- The paper presents a novel connection between uniform-state discrete diffusion and continuous Gaussian processes, enabling the transfer of advanced techniques.
- The paper implements curriculum learning to reduce training variance and double training speed, achieving competitive zero-shot performance.
- The paper adapts discrete consistency distillation for few-step generation, speeding up sampling by two orders of magnitude while maintaining quality.
The Diffusion Duality
The paper "The Diffusion Duality" introduces an innovative approach to discrete diffusion models by drawing parallels between discrete diffusion processes and continuous Gaussian diffusion processes. This methodology, encapsulated in the Duo model, enhances the applicability and efficiency of diffusion processes in language modeling.
Conceptual Framework
Uniform-State Diffusion and Gaussian Emergence
The paper begins by establishing a fundamental connection between uniform-state discrete diffusion and an underlying continuous Gaussian diffusion process. By leveraging the operation within these models, the authors demonstrate that the marginals of a Gaussian diffusion can be transformed into those of a uniform-state discrete diffusion, thus enabling the transfer of advanced techniques from Gaussian diffusion to discrete diffusion models.
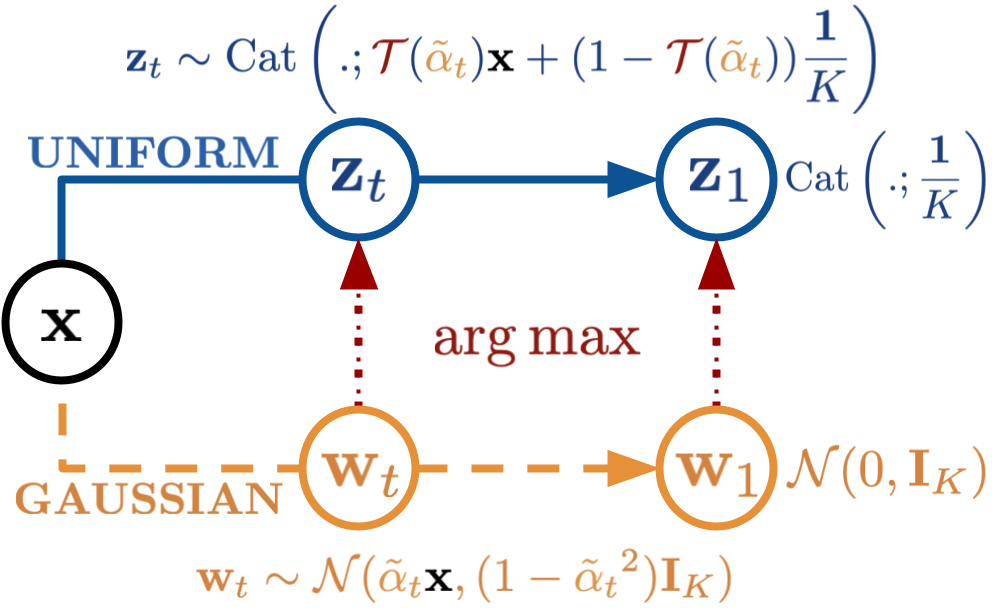
Figure 1: An illustration of Uniform-state discrete diffusion (top) and the underlying Gaussian diffusion (bottom).
Key Contributions
- Curriculum Learning for Fast Training
The authors introduce a curriculum learning approach that reduces training variance, consequently doubling the training speed. This model, when evaluated against autoregressive models across multiple benchmarks, not only competes favorably but even surpasses these traditional models in zero-shot perplexity on several tasks.
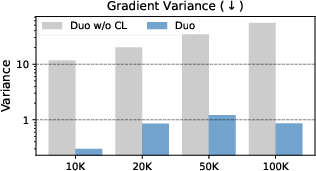
Figure 2: Curriculum learning drastically lowers the gradient variance in Duo trained with a fixed τ=0.001. The figure shows the summed gradient variance of the 100 weights with the highest variance, comparing Duo with CL (blue) and without CL (grey).
- Discrete Consistency Distillation
By adapting consistency distillation from continuous to discrete settings, Duo facilitates few-step generation in diffusion LLMs. This method accelerates sampling by two orders of magnitude without significantly affecting sample quality.
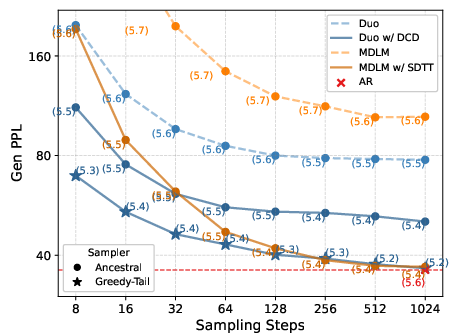
Figure 3: Sample quality comparison of Duo vs. MDLM. Duo outperforms MDLM in Gen PPL (downarrow) for base models and in low-NFE regime after 5 distillation rounds.
- Extending Discrete Diffusion Framework
The research extends the use of discrete diffusion by incorporating techniques from Gaussian diffusion, thus enriching the training strategies and increasing the operational efficiency of Uniform-state Diffusion Models (USDMs).
Theoretical Analysis
The paper explores the mathematical backing of these findings, introducing a closed-form expression for the mapping of Gaussian marginals to discrete states. It establishes the time evolution of these marginals, supported by linear ordinary differential equations that characterize a uniform-state discrete diffusion process.
Empirical Evaluation
The empirical results demonstrate that Duo achieves state-of-the-art performance in numerous standard language modeling benchmarks. This includes competitive results on zero-shot datasets where Duo not only matches but sometimes outperforms autoregressive transformers.
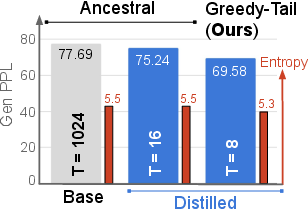
Figure 4: Sample quality comparison between the base Duo model and Duo distilled for 5 rounds using our DCD algorithm.
Implications and Future Directions
Implications
The work suggests substantial implications for the development and efficiency of discrete diffusion models in AI. The theoretical bridge between discrete and continuous diffusion models simplifies the adoption of sophisticated techniques from continuous settings, enhancing training and inference in discrete models.
Future Directions
Future research can explore further refinements of discrete consistency distillation and curriculum learning approaches. Additionally, exploring the integration of these methods into other domains beyond language modeling, such as graph or molecular generation, could be beneficial.
Conclusion
The insights provided by this paper significantly enrich the methodology of discrete diffusion models, offering robust tools for enhancing interpretability and effectiveness in AI applications. This foundational approach is poised to influence a broad spectrum of applications where discrete diffusion processes are relevant.