RoboSSM: Scalable In-context Imitation Learning via State-Space Models (2509.19658v1)
Abstract: In-context imitation learning (ICIL) enables robots to learn tasks from prompts consisting of just a handful of demonstrations. By eliminating the need for parameter updates at deployment time, this paradigm supports few-shot adaptation to novel tasks. However, recent ICIL methods rely on Transformers, which have computational limitations and tend to underperform when handling longer prompts than those seen during training. In this work, we introduce RoboSSM, a scalable recipe for in-context imitation learning based on state-space models (SSM). Specifically, RoboSSM replaces Transformers with Longhorn -- a state-of-the-art SSM that provides linear-time inference and strong extrapolation capabilities, making it well-suited for long-context prompts. We evaluate our approach on the LIBERO benchmark and compare it against strong Transformer-based ICIL baselines. Experiments show that RoboSSM extrapolates effectively to varying numbers of in-context demonstrations, yields high performance on unseen tasks, and remains robust in long-horizon scenarios. These results highlight the potential of SSMs as an efficient and scalable backbone for ICIL. Our code is available at https://github.com/youngjuY/RoboSSM.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots new tasks quickly by showing them just a few examples right before they act. The authors introduce RoboSSM, a method that helps robots copy what they see (“imitation learning”) using a special kind of model called a state-space model. Unlike many popular models called Transformers, RoboSSM can handle very long examples efficiently and keeps working well even when the robot is shown more or longer demonstrations than it saw during training.
Goals and Questions
The paper asks four simple questions:
- Can the robot still do well if we give it much longer prompts (more or slower demonstrations) than it saw during training?
- How many training demonstrations does it need to do well with long prompts?
- When the test prompts are the same length as in training, can it match or beat Transformer-based methods?
- Is this “in-context” approach better than training a single multi-task robot model that relies on text instructions?
How RoboSSM Works
Think of in-context imitation learning as “learning by example on the fly.” Instead of retraining the robot after you give it examples, you simply show a few demonstration videos, and the robot uses them right away to figure out what to do.
Here’s the approach in everyday terms:
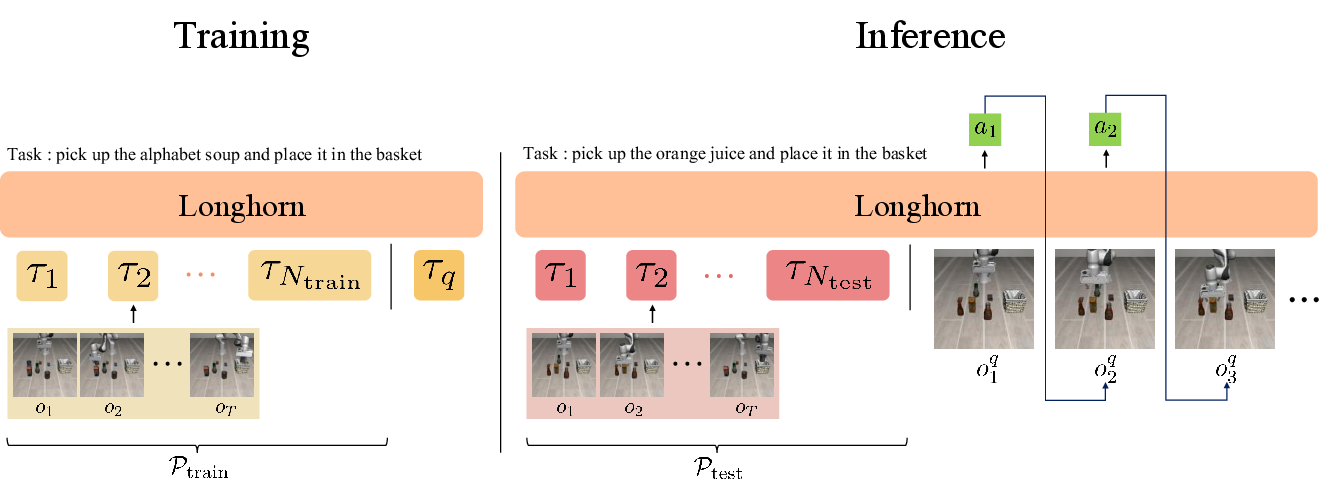
- Inputs: The robot gets camera images (what it sees) and its own body positions (like joint angles and gripper state). It does not get the actions from the demonstrations and does not use task text instructions, so it must truly learn from the visual examples.
- Prompt and query: The “prompt” is a handful of demonstration trajectories showing how to do a task. The “query” is the robot’s live attempt. The model watches the prompt, then predicts the next action step-by-step during the query.
- The model: RoboSSM replaces Transformers with a state-space model called Longhorn. You can think of Longhorn like a running summary notebook: at each step, it updates a compact memory of what it has seen so far. This makes it fast and steady even for long sequences.
- Why not Transformers? Transformers compare every part of the input with every other part, which gets slow and memory-heavy as inputs get longer. Longhorn updates its memory one step at a time, so the time grows more smoothly with input length.
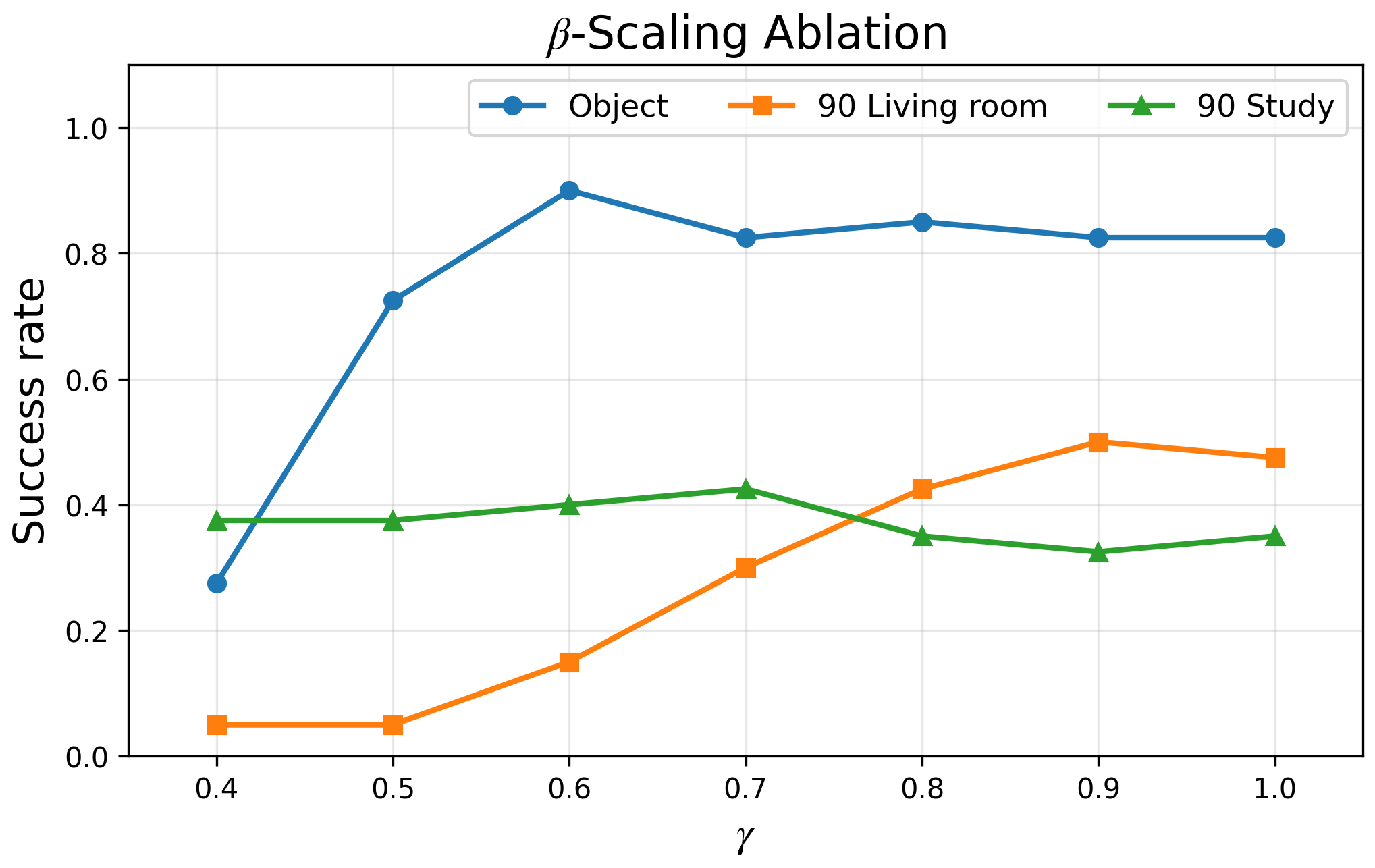
- A helpful “volume knob” (beta-scaling): The model has a setting that balances how much it trusts its past memory versus how much it reacts to new input. The authors adjust this knob at test time to help the robot focus more on the demonstrations.
Analogy:
- Transformer: A classroom where everyone tries to talk to everyone at once to compare notes. Works great for short discussions but gets chaotic and slow in long ones.
- Longhorn (state-space model): One student keeps a clean, updated summary as the discussion moves forward, so it stays efficient and clear even when the conversation gets long.
Main Findings and Why They Matter
The authors tested RoboSSM on LIBERO, a set of tough robot tasks, and compared it to a strong Transformer-based method called ICRT. They looked at several scenarios:
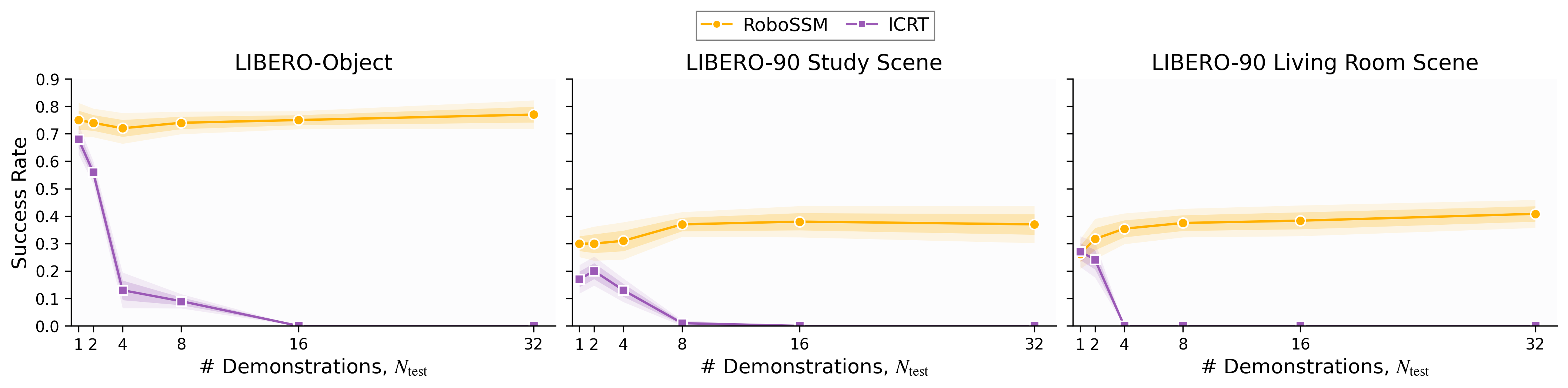
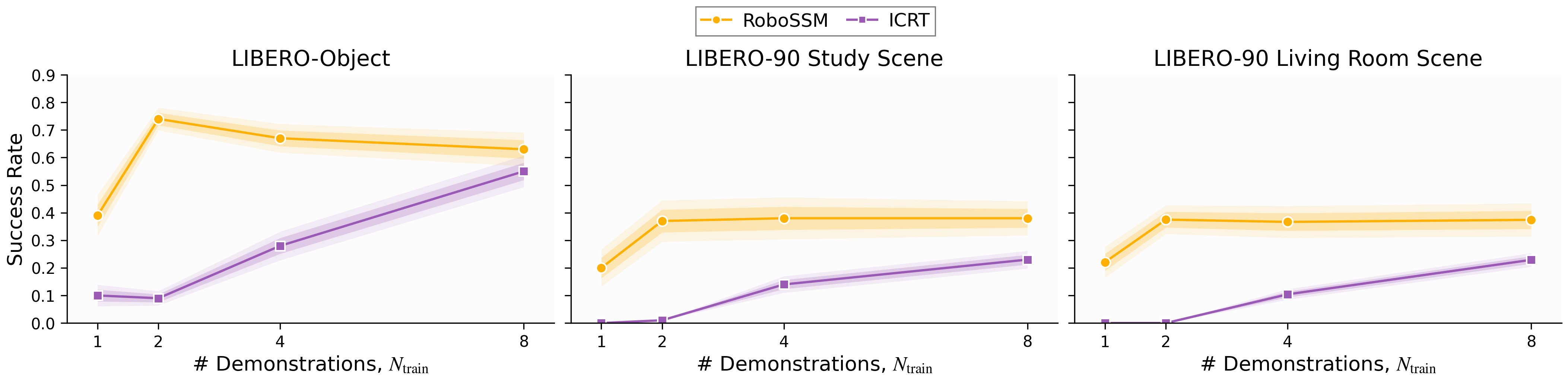
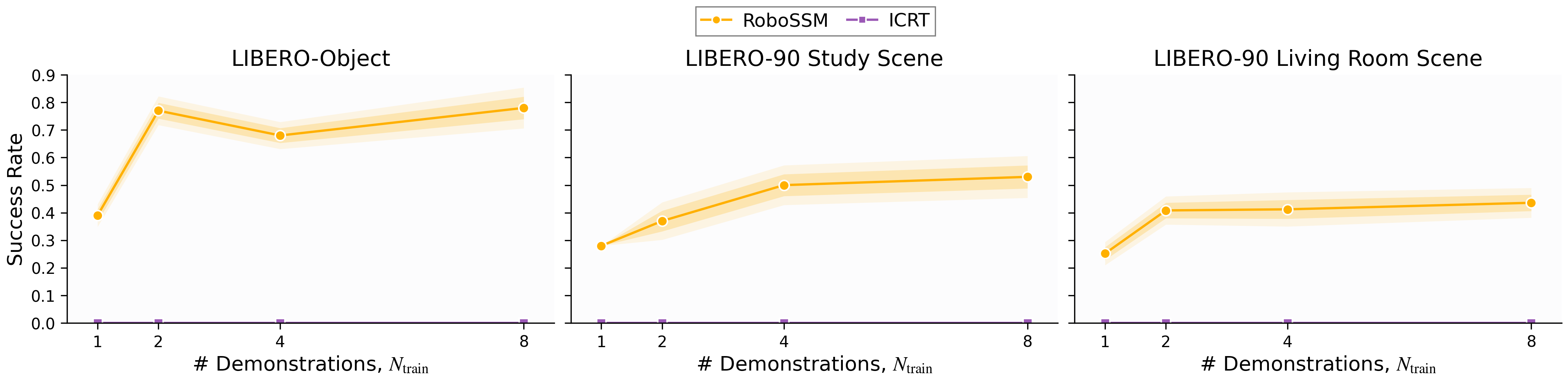
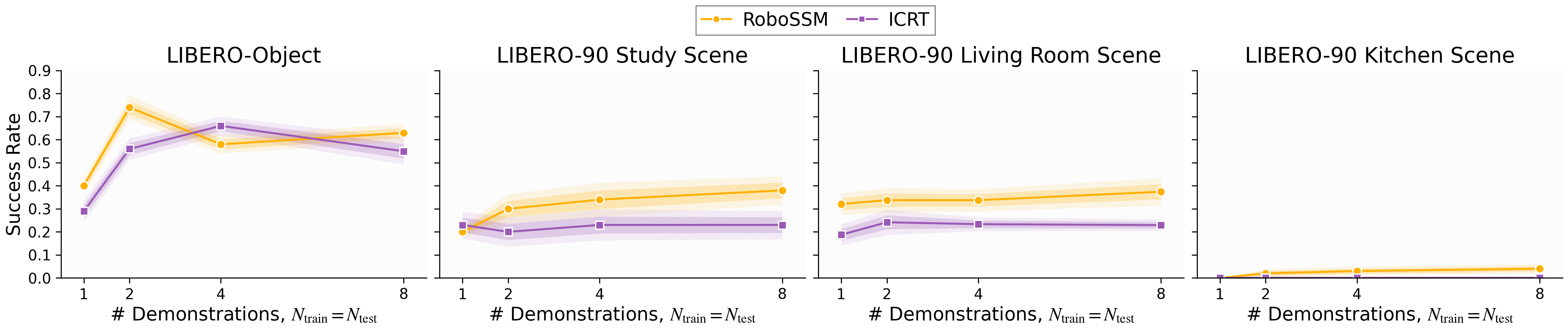
- Longer prompts with more demonstrations:
- RoboSSM stayed strong or even improved as they gave it more demonstrations at test time, including up to 32 demos (much more than it saw during training).
- ICRT got worse once the test prompt was longer than the training prompt and eventually failed on very long prompts.
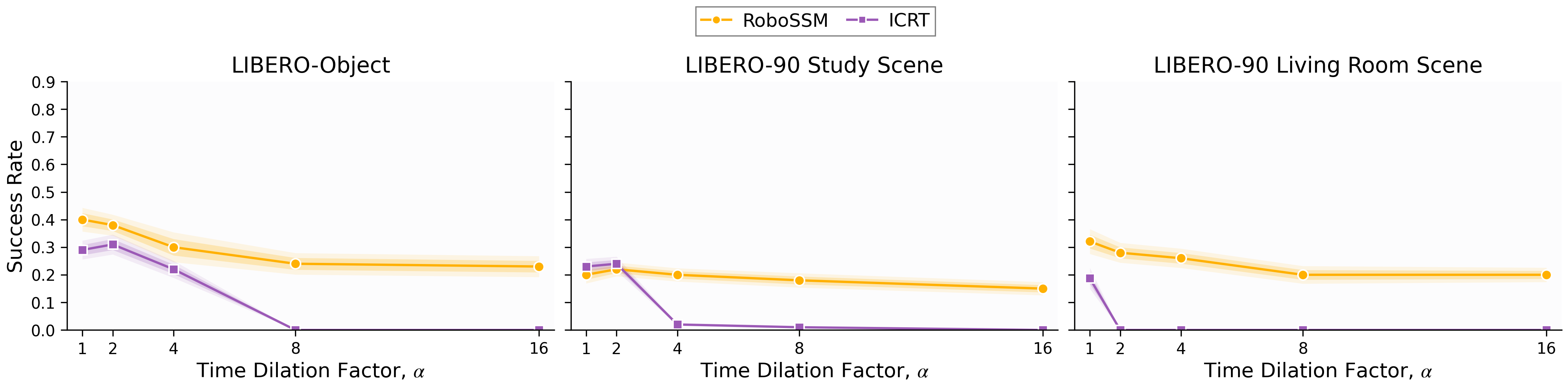
- Time-dilated demonstrations (simulating slower or longer videos):
- RoboSSM remained robust even when demonstrations were stretched to be up to 16 times longer.
- ICRT’s performance kept dropping as demonstrations got longer.
- Same-length prompts (fair, in-distribution comparison):
- RoboSSM was consistently as good or better than ICRT when test prompts matched training prompts.
- Compared to multi-task learning with text instructions:
- Both RoboSSM and ICRT (in-context methods) beat multi-task baselines that rely on language instructions to specify tasks.
- This shows that learning directly from examples right before acting can be more effective for new tasks than just reading task text and using a single trained policy.
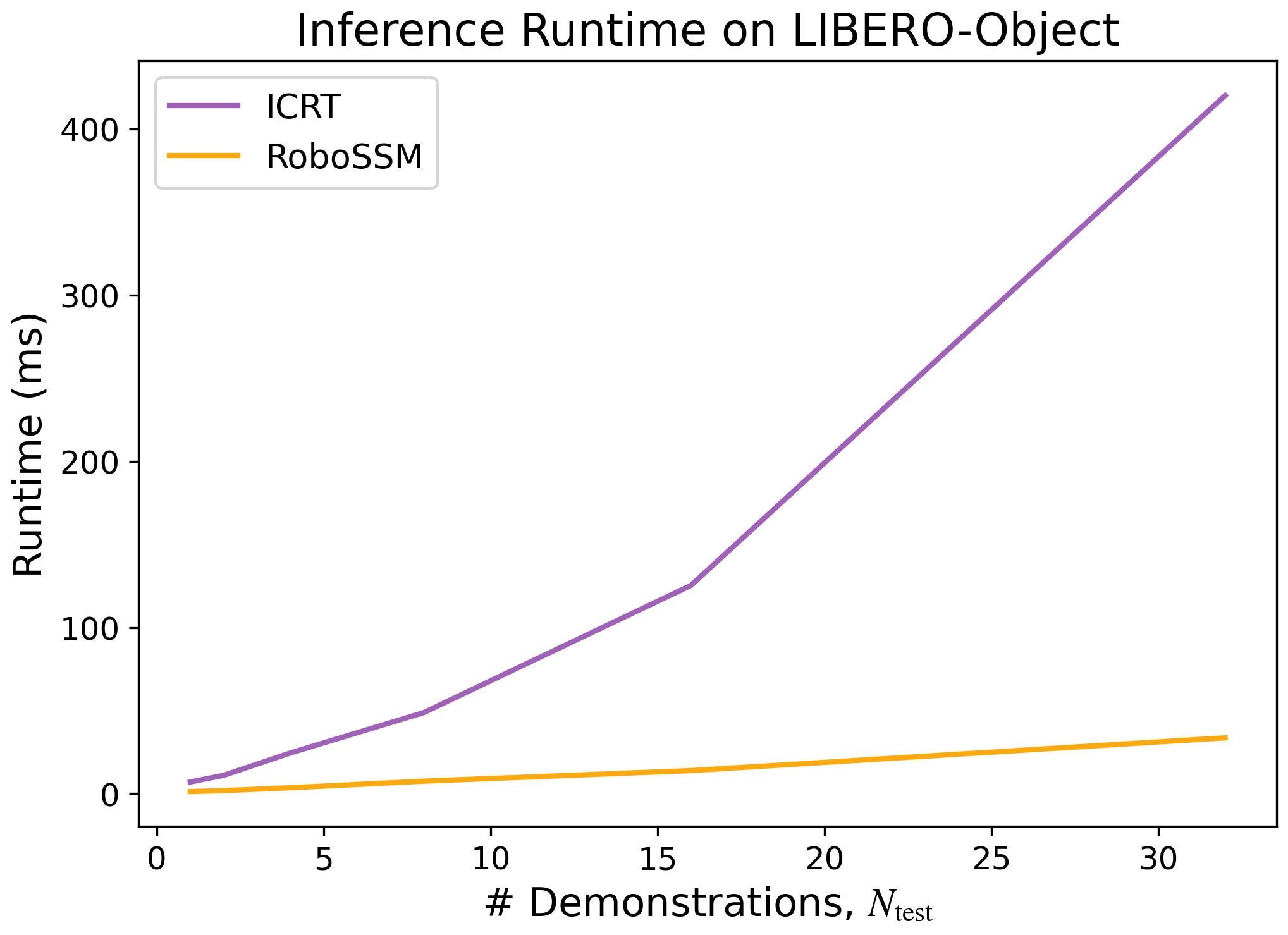
- Speed and efficiency:
- RoboSSM’s runtime grows roughly linearly with prompt length, staying efficient for long contexts.
- ICRT’s runtime grows much faster, making it less practical for longer prompts.
Why this matters:
- It shows that state-space models are a strong backbone for robots that need to learn from longer or more varied demonstrations without retraining.
- Robots can adapt quickly to new tasks just by watching examples, which is useful in homes, factories, or hospitals where tasks can change often.
Implications and Impact
RoboSSM points to a future where robots can:
- Adapt on the spot by watching a few examples, without needing time-consuming retraining.
- Handle long, detailed demonstrations more efficiently and reliably.
- Work better in real-world situations where demonstrations vary in speed and length.
The authors note limitations: they didn’t cover very complex, multi-step tasks that require combining many skills. To go further, they suggest collecting bigger and more diverse training data so robots can generalize to even more types of tasks. Overall, RoboSSM helps move robotics toward fast, flexible, and scalable learning from demonstrations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address to strengthen, generalize, and better understand RoboSSM and ICIL with state-space models.
- Real-world validation: The paper is conducted in simulation (LIBERO). How does RoboSSM perform on physical robots under sensor noise, actuation delays, contact-rich manipulation, and safety constraints? What are the sim-to-real gaps and required adaptations?
- Dataset breadth and diversity: Evaluation is limited to LIBERO-Object and subsets of LIBERO-90 (Study, Living Room, Kitchen), with only two held-out test tasks per suite. How does performance scale with more diverse, complex, and numerous tasks, including LIBERO-Long and LIBERO-Spatial, and beyond LIBERO?
- Kitchen suite failure analysis: Both models struggle in the Kitchen tasks (near-zero success). What specific visual, dynamics, or task-structure factors drive these failures, and which architectural or training changes (e.g., richer sensors, better pretraining, curriculum learning) mitigate them?
- Compositional and multi-stage tasks: Time dilation via frame repetition does not test multi-step dependencies or task compositionality. Can RoboSSM handle tasks that require long-range credit assignment, hierarchical reasoning, subgoal sequencing, and tool use?
- Prompt contamination and distractors: The paper assumes all prompt demonstrations match the query task. How robust is RoboSSM to mixed-task prompts, irrelevant/distractor demos, or mislabeled demonstrations? Can it detect and selectively attend to relevant demos?
- Prompt engineering and selection: The work uses randomly selected demonstrations. How do prompt order, diversity, quality, and retrieval strategies (e.g., nearest-neighbor in latent space) affect performance? Can learned prompt selection further improve success rates?
- Absence of actions in prompts: Actions are intentionally excluded from the prompt to avoid copying. What is the trade-off between preventing trivial imitation and losing informative action-state correlations? Ablate including actions (e.g., tokenized via LipVQ-VAE) or low-rate action summaries to assess their utility.
- Language-conditioned ICIL: Language did not improve performance in the current setup. How should language be integrated with SSM memory to aid disambiguation and compositional generalization (e.g., joint training with VLA models, language-to-state alignment, instruction-grounded retrieval)?
- Generalization across camera/view changes: Only RGB front and hand views are used, with modest augmentation. How robust is RoboSSM to viewpoint shifts, occlusions, lighting changes, and background clutter typical in real deployments?
- Sensor modality expansion: Performance with depth, point clouds, tactile/force sensing, audio, or eye-in-hand mobile camera streams is unexplored. How does Longhorn scale and fuse additional modalities for manipulation under partial observability?
- Scaling laws and capacity: The architecture uses 4 Longhorn blocks (d=512, m=16). What are the scaling laws with model size, key/query dimensionality m, number of blocks, and recurrent depth? Which hyperparameters most affect long-context extrapolation?
- Training for long-context robustness: The paper evaluates OOD prompt lengths but trains with fixed N_train. Would length curriculum, random time warping (beyond repetition), or mixed-length training further improve extrapolation and reduce dependence on β-scaling?
- β-scaling design: Test-time β is scaled by a global γ∈(0,1], chosen heuristically. Can γ be learned, scheduled (e.g., different γ for prompt vs query), or conditioned on prompt length L or task features? What principled methods calibrate β for stability and retention?
- Theoretical guarantees: There is no analysis of forgetting/stability bounds, memory half-life, or retrieval fidelity in Longhorn’s online optimization view. Can we derive conditions under which RoboSSM maintains relevant prompt information over very long horizons?
- Memory usage and deployment constraints: Runtime is analyzed, but memory footprint (state size, KV-equivalents), throughput on edge hardware (Jetson, CPU), and latency under real-time control constraints are not reported. What configurations meet embedded deployment requirements?
- Fair baselines for long contexts: The Transformer baseline (ICRT with LLaMA2-Base) is not augmented with long-context techniques (ALiBi, RoPE scaling, position interpolation, FlashAttention variants, memory layers) or hybrid recurrent-attention architectures. How does RoboSSM compare against state-of-the-art long-context Transformers and other SSMs (Mamba, S4/S5, H3) under matched training?
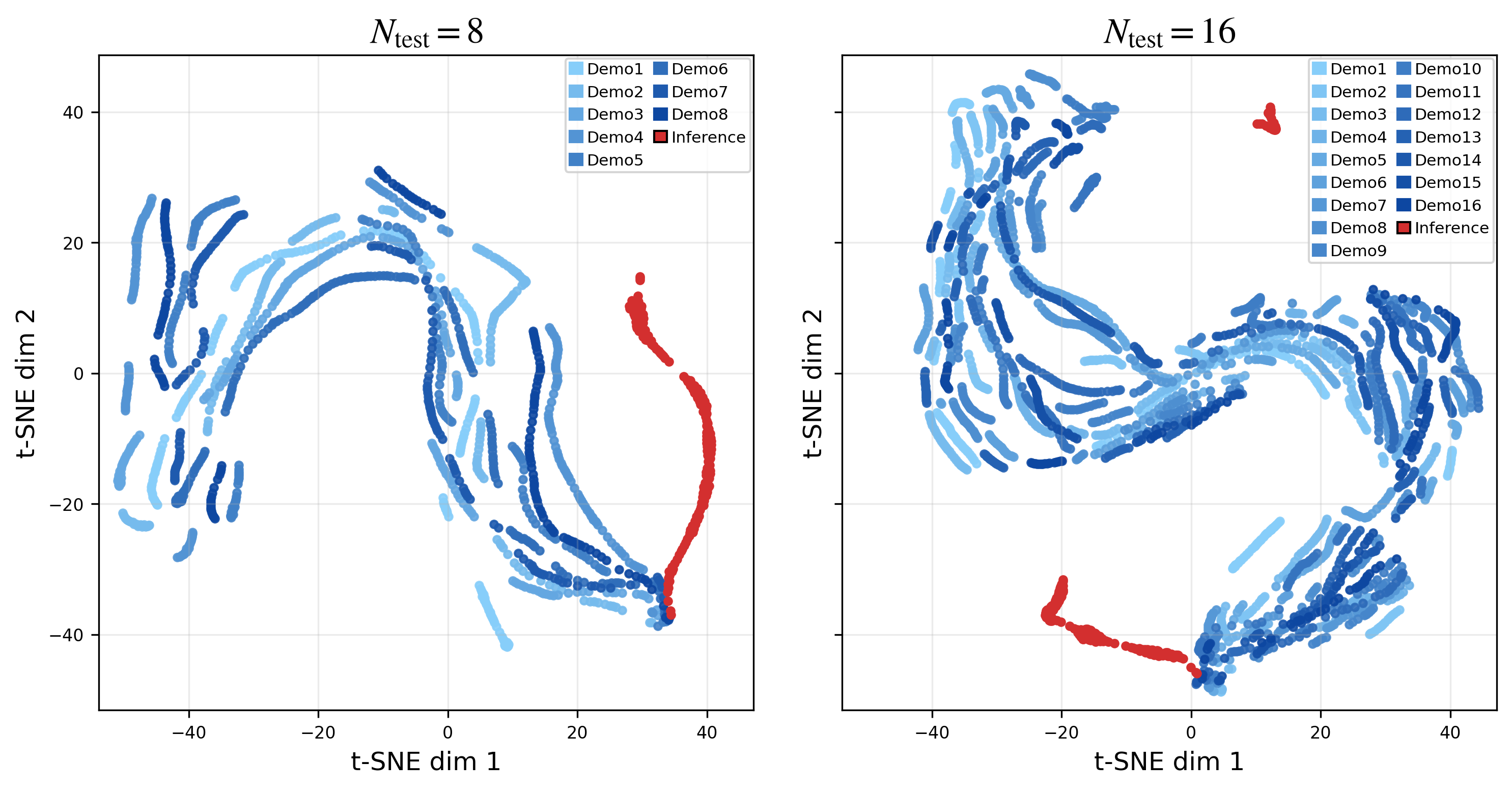
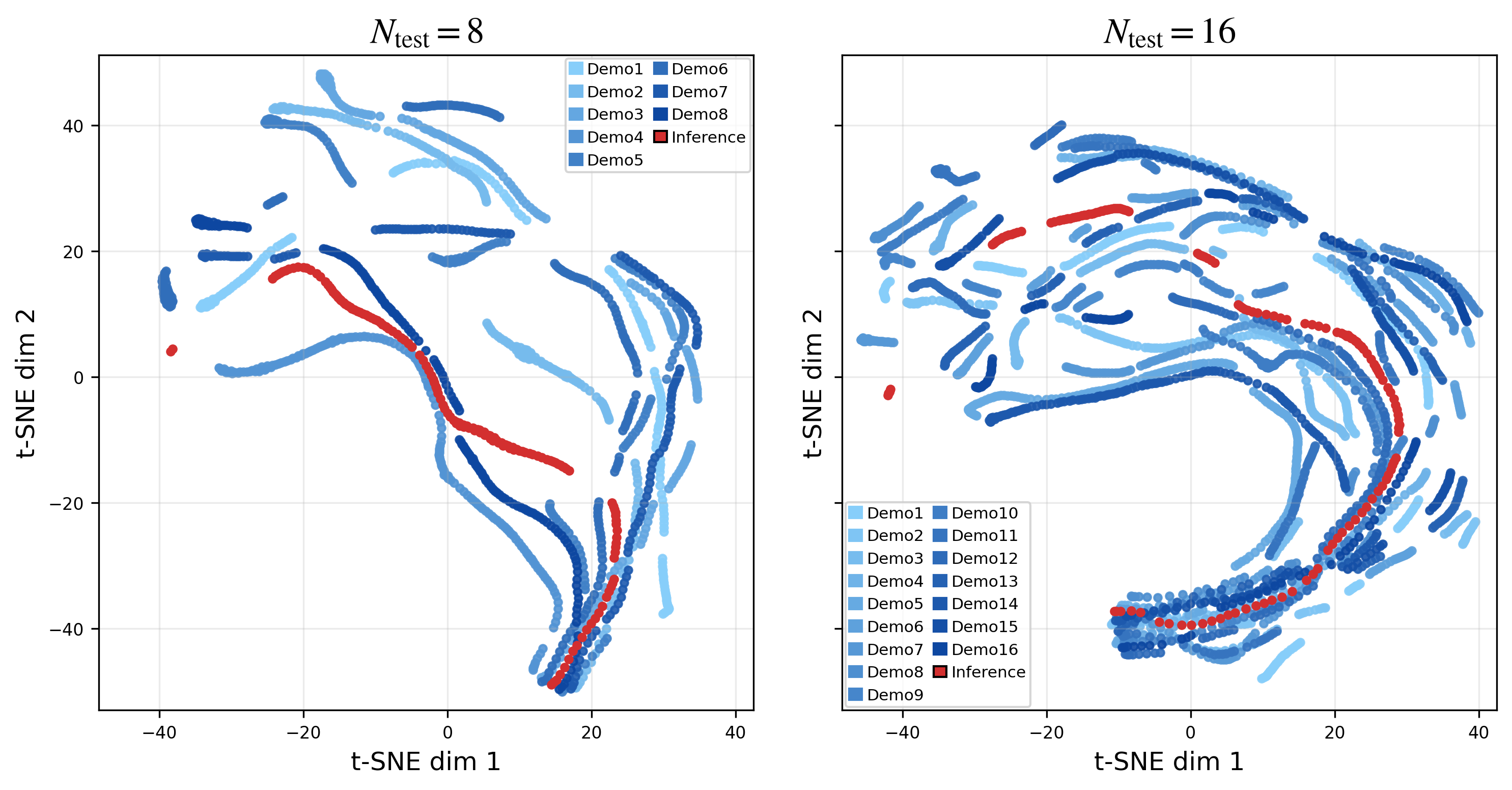
- Retrieval and attribution in memory: Latent t-SNE plots suggest RoboSSM stays near prompt manifolds, but quantitative measures of demo-to-query attribution, memory content relevance, and per-step contribution are missing. Can we audit which prompt segments influence actions and design interpretable readouts?
- Robustness to noisy demonstrations: Real teleoperation datasets contain errors and inconsistencies. How tolerant is RoboSSM to noisy, partial, or truncated demonstrations? Does denoising, confidence weighting, or robust training (e.g., bootstrapping) help?
- Action-space design and smoothness: Actions are produced by an MLP head; no analysis of control smoothness, rate limits, or stability under closed-loop drift is provided. Does action tokenization, diffusion policies, or control-aware regularization improve reliability?
- Task ambiguity without language: With actions excluded and language often disabled, disambiguation relies solely on visual trajectories. How does RoboSSM behave when visually similar scenes correspond to different goals? Evaluate explicit ambiguity cases and measure failure modes.
- Data efficiency and demonstration budgets: While prompt length extrapolation is shown, the impact of total training data (number of tasks, demos per task) on generalization is not characterized. What are the minimum data requirements for strong ICIL with SSMs?
- Continual and lifelong learning: RoboSSM is positioned for continual adaptation via prompts, but retention across sessions, task interference, and catastrophic forgetting across long deployments are not studied. Can prompts be persisted, compressed, or indexed to support lifelong operation?
- Upper limits of prompt length: Test prompts go up to N_test=32 and dilation up to 16×. What are the empirical and practical limits (e.g., 64, 128+) where performance or memory degrades, and how does Longhorn’s state capacity constrain these limits?
- Query initialization and rollout stability: The query starts from o0 and runs up to 200 steps. How does initial state uncertainty, horizon length, compounding error, and recovery behavior affect success? Evaluate longer horizons and perturbation robustness.
- Cross-embodiment and multi-robot generalization: ICIL claims broad adaptability, but performance across different robot platforms, kinematics, and action spaces is untested. Can RoboSSM generalize via demonstration prompts across embodiments (e.g., from Franka to UR5)?
- Integration with retrieval-augmented policies: Real systems will need to select a few demos from large corpora. How does retrieval quality and index design interact with Longhorn’s state memory? Benchmark end-to-end pipelines with retrieval plus ICIL.
- Safety and constraint handling: No analysis of safe action generation, constraint satisfaction (e.g., collision avoidance), or recovery strategies is provided. How can ICIL policies incorporate safety filters or constraint-aware planning within SSM frameworks?
- Evaluation rigor: Success rates are averaged over 6 seeds, but no statistical significance tests, confidence intervals across tasks, or per-task breakdowns are provided. More granular reporting could identify structured failure modes and guide targeted improvements.
Practical Applications
Immediate Applications
Below are actionable use cases that can be piloted now using the paper’s findings (RoboSSM with Longhorn SSM), given code availability and demonstrated performance on long prompts with linear-time inference.
- Industrial robotics: rapid task changeover for low-volume/high-mix manufacturing
- Use case: Operators show 2–8 short demos to adapt pick-and-place, kitting, simple assembly, or machine-tending when SKUs change, without retraining downtime.
- Sectors: Manufacturing, Logistics.
- Tools/workflows: “Demo-to-Policy” station (capture demos; auto-build prompt; run policy); ROS2/MoveIt plugin wrapping RoboSSM; retrieval of most similar demos per SKU.
- Dependencies/assumptions: Controlled environments, calibrated cameras, reliable grasping primitives; high-quality demonstrations; safety interlocks and human-in-the-loop supervision.
- Warehouse/bin-picking adaptation to new items
- Use case: Few-shot prompting to handle new packaging shapes, restocking patterns, or tote sorting; robustness to operator speed variability via time-dilation tolerance.
- Sectors: Logistics, Retail.
- Tools/workflows: SKU-conditioned demo libraries; “Prompt Packs” attached to item metadata in WMS; beta-scaling knob exposed as an “Adaptation vs Stability” slider for operators.
- Dependencies/assumptions: Consistent lighting and perception; item pose estimation/grasp proposal stack; fallback to teleop for edge cases.
- Laboratory automation: few-shot protocol adjustments
- Use case: Adjust pipetting, plate handling, or instrument loading by showing small demo sets instead of reprogramming.
- Sectors: Healthcare (labs), Biotech, Pharma.
- Tools/workflows: LIMS-integrated demo capture; versioned “protocol prompts”; runtime guardrails (volume checks, deck maps).
- Dependencies/assumptions: Precise end-effector control and calibration; compliance and audit logging; contamination and safety protocols.
- Service and hospitality robots: task personalization
- Use case: Staff demonstrate placing/arranging objects on trays, basic tidying, or table reset sequences that vary by venue.
- Sectors: Hospitality, Facilities.
- Tools/workflows: On-device inference using linear-time SSM; quick demo capture on shift change; demo retrieval by location/task tag.
- Dependencies/assumptions: Low-risk interactions; simple manipulators; clear visual context; human oversight.
- Human-in-the-loop bootstrapping and drift correction
- Use case: Start with few-shot demos; monitor rollout; add 1–2 quick demos to “nudge” behavior without retraining if task conditions shift.
- Sectors: Cross-sector.
- Tools/workflows: Real-time beta-scaling γ control exposed in UI; “Add-to-Prompt” telemetry button; confidence-based autopause and teleop handover.
- Dependencies/assumptions: Good UX for operators; confidence estimation and anomaly detection; latency constraints for safe handover.
- Edge inference for resource-constrained robots
- Use case: Deploy in-context policies on embedded GPUs with long prompts (up to 16× training length) while maintaining responsiveness.
- Sectors: Mobile manipulation, Field robotics.
- Tools/workflows: Optimized Longhorn SSM runtime; mixed-precision inference; prompt-length stress testing during commissioning.
- Dependencies/assumptions: Availability of CUDA-capable edge hardware or NPU; thermal and power management; real-time OS integration.
- Academic benchmarking and method development
- Use case: Replace Transformer baselines with RoboSSM in ICIL studies to test long-context extrapolation, time-dilation robustness, and runtime scaling.
- Sectors: Academia, Open-source.
- Tools/workflows: LIBERO-based evaluation harness; latent trajectory visualization; ablation of β-scaling for ICIL.
- Dependencies/assumptions: Reproducible datasets; fair model-size parity; standardized metrics across suites.
- DataOps for demonstration management
- Use case: Curate, version, and retrieve heterogeneous demos; maintain “Prompt Packs” per task/SKU/site with quality checks.
- Sectors: Software, Robotics Integration.
- Tools/workflows: Demo version control, metadata tagging, similarity search; policy that excludes actions/language at input (as per paper) to enforce true in-context learning.
- Dependencies/assumptions: Storage and governance for demo data; privacy controls; consistent observation encoders.
- Safety and acceptance testing for adaptive robots
- Use case: Add prompt-length and time-dilation stress tests to acceptance criteria, ensuring policies remain stable as contexts grow.
- Sectors: QA, Compliance.
- Tools/workflows: “Long-Context Stability” test suite; failure-mode cataloging; safe defaults for γ (β-scaling) in critical environments.
- Dependencies/assumptions: Well-defined pass/fail thresholds; sandbox environments; traceability of runs.
Long-Term Applications
These use cases are plausible extensions that will benefit from further research, real-world validation, larger/diverse datasets, integration with broader autonomy stacks, and safety certification.
- Generalist home assistants taught by short demos
- Use case: Residents demonstrate new chores (loading dishwashers, organizing shelves, tidying) with robust adaptation to varied execution speeds and long horizons.
- Sectors: Consumer robotics.
- Potential products: “Promptable Home Robot” platform; household “Task Prompt Library.”
- Dependencies/assumptions: Robust perception in unstructured environments; safety with humans/pets; multi-surface grasping; regulatory acceptance.
- Hospital service robotics with evolving workflows
- Use case: Rapidly adapt non-critical logistics tasks (room turnover, supply runs, device fetch/placement) to new wards and equipment.
- Sectors: Healthcare operations.
- Potential products: Hospital “PromptOps” system integrated with EHR/LIS; policy sandbox for audit.
- Dependencies/assumptions: Stringent safety/compliance; infection control; authenticated demo authors; facility mapping.
- Field and energy utilities: on-site adaptation by technicians
- Use case: Field robots learn new valve/handle geometries, sampling routines, or inspection maneuvers from a few technician demonstrations.
- Sectors: Energy, Utilities, Infrastructure.
- Potential products: Ruggedized mobile manipulator with on-site demo capture; offline prompt rehearsal with digital twins.
- Dependencies/assumptions: Harsh conditions (weather, lighting); robust hardware; reliable comms; digital twin fidelity.
- Agricultural manipulation across seasons and cultivars
- Use case: Few-shot adaptation for harvesting, pruning, trellising, and packing as plant morphology changes.
- Sectors: Agriculture, Food processing.
- Potential products: “Seasonal Prompt Packs”; farm management system integration.
- Dependencies/assumptions: Vision under occlusions; gentle, variable-force manipulation; crop damage minimization.
- Cross-embodiment and cross-site transfer via in-context prompts
- Use case: Share demo prompts across different robot arms/grippers and facilities, with on-site few-shot “localization.”
- Sectors: Robotics integration, Platforms.
- Potential products: Prompt marketplaces; embodiment adapters; auto-calibration pipelines.
- Dependencies/assumptions: Kinematics/actuation differences; standardized observation/action spaces; safety certification per embodiment.
- Lifelong learning via persistent prompt memory and retrieval
- Use case: Build a continually growing demonstration memory that improves with use; retrieve and compose relevant sub-tasks at runtime.
- Sectors: Software, AI platforms.
- Potential products: “Demonstration Memory” service; retrieval-augmented ICIL; composition of long-horizon tasks.
- Dependencies/assumptions: Catastrophic forgetting mitigation; scalable retrieval; governance for demo provenance and quality.
- Multimodal prompting that composes language, video, and demonstrations
- Use case: Combine natural language with a handful of demos to specify constraints, safety zones, or preferences.
- Sectors: Enterprise automation, Education.
- Potential products: Multimodal Prompt Studio (text + short clips + teleop traces).
- Dependencies/assumptions: Robust grounding from language to action; clarity around conflicting modalities; UI for non-experts.
- Safety-validated adaptive autonomy frameworks and standards
- Use case: Certification pathways and policies for “promptable” robots that change behavior without code or parameter updates.
- Sectors: Policy, Standards bodies, Insurance.
- Potential products: Standard test protocols for long-context extrapolation; demo authorship/approval workflows; audit trails of prompts used.
- Dependencies/assumptions: Consensus on risk categorization; logging/traceability; incident reporting norms.
- Cloud-edge “PromptOps” and fleet learning
- Use case: Centralized demo management and distribution; site-specific adaptation with edge inference; optional cloud simulation for prompt rehearsal.
- Sectors: Platform providers, MSPs.
- Potential products: Fleet-wide prompt rollout/canarying; A/B testing of prompt variants; automatic prompt pruning and refresh.
- Dependencies/assumptions: Secure connectivity; latency budgets; data residency/privacy compliance.
- Education and workforce upskilling
- Use case: Teach non-programmers to “program by demonstration,” creating a broader technician workforce for robotics deployment.
- Sectors: Education, Workforce development.
- Potential products: Curricula and simulators focused on ICIL/SSMs; certification for demo authoring best practices.
- Dependencies/assumptions: Accessible hardware; reproducible training materials; partnerships with vocational programs.
Notes on global assumptions across applications:
- The paper’s results are from the LIBERO simulation/manipulation benchmarks; sim-to-real transfer, multi-sensor robustness, and safety-critical deployment need additional validation.
- Performance depends on the availability of clean, task-relevant demonstrations; observation encoders (RGB + proprioception) must be well-calibrated.
- Excluding actions and language at input (as in the paper) enforces reliance on in-context demonstrations; some deployments may prefer adding language—this will require further paper of trade-offs.
- β-scaling (γ) is a practical control to balance stability vs. adaptation; safe defaults and operator training are essential.
- Linear-time inference is an engineering advantage, but embedded deployment still requires optimization, thermal headroom, and real-time integration.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update to improve generalization in deep learning. "we use the AdamW~\cite{adamw_loshchilov} optimizer"
- Action tokenizer: A module that discretizes continuous robot actions into a sequence of tokens. "LipVQ-VAE is an action tokenizer that uses vector quantization"
- Behavior cloning: A supervised learning approach that learns a policy by imitating expert demonstrations. "Standard behavior cloning approaches~\cite{bc_bain,bc_torabi}"
- β-Scaling: Test-time scaling of the β weighting to control how much new inputs influence the recurrent state in Longhorn. "via -scaling ablations"
- Causal Transformer: A Transformer architecture with autoregressive masking used for next-step prediction. "ICRT~\cite{icrt_fu} performs in-context learning using a causal Transformer that predicts actions with next-token prediction"
- Cosine decay schedule: A learning-rate schedule that decays following a cosine curve over training. "The learning rate follows a cosine decay schedule"
- Dilation factor: The multiplicative factor by which a trajectory is temporally stretched by repeating frames. " is the dilation factor."
- Element-wise product: The Hadamard product; multiplication applied component-wise to matrices or vectors. "where denotes the element-wise product"
- Few-shot adaptation: The ability of a model to adapt to new tasks using only a few demonstrations without parameter updates. "this paradigm supports few-shot adaptation to novel tasks."
- Few-shot learning: Learning from a small number of examples, often via prompting rather than weight updates. "in adapting to unseen language tasks through few-shot learning"
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries. "where is the Frobenius norm"
- H3: A structured state-space model (SSM) architecture designed for efficient sequence modeling. "S4~\cite{s4_gu}, H3~\cite{h3_fu}, S5~\cite{s5_smith}, Mamba~\cite{mamba_gu}, and Longhorn~\cite{longhorn_liu} have introduced structured state transition matrices"
- ICRT: A Transformer-based in-context imitation learning method using next-token prediction. "ICRT~\cite{icrt_fu} performs in-context learning using a causal Transformer"
- In-context imitation learning (ICIL): Learning to perform a task by conditioning on demonstration prompts without fine-tuning. "In-context imitation learning (ICIL) enables robots to learn tasks from prompts consisting of just a handful of demonstrations."
- In-context learning: A paradigm where a model infers tasks from context examples provided at inference time. "Inspired by the in-context learning paradigm in LLMs"
- Keypoint Action Tokens: A method that tokenizes observations and actions for ICIL using a language-model backbone. "Keypoint Action Tokens~\cite{kat_palo} introduce an ICIL framework that converts the visual observations and actions into tokens"
- KV cache: A stored cache of key/value tensors that accelerates autoregressive decoding in Transformers. "with a LLaMA-2 backbone and a KV cache"
- LIBERO benchmark: A suite of simulated robot manipulation tasks used to evaluate visuomotor policies. "We evaluate our approach on the LIBERO benchmark"
- Linear recurrence: A recurrence relation where the next state is a linear function of the previous state and input. "update the hidden state via a linear recurrence:"
- Linear-time inference: Inference whose runtime grows linearly with input length. "provides linear-time inference"
- LLaMA2-Base: A Transformer LLM used here as a backbone for ICIL baselines. "employs LLaMA2-Base~\cite{llama2_touvron} as its backbone"
- Long-horizon: Referring to tasks or sequences that span many time steps or actions. "remains robust in long-horizon scenarios."
- Longhorn: A state-of-the-art SSM with linear-time inference and strong long-context extrapolation. "Longhorn -- a state-of-the-art SSM that provides linear-time inference and strong extrapolation capabilities"
- Mamba: A selective state-space model architecture enabling efficient sequence modeling. "S4, H3, S5, Mamba, and Longhorn have introduced structured state transition matrices"
- Multi-task learning (MTL): Training a single model jointly across multiple tasks. "We then compare RoboSSM against a multi-task learning (MTL) policy"
- Next-token prediction: The objective of predicting the next element in a sequence given the previous context. "predicts actions with next-token prediction"
- Online convex programming: Solving a sequence of convex optimization problems in an online manner as new data arrive. "the solution to the following online convex programming objective"
- Online regression view: Interpreting the recurrent state update as the solution to an online regression problem. "In this online regression view, the use of ... enables efficient in-context learning with long contexts."
- Outer product: A product of two vectors producing a matrix whose entries are pairwise products. "where denotes the outer product"
- Prefill: The initial pass over the prompt to populate the KV cache before autoregressive decoding. "incurs prefill over the prompt"
- Proprioception: Internal sensing of a robot’s own joint and gripper states. "the robot’s joint angles and gripper state for proprioception."
- S4: A structured state-space sequence model designed for efficient long-context processing. "S4~\cite{s4_gu}, H3~\cite{h3_fu}, S5~\cite{s5_smith}, Mamba~\cite{mamba_gu}, and Longhorn~\cite{longhorn_liu} have introduced structured state transition matrices"
- S5: An improved SSM architecture building on S4 for enhanced efficiency and modeling power. "S4~\cite{s4_gu}, H3~\cite{h3_fu}, S5~\cite{s5_smith}, Mamba~\cite{mamba_gu}, and Longhorn~\cite{longhorn_liu}"
- State-space models (SSMs): Sequence models defined by latent state updates driven by inputs, enabling linear-time inference for long contexts. "State-space models (SSMs) have emerged as a promising alternative to Transformers for sequence modeling"
- Teleoperated demonstrations: Demonstrations collected by a human operator controlling the robot. "a sequence of encoded teleoperated demonstrations"
- t-SNE: A dimensionality-reduction technique for visualizing high-dimensional data. "two-dimensional t-SNE"
- Time dilation: Evaluation setting where demonstrations are temporally stretched to longer lengths. "Time dilation"
- Vector quantization: Mapping continuous vectors to the nearest codebook entries to obtain discrete tokens. "uses vector quantization"
Collections
Sign up for free to add this paper to one or more collections.

