- The paper introduces a novel camera conditioning method via per-pixel ray embeddings that significantly improves viewpoint generalization in imitation learning.
- Benchmarks across RoboSuite and ManiSkill using ACT, Diffusion Policy, and SmolVLA show substantial success rate improvements under varied camera setups.
- The study demonstrates enhanced data efficiency and robust integration with existing RGB policies while mitigating reliance on static background cues.
View-Invariant Policy Learning with Camera Conditioning
Introduction
This paper addresses the challenge of viewpoint invariance in imitation learning for robotic manipulation, focusing on RGB-only policies. The authors propose explicit conditioning of policies on camera extrinsics using per-pixel ray embeddings, demonstrating that this approach significantly improves generalization across camera viewpoints for standard behavior cloning architectures such as ACT, Diffusion Policy, and SmolVLA. The work introduces six manipulation benchmarks in RoboSuite and ManiSkill, designed to decouple background cues from camera pose, and provides a comprehensive empirical analysis of the factors influencing viewpoint robustness.
Camera Conditioning via Per-Pixel Ray Embeddings
The core methodological contribution is the use of Plücker ray-maps to encode camera geometry. For each pixel, a six-dimensional vector (d,m) is computed, where d is the world-frame unit direction and m=p×d is the moment vector, with p as the camera center. This representation is homogeneous and satisfies d⊤m=0, capturing oriented 3D lines in a continuous form. The ray direction for pixel (u,v) is computed as:
dw=∥R⊤K−1u~∥R⊤K−1u~,u~=[u,v,1]⊤
and the camera center as C=−R⊤t, yielding the ray r=(dw,C×dw). This mapping is independent of scene content and provides a direct geometric link between image pixels and the robot's action frame.
Two integration strategies are proposed:
- Channel-wise Concatenation: For policies without pretrained encoders (e.g., Diffusion Policy), the ray-map is concatenated with the image, and the encoder input layer is modified to accept 9 channels.
- Latent Fusion: For policies with pretrained encoders (e.g., ACT, SmolVLA), a small CNN encodes the ray-map to match the image latent dimension, followed by channel-wise concatenation in the latent space.
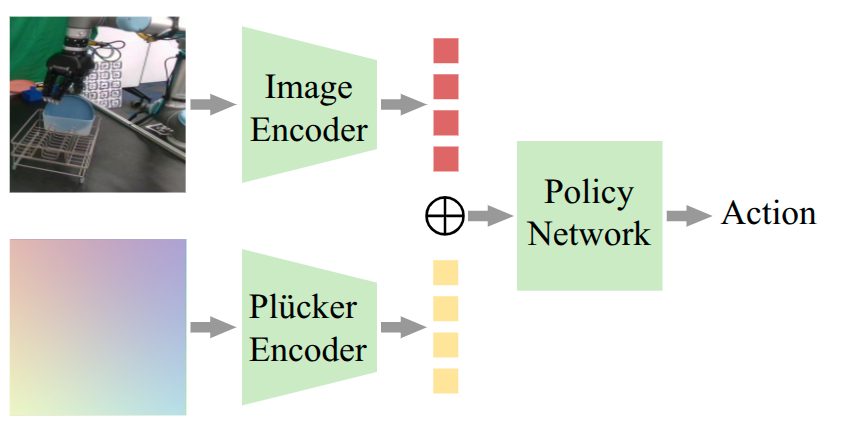
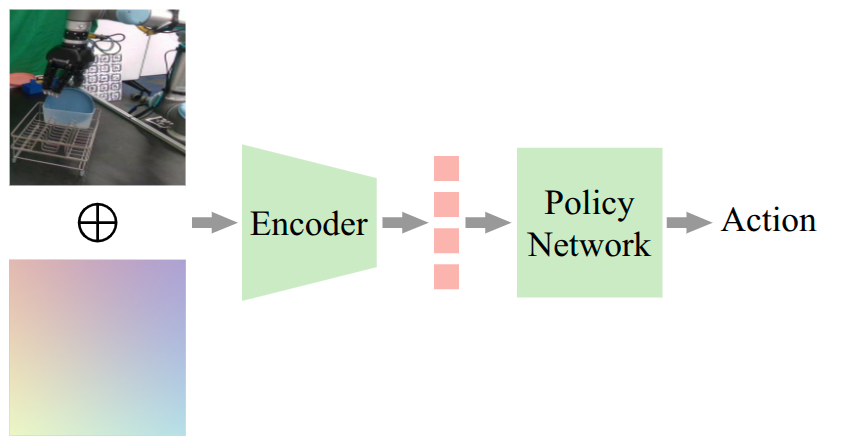
Figure 1: Two architectures for ray-map encoding: channel-wise concatenation for non-pretrained encoders and latent fusion for pretrained encoders.
Benchmark Tasks and Data Collection
Six custom manipulation tasks are introduced, three in RoboSuite and three in ManiSkill, each with fixed and randomized scene variants. The randomized setting involves varying the robot's position and orientation relative to the table and floor, as well as camera azimuth and elevation, to prevent policies from exploiting static background cues for implicit camera pose inference.












Figure 2: Six custom tasks in RoboSuite and ManiSkill, illustrating fixed and randomized setups and environment variations.
Data collection follows a "stair"-shaped compositional strategy, where each demonstration is recorded with n cameras, and episodes share n−m camera poses, promoting efficient generalization across initial states and camera configurations.

Figure 3: Visualization of camera poses in the real-robot experiment, with training cameras in green and test cameras in red.
Empirical Analysis
Success Rate Improvements
Explicit camera conditioning yields substantial improvements in success rates across all evaluated models and tasks. For example, ACT's success rate on the Lift task increases from 33.6% to 60.6% with conditioning, and similar gains are observed for Diffusion Policy and SmolVLA.
Robustness to Background Randomization
Policies without camera conditioning perform significantly worse in randomized environments, where static cues are unavailable. Conditioning on camera extrinsics restores performance, demonstrating that explicit geometric information is critical for viewpoint generalization.
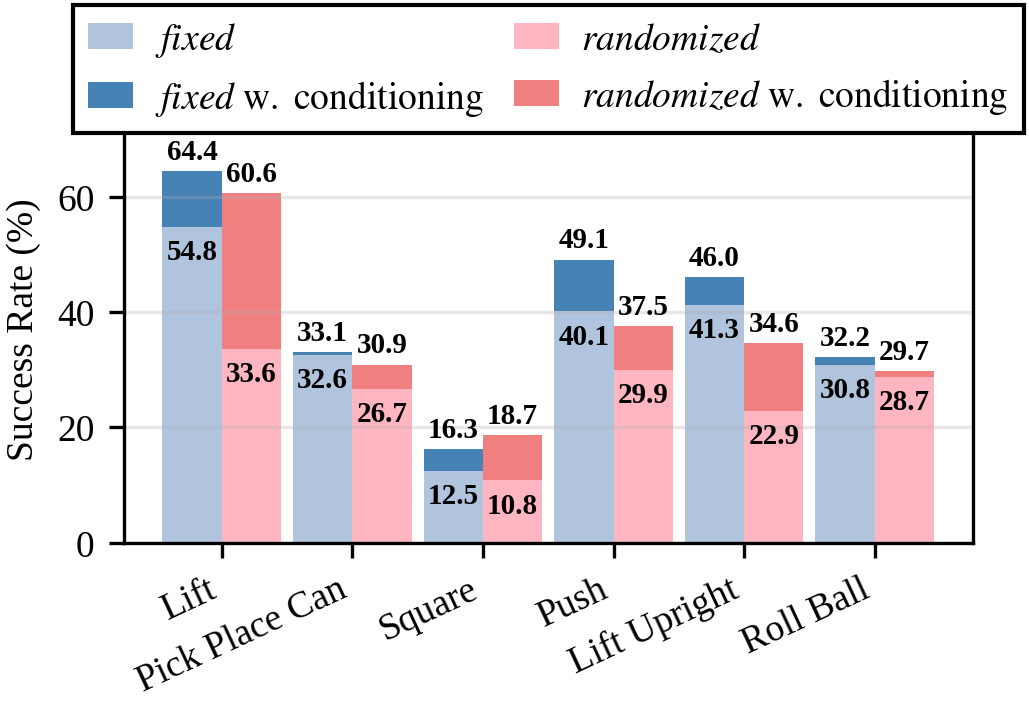
Figure 4: Success rates for fixed and randomized settings, with and without camera pose conditioning.
Action Space and Data Augmentation
Delta end-effector pose actions yield the highest performance, but camera conditioning improves success rates across all action spaces. Random cropping of images and ray-maps further enhances robustness, effectively simulating additional virtual camera viewpoints.
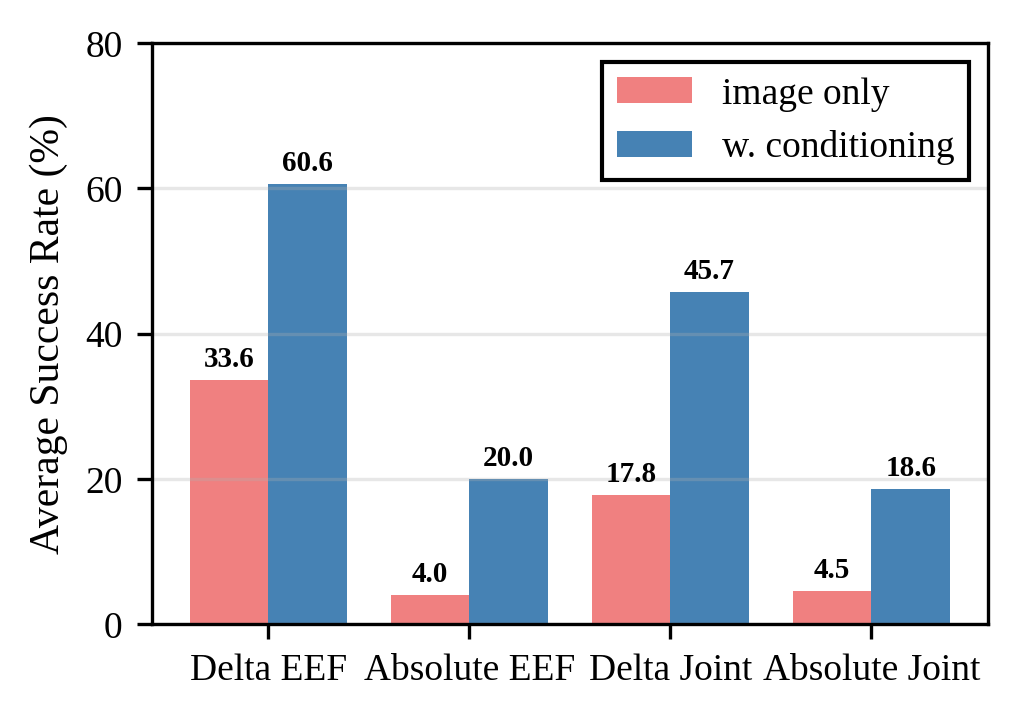
Figure 5: Success rates for different action spaces.
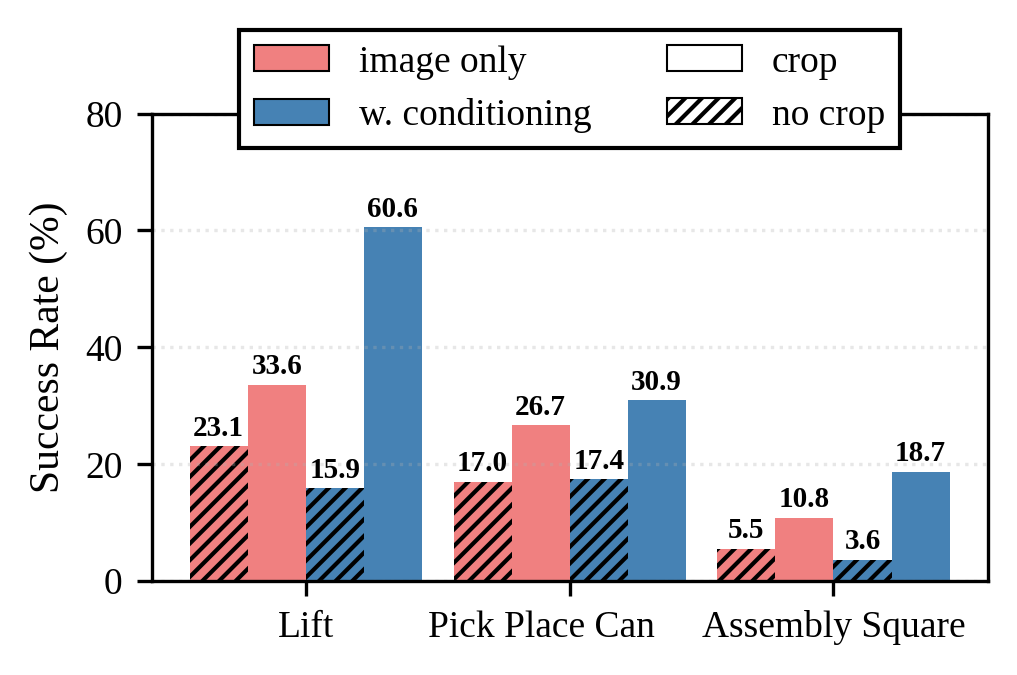
Figure 6: Ablation of random cropping's effect on task success.
Camera Pose Encoding Methods
Late fusion of ray-map and image latents outperforms early fusion and linear projection methods, especially when using pretrained encoders. Early fusion can introduce out-of-distribution inputs for pretrained networks, reducing effectiveness.
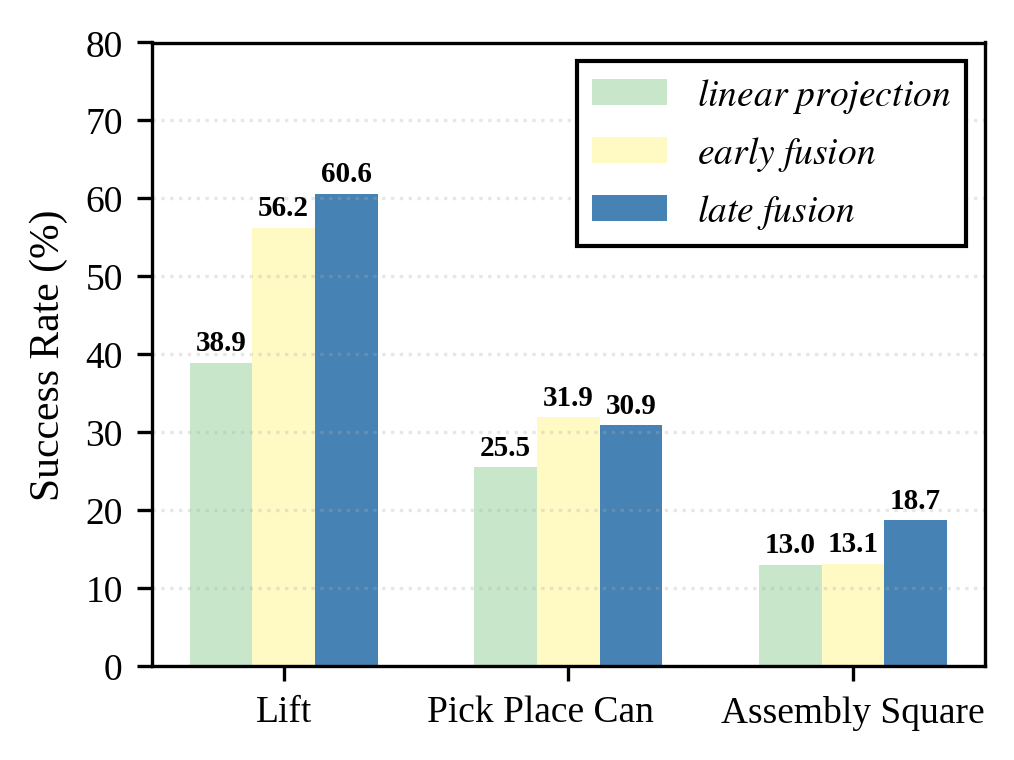
Figure 7: Ablation of different camera pose encoding methods.
Pretrained Vision Encoders
Pretraining the image encoder (ImageNet, R3M) has minimal impact on success rates in the context of camera conditioning, suggesting that geometric information is more critical than representation learning for viewpoint invariance.
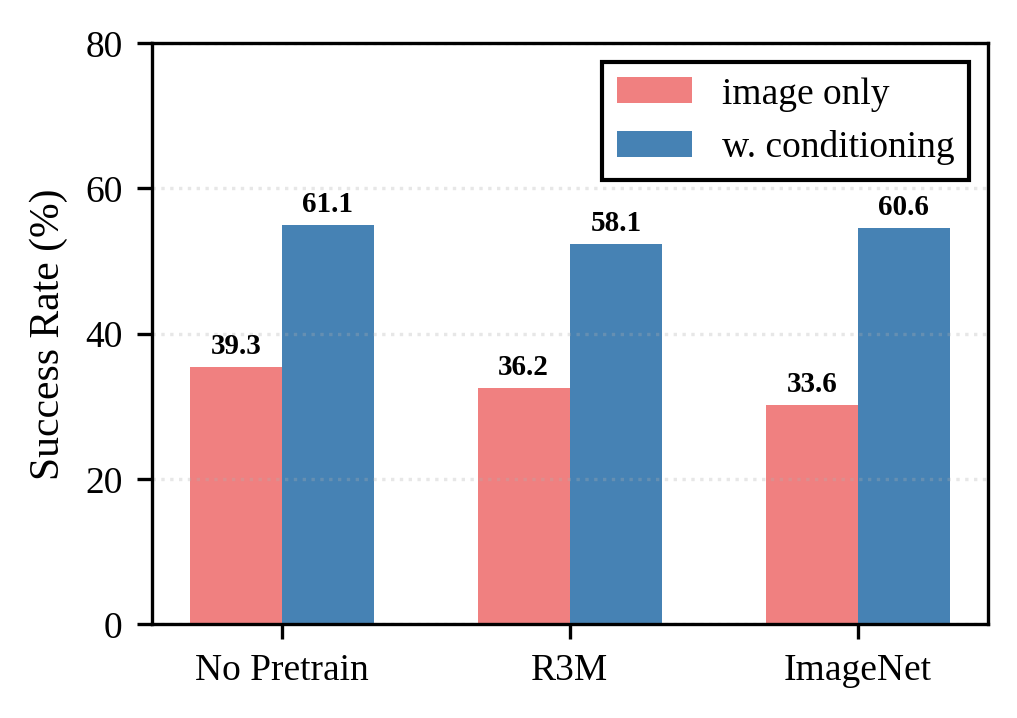
Figure 8: Ablation on pretraining of image encoders.
Scaling to More Camera Poses
Conditioning on camera pose enables policies to achieve high performance with fewer camera views during training. Without conditioning, many more cameras are required to reach comparable robustness.
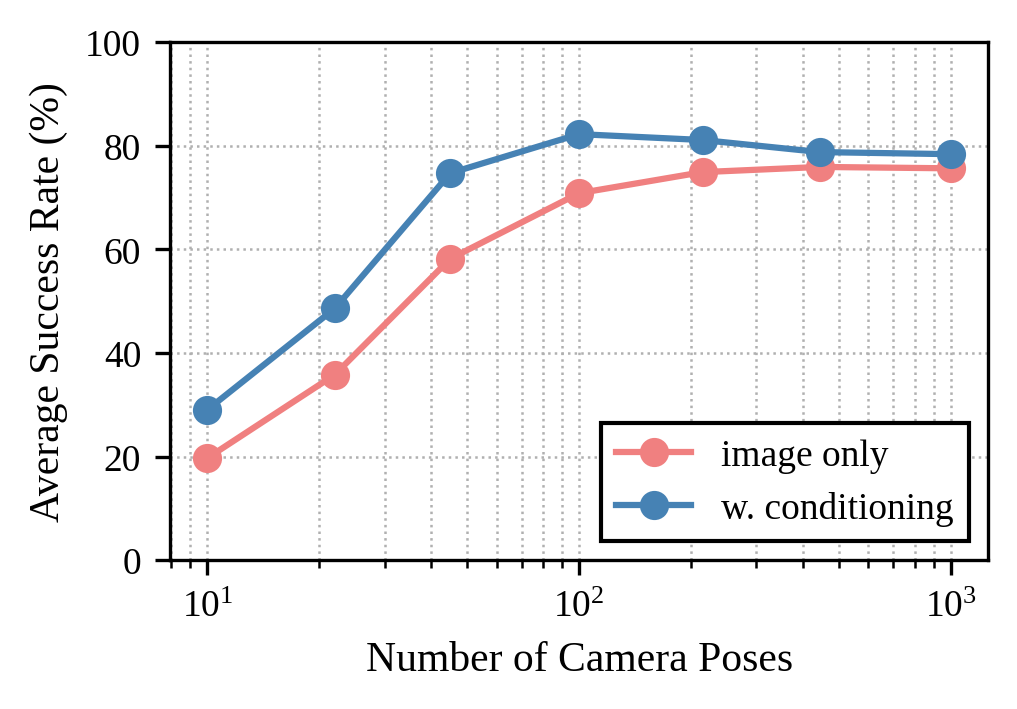
Figure 9: Scaling experiment showing improved data efficiency with camera pose conditioning.
Real-World Experiments
Experiments on a UR5 robot with three manipulation tasks (Pick Place, Plate Insertion, Hang Mug) confirm the simulation findings. Conditioning on camera pose consistently improves both full and half-success rates across all tasks and models.


Figure 10: Real-robot tasks with varied initial states.
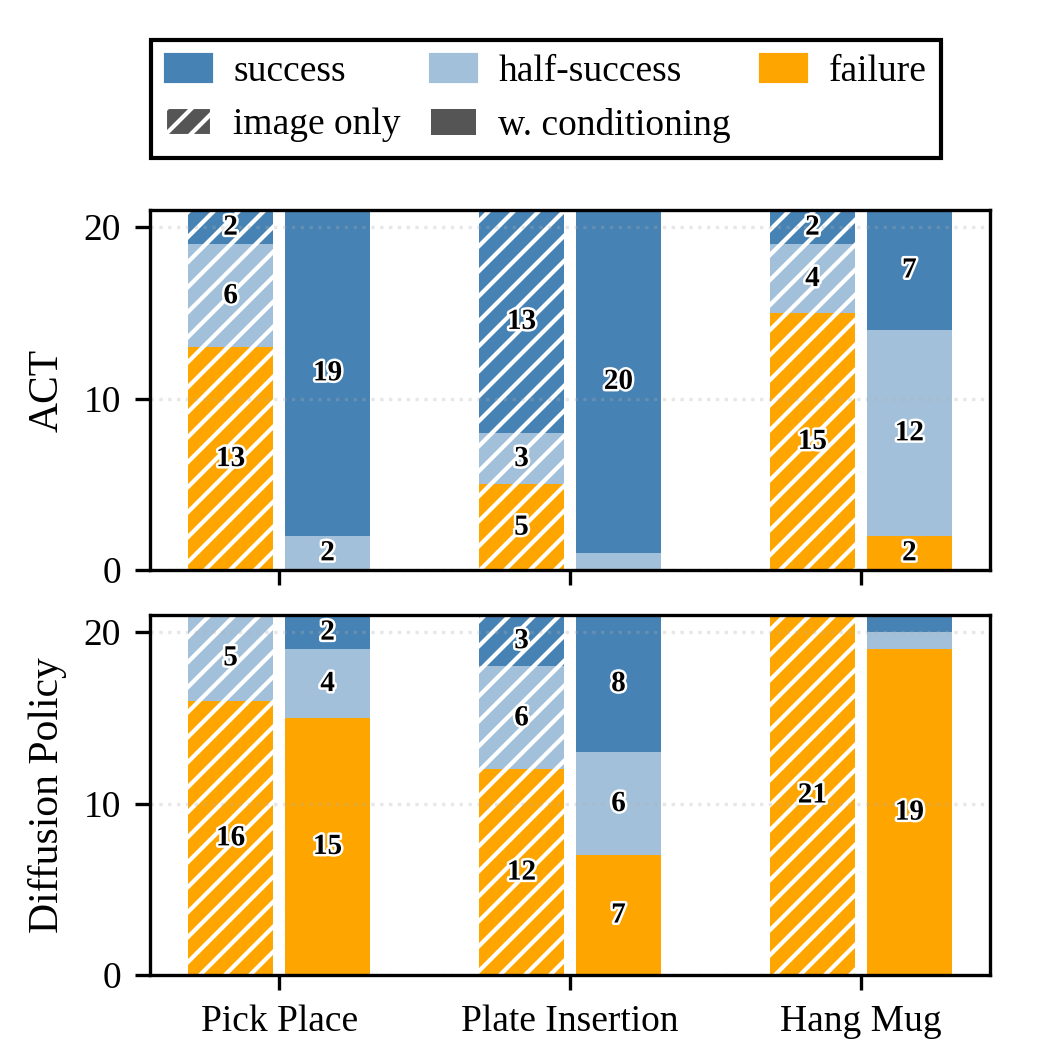
Figure 11: Performance of ACT and Diffusion Policy with and without camera pose conditioning in real-world experiments.
Implementation Considerations
- Computational Overhead: The ray-map encoding introduces minimal additional computation, as the per-pixel mapping is fixed and can be precomputed.
- Pose Estimation: Accurate camera extrinsics are required; errors in pose estimation can propagate to policy performance, especially in dynamic or featureless environments.
- Integration with Existing Pipelines: The conditioning mechanism is compatible with standard behavior cloning architectures and can be retrofitted to existing RGB-only policies.
- Data Efficiency: Camera conditioning reduces the need for extensive viewpoint randomization during data collection, improving sample efficiency.
Implications and Future Directions
The results demonstrate that explicit camera conditioning is a principled and effective approach for achieving viewpoint invariance in RGB-only robot policies. This decouples the challenge of pose inference from policy learning, enabling more robust deployment in real-world settings with variable camera configurations. The introduced benchmarks provide a standardized evaluation protocol for future research.
Potential future directions include:
- Extending conditioning to support generalization across cameras with varying intrinsics.
- Investigating robustness to pose estimation errors and developing mitigation strategies.
- Integrating camera conditioning with multimodal (e.g., depth, language) policy architectures.
- Exploring end-to-end learning of camera pose estimation and policy control in unified frameworks.
Conclusion
This work establishes explicit camera pose conditioning via per-pixel ray embeddings as a critical component for robust, view-invariant imitation learning in robotic manipulation. The empirical analysis across diverse tasks and architectures demonstrates consistent improvements in generalization and data efficiency. The proposed benchmarks and conditioning strategies provide a foundation for future research on viewpoint-robust robot policies and highlight the importance of leveraging geometric information in policy learning.