- The paper introduces a keyframe-based approach that condenses dense observation histories into semantically meaningful events to mitigate spurious correlations.
- It employs a diffusion transformer policy with latency masking, enhancing robustness by conditioning on current observations and selected keyframes.
- Empirical evaluations across multi-stage tasks reveal up to a 70% improvement over naive history-conditioned policies in both real-world and simulated environments.
BPP: Long-Context Robot Imitation Learning by Focusing on Key History Frames
Motivation and Problem Analysis
Robotic imitation learning has achieved widespread success in settings where only local, current observations are required for action prediction. However, numerous real-world tasks—such as sequential search, ingredient counting, and multi-stage manipulation—require reasoning over the history of sensory inputs and actions. Conditioning policies on temporal sequences theoretically enables memory, but empirically, history-conditioned policies often fail, especially when exposed to novel, non-expert rollouts. The central finding highlighted is that coverage over the exponentially large space of observation histories is fundamentally lacking; as a result, policies overfit to spurious correlations in training data and fail in deployment scenarios.
Action chunking and architectures with shared encoders across timesteps alleviate catastrophic failure but do not close the performance gap to oracle policies, as models still lack robustness on out-of-distribution histories. Empirical evaluation with auxiliary regularization (including explicit ground-truth state predictions) demonstrates that these methods actually degrade generalization, reinforcing that coverage—not architectural or objective engineering—is the “bottleneck” (Figure 1).
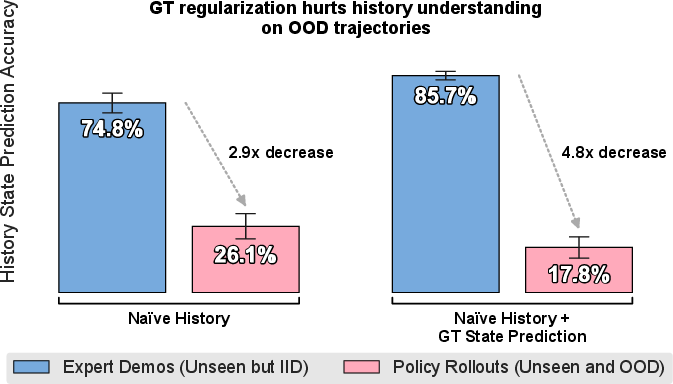
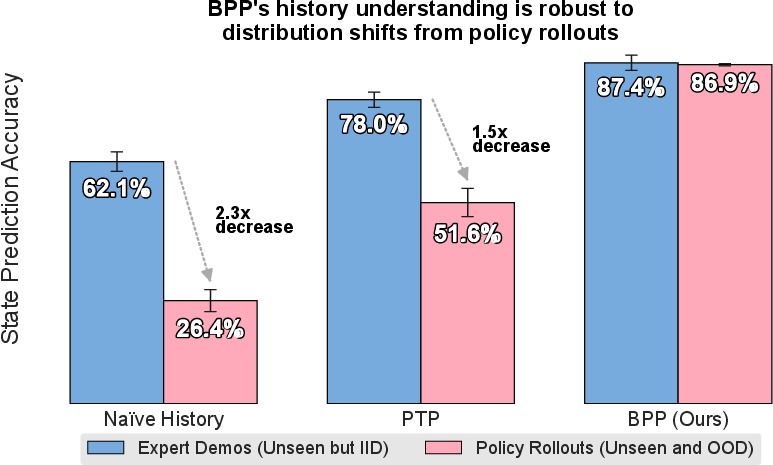
Figure 1: History state prediction regularization hurts history understanding; auxiliary ground-truth state prediction improves in-distribution accuracy but exacerbates reliance on spurious correlations under rollout shift.
BPP Methodology and System Design
The Big Picture Policies (BPP) approach resolves the coverage issue by changing the representation of history from dense, uniformly-strided observation sequences to a compact set of semantically meaningful keyframes. Keyframes correspond to salient events (e.g., object grasp, subgoal completion), detected via vision-LLMs (VLMs) using simple prompt engineering. Keyframe selection compresses varied trajectories into a concise, behaviorally relevant summary, ensuring that the policy input space at train and test time exhibits strong overlap and mitigating spurious correlations.
The BPP system architecture leverages a diffusion transformer policy conditioned exclusively on the current observation and detected keyframes. Latency masking during training simulates VLM inference delays during deployment, yielding realistic and robust behavior.
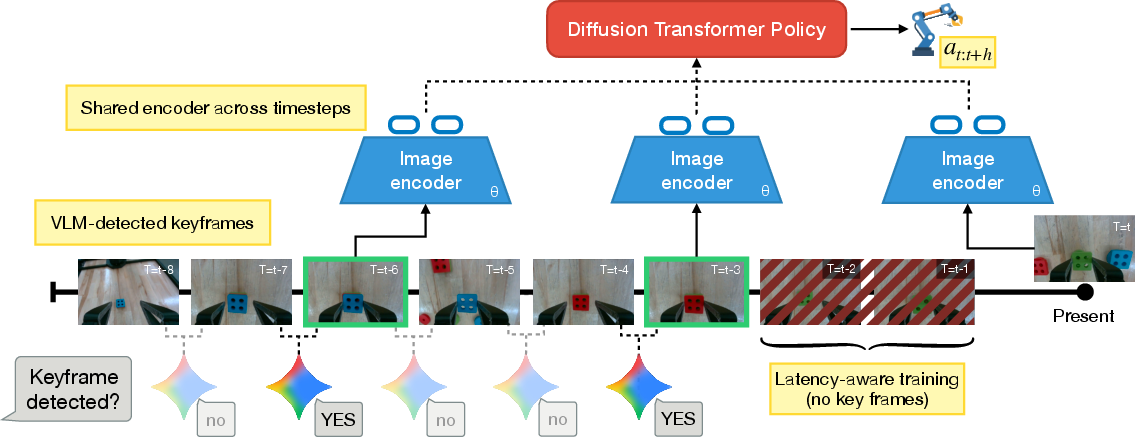
Figure 2: BPP system architecture; diffusion transformer policy receives current observation and a small set of history keyframes detected by VLMs, masking recent events for latency.
Empirical Evaluation: Real-World and Simulation Benchmarks
BPP is evaluated across four complex real-world manipulation tasks and three simulation tasks, all requiring history reasoning for success. Real-world tasks include Mug Replacement, Marshmallows, Drawer Search, and Stacking Puzzle, each characterized by long horizons and diverse operator strategies. Simulation tasks focus on password entry and ingredient counting with hidden state.
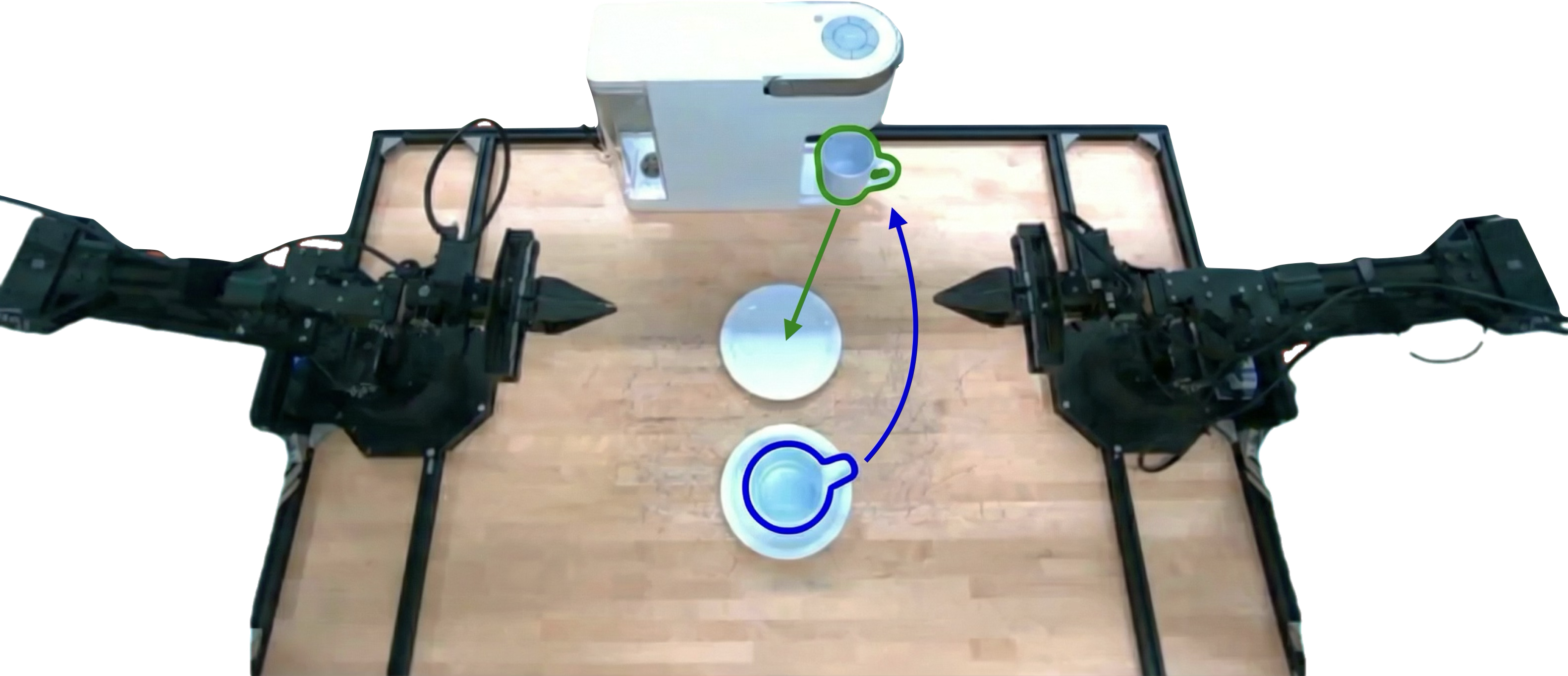


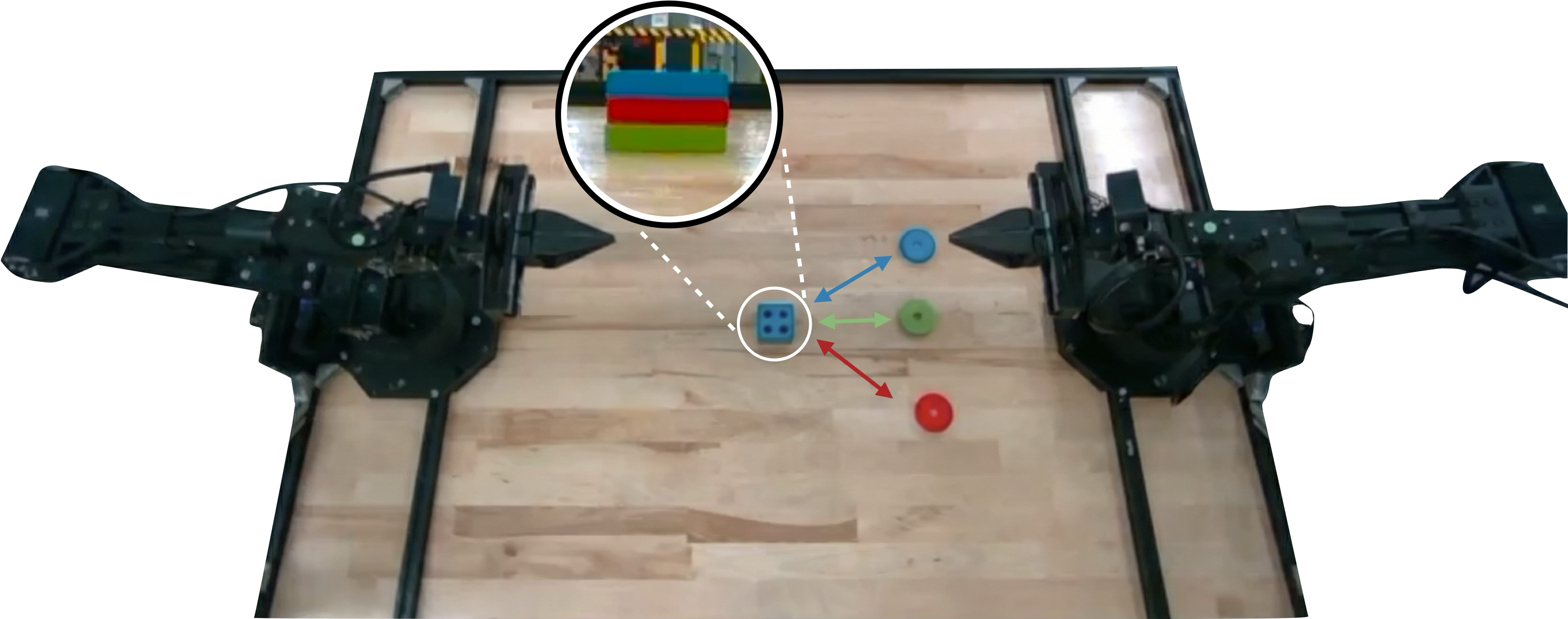



Figure 3: Benchmark tasks span real-world object manipulation and simulation scenarios, unified by the requirement of history conditioning.
On real-world benchmarks, BPP outperforms memoryless and naive history-conditioned baselines by up to 70% in success rates, demonstrating robust progress tracking and avoidance of redundant or premature actions (Table: Real Robot Experiments). In Drawer Search, for instance, BPP strategically searches multiple drawers without revisiting, whereas history-agnostic policies loop or terminate early.
PTP (Past Token Prediction) provides task-specific improvements where past actions tightly correlate with task state, but fails otherwise—especially in scenarios where identical actions arise from ambiguous states (Figure 4).

Figure 4: PTP failure in Drawer Search; inability to disambiguate task progress after failed grasps or checking empty drawers.
Qualitative filmstrips further confirm that BPP's keyframe-based memory sustains progress in long-horizon, non-Markovian environments (Figure 5, Figure 6).
Figure 5: Drawer Search evaluation behaviors; BPP demonstrates systematic exploration and avoids repetitive failures.


Figure 6: Mug Replacement evaluation behaviors; BPP accurately completes multi-stage swaps, outperforming naive history-conditioning.
In simulation, BPP not only surpasses all non-oracle policies but, in some cases, exceeds performance achieved with ground-truth state access (Figure 7), likely due to better learning representations.
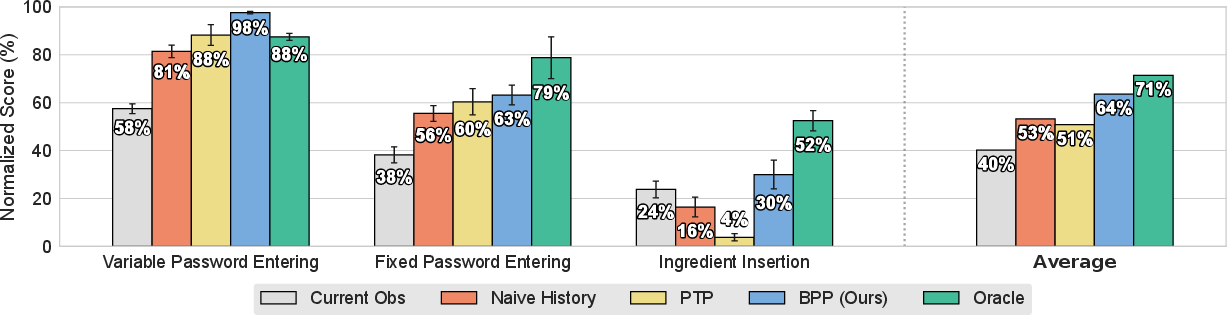
Figure 7: Simulation results; BPP outperforms non-oracle and even oracle methods, showing superior learning from keyframe-conditioned histories.
Ablations and Robustness
Data efficiency ablations show BPP achieves high success rates with modest demonstration counts, whereas naive history conditioning requires extensive data to converge, underscoring the importance of input space compression. VLM errors (false positives, latency) impose only modest performance drops; the system is robust to imperfect detection, though systematic failures can impact outcomes.
Implications, Limitations, and Future Directions
BPP introduces a paradigm shift in history-conditioned imitation learning by emphasizing input space representation over loss or architecture engineering. Its method—semantic event abstraction and VLM-driven filtering—enables scalability to tasks with longer horizons and increased behavioral diversity, even under limited demonstration coverage.
Practically, BPP enables progress tracking in sequential tasks, systematic retry after failures, and avoidance of overfitting to incidental observation sequences. Theoretically, the approach motivates future research on event-based robot policy abstractions, automatic keyframe detection via LLMs, and adaptation to in-context learning from failure or environmental shifts.
Operational limitations include VLM inference latency and dependence on accurate event detection. Mitigation via low-latency distillation and event-segment generalization are promising extensions. Automatic keyframe labeling, potentially using LLM-generated definitions and prompts, would further reduce domain specification burden and support broad generalization.
Conclusion
BPP addresses the primary challenge of history-conditioned imitation learning—coverage over observation histories—by conditioning on behaviorally salient keyframes detected with VLMs. This representation shift enables robust generalization, efficient data utilization, and state-of-the-art performance on real-world and simulation benchmarks. The implications extend toward scalable, event-based robot learning systems, resilient to demonstration diversity and real-world deployment shifts (2602.15010).