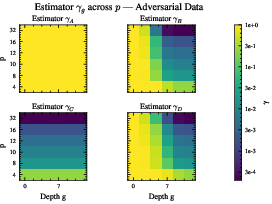
- Adversarial sampling oracle: An oracle that generates evidence intentionally structured to defeat shortcut strategies unless conditioned on the revealed history. "we employ an adversarial sampling oracle."
- Algebraic Normal Form (ANF): A canonical representation of Boolean functions over GF(2) as XORs of monomials. "represented in Algebraic Normal Form (ANF) as XORs of monomials"
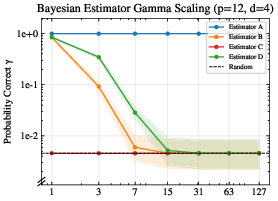
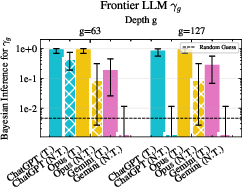
- Bayesian confidence interval: A credible interval derived from a Bayesian posterior, reflecting uncertainty about a parameter. "The bars show the Bayesian confidence interval with a random prior as supported by the results in Section \ref{sec:results:small}."
- Bayesian estimators: Solvers that use Bayesian inference to estimate hypotheses or parameters from data. "We build such a dataset and evaluate it on Bayesian estimators, small LLMs, and state-of-the-art LLMs."
- Bayes advantage: The expected improvement of a Bayes-optimal predictor over chance, given available information. "we prove that the Bayes advantage from any single sample shrinks exponentially with the number of active prefix bits."
- Bayes masking: A phenomenon where obfuscation causes labels to be uninformative to data-only inference under a Bayesian view. "Bayes masking given observed "
- Bernoulli distribution: A distribution over {0,1} with a specified success probability. "a_1,\dots,a_g \stackrel{i.i.d.}{\sim}\mathrm{Bernoulli}(1/2)"
- Chain-of-Thought (CoT) prompting: A prompting technique that elicits step-by-step reasoning traces from an LLM. "chain-of-thought prompting"
- Compositional generalization: The ability to generalize by recombining learned components or primitives into new compositions. "probe compositional generalization and algorithmic structure"
- Depth-first search (DFS): A search strategy that explores one branch to completion before backtracking. "validator-guided depth-first search with a backtrack action."
- Diligent Learner: A framework that models reasoning as validator-guided search, emphasizing a non-vanishing per-step success probability. "introduced the Diligent Learner framework"
- Exact-next accuracy: The probability that a solver predicts the unique correct continuation at a given step. "enabling direct measurement of as exact-next accuracy with a polynomial-time validator."
- GF(2): The finite field with two elements {0,1}, with addition and multiplication modulo 2. "We design a form of Boolean circuit reconstruction from data over ."
- Golden path: A validator-accepted root-to-solution reasoning trajectory. "a golden path is a root-to-done path accepted by "
- Hamming sphere: The set of binary vectors with a fixed Hamming weight (number of ones). "Let be uniform over the Hamming sphere "
- Hamming weight: The number of ones in a binary vector. "We fix a Hamming weight and sample payloads uniformly from the sphere"
- Jeffreys intervals: Bayesian credible intervals for binomial proportions based on the Jeffreys prior. "with shaded Jeffreys intervals."
- LLM-ERM framework: A formulation where an LLM proposes hypotheses and a verifier enforces correctness, akin to empirical risk minimization with a verifier. "the LLM-ERM framework treats the LLM as proposing hypotheses and a verifier as enforcing correctness"
- Mutual information: A measure of statistical dependence between random variables. "the history prefix provides no mutual information about the upcoming support."
- PAC-style setting: The Probably Approximately Correct framework for learnability and sample complexity in statistical learning theory. "learnable in a PAC-style setting"
- Payload bits: The subset of input variables that carry data combined by monomials in the target function. "v=(v_1,\dots,v_p)\in{0,1}p$</sup> are payload bits."</li> <li><strong>Polynomial-time validator</strong>: A verification procedure whose runtime grows polynomially with input size. "exact-next accuracy with a polynomial-time validator."</li> <li><strong>Reflexion</strong>: An agentic loop where a model proposes, critiques, and revises its reasoning steps. "agentic loops such as Reflexion"</li> <li><strong>Statistical obfuscation</strong>: Masking labels with randomized structure so that data-only strategies gain negligible information. "we design a statistical obfuscation sampling oracle."</li> <li><strong>Step-success probability (γ)</strong>: The per-step probability that the model proposes a useful next move that keeps the reasoning prefix completable. "The viability of this framework hinges on a critical quantity: the stepwise success probability, denoted by $\gamma$."</li> <li><strong>Support (of a monomial)</strong>: The index set of variables included in a monomial. "each support $S_j\subseteq[p]|S_j|=d-1$."</li> <li><strong>Tree-of-Thought (ToT)</strong>: A search paradigm that explores partial reasoning states as a tree structure. "Tree-of-Thought search over partial reasoning states"</li> <li><strong>vLLM</strong>: A high-throughput serving system for LLM inference. "We run inference in vLLM on $3000$ generated instances"
Collections
Sign up for free to add this paper to one or more collections.

