- The paper introduces MICE, a minimal interaction cross-encoder that uses targeted masking of self-attention to isolate and retain only essential query-document interactions.
- Empirical results show that MICE achieves nearly full cross-encoder ranking effectiveness with a 4x reduction in inference latency and improved out-of-domain performance.
- The architecture enables efficient full-corpus retrieval by precomputing document vectors and applying layer dropping to maintain high ranking quality.
Minimal Interaction Cross-Encoders (MICE) for Efficient Re-ranking: An Expert Analysis
Motivation and Context
Neural Information Retrieval (IR) architectures have reached high effectiveness with interaction-heavy transformer-based cross-encoders, yet their inference cost remains prohibitive for full-corpus first-stage retrieval. This resource expenditure has maintained the two-stage retrieve-and-rerank paradigm, restricting cross-encoders to expensive reranking of candidate pools pre-selected by faster, less effective retrieval models (e.g., bi-encoders, BM25). Late-interaction models such as ColBERT offer improved efficiency, but their ranking performance lags behind cross-encoders. Prior acceleration methods targeting self-attention sparsity have not fully closed this gap.
This paper introduces MICE (Minimal Interaction Cross-Encoders), an approach leveraging interpretability and ablation studies to identify and eliminate non-essential self-attention interactions within cross-encoders, yielding an architecture that retains cross-encoder-level effectiveness but matches late-interaction efficiency.
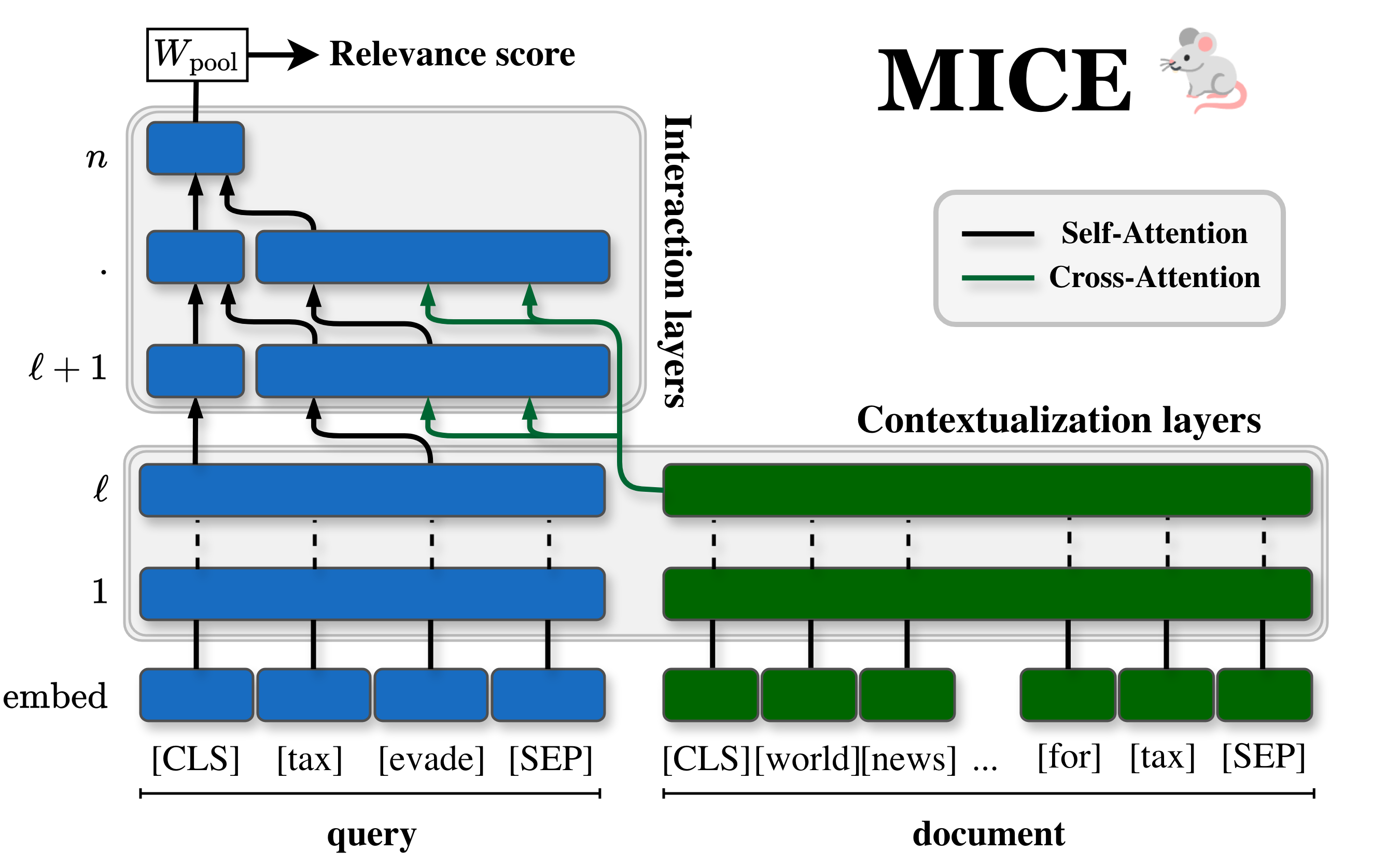
Figure 1: MICE Architecture: stripping cross-encoders to keep the strict minimum interactions that maintain effectiveness.
Methodological Overview: Masking and Architectural Derivation
The authors systematically decompose the cross-encoder self-attention mechanism by masking specific interactions among input segments ([CLS], Query (Q), Document (D), \SEP{} tokens). Following interpretability studies, several masking steps are proposed:
- Mask Step 0: Block information flow to \SEP{} tokens and from [CLS] to other parts, retaining attention sinks.
- Mask Step 1: Prevent document-to-[CLS] transfers.
- Mask Step 2: Remove query-to-document (D←Q) flows, hypothesized to be less critical.
- Mask Step 3: In early layers, block bidirectional query-document interactions, enabling independent query/document contextualization (mid-fusion).
These steps isolate the minimum set of attention pathways required for effective ranking. Ablations confirm that judicious masking is ineffective when applied post-hoc to fine-tuned models, due to latent reliance on masked pathways. However, fine-tuning with these masks in place maintains or even improves effectiveness, particularly out-of-domain (OOD).
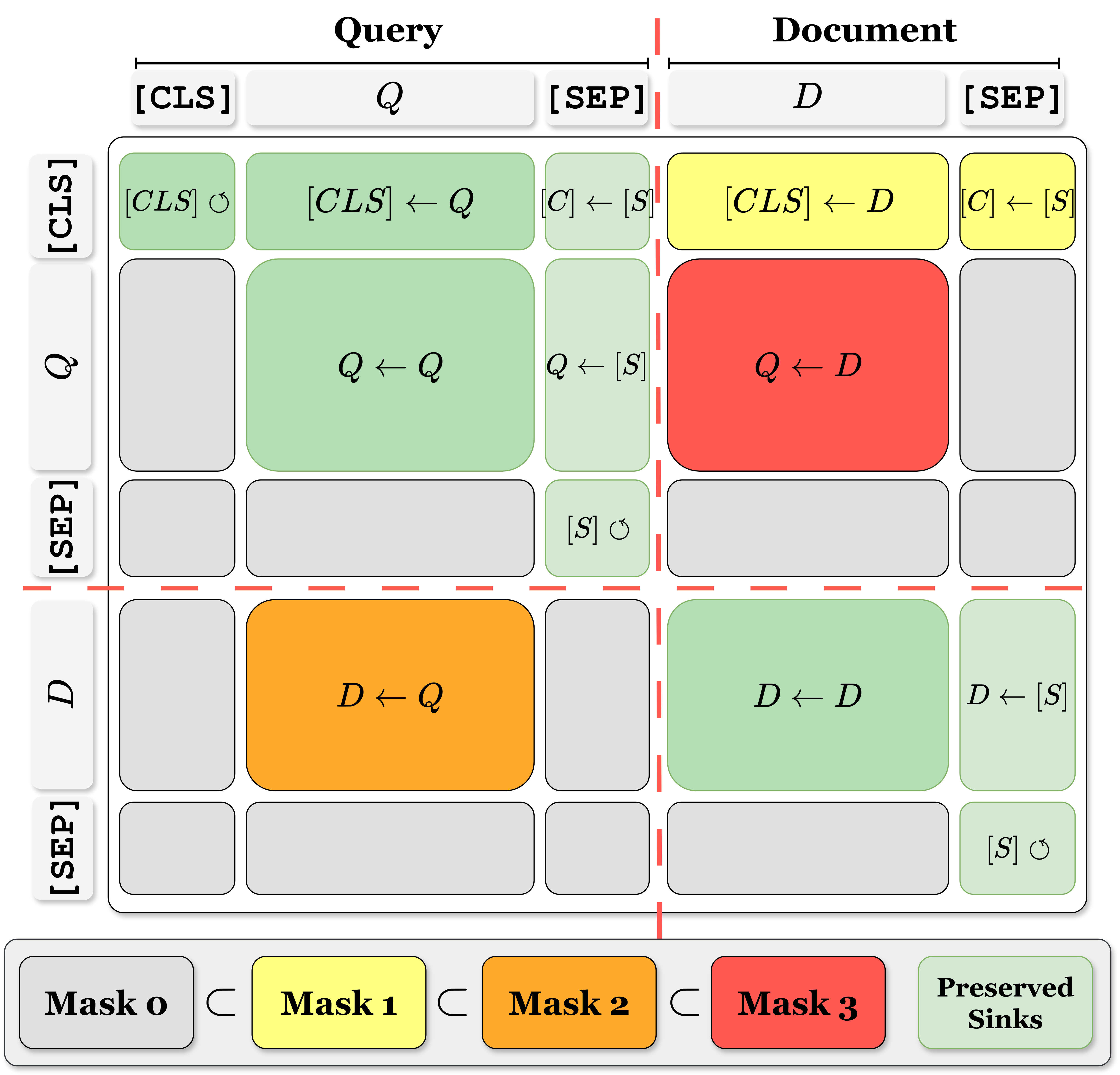
Figure 2: Masking approach. Interactions between input parts ([CLS], Q, D, \SEP{}) are blocked using cumulative masking.
MICE: Architecture and Implementation
MICE is constructed with three architectural innovations:
- Mid-Fusion: Initial layers encode query and document independently, deferring interaction until later layers.
- Light Cross-Attention: During interaction layers, only information transfer from a (frozen) document representation to the query is permitted. No further contextualization or updates to document tokens.
- Layer Dropping: Final layers specialized for masked language modeling are pruned; only a minimal number of interaction layers (e.g., three) are retained, empirically shown to recover near-original performance.
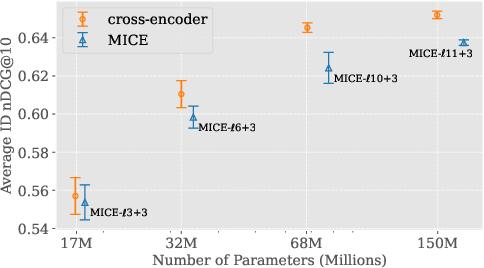
Empirical evaluation demonstrates that MICE, when properly configured (e.g., MICE-ℓ4+3 with MiniLM-L12-v2 backbone), can drop multiple late backbone layers without loss in ranking effectiveness.
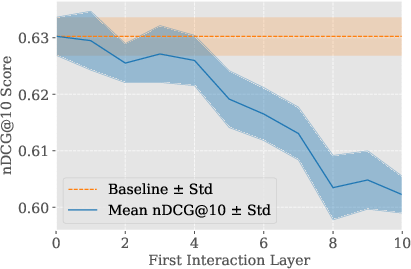
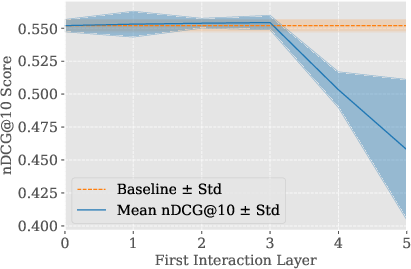
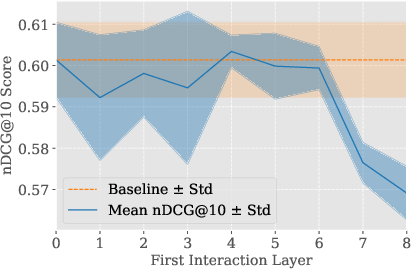
Figure 3: MiniLM-L12-v2 backbone used for MICE, facilitating efficient layer dropping and minimal interaction.
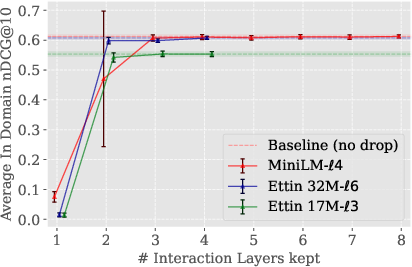
Figure 4: Impact of dropping backbone's late layers in MICE. 3 interaction layers consistently recovers full performance.
Empirical Results
MICE was tested vigorously on standard re-ranking benchmarks:
- In-Domain (ID): MS MARCO, TREC Deep Learning tracks.
- Out-of-Domain (OOD): 13 BEIR benchmark datasets.
Key findings:
Efficiency Analysis
Inference profiling on MiniLM-L12-v2 backbone revealed:
- Standard cross-encoder: 470ms, 267 docs/s, 1193MB peak memory.
- MICE (with offline document encoding): 113ms latency per query, $1130$ docs/s, 598MB.
- ColBERT: 130ms, $982$ docs/s, 331MB.
MICE is 4× faster than cross-encoder and marginally faster than ColBERT, though its memory footprint is slightly higher due to frozen document representations. When run without precomputed document encoding, speedup is 2×.
Contradictory Claims and Strong Results
The study demonstrates contradictory evidence to prior assumptions: masking query-to-document interactions (D←Q) is not detrimental, and in fact, enhances OOD generalization. Masking document-to-query (Q←D) as done in Sparse CE does not yield comparable effectiveness. Strong numerical claims: MICE obtained up to $11.3$ nDCG@10 on BM25-hard datasets above its own baselines.
Practical and Theoretical Implications
Practically, MICE facilitates deployment of cross-encoder-level ranking models as first-stage retrievers, enabling full-corpus search with acceptable latency and resource usage. The minimal interaction design allows for document vector pre-computation, akin to late-interaction models, integrating with existing IR infrastructure.
Theoretically, the findings support a refined understanding of transformer-based cross-encoders in IR, revealing which interaction directions are crucial and which are redundant, aligning with interpretability studies. Masking unnecessary attention pathways acts as a regularizer, improving robustness and generalization.
(Figure 1 repeated)
Figure 1: MICE Architecture: stripping cross-encoders to keep the strict minimum interactions that maintain effectiveness.
Speculation on Future Development in AI
MICE's reductionist approach can guide future design of efficient, accurate neural ranking architectures, especially in large-scale, heterogeneous retrieval contexts. Extending MICE to larger backbones, integrating more aggressive dimensionality compression with distillation, and automating optimal layer selection or masking based on corpus-specific data may further propel efficiency. These developments may enable cross-encoder models to be standard in real-time, full-corpus retrieval—overcoming the entrenched trade-off between speed and ranking effectiveness in neural IR.
Conclusion
By combining targeted masking of self-attention interactions, mid-fusion contextualization, light cross-attention, and layer dropping, Minimal Interaction Cross-Encoders (MICE) achieve a new effectiveness-efficiency operating point for neural IR. MICE matches late-interaction efficiency while almost fully preserving cross-encoder effectiveness, and demonstrates superior out-of-domain generalization. The approach re-defines architectural requirements for high-performing rankers and establishes a foundation for scalable, robust, and precise neural retrieval systems.
Reference: "MICE: Minimal Interaction Cross-Encoders for efficient Re-ranking" (2602.16299)