- The paper presents a novel PITA dataset of 23M propositional logic statements to evaluate reasoning trace (RT) versus direct prediction (DP) models.
- It demonstrates that RT models outperform DP models on shallow, breadth-intensive tasks while struggling with deeper, narrow task configurations.
- The study employs transitive inference tasks and theoretical analysis, revealing uniform attention distribution as a key factor in model generalization.
Boule or Baguette? A Study on Task Topology, Length Generalization, and the Benefit of Reasoning Traces
The paper "Boule or Baguette? A Study on Task Topology, Length Generalization, and the Benefit of Reasoning Traces" (2602.14404) presents a nuanced analysis of reasoning trace models (RTs) in artificial intelligence, addressing their ability to handle various task topologies and their generalization capabilities over different reasoning lengths. A novel dataset, PITA, is introduced consisting of 23 million statements in propositional logic, designed to probe the models' length generalization across task depths and breadths.
PITA Dataset Overview
PITA is a large-scale propositional inference task aimed at understanding RT models relative to direct prediction (DP) models. Each statement in PITA is formalized using Lean, and the dataset includes proofs that demonstrate each statement's truth or falsity.
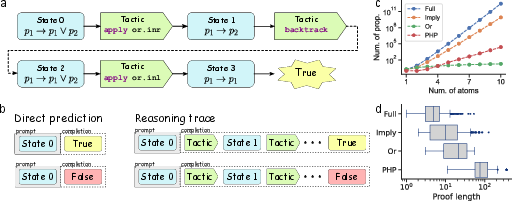
Figure 1: The PITA dataset. (a) Statements and proofs are expressed in Lean. Tactics are Lean commands that transform sets of propositions. A proof is an alternating sequence of tactics and proof states, which terminates in a special token indicating whether the statement is true or false. (b) Inputs are formatted as prompt-completion pairs, where losses are computed only on completion tokens. The DP model's completion consists only of the special classification token. The RT model's completion includes the whole proof. (c) Breadth of each split, plotted as the total number of unique examples that can be enumerated for a particular statement size (where size is the number of atoms in that statement). (d) Depth of each split, plotted as the number of unique proof states. Boxplots are constructed from 500 samples from each split and illustrate the median and quartiles. Outliers are determined from 1.5 times the inter-quartile range.
The PITA dataset is divided into several splits that vary by depth and breadth. Depth measures the complexity of proofs, while breadth refers to the diversity of statements. This configuration enables the analysis of how RT models generalize across different task structures.
Experimental Results
The paper presents findings showing RT models generally outperform DP models on breadth-dominated splits, proving effective in shallow and wide task configurations. However, RT models suffer on deep and narrow configurations, a setting where DP models exhibit superior performance.
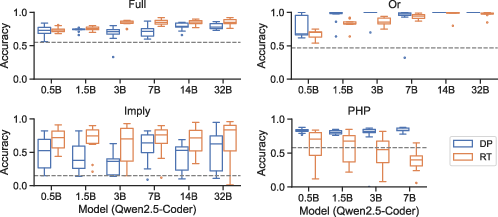
Figure 2: Generalization accuracy on PITA splits. Models are trained up to median proof length of their respective splits, then evaluated on longer examples. The dashed line marks chance level performance, where chance is calculated as the test accuracy attained through random guessing with probability equal to the proportion of true/false examples in the training distribution. Because true/false proportion may vary widely between train and test distributions, chance level is sometimes substantially below 50 percent, as in Imply. RT models typically outperform DP models on breadth-dominated splits (Full and Imply), while the reverse is true for depth-dominated splits (Or and PHP). Due to the computational constraints, the largest trainable model is 7B for PHP and 32B for all others. Boxplots are constructed from 10 runs, where each model is evaluated on 100 test samples. Box lines illustrate the median and quartiles. Outliers are determined from 1.5 times the inter-quartile range.
This reversal in generalization performance is attributed to differences in how RT and DP models handle long reasoning traces, with RT models exhibiting weaknesses when faced with tasks requiring extended contextual understanding.
Transitive Inference Explanation
The paper utilizes the transitive inference (TI) task as a simplified model to support the analysis of RT models. TI involves reasoning with syllogisms, a foundational component of propositional logic, and provides a tractable way to understand reasoning generalization.
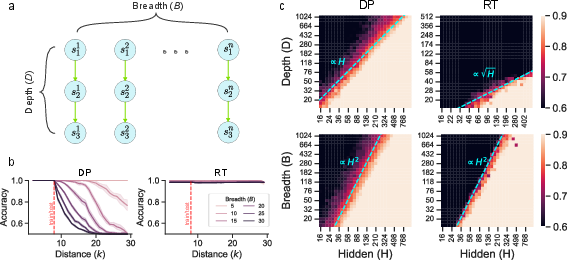
Figure 3: Transitive inference task. (a) Illustration of the TI task. Symbols are arranged in a series of parallel branches, each consisting of a line of inferences. Breadth is parameterized by the number of branches B, while depth is parameterized by the number of symbols in a branch D. (b) Generalization accuracy for fixed depth D = 30 and varying breadth. The red dashed line indicates the max training length. Generalization accuracy for the DP model decays quickly with breadth, while remaining consistently high for the RT model. Shaded error regions correspond to 95 percent confidence intervals estimated from six seeds. (c) Heatmaps of training accuracy for varying depth, breadth, and model size for the full model described in Section {app:details}.
Through analytical discussion of TI, the paper identifies how RT models generalize well in breadth-oriented tasks but are limited by the depth due to their propensity for extended reasoning traces.
Theoretical Insights
The analysis suggests that RT models possess a beneficial inductive bias that enhances generalization on broad tasks, while DP models tend to overfit under breadth increase, leading to generalization decay. These results are supported by theoretical perspectives from margin-based solutions in neural networks.
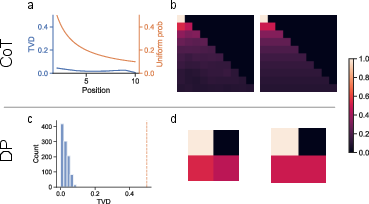
Figure 4: Attention weights are uniform. We show empirically that the attention weights become uniform in a Transformer trained on our transitive inference task. (a) In blue, total variation distance (TVD) between a uniform distribution and the attention weights in an RT model, measured across 1000 examples. The x-axis indicates the position of the query token. In orange, the probability assigned to each position by a uniform distribution, plotted for comparison. The TVD is very close to zero across all positions, indicating that the attention weights are close to uniform. (b) Left, an example attention matrix from the RT model. Right, attention matrix with uniform entries, plotted for comparison. (c) Histogram of TVD between a uniform distribution and attention weights in a DP model at position 2 (the output position for a DP model), measured across 1000 examples. In orange, the probability assigned to position 2 by a uniform distribution (which is 0.5). As in (a), the TVD is fairly close to 0. (d) The same as (b), plotted with the DP model.
The analysis of RT models reveals that Transformer models often learn uniform attention weights, empirically supporting their statistical advantage in processing reasoning tasks.
Conclusion
The paper "Boule or Baguette?" showcases how task topology—depth and breadth—affects the generalization abilities of reasoning models. It underscores the strengths of RT models in handling broad, simple tasks, while highlighting their vulnerabilities in deep contexts. This research provides a basis for further exploration of task types and model architectures to facilitate better reasoning model development in AI.
