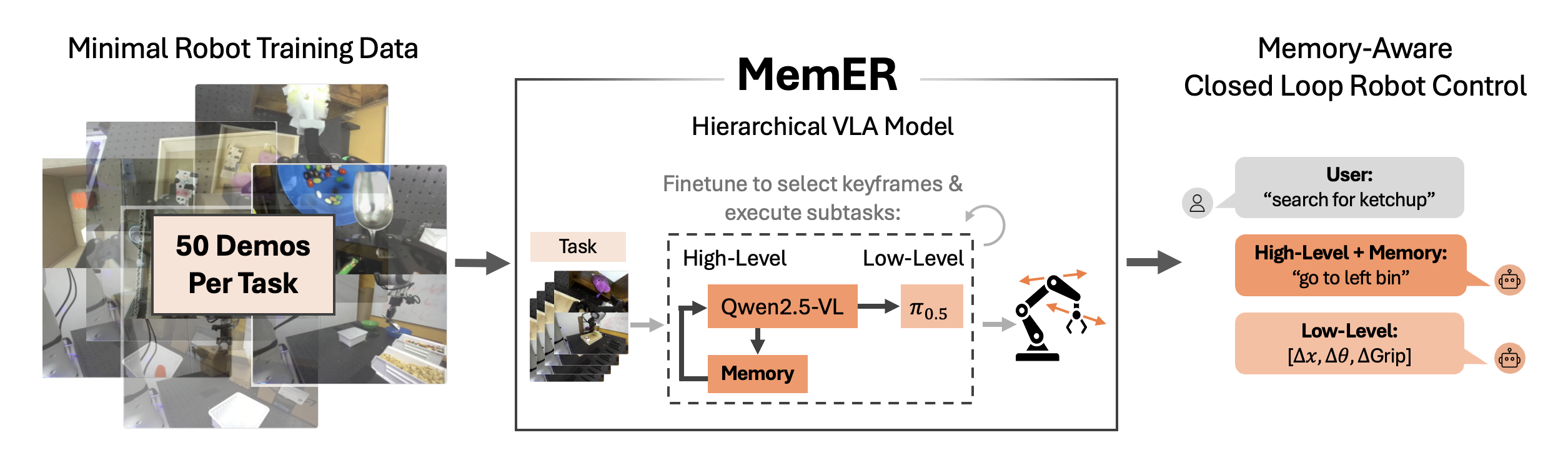
MemER: Scaling Up Memory for Robot Control via Experience Retrieval
Abstract: Humans routinely rely on memory to perform tasks, yet most robot policies lack this capability; our goal is to endow robot policies with the same ability. Naively conditioning on long observation histories is computationally expensive and brittle under covariate shift, while indiscriminate subsampling of history leads to irrelevant or redundant information. We propose a hierarchical policy framework, where the high-level policy is trained to select and track previous relevant keyframes from its experience. The high-level policy uses selected keyframes and the most recent frames when generating text instructions for a low-level policy to execute. This design is compatible with existing vision-language-action (VLA) models and enables the system to efficiently reason over long-horizon dependencies. In our experiments, we finetune Qwen2.5-VL-7B-Instruct and $\pi_{0.5}$ as the high-level and low-level policies respectively, using demonstrations supplemented with minimal language annotations. Our approach, MemER, outperforms prior methods on three real-world long-horizon robotic manipulation tasks that require minutes of memory. Videos and code can be found at https://jen-pan.github.io/memer/.

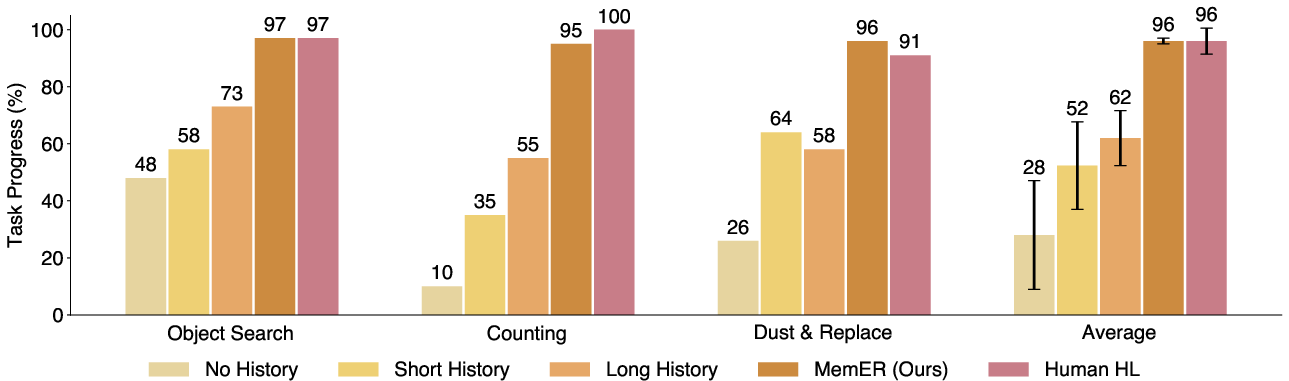
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how to give robots a better “memory” so they can finish long, multi-step jobs in the real world. Instead of trying to look at every video frame they’ve ever seen (which is slow and confusing), the robot learns to remember just the most important moments as simple snapshots. The method is called MemER, short for Memory via Experience Retrieval.
What questions did the researchers ask?
- How can a robot remember key things it saw earlier (like where an object was) without slowing down?
- Can a robot pick out the few frames worth remembering from a long video stream?
- Will this kind of memory help on real, long tasks, like searching for objects, counting scoops, or cleaning a shelf?
- Is it better to remember with pictures, words, or both?
- Do open-source models (that anyone can use) work well if you train them a bit, compared to big, closed, online models?
How did they do it?
The two-part robot “brain”
They split the robot’s control into two parts, like a team:
- A high-level planner that thinks and decides what to do next.
- A low-level doer that moves the robot’s arm and gripper precisely to carry out the plan.
Think of the planner as saying “Open the left bin” or “Pick up the duster,” and the doer as actually moving the arm to do that safely.
Picking the right memories: “keyframes”
Instead of remembering every single frame, the planner learns to choose “keyframes,” which are just especially helpful snapshots (like a bookmark in a long video). For example, if the robot looked inside a bin and saw a ketchup bottle, it can save that frame so it can later remember, “Ketchup was in the right bin.”
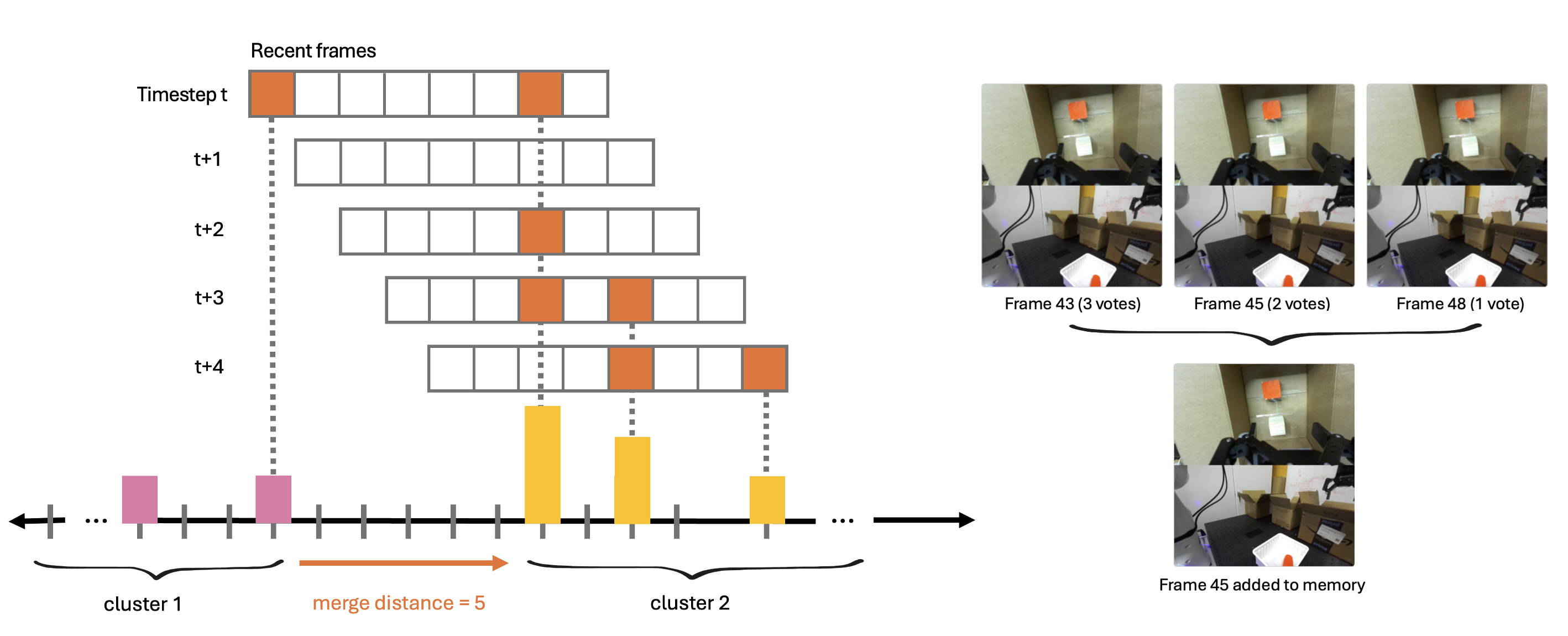
To keep things tidy, the method groups keyframes that are very close in time and keeps just one representative snapshot. That’s like taking a bunch of photos during the same moment and then keeping the best one. This keeps memory small and useful.
What the planner and doer see
- The planner always looks at a small recent window of frames (the last few seconds) plus the saved keyframes (older, important snapshots).
- The planner outputs the next subtask (plain text like “look in right bin”) and suggests any new keyframes to remember.
- The doer takes the subtask text and the current images and outputs actual arm movements.
Training
They trained the system with about 50 human demonstrations per task, plus a few extra “intervention” demos to help fix common mistakes. They fine-tuned:
- A video-LLM (Qwen2.5-VL-7B-Instruct) for the high-level planner.
- A robot control model (called π₀.₅) for the low-level actions.
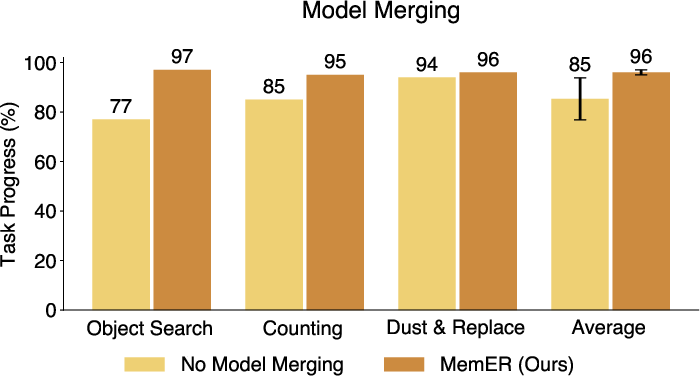
They also used a simple trick called “model merging,” which blends some of the original general knowledge of the planner with what it learned from the new robot training. This helped it stay robust to weird situations.
Running in real time
- The planner runs about once per second (to choose the next subtask and keyframes).
- The doer runs about twice per second (to update arm motions frequently). This keeps the robot responsive without being overwhelmed by too much video.
What did they find, and why does it matter?
- MemER beat other approaches on three long, real-robot tasks:
- Object Search: The robot had to find requested items placed in opaque bins. With memory, it could skip re-checking bins it already looked in and go straight to the right place.
- Counting Scoops: The robot had to put the correct number of scoops of two different ingredients into two bowls. Memory helped it keep count.
- Dust and Replace: The robot had to remove objects from shelves, dust each shelf, and put objects back in their exact spots. Memory helped it remember where things were and which shelf was already dusted.
- Compared to “no memory,” “short memory,” or “just give it a long sequence” baselines, MemER did much better. Simply feeding a lot of frames made the system slow and still not reliable. Picking the right keyframes worked best.
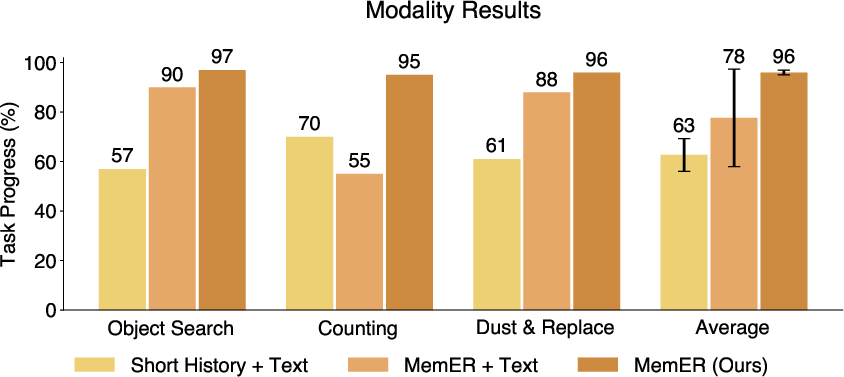
- Remembering with pictures worked better than remembering with text. Adding text notes sometimes made the planner pay too much attention to words and ignore visuals, which led to mistakes. Visual memory alone was the most reliable.
- Big proprietary online models (like GPT-5 or Gemini Robotics-ER 1.5) were too slow for real-time control and didn’t perform as well without special fine-tuning for robot tasks.
- Model merging (blending the fine-tuned planner with its original weights) improved robustness.
What’s the impact?
This work is a step toward robots that can handle long, real-world jobs—like tidying a room or cooking—where remembering past observations matters. By storing just the most important snapshots, robots can:
- Work faster (less to process),
- Make fewer mistakes,
- And use existing vision-LLMs more effectively.
In the future, this idea could be expanded to:
- Manage memory over even longer times (including forgetting no-longer-useful snapshots),
- Add other senses like touch or sound,
- Run even faster for more reactive control,
- And work across different robots and mobile tasks (like cleaning multiple rooms).
Overall, MemER shows that smart, selective memory helps robots plan better and act more reliably over long tasks—much like how people remember the key moments that matter.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Memory scalability and forgetting:
- No mechanism to discard or compress memories once accumulated; unclear policies for memory eviction, prioritization, or decay for hour-scale tasks with tight latency budgets.
- Fixed memory budget of ≤8 keyframes without ablations on memory size vs. performance vs. latency; no scaling laws or adaptive memory sizing.
- Keyframe selection and consolidation:
- Keyframe selection is supervised via simple subtask-specific rules and consolidated by a 1D temporal clustering heuristic; no content-aware deduplication, robustness to occlusions, or learned importance scoring.
- Sensitivity to clustering hyperparameters (e.g., merge distance d) and context window N is not studied; no adaptive or confidence-aware selection strategies.
- Representative-frame choice (median index) is not justified; content quality (e.g., visibility, pose) is not used when picking cluster representatives.
- Missed critical frames cannot be recovered because selection operates only on frames nominated within the recent N-frame window; no mechanism to search farther back or backfill from the full episode buffer.
- Memory representation:
- Memory is limited to images; textual memory underperforms in this setup, but the paper does not explore structured memory (e.g., scene graphs, object-state logs, counters) or multimodal fusion strategies that mitigate language over-attention.
- No exploration of compact visual representations (e.g., learned embeddings, object slots, event summaries) that could improve capacity/latency trade-offs.
- No persistent, cross-episode memory (lifelong/continual) across days, tasks, or environments; object identity tracking and long-term entity consistency remain open.
- High-level policy training and robustness:
- High-level model is trained on optimal expert demonstrations; robustness to low-level failures (retries, stalls, backtracking) is only partially addressed via weight interpolation, without explicit training on off-policy/failure data.
- No on-policy data aggregation, RL fine-tuning, or counterfactual data augmentation to make the high-level policy robust to non-expert state distributions and failure recovery.
- Model merging uses a fixed α=0.8; no sensitivity analysis, principled selection, or comparison to alternative ensembling/regularization approaches (e.g., adapter mixtures, SVD-based merging).
- Low-level policy and interface:
- Failures are frequently attributed to the low-level policy, but the interface design (subtask granularity, timing of transitions) and its effect on low-level success are not systematically analyzed.
- No comparison of alternative intermediate representations (e.g., waypoints, affordance maps) vs. language subtasks for more reliable execution.
- Latency and scheduling:
- The system operates at ~1 Hz for the high-level and ~2 Hz for the low-level; viability for tasks requiring high-frequency reactions to rapid changes is not evaluated.
- Asynchronous execution risks subtask-context mismatches; no formal analysis or mitigation for synchronization, stability, or safety in the presence of delays.
- Evaluation scope and generalization:
- Experiments focus on three tabletop manipulation tasks with a single robot embodiment and two RGB cameras; no tests on mobile manipulation, multi-room settings, deformable objects, liquids, or highly cluttered/novel environments.
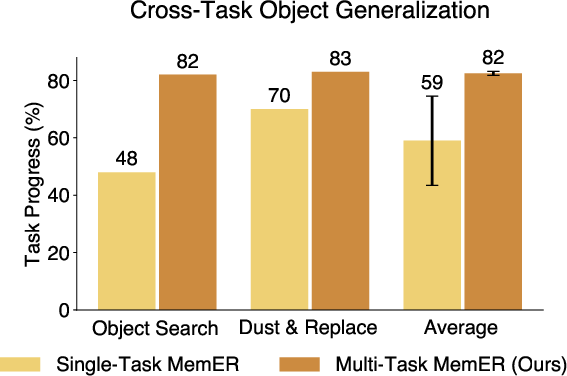
- Generalization beyond the tested object sets and layouts is limited; cross-domain/object generalization is only partially explored (single vs. multi-task), without broader datasets or unseen environments.
- No robustness tests under sensor noise, camera failures, lighting variation, motion blur, distractors, or adversarial rearrangements by external agents.
- Baselines and alternatives:
- Comparisons omit learned memory modules (e.g., key–value memory networks, recurrent architectures with gating/attention, differentiable external memories) and content-retrieval baselines (e.g., embedding-based nearest-neighbor keyframe retrieval, change-point/event segmentation models).
- API-based VLM comparisons are offline, prompt-sensitive, and without fine-tuning; fairness and conclusions about capability vs. latency are therefore limited.
- Counting and temporal reasoning:
- Counting performance relies implicitly on keyframe enumeration; no explicit temporal/logical state tracking (e.g., learned counters, finite state machines, belief updates) to handle near-duplicate visual states or ambiguous frames.
- No analysis of error accumulation when count-related frames are missed or duplicated; no corrective mechanisms (e.g., uncertainty-aware re-checks or confirmations).
- Active perception and memory acquisition:
- The system does not actively seek informative observations (e.g., viewpoint selection) to acquire better keyframes; no closed-loop coordination between active perception and memory building.
- No ablations on the number of nominated candidate frames per step or strategies to throttle/expand nomination to meet latency constraints.
- Ordering and prompting effects:
- The order and formatting of keyframes in the high-level model context are not ablated; VLMs are known to be order-sensitive, and optimal interleaving/layout is unexplored.
- Tokenization and caching strategies for lower latency are mentioned as future directions but not evaluated.
- Safety and open-loop execution:
- The system executes 8 open-loop low-level actions per cycle; safety, collision avoidance, and recovery behaviors are not formally assessed, especially under memory or perception errors.
- Annotation burden and scalability:
- Subtask segmentation and rule-based keyframe labeling require human input; scalability to many tasks and environments, and robustness to label noise, remain untested.
- No investigation of unsupervised/subtask discovery, self-labeling, or weakly supervised keyframe targets to reduce annotation effort.
- Metrics and diagnostics:
- No explicit metrics or diagnostics for “memory quality” (e.g., utility, precision/recall of keyframes, contribution to decisions); attribution of which memories influenced specific predictions is absent.
- Lack of theoretical or empirical analysis linking memory design to reduction in covariate shift or compounding errors.
- Privacy, ethics, and governance:
- Persistent storage of visual memories raises privacy and data governance issues; retention policies, selective redaction, or on-device constraints are not addressed.
- Hardware and compute efficiency:
- Training costs (e.g., 96 H200 GPU hours for the high-level) are non-trivial; strategies for distillation, model compression, or smaller backbones with comparable performance are not explored.
- Multi-agent and collaboration:
- No extensions to shared memory across agents, collaborative tasks, or communication protocols for distributed episodic memory.
Practical Applications
Immediate Applications
The following applications leverage MemER’s demonstrated capabilities and compatibility with existing VLA stacks. They can be piloted or deployed now with modest data collection (≈50 demonstrations), two-camera setups, and commodity GPUs, assuming access to open-weight models (e.g., Qwen2.5-VL-7B-Instruct) and low-level controllers (e.g., π₀.₅/DROID).
- Memory-aware bin/bay search and retrieval in workcells (Manufacturing, Logistics, Retail)
- Description: Robots perform “object search” across opaque or cluttered bins/shelves, remembering previously inspected locations to avoid redundant search and navigate to the optimal next location.
- Tools/Products/Workflows: MemER high-level module + ROS2 node; keyframe memory store with single-linkage clustering; “Memory Dashboard” for visualizing selected keyframes and subtask sequencing; integration with warehouse WMS.
- Assumptions/Dependencies: Wrist + third-person cameras; stable subtask schema; latency budget ~1 s for high-level inference; safe manipulation primitives from the low-level policy.
- Shelf dusting, restocking, and “restore-to-original-state” routines (Retail, Facilities Management, Hospitality)
- Description: Long-horizon tidying tasks with episodic memory of object locations and completed steps (e.g., dusted shelf A but not shelf B; restore items to remembered placements).
- Tools/Products/Workflows: MemER “Memory-Aware Task Planner” templates (dust/replace); semi-automatic keyframe annotation rules per subtask; supervisory UI to confirm placements.
- Assumptions/Dependencies: Minimal language annotations; reliable pick/place primitives; continuous visual tracking of shelves; defined failure recovery subtasks.
- Counting and batching workflows (Food service, MedTech logistics, Kitting)
- Description: Robots count repeated scoops or batch items into containers while tracking progress across minutes-long sequences; reduces over/under-filling without relying on brittle text-only memory.
- Tools/Products/Workflows: Count-tracking subtask libraries; MemER keyframe memory only (no text memory to avoid attention over-indexing); exception handling (retries after missed grasps).
- Assumptions/Dependencies: Visually distinguishable containers and scoops; well-calibrated policies for retries; low-level action chunking at ~15 Hz.
- On-the-fly “episodic memory” augmentation for existing VLA robots (Software/Robotics)
- Description: Drop-in high-level MemER module that selects visual keyframes and issues subtasks to a vendor or open-source low-level controller (Octo/π₀.₅/OpenVLA).
- Tools/Products/Workflows: MemER wrapper library; ROS2 bridge; memory inspection API; weight merging utility (pretrained + finetuned α≈0.8) to preserve robustness.
- Assumptions/Dependencies: Access to high-level VLM finetuning; 5–15 epochs; compute budget (tens of GPU hours); recent-frame buffers (2 Hz) and memory cap (≤8 keyframes).
- Robotics education/labs: long-horizon control curriculum (Academia, Education)
- Description: Course modules on hierarchical control and memory retrieval; students reproduce three tasks (search, counting, dust/replace) and ablate modalities (vision-only vs. text+vision).
- Tools/Products/Workflows: Ready-to-use dataset/protocols; annotation assistants; evaluation harness for trajectory/boundary accuracy; reproducible pipelines.
- Assumptions/Dependencies: Access to a manipulator (Franka or similar), two cameras, and compute; safe lab SOPs.
- Memory visualization and debugging tools (Software/Robotics)
- Description: Developer-facing memory UIs showing nominated frames, clusters, and selected keyframes; step-wise subtask outputs to diagnose mispredictions or over-attention to text.
- Tools/Products/Workflows: “Keyframe Inspector,” clustering timeline view, subtask sequence diff tools; inference logging.
- Assumptions/Dependencies: Loggers, time-synced sensors, reproducible runs.
- Hospital supply restocking and linen routing (Healthcare operations)
- Description: Long-horizon supply retrieval and placement with memory of previously visited storage locations; avoids redundant checks and tracks completion status across carts/rooms.
- Tools/Products/Workflows: MemER-based route subtasks; keyframe memory checkpoints per room/bay; simple compliance logging (what was inspected/moved).
- Assumptions/Dependencies: Non-sensitive visual fields (avoid PHI); controlled environments; clear subtask schemas (e.g., room-level lists).
- In-store guided search assistant for associates (Retail, Customer Support)
- Description: Mobile-manipulator or stationary robot assists staff by recalling where products were seen earlier, reducing lookup time and duplicated search.
- Tools/Products/Workflows: Voice or kiosk interface; MemER memory retrieval and visual cue surfacing; “seen earlier” snapshots.
- Assumptions/Dependencies: Store mapping; permission to capture visual keyframes; privacy notices.
- Quality assurance re-checks with episodic recall (Manufacturing)
- Description: Robot recalls prior inspection states when anomalies are detected downstream, revisiting relevant stations or components without re-scanning everything.
- Tools/Products/Workflows: Keyframe memory link to QA events; “revisit” subtask templates; model merging to retain generalization over varied parts.
- Assumptions/Dependencies: Traceability; device IDs; stable lighting/visual quality; low-latency scheduling.
- Benchmarking and dataset extension for long-horizon manipulation (Academia)
- Description: Immediate replication of MemER tasks with standardized metrics (trajectory accuracy, boundary accuracy, per-component scores).
- Tools/Products/Workflows: Task specification packs, metric scripts; modality ablation protocols; public leaderboards.
- Assumptions/Dependencies: Comparable embodiments; similar camera configuration; standardized annotation rules.
Long-Term Applications
These applications require additional research in scalable memory management (e.g., deletion/aging), multimodal fusion, higher-frequency control, mobile manipulation, and stronger privacy/compliance frameworks.
- Multi-hour, multi-room episodic memory for mobile manipulation (Robotics, Smart Facilities)
- Description: Robots interleave SLAM-style spatial maps with MemER-style visual episodic memories to clean, restock, and audit multi-room environments over hours.
- Tools/Products/Workflows: “Memory OS” combining spatial-semantic maps + keyframe memory; cross-episode retrieval; task-level progress graphs.
- Assumptions/Dependencies: Memory pruning and forgetting strategies; robust scheduling beyond 1–2 Hz; on-device or edge inference; reliable navigation stack.
- Privacy-preserving memory policies and auditing (Policy, Governance, Healthcare)
- Description: Standards for visual memory retention (keyframe caps, aging, redaction), access controls, and audit logs (who accessed which frame and why).
- Tools/Products/Workflows: Policy toolkits; memory encryption; PHI-aware redaction models; opt-in signage and consent workflows.
- Assumptions/Dependencies: Legal frameworks (HIPAA/GDPR equivalents for robotics); stakeholder buy-in; certifiable compliance tooling.
- Multimodal memory (vision + tactile + audio) for dexterous tasks (Robotics, Manufacturing)
- Description: Fuse tactile events (grip patterns), audio cues (pouring/scraping), and visual keyframes to enhance robustness in similar-looking subtasks (e.g., counting scoops).
- Tools/Products/Workflows: Sensor-fusion memory stores; cross-modal clustering; retriever modules for “what happened” not just “what was seen.”
- Assumptions/Dependencies: Tactile/force sensors; audio capture; model architectures for multimodal retrieval; domain-specific annotation.
- Memory-driven maintenance and inspection in energy and infrastructure (Energy, Utilities)
- Description: Long-horizon inspections across distributed assets (substations, turbines) with episodic memory of anomalies and parts, enabling efficient revisits and deferred checks.
- Tools/Products/Workflows: Memory-indexed inspection journals; anomaly keyframe tagging; schedule-aware revisit planning.
- Assumptions/Dependencies: Outdoor robustness; variable lighting/weather; remote comms; policies for industrial video retention.
- Human-robot collaboration with shared episodic memory (Workplace productivity)
- Description: Shared memory buffers where humans can add/remove “important frames” and annotate context; robots adapt subtasks accordingly.
- Tools/Products/Workflows: Co-pilot UIs for memory editing; “explainable memory” snapshots; collaborative planning boards.
- Assumptions/Dependencies: Usable interfaces; live synchronization; training on human-edited memory states; safety guardrails.
- Memory-aware error recovery and self-correction (Robotics autonomy)
- Description: Robots use episodic memory to diagnose failure modes (e.g., missed grasp), plan retries, and avoid repeating error-inducing behaviors.
- Tools/Products/Workflows: Failure classifier hooked into keyframe store; temporal causal tracing; automatically generated “retry subtasks.”
- Assumptions/Dependencies: Rich logs; causal modeling; adaptive low-level controllers; high-frequency planning.
- Standard benchmarks and certification for long-horizon robot memory (Policy, Industry Consortia)
- Description: Sector-wide benchmarks defining task types, metrics (e.g., boundary accuracy), latency requirements, and safety/compliance criteria.
- Tools/Products/Workflows: Certification suites; reference tasks (search, counting, restore-state); audit-ready scoring pipelines.
- Assumptions/Dependencies: Multi-stakeholder agreement; testbed availability; reference datasets.
- Edge/on-device inference optimization for memory-heavy control (Software/Robotics)
- Description: Reduce latency and cost via token caching, quantization, and memory-aware scheduling to approach higher-frequency control rates.
- Tools/Products/Workflows: “Latency-aware scheduler” library; LLM/vLM caching; quantized vision encoders; on-device accelerators.
- Assumptions/Dependencies: Hardware accelerators; acceptable accuracy after quantization; robust scheduling under load.
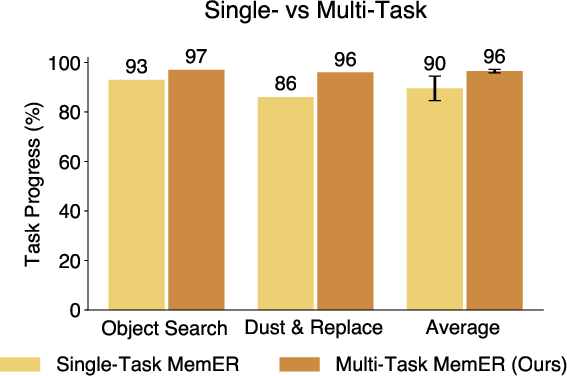
- Generalist multi-task training and transfer across domains (Academia, Industry)
- Description: Scale MemER to diverse tasks to improve cross-task object generalization and robustness (demonstrated benefits with multi-task high-level policy).
- Tools/Products/Workflows: Large, diverse long-horizon task libraries; automated subtask schema learning; continual learning pipelines.
- Assumptions/Dependencies: Data breadth; catastrophic forgetting mitigation (e.g., model merging, regularization); scalable annotation.
- Memory lifecycle management (insertion, aging, deletion, summarization)
- Description: Algorithms to add, remove, and summarize keyframes over very long durations, preventing unbounded memory growth and preserving relevance.
- Tools/Products/Workflows: “Forgetting policies” (time/usage-based); hierarchical clustering; semantic summarization snapshots; memory compaction routines.
- Assumptions/Dependencies: Task-aware relevance scoring; performance-privacy tradeoffs; safe deletion guarantees.
- Patient and elder-care assistance with episodic recall (Healthcare, Assistive Tech)
- Description: Assistive robots remember where items were last seen (glasses, medication box), track completed chores, and support daily routines.
- Tools/Products/Workflows: Home-safe memory stores; caregiver oversight interfaces; explainable recall prompts.
- Assumptions/Dependencies: Strong privacy controls; safe hardware; diverse home environments; fallback teleoperation.
- Regulatory guidance for memory-enabled robots in public spaces (Policy)
- Description: Governance frameworks for collection and retention of visual memory in retail/transport hubs; disclosure, consent, and redaction mandates.
- Tools/Products/Workflows: Policy blueprints; compliance audits; standardized notices; API-level controls for memory offloading.
- Assumptions/Dependencies: Clear statutory rules; stakeholder education; harmonization across jurisdictions.
Glossary
- Action chunk: A short sequence of low-level control commands executed by the robot before replanning. "outputs an action chunk of 15 actions sampled at 15Hz, and we execute 8 actions open-loop before replanning."
- Affordances: The actionable properties of objects or environments that suggest how they can be used by the robot. "reason about robot affordances for our long-horizon manipulation tasks"
- API-Based VLMs: Vision-LLMs accessed via web APIs, typically with higher latency than local models. "Other works directly prompt API-Based VLMs with video context to decide where the robot should navigate"
- Asynchronous: A deployment setup where different components run independently without strict synchronization to improve responsiveness. "we choose to run the policies asynchronously, as we find it to improve responsiveness and stability during deployment."
- Auxiliary losses: Additional training objectives used to shape model behavior beyond the primary task. "expand the observation context of their policy via auxiliary losses"
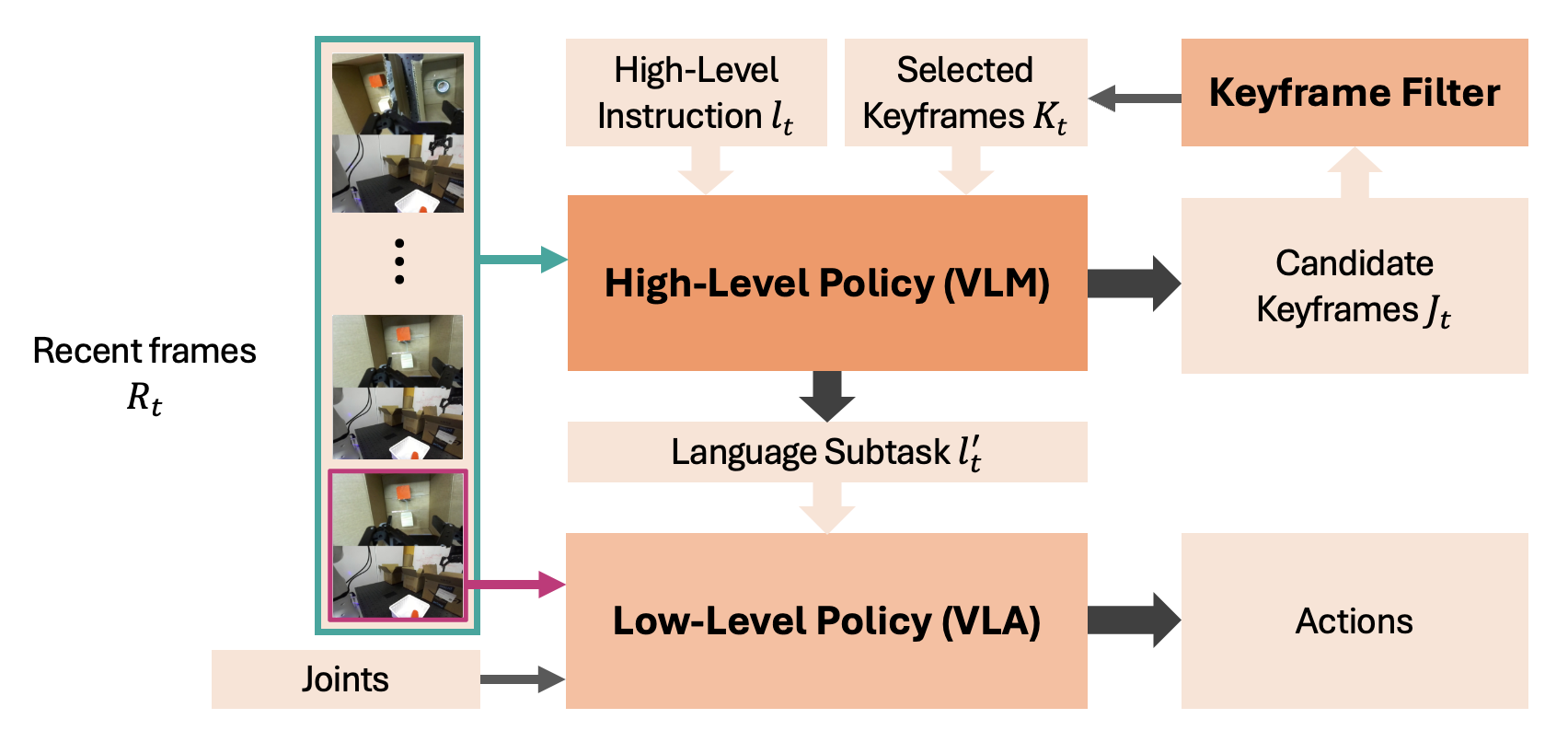
- Candidate keyframes: Recently observed frames nominated by the high-level policy as potentially worth remembering. "At each timestep, the high-level policy nominates candidate keyframe(s), as highlighted in orange."
- Closed-loop control: Control where actions are continuously updated based on current observations, enabling real-time corrections. "predict subtasks for the low-level policy during closed-loop control"
- Context window: The fixed number of recent frames provided to the high-level policy for decision making. "integer context-window shared across cameras"
- Covariate shift: A mismatch between the training and deployment state distributions that can degrade performance. "brittle under covariate shift"
- End-effector: The tool at the end of a robot arm (e.g., gripper) that interacts with objects. "2D visual traces of the motion of the end-effector and moving objects in the scene."
- End-to-end model: A single model that maps sensory input and task instructions directly to actions without intermediate modules. "single end-to-end model which takes images and a language task as input and outputs actions"
- Episodic memory: A compact representation of key events or frames from a task execution that the policy can recall. "converts per-timestep candidate keyframes into a compact, stable episodic memory"
- Foundation models: Large pretrained models that can be finetuned for downstream tasks. "finetuning pretrained foundation models for action prediction with native memory capabilities"
- Hierarchical policy: A control architecture that separates high-level planning (subtasks, memory) from low-level actuation. "Hierarchical Policies. In order to execute complex, long-horizon tasks, we follow \cite{hirobot} and hierarchically decompose the robot policy"
- Imitation policies: Policies trained to mimic expert demonstrations of behavior. "extend the context of imitation policies from a few frames to at most two dozen."
- Intervention demonstrations: Additional demonstrations that correct failure states to bolster robustness at deployment. "we supplement the low-level policy training set with 10–15 intervention demonstrations"
- Keyframe filter: The mechanism that consolidates nominated frames into a non-redundant memory set. "The candidate keyframe(s) are processed by the keyframe filter to obtain the selected keyframes for input during the next step of inference."
- Keyframe selection: The process of choosing representative frames from a stream to store for future reasoning. "to select keyframes from its fixed recent context"
- Markovian: A property where decisions depend only on the current state, not the full history. "Since the low-level policy is Markovian, we can efficiently collect the intervention data"
- Model merging: Linearly interpolating weights between a pretrained and finetuned model to balance robustness and specialization. "Merging the weights of our finetuned high-level policy with the pretrained Qwen2.5-VL-7B-Instruct weights helps or maintains performance with all tasks."
- Non-uniform frame sampling: Selecting frames at variable temporal intervals to emphasize important moments without extra models. "we achieve non-uniform sampling without additional models."
- Open-loop: Executing a preplanned action sequence without immediate feedback-based adjustment. "we execute 8 actions open-loop before replanning."
- Partial observability: When the robot cannot fully observe the state of the environment at each moment, necessitating memory. "Memory allows humans to handle the inherent partial observability found in their environment."
- Proprioceptive inputs: Internal robot sensor readings like joint angles and gripper state used for control. "proprioceptive inputs from the robot (i.e. joint angles and gripper state)"
- Single-linkage clustering: A clustering method that groups items based on minimum pairwise distance; used here on frame indices. "a simple 1D single-linkage clustering algorithm"
- Subsampling: Reducing the rate of frames included in processing to manage latency and compute. "indiscriminate subsampling of history leads to irrelevant or redundant information."
- Teleoperated: Human-controlled robot demonstrations used for training. "we find that we only need 50 teleoperated robot demonstrations"
- Trajectory accuracy: The fraction of timesteps where the predicted subtask matches the ground truth along an execution. "We measure trajectory accuracy, which is how often the correct subtask is predicted at each timestep"
- Vision-Language-Action (VLA) models: Models that integrate visual inputs, language instructions, and action outputs for robotics. "This design is compatible with existing vision-language-action (VLA) models"
- Vision-LLM (VLM): Models that jointly process visual and textual information; used as high-level planners. "open-source VLMs are finetuned on large amounts of video understanding data."
- Waypoints: Intermediate target positions or states that guide lower-level motion planning. "language subtask or waypoints"
Collections
Sign up for free to add this paper to one or more collections.