HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Abstract: Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier LLMs on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art LLMs on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a popular “big test” used to judge how smart large AI models are. The test is called Humanity’s Last Exam (HLE). It has very hard questions from many subjects—math, science, engineering, and the humanities. But people noticed that some HLE questions and answers were wrong, unclear, or confusing. That makes it unfair to compare AI models using it.
The authors created HLE-Verified, a cleaned-up and checked version of HLE. Their goal is to fix mistakes, clearly label uncertain items, and make the test more trustworthy so it measures what AI models can really do.
What were the main goals?
The study had three simple goals:
- Check each HLE question carefully to see if it’s clear, correct, and solvable.
- Fix items that can be repaired without changing what they’re supposed to test.
- Show how cleaning the test changes AI models’ scores and confidence, so results are fairer and more accurate.
How did they do it?
Think of each test item like a school question with three parts:
- The question itself (Problem)
- The official answer (Answer)
- The explanation or “show your work” (Rationale)
They used a two-stage process:
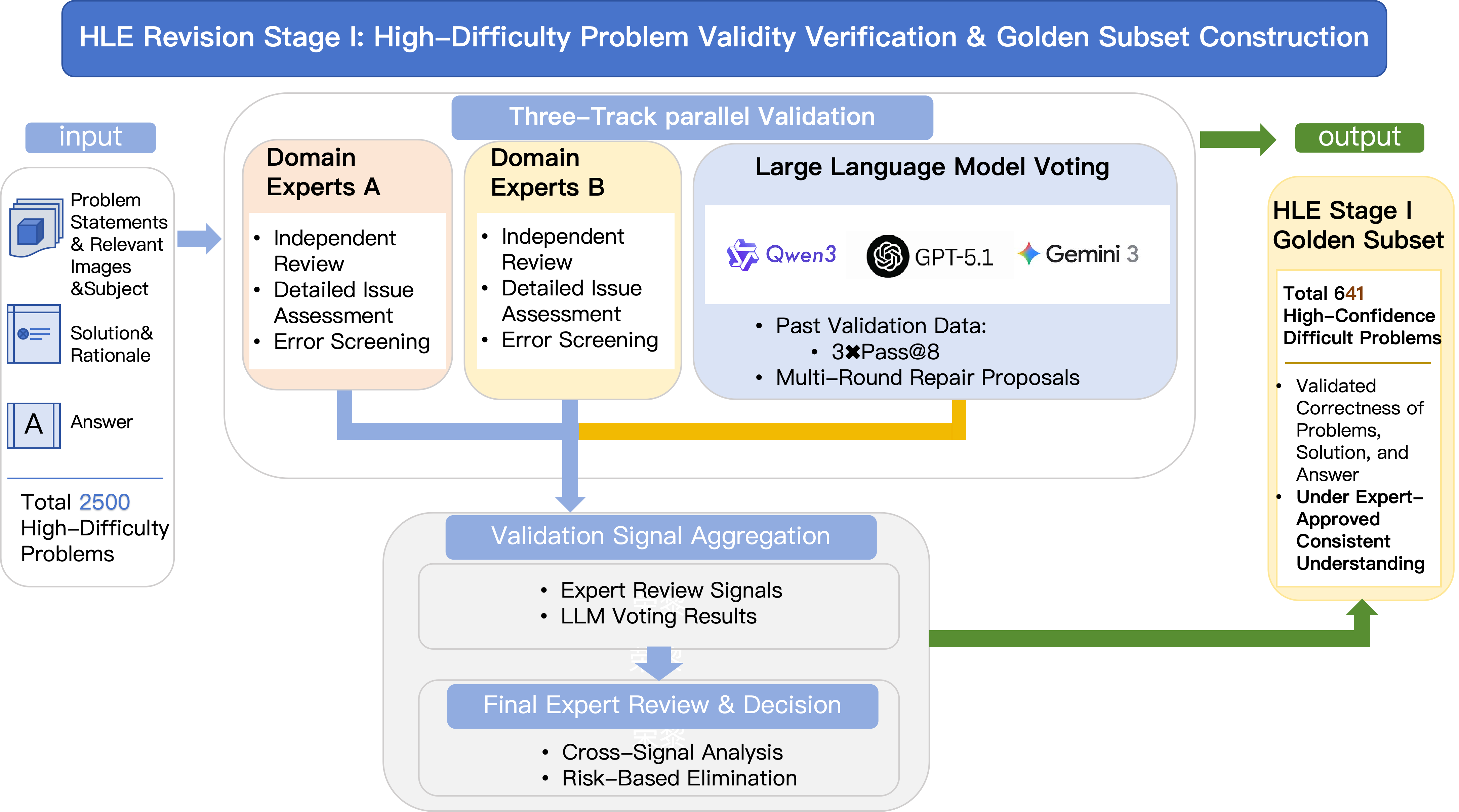
Stage I: Verify without changing
- Domain experts (people trained in the subject) read each item to check if the question is well-posed (clear and solvable), the answer matches the question, and the explanation makes sense.
- They also asked several top AI models to try the question multiple times (this is called “pass@8,” like giving the question up to 8 tries) to see if the results were consistent.
- If both the question and answer looked solid, the item was marked as “gold” (fully verified).
Outcome: 641 items were verified “as-is” and kept unchanged.
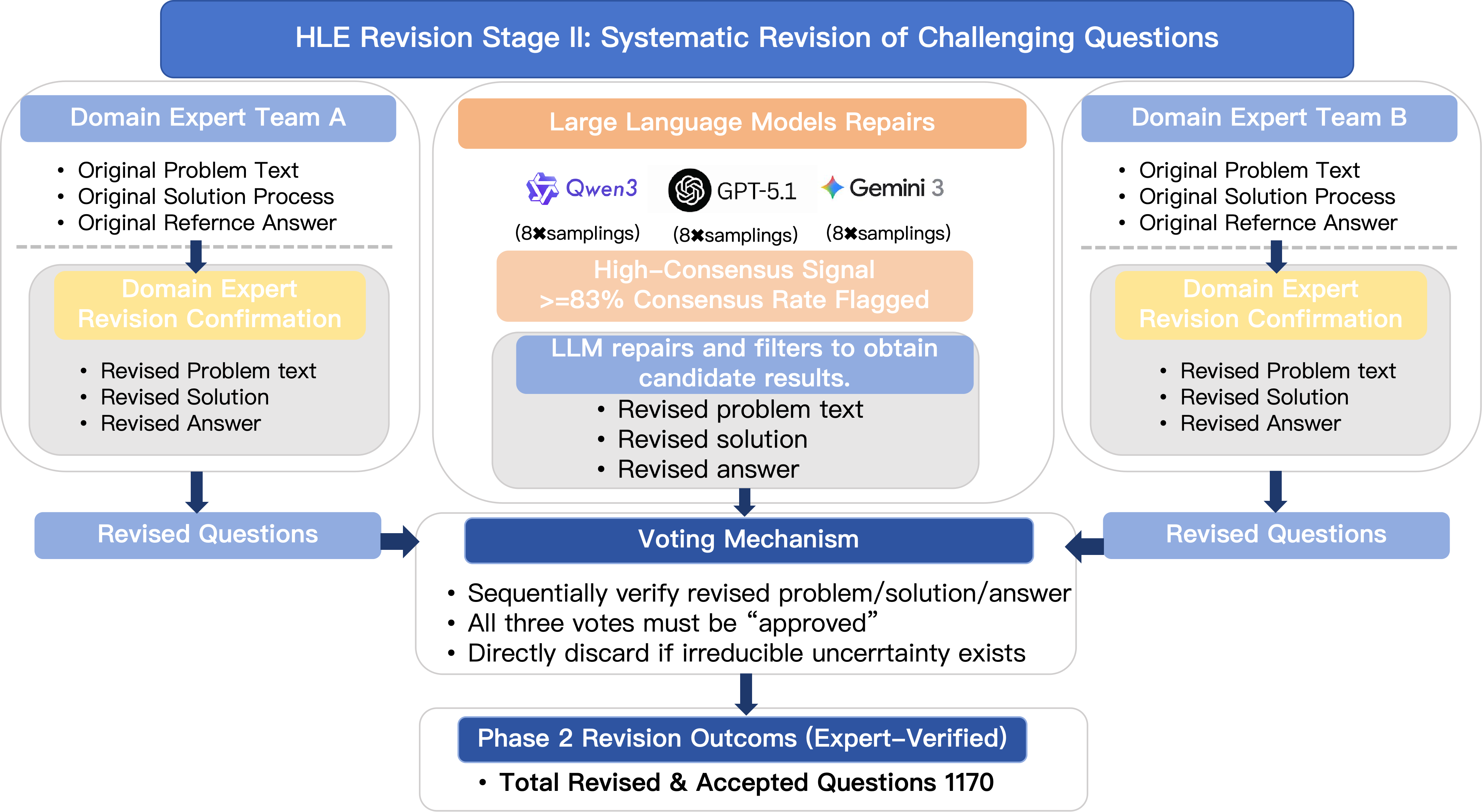
Stage II: Fix what can be fixed
- For items with problems (like a wrong answer key, missing details, or a confusing explanation), two independent expert teams proposed careful fixes while keeping the original intent of the question.
- AI models could suggest ideas, but experts made the final decisions.
- If the item could be made clear and correct without changing what it tests, it was repaired and re-verified.
Outcome: 1,170 items were repaired and certified as good to use.
What about items that were too uncertain?
Some items couldn’t be confidently judged (for example, they depended on disputed facts or unclear conventions). Instead of deleting them, the team kept them as an “uncertain set” with notes on what kind of expert or evidence would be needed to settle them.
Outcome: 689 items were kept with uncertainty labels for future community review.
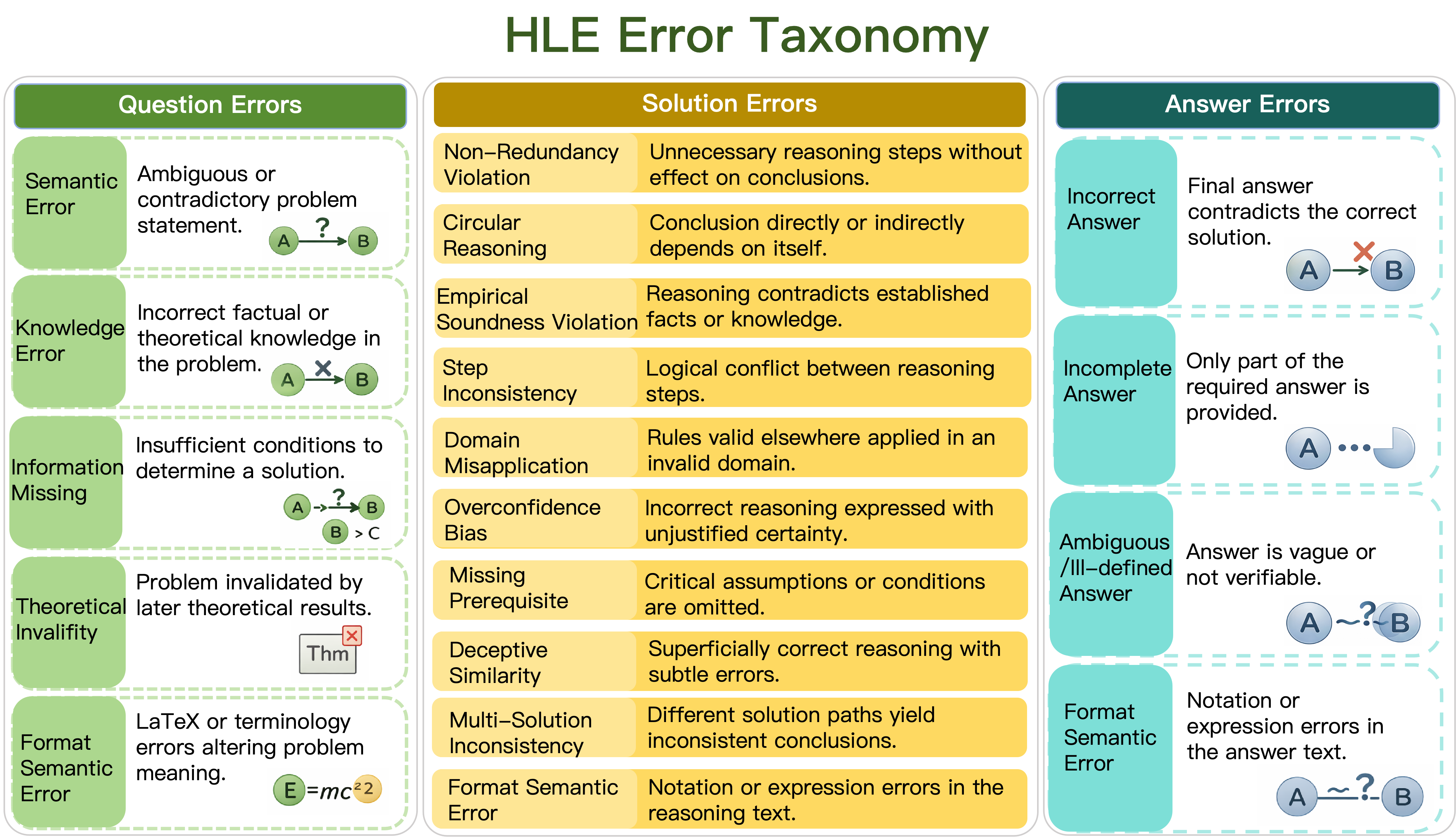
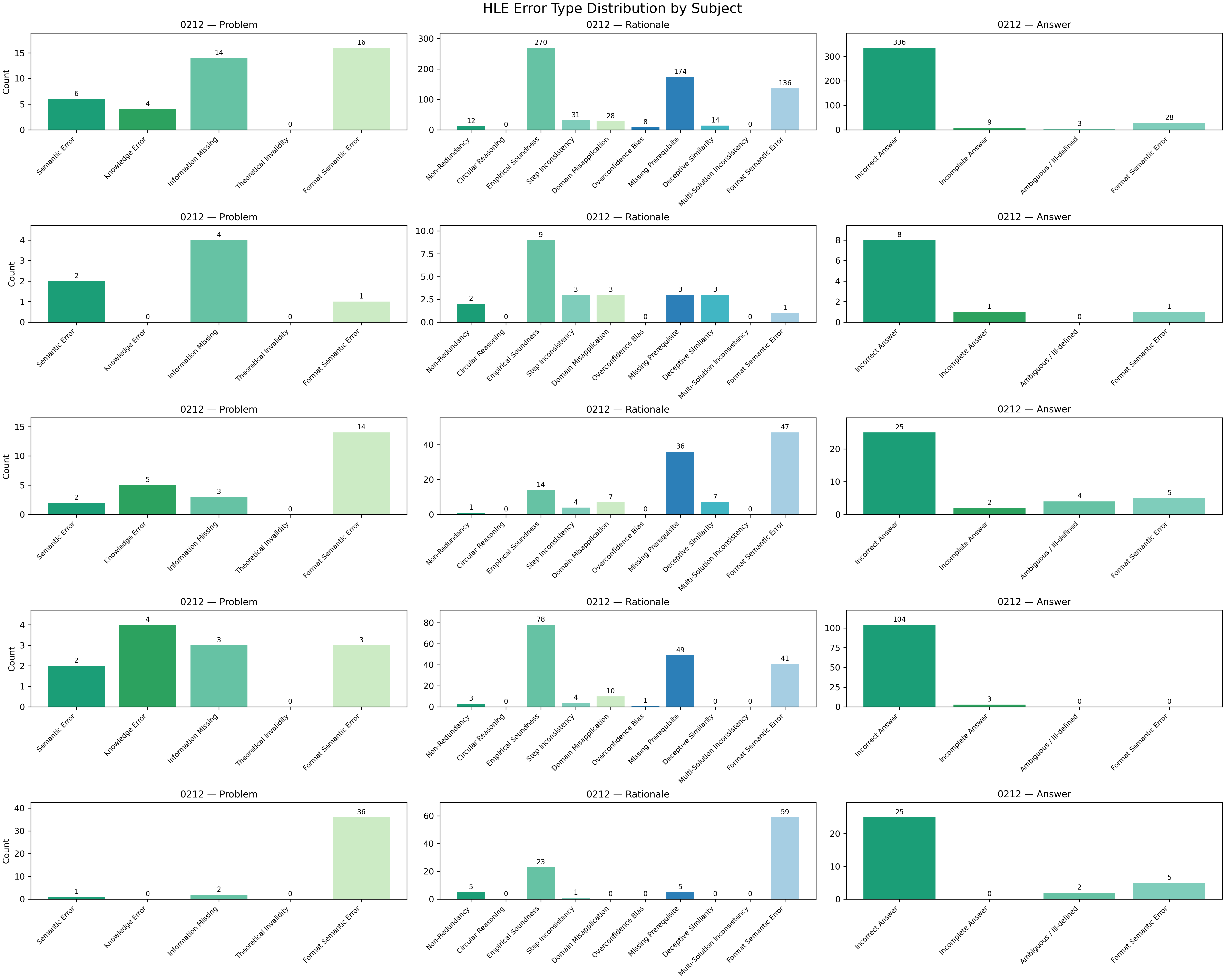
How did they organize mistakes?
To keep things consistent, they sorted errors into simple categories:
- Problem errors: the question is unclear, missing key information, or uses wrong facts.
- Rationale errors: the explanation is incomplete, inconsistent, or uses rules incorrectly.
- Answer errors: the final answer is wrong, incomplete, or in a confusing format.
This “error map” helps others understand exactly what went wrong and what was fixed.
What did they find?
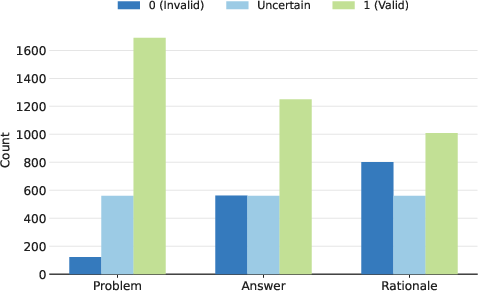
About the dataset
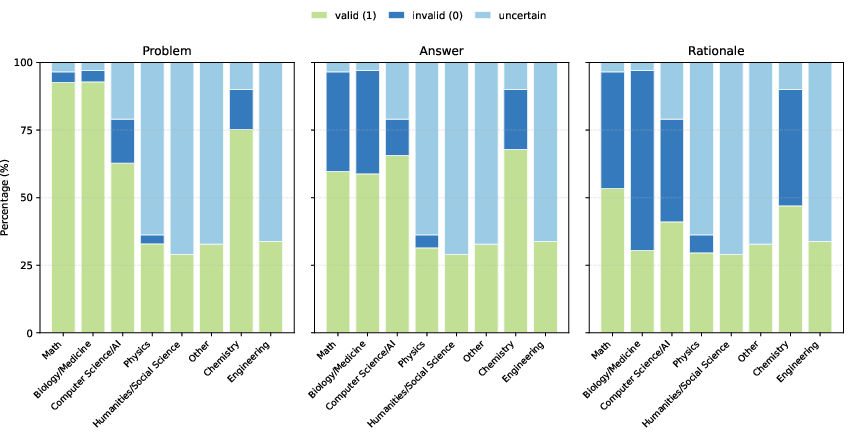
- Many issues were not in the question text but in the answer key and the explanation.
- The “rationale” (explanation) was often the weakest part—missing steps or assumptions.
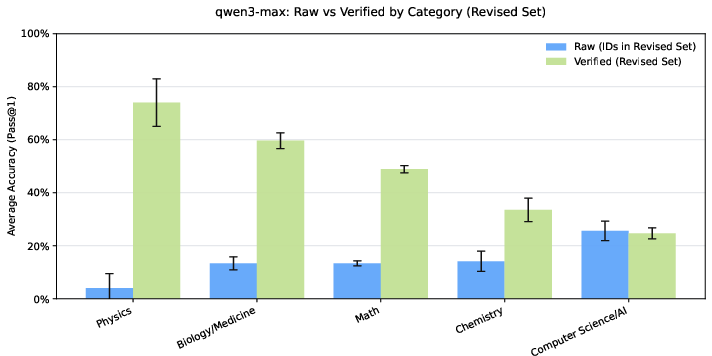
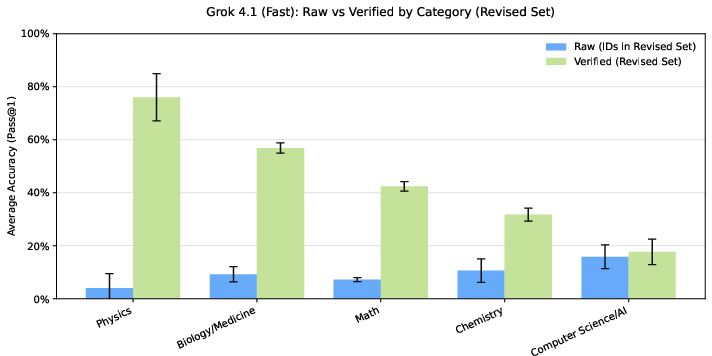
- Correctness problems varied by subject. For example:
- Math and biology often had wrong answers (but the questions themselves were mostly well-formed).
- Physics and humanities often had uncertainties due to conventions or interpretation.
About model performance
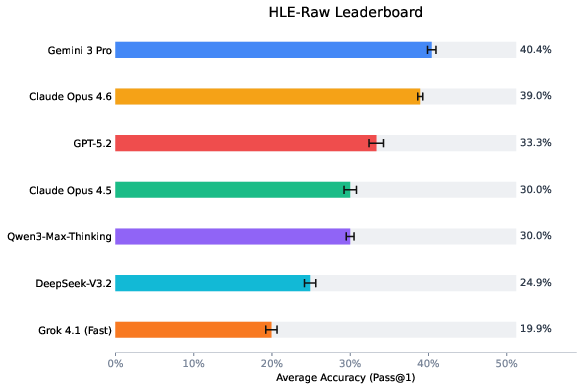
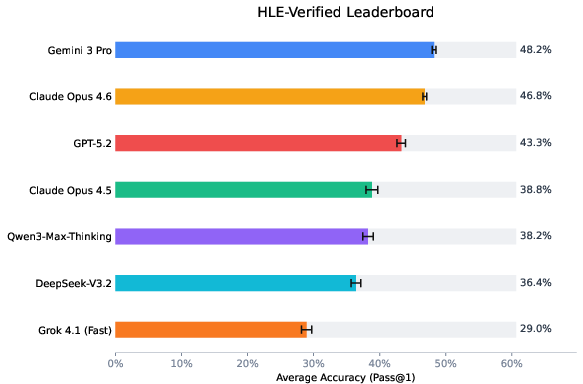
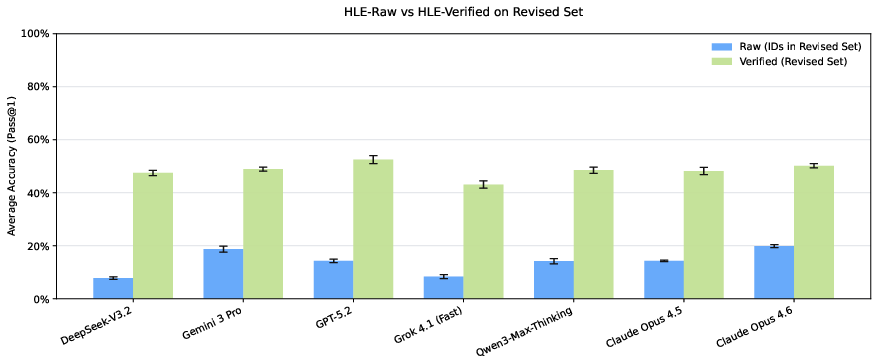
After switching from raw HLE to HLE-Verified:
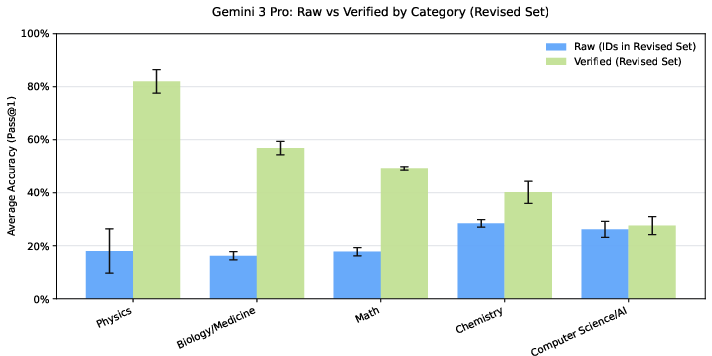
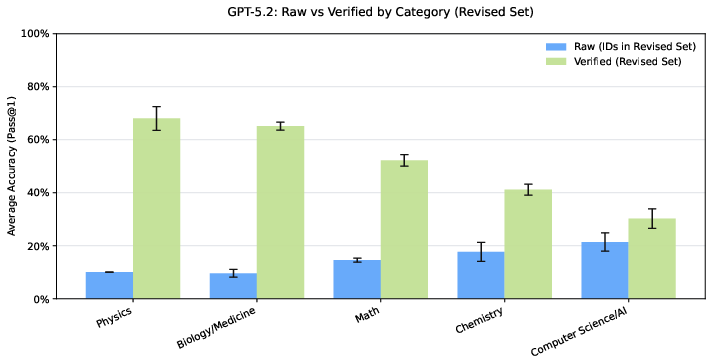
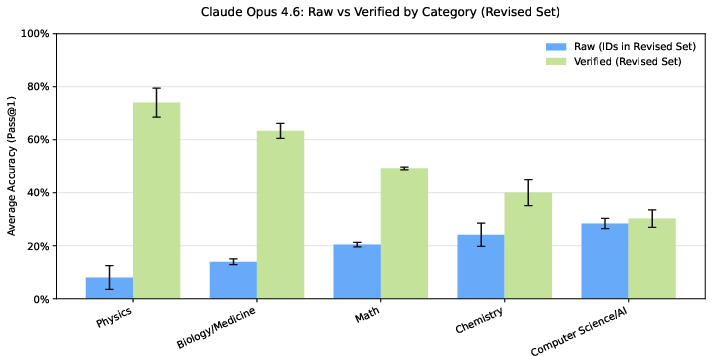
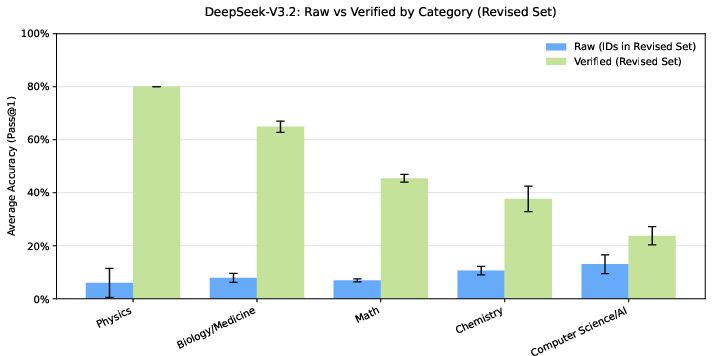
- Overall accuracy went up by around 7–10 percentage points on average across several top AI models.
- On items where the original question or answer had errors, accuracy jumped by about 30–40 percentage points. This means models were penalized before because the test itself had mistakes.
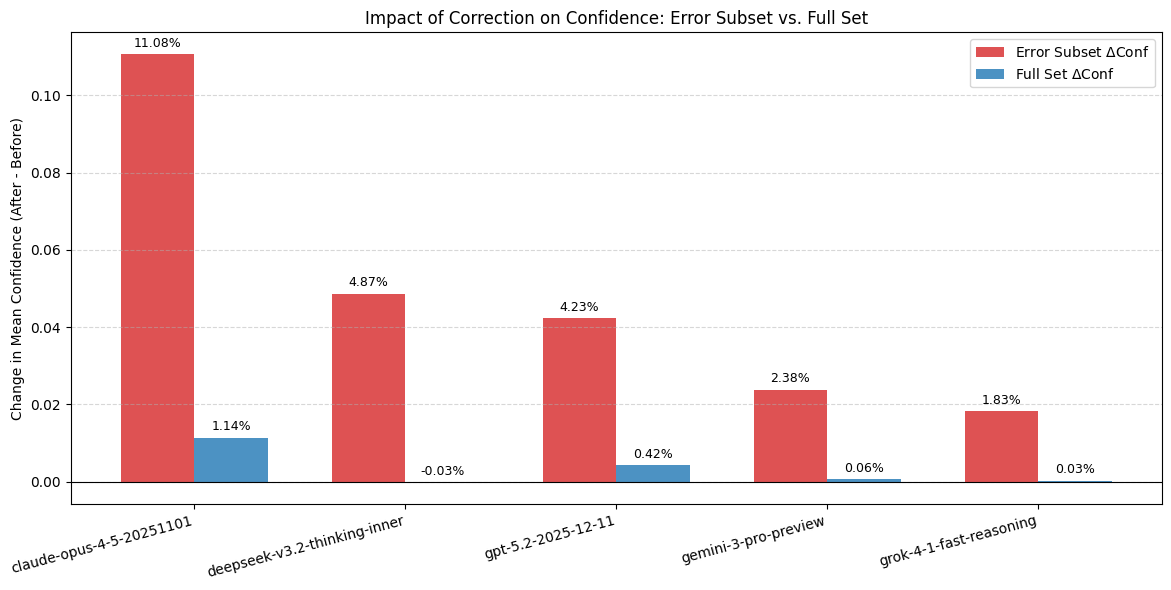
- Model “calibration” improved. Calibration means how well a model’s confidence lines up with being correct. With cleaner questions and answers, models’ confidence matched results more reliably.
- Models were more confident on repaired problem statements. When the question was fixed to be clear and correct, models’ confidence increased, which is a good sign the test is now less confusing.
Why is this important?
If a test has wrong or unclear items, models can look worse (or better) than they really are. That’s bad for science and progress, because decisions about safety, reliability, and capability depend on fair evaluations.
HLE-Verified:
- Reduces noise and errors in a widely used benchmark.
- Makes comparisons between models more fair.
- Helps researchers trust what scores actually mean.
- Provides a clear process and labels so the community can keep improving the test over time.
What could this change in the future?
- Better benchmarks: Other tough tests for AI can copy this verification-and-repair approach.
- Fairer leaderboards: Model rankings will reflect real skill, not mistakes in the test.
- Smarter diagnostics: Since models’ confidence drops on flawed items, confidence can help flag questions that need review.
- Community teamwork: The “uncertain set” invites experts to help resolve tricky items, making future versions even stronger.
In short, HLE-Verified turns a great idea—a very hard, broad test—into a more reliable tool. It helps everyone measure AI progress in a way that’s fair, clear, and honest.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces HLE-Verified and demonstrates clear benefits, but it leaves multiple methodological and empirical questions unresolved. The following list distills concrete gaps that future work can address:
- Lack of inter-annotator agreement metrics and reviewer calibration: no reported κ/α scores, cross-team consistency checks, or drift analyses for the domain-expert screenings, repairs, and adjudications.
- Unspecified bias controls in expert recruitment: reviewer backgrounds, incentives, and potential domain/affiliation biases are not characterized or mitigated.
- Ambiguity in “preserving evaluation intent”: no operational test or independent audit shows that revisions did not inadvertently change item difficulty, scope, or construct validity.
- No psychometric analysis of difficulty/discrimination: absence of IRT/Rasch or reliability analyses before vs. after revision to quantify item difficulty shifts and benchmark-level measurement properties.
- Limited domain coverage in revision scope: humanities/social sciences and parts of engineering are often deemed “uncertain”; no methodology is offered to reliably verify or repair items in subjective or convention-heavy domains.
- Multimodal gap in experiments: although the pipeline supports images, all main evaluations are on text-only items; the impact of verification/revision on multimodal items remains untested.
- Circularity risk in model-assisted verification: use of frontier LLMs for pass@8 cross-checks may import their biases into the verification process and favor models with similar training/inductive biases.
- Unknown sensitivity to model choice in verification: no ablation shows how verification outcomes vary with different solver families, temperatures, or sampling budgets.
- Equivalence protocol underspecified: numeric tolerances, unit normalization, and semantic-matching rules are not fully detailed or validated across domains; no error analysis of grader false positives/negatives.
- Confidence-based diagnostics left undeveloped: paper shows confidence rises post-repair but does not build or evaluate automated item-noise detectors using confidence signals (e.g., ROC, precision/recall for noisy-item detection).
- Calibration metric dependence: only a smoothed L2 “Cali Err” using self-reported confidences is used; no comparison with proper scoring rules (Brier, log-loss), ECE variants, or elicitation-hardened confidence protocols.
- Prompting/decoding sensitivity unstudied: results use a single system prompt and default decoding; no robustness study for prompt variants, CoT vs. no-CoT, temperature/top-p changes, or majority-vote vs. avg@k scoring.
- Limited model coverage and generality: seven frontier models are evaluated; improvements might differ for smaller/open-source models, tool-augmented systems, or non-English LMs; no cross-lingual verification is attempted.
- Training-data leakage risk: revised items may enter pretraining/finetuning corpora; the paper does not assess contamination or propose held-out protocols to protect future evaluations.
- Large uncertain set remains unresolved (689 items): the paper provides tags but no concrete governance process, timelines, or mechanisms (e.g., adjudication panels, external expert pools) to converge these items to verified status.
- No quantitative audit of taxonomy reliability: the 19-category defect taxonomy lacks reported label consistency, multi-label overlap handling, or confusion matrices across annotators/domains.
- Minimal analysis by repair type: performance effects are not decomposed by what was fixed (problem vs. answer vs. rationale vs. combinations), leaving unclear which fixes drive gains and where to prioritize future audits.
- No assessment of item/edit-level difficulty drift: edits may unintentionally make items easier/harder; absence of anchor-item strategy or DIF (differential item functioning) analysis.
- Rationale quality evaluation is out-of-scope for scoring: although rationales are corrected, the paper does not quantify rationale quality post-revision, its utility for CoT evaluation, or its impact when rationales are used as references in judge LMs.
- External validity not tested: no evidence that HLE-Verified scores better predict performance on other high-difficulty benchmarks (e.g., GPQA, MATH, MMLU-Pro) or real-world tasks.
- Grader robustness for open-ended/semantic answers: beyond numeric equivalence, the paper does not present validated semantic matchers or human-in-the-loop protocols for complex answers (proofs, essays, code behavior).
- Reproducibility details missing for verification runs: solver identities, versions, seeds, decoding configs, and pass@k settings used in verification are not exhaustively documented for replication.
- Cost, time, and scalability not reported: no accounting of human-hours, costs per item, or throughput; unclear whether the pipeline is practical for continual maintenance or for other benchmarks at scale.
- Governance and continuous maintenance plan undefined: versioning, re-verification cadence, community contribution vetting, and conflict resolution processes are not specified.
- Security/Goodhart risks unaddressed: releasing a fixed verified set may encourage overfitting; no proposal for sequestered items, rotating test slices, or leak-resistant evaluation protocols.
- Cross-domain fairness analysis incomplete: while gains vary by subject, there’s no investigation of whether revisions alter domain distributions or systematically advantage certain model families.
- Unclear handling of multimodal-specific errors: taxonomy and fixes for image/diagram ambiguity, OCR/LaTeX rendering issues in figures, and visual-answer equivalence are not detailed or validated.
- Limited statistical reporting: accuracy shifts lack confidence intervals, bootstrap estimates, or significance testing; stability across multiple evaluation seeds is not reported.
- Expertise tag reliability for uncertain items: the consistency and granularity of “required expertise” tags are not validated; criteria for when such expertise is considered sufficient remain unspecified.
- Lack of downstream benchmarking tools: no release of standardized graders, validators, or confidence-based filters that others can reuse to replicate the verification process on new or related datasets.
Glossary
- adjudication: A formal expert decision process to resolve disagreements or synthesize evidence into a final judgment. "Final expert adjudication."
- aggregate metrics: Summary performance statistics computed over a dataset, often used for model comparison. "aggregate metrics such as accuracy or pass@k"
- auditability: The degree to which reasoning or processes can be inspected and verified for correctness. "Redundant reasoning steps that reduce minimality or auditability."
- calibration: The alignment between a model’s stated confidence and its actual correctness. "calibration- or uncertainty-aware evaluations"
- calibration behavior: How a model’s confidence levels relate to its correctness across different conditions. "due to differences in training exposure, reasoning style, or calibration behavior."
- Calibration Error: A quantitative measure of the mismatch between predicted confidence and observed correctness. "Calibration error is computed from the model's self-reported confidence and the binary correctness label:"
- chain-of-thought: A prompting strategy that elicits intermediate reasoning steps before the final answer. "chain-of-thought-based prompting."
- component-wise: Treating different parts of an item (problem, answer, rationale) as separate units for verification or analysis. "a transparent, component-wise verification protocol"
- dataset infrastructure: A dataset designed and maintained as core evaluation infrastructure rather than a one-off benchmark. "We position HLE-Verified as dataset infrastructure"
- decision boundary: The threshold region where a model’s predictions switch classes and are most sensitive to small changes. "near a modelâs decision boundary"
- defect taxonomy: A structured categorization system for different error types within benchmark items. "HLE Component-wise Defect Taxonomy"
- epistemic status: A label reflecting the level of certainty or knowledge about an item’s validity. "an epistemic status label (verified, revised, or uncertain)"
- equivalence classes: Sets of answers considered interchangeable under defined rules (e.g., unit, format, or semantic equivalence). "including units, format, and acceptable equivalence classes."
- equivalence protocol: A predefined set of rules for judging when two answers are considered the same. "under a fixed equivalence protocol (numeric tolerance, format normalization, semantic equivalence where applicable)."
- evaluation intent: The original objective or capability a question is meant to assess, which revisions must preserve. "preserve the original evaluation intent"
- evaluation substrate: The foundational benchmark context used for assessing models. "HLE as an evaluation substrate"
- frontier LLMs: The latest, most advanced LLMs at the leading edge of capability. "frontier LLMs on challenging, multi-domain questions."
- gold subset: The set of items validated as correct without modification and suitable for evaluation. "Gold subset (641 items): validated without modification."
- model-assisted replication checks: Using model-generated solutions to help verify answers and highlight inconsistencies. "Model-assisted replication checks (pass@8)."
- pass@8: A metric indicating success when up to eight sampled attempts are allowed. "pass@8 sampling"
- pass@k: A metric indicating success when up to k sampled attempts are allowed. "accuracy or pass@k"
- post-release benchmark auditing: Systematic verification and correction of a benchmark after it has been published. "a systematic two-stage verification-and-revision framework for post-release benchmark auditing."
- rationale: The reference solution or explanation accompanying an item, used as a diagnostic signal. "the rationale serves as diagnostic support for detecting inconsistencies, missing assumptions, or explanation defects."
- reproducibility: The ability for results to be independently replicated under the same conditions. "undermine interpretability, reproducibility, and measurement reliability."
- semantic equivalence: Different answer expressions that convey the same meaning and are treated as equivalent. "semantic equivalence where applicable"
- smoothed L2 miscalibration estimator: A specific statistical estimator for measuring calibration error using an L2-based smoothing. "a smoothed miscalibration estimator with smoothing parameter ."
- subject-matter reviewers: Domain experts who assess items for correctness and validity. "Independent subject-matter reviewers assess problem, answer, and rationale, providing component-wise binary judgments and concise notes."
- uncertainty-aware evaluations: Assessments that explicitly consider uncertainty or confidence in correctness. "calibration- or uncertainty-aware evaluations"
- uncertainty descriptors: Structured metadata fields that document sources and types of uncertainty for an item. "structured uncertainty descriptors"
- verification protocol: A formal, transparent procedure for checking item correctness and consistency. "a transparent, component-wise verification protocol"
- well-posed: A problem that is sufficiently specified, self-consistent, and admits a unique or properly qualified solution. "well-posed, self-consistent, and sufficiently specified for a unique or properly qualified solution"
Practical Applications
Immediate Applications
The following list outlines concrete, deployable applications that leverage HLE-Verified’s verification protocol, defect taxonomy, metadata, and empirical findings.
- Industry (software/ML ops): “Benchmark Audit Studio” for internal eval datasets
- A toolchain implementing the paper’s two-stage verification workflow (expert + model-assisted pass@k replication, equivalence normalization, component-wise labeling) to audit company benchmarks and prompt collections before release.
- Outputs dataset-level health reports (gold/revised/uncertain split, defect distributions) and calibration dashboards.
- Dependencies/Assumptions: Access to domain experts; standardized equivalence policies; compute access to multiple models for pass@k sampling.
- Academia (evaluation methodology): Component-wise verification protocol and taxonomy adoption
- Research groups can adopt the 19-category defect taxonomy and component-level labeling to improve reproducibility and interpretability of evaluations (e.g., MMLU, GPQA, Code benchmarks).
- Enables stratified analyses and more faithful cross-model comparisons.
- Dependencies/Assumptions: Agreement on annotation schema; light training for annotators; shared metadata formats.
- Education (assessment quality): Answer Key Validator for question banks
- A workflow to identify incorrect, incomplete, or ambiguously formatted answer keys in K–12 and higher-ed item banks using the paper’s answer-level defect categories and equivalence normalization.
- Reduces false negatives when evaluating students and AI tutors; improves standardized test reliability.
- Dependencies/Assumptions: Access to item metadata; clear domain conventions (units, formats); optional expert oversight for edge cases.
- Healthcare (clinical QA sets): Verified evaluation for medical reasoning tasks
- Apply Stage I/II verification to clinical case questions, guidelines-based QA, and biomedical exam banks to remove incorrect answers and ambiguous statements that can bias model assessments.
- Calibrated evaluation (confidence vs correctness) supports safer deployment and internal model governance.
- Dependencies/Assumptions: Clinical subject-matter experts; careful scoping for contested medical facts; defensible equivalence policies.
- Finance and compliance (model governance): Confidence-based noise diagnostics
- Integrate confidence-shift analyses to flag potentially noisy evaluation items (as shown, confidence rises post-repair on problem-error items), improving risk reporting for LLMs used in compliance workflows.
- Supports audit trails showing that performance claims are not inflated by benchmark defects.
- Dependencies/Assumptions: Models must expose confidence; standardized parsing of self-reported probabilities; governance buy-in.
- Engineering/energy (technical content QA): Notation and unit consistency checks
- Use the format semantic error categories and unit/sign-convention checks to clean engineering problem sets, specs, and technical documentation that feed into LLM evaluation or training.
- Reduces ambiguity-induced failures in physics/chemistry/engineering tasks.
- Dependencies/Assumptions: Domain-specific unit and notation standards; tooling for LaTeX/symbol normalization.
- Publishing and documentation (technical editorial QA): Rationale completeness audits
- Apply rationale-level defect categories (e.g., missing prerequisites, format semantic errors) to ensure reference solutions and worked examples are auditable and aligned with final answers.
- Improves reader trust and downstream dataset usability for research.
- Dependencies/Assumptions: Editorial workflows that permit structured audits; access to subject reviewers for contested domains.
- Open-source / community (dataset stewardship): Uncertainty registry and triage
- Maintain an “uncertain” subset with explicit uncertainty sources and required expertise tags to crowdsource resolution without discarding items.
- Encourages transparent, versioned refinement and reduces benchmark drift.
- Dependencies/Assumptions: Contribution guidelines; lightweight review and adjudication; community incentives.
Long-Term Applications
These applications require further research, scaling, standardization, or development effort before broad deployment.
- Cross-benchmark certification (policy and standards): Verified dataset labels
- An independent certification program (e.g., ISO-like) that mandates component-wise verification, uncertainty documentation, and calibration reporting for benchmarks used in capability claims and procurement.
- Sectors: government, standards bodies, AI safety organizations.
- Dependencies/Assumptions: Consensus on minimum verification criteria; third-party auditors; funding.
- Automated defect detection (software/tools): ML-assisted “benchmark linter”
- Train detectors on HLE-Verified metadata to auto-suggest defect tags (problem/answer/rationale) and prioritize items for expert review via active learning.
- Reduces expert workload; scales verification to very large datasets.
- Dependencies/Assumptions: High-quality labeled corpora; iterative human-in-the-loop refinement; domain transfer studies.
- BenchOps (evaluation DevOps): Continuous verification pipelines
- CI/CD for benchmarks: versioning, regression-on-accuracy/calibration after item changes, and provenance tracking of repairs and adjudications.
- Integrates with model leaderboards to report both raw and verified scores, and confidence–correctness curves.
- Dependencies/Assumptions: Tooling integration with eval harnesses; dataset governance policies; storage of revision metadata.
- Model training with verified data (academia/industry): Noise-aware curriculum
- Use verified/revised items for fine-tuning reasoning models; exclude uncertain items or treat them as weakly supervised signals.
- Study the effect on calibration, robustness, and generalization.
- Dependencies/Assumptions: Sufficient verified item volume; careful curriculum design; empirical validation across domains.
- Sector-specific benchmark repair programs (healthcare, finance, law)
- Domain consortia curate verified evaluation suites with component-wise metadata, equivalence policies, and uncertainty registries tailored to sector standards (e.g., ICD/CPT in healthcare, GAAP in finance).
- Supports regulatory reporting and safer deployment.
- Dependencies/Assumptions: Multi-stakeholder governance; legal review for contested facts; sustained funding.
- Adaptive education platforms (education): Verified rationales and calibration-aware tutoring
- Build AI tutors that rely on verified question–answer pairs and rationales, exposing confidence and highlighting uncertainty to learners.
- Improves feedback quality and reduces propagation of incorrect solutions.
- Dependencies/Assumptions: Integration with LMS; guardrails for ambiguity; UX for confidence and uncertainty.
- Transparent leaderboards and “confidence health” metrics (research/industry)
- Standardize reporting beyond accuracy: publish calibration error, confidence shifts after verification, and domain-stratified defect impacts to minimize misleading rankings.
- Dependencies/Assumptions: Community adoption; shared metric definitions; incentives for transparent reporting.
- Marketplace for benchmark repair and expertise (ecosystem)
- A platform where dataset owners post uncertain items with expertise tags; reviewers submit repairs with structured change notes; maintainers adjudicate and version releases.
- Dependencies/Assumptions: Incentive mechanisms, quality control, and dispute resolution protocols.
- Regulatory stress testing (policy): Verified scenario sets for risk assessments
- Develop verified, multi-domain stress tests that probe known failure modes (e.g., answer-key errors, rationale omissions) and report calibrated risk profiles for LLMs used in critical settings.
- Dependencies/Assumptions: Alignment with regulatory frameworks; periodic updates; cross-agency collaboration.
- Consumer trust signals (daily life): “Verified evaluation” labels for AI products
- Product-facing badges indicating that claimed capabilities were measured on verified benchmarks with documented uncertainty handling and calibration results.
- Helps end users make informed choices; reduces overclaiming.
- Dependencies/Assumptions: Industry agreement on labeling; auditability; avoidance of badge inflation.
Collections
Sign up for free to add this paper to one or more collections.