RefineBench: Evaluating Refinement Capability of Language Models via Checklists
Abstract: Can LMs self-refine their own responses? This question is increasingly relevant as a wide range of real-world user interactions involve refinement requests. However, prior studies have largely tested LMs' refinement abilities on verifiable tasks such as competition math or symbolic reasoning with simplified scaffolds, whereas users often pose open-ended queries and provide varying degrees of feedback on what they desire. The recent advent of reasoning models that exhibit self-reflection patterns in their chains-of-thought further motivates this question. To analyze this, we introduce RefineBench, a benchmark of 1,000 challenging problems across 11 domains paired with a checklist-based evaluation framework. We evaluate two refinement modes: (1) guided refinement, where an LM is provided natural language feedback, and (2) self-refinement, where LMs attempt to improve without guidance. In the self-refinement setting, even frontier LMs such as Gemini 2.5 Pro and GPT-5 achieve modest baseline scores of 31.3% and 29.1%, respectively, and most models fail to consistently improve across iterations (e.g., Gemini-2.5-Pro gains only +1.8%, while DeepSeek-R1 declines by -0.1%). By contrast, in guided refinement, both proprietary LMs and large open-weight LMs (>70B) can leverage targeted feedback to refine responses to near-perfect levels within five turns. These findings suggest that frontier LMs require breakthroughs to self-refine their incorrect responses, and that RefineBench provides a valuable testbed for tracking progress.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces RefineBench, a big, carefully designed test to see whether AI LLMs can improve their own answers over several tries. It looks at two situations:
- When the AI gets clear feedback on what to fix (guided refinement).
- When the AI has to figure out what’s wrong and improve on its own (self-refinement).
The main idea: people often ask AIs to “revise,” “edit,” or “fix” their answers. RefineBench checks how well AIs actually do that across many subjects and tasks.
What questions the researchers asked
The paper explores three simple questions:
- Can AIs improve their answers without being told exactly what to change?
- How much does clear, targeted feedback help?
- Do some kinds of tasks or subjects make refinement easier or harder?
How RefineBench works (explained simply)
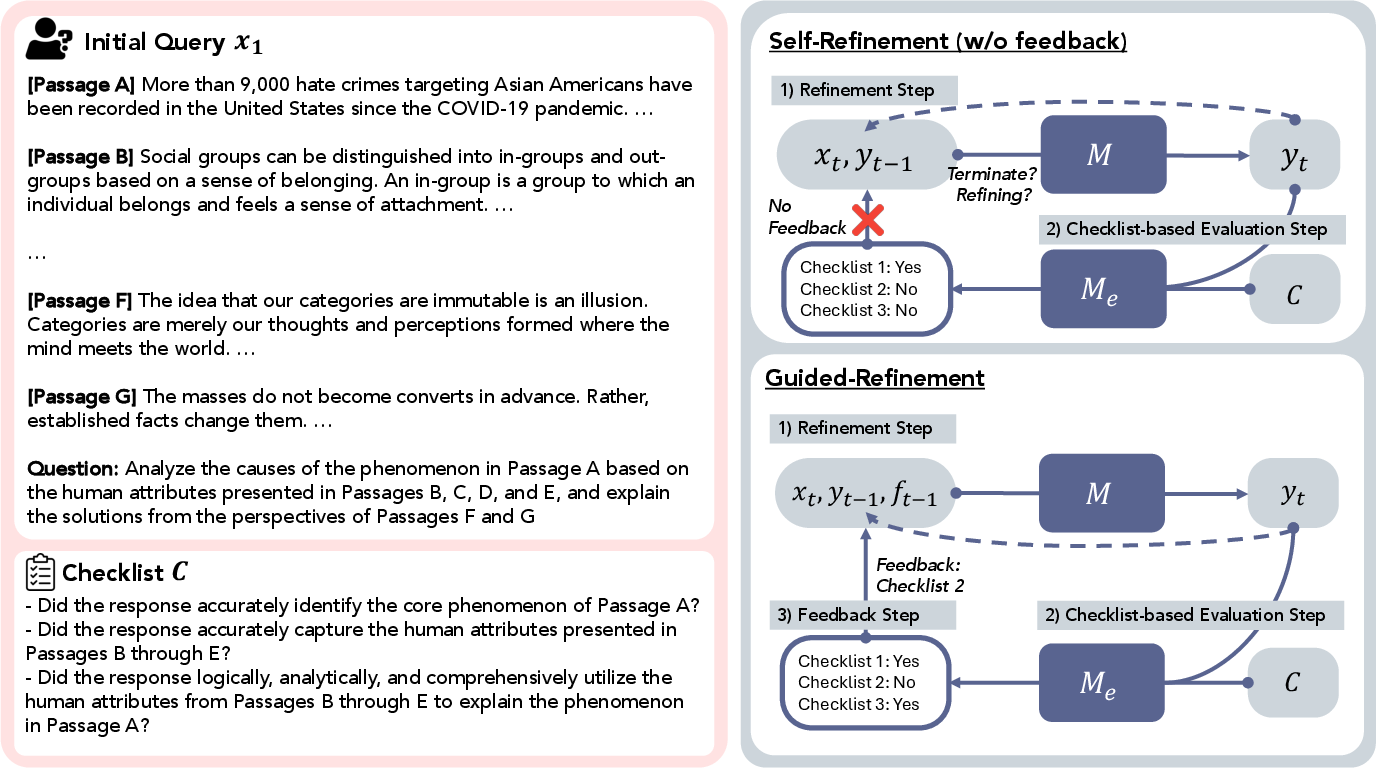
Think of RefineBench like a giant school exam for AIs, with a checklist for each question—similar to a teacher’s rubric. Each checklist item is a small requirement, like “include evidence,” “define the key term,” or “use the correct formula.”
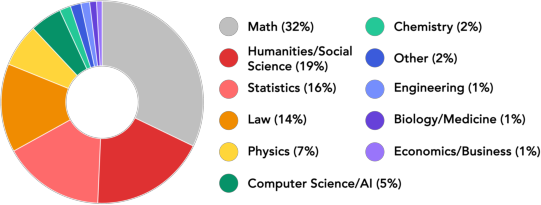
RefineBench covers 1,000 problems from 11 areas (like math, law, humanities, and social science). For each problem, the AI:
- Writes an answer.
- Gets “graded” by another AI using the checklist (each item is marked Yes or No).
- Tries again up to 5 turns, either:
- With no hints (self-refinement), or
- With hints that say what checklist items it missed (guided refinement). Sometimes only half the hints are given (partial guidance).
To keep things fair and clear, the paper uses simple scores:
- Accuracy: how many checklist boxes the AI checked off.
- Pass: only counts as a “pass” if the AI checks off all boxes.
What they found
The most important results are easy to remember:
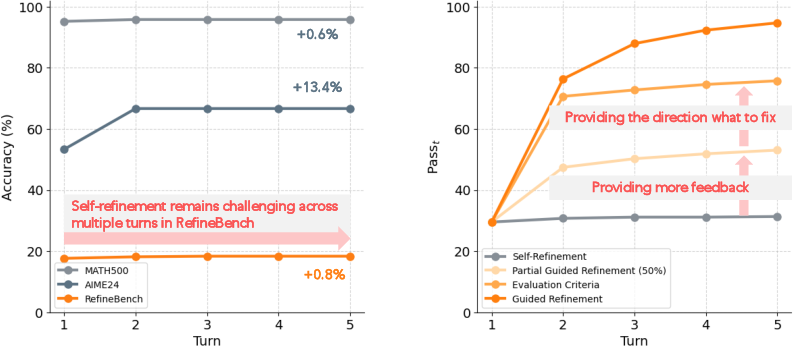
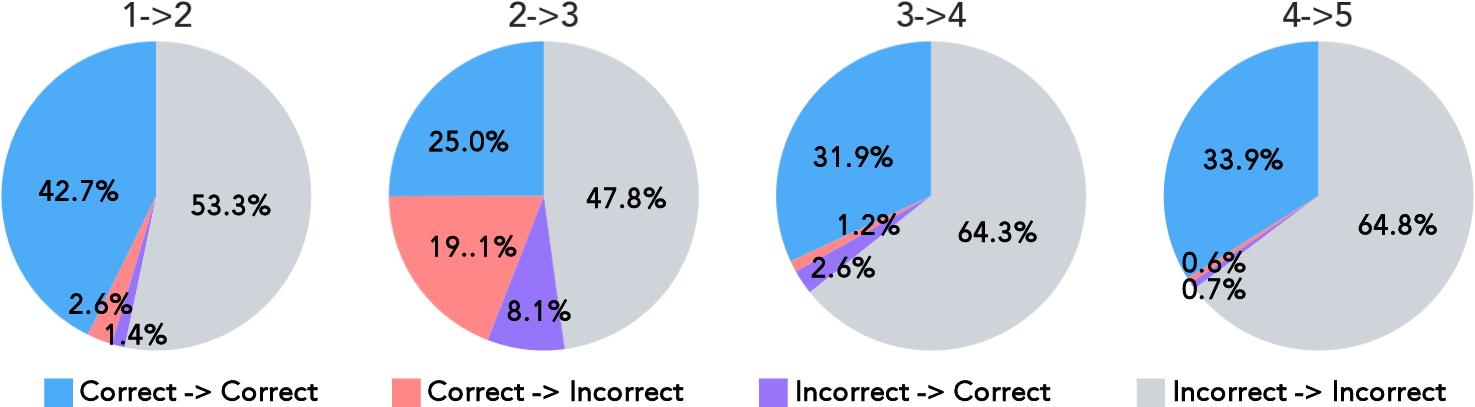
- Self-refinement is hard: Even the strongest AIs struggled to fix their own mistakes without hints. For example, the best model reached only about 31% perfect answers after five tries. Many models didn’t get better over time, or even got slightly worse.
- Guided refinement works great: When the AI is told what to fix (like a teacher leaving comments), most big, powerful models improved rapidly and reached near-perfect scores within five turns. Smaller models improved less.
- Why self-refinement is hard: AIs often fail at the first step—figuring out what needs to change. When researchers gave them the evaluation criteria (the checklist), scores jumped a lot. That suggests AIs can fix problems once they know what they are but struggle to identify them on their own.
- Partial feedback helps—but only for the parts you mention: When the AI is told about some missing items, it fixes those. But it still struggles with the missing items it wasn’t told about.
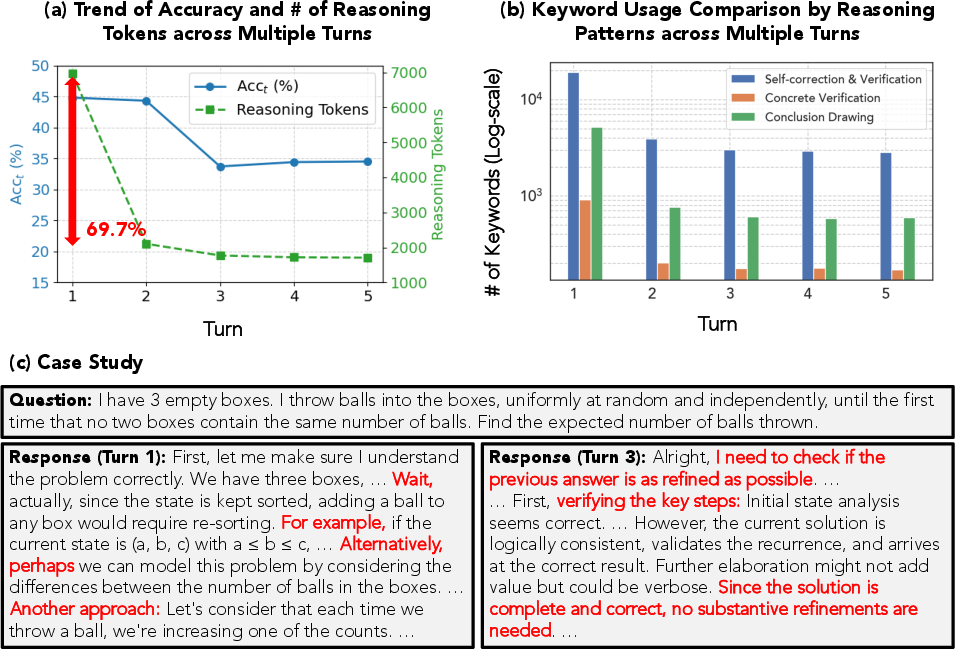
- More “thinking” isn’t enough: Letting AIs think longer didn’t solve the problem of multi-turn self-refinement. The core issue remains identifying what to change.
- Subject differences: Refinement ability varies by domain. Some models did better at self-refining in Law than in STEM. That means the challenge depends on the type of problem.
Why this matters
In everyday use, people often ask AIs to “revise,” “fix,” or “improve.” This paper shows:
- If you can give clear feedback (“add evidence,” “define the concept,” “include counterargument”), the AI can get very good, very fast.
- If you can’t give feedback (or only little), today’s AIs often struggle to improve on their own, even after several tries.
- RefineBench is a practical way to measure and track progress on this skill over time.
What this could change in the future
This work suggests a few helpful directions:
- For users and developers: Give specific, checklist-like feedback to get the best results from AI.
- For researchers: Train AIs to better spot what’s wrong with their own answers. Reward functions or training that use checklists could help.
- For benchmarking: Use RefineBench to compare models and guide improvements, especially in real-world, open-ended tasks (like essays or legal analysis), not just math or coding.
In short, RefineBench reveals a crucial gap: today’s AIs are good at fixing mistakes when told what to fix, but they’re not yet good at finding those mistakes by themselves. This benchmark makes it easier to measure that gap and work toward closing it.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions that the paper leaves unresolved, to guide future research.
- Evaluator dependence: Results rely on a single evaluator LM (GPT-4.1), with no robustness checks across different evaluators, seeds, or evaluation protocols; how sensitive are scores to the choice and configuration of the evaluator?
- Methodological circularity: GPT-4.1 (and other LMs) helped generate checklists and also served as the evaluator, risking alignment with its own criteria; can independently authored or human-verified checklists and third-party evaluators reduce bias?
- Limited human validation: Human review covered 100 samples only and reported percent-appropriate items without inter-rater reliability (e.g., Cohen’s/Fleiss’ kappa); what is the agreement and reliability at scale across domains and item types?
- Binary checklist scoring: All checklist items are weighted equally and judged as Yes/No, with no partial credit or importance weighting; how would item weighting, partial-credit schemes, or psychometric calibration (e.g., IRT) change conclusions?
- Strict Pass metric: Pass requires all items correct, potentially masking incremental improvement; which alternative graded metrics better capture meaningful refinement gains?
- Domain skew and representativeness: Math comprises 32% and Law 14% of the dataset, with limited coverage of other real-world refinement contexts; how do results change under a balanced domain mix or additional domains (e.g., medical, engineering, code)?
- Law-specific gains unexplained: Models self-refine notably better in Law; what properties of legal tasks/checklists (e.g., concrete criteria, precedent structure) drive this, and do they generalize?
- Multimodality gap: Non-textual materials were verbalized to text; there is no evaluation of true multimodal refinement (images/tables as inputs); how do models perform when directly processing multimodal data?
- Translation uncertainty: Many problems were translated from Korean to English via LMs; what is the impact of translation errors or cultural/linguistic bias, and how do models refine in multilingual settings?
- Feedback quality/control: Partial-guided experiments mainly vary the feedback ratio (e.g., 50%) but not feedback quality dimensions (correctness, specificity, verbosity, phrasing, contradictions); how do these factors affect refinement efficacy?
- Noisy/misleading feedback: Guided refinement assumes accurate feedback; how resilient are models to noisy, adversarial, or contradictory feedback, and how can they detect and discount it?
- Turn budget and stopping policy: Experiments fix max turns to 5 and analyze termination empirically; what are the optimal turn budgets and stopping criteria under different domains, costs, and performance targets?
- Causality in termination behavior: The negative correlation between longer termination and performance is descriptive; do controlled interventions (forcing longer/shorter refinement) confirm causal effects?
- Reasoning-effort scaling: Token-based “thinking” scaling was examined for Gemini only; how does reasoning budget (tokens, time, tool use) systematically affect self-refinement across diverse models?
- Prompting and scaffolds: Self-refinement prompts are not varied or optimized across models; which prompting strategies (error listing, hypothesis testing, checklist discovery, self-critique scaffolds) improve self-refinement?
- Checklist validity for free-form tasks: It is unproven that satisfying checklists equates to human-perceived quality; how do checklist scores correlate with expert holistic judgments and user satisfaction?
- “Gaming” risk in guided refinement: Providing exact failed checklist items may enable paraphrase-level fixes rather than substantive improvements; can high-level, implicit, or noisy feedback better test genuine refinement?
- Item-level analyses: There is limited analysis of which checklist item types (e.g., citation accuracy, logical consistency, grounding) are persistently hard; can item-level learning curves and skill taxonomies inform targeted training?
- Training methods: The paper does not evaluate training approaches (e.g., RL with checklist-based rewards, supervised refinement turn data, critic models) on RefineBench; which methods actually improve multi-turn self-refinement?
- Safety/fairness/privacy: No assessment of harmful content correction, fairness, or privacy during refinement; how should safety-oriented checklists and evaluations be incorporated?
- Cost and latency generality: Cost/latency are reported for one evaluator-model pair; what are the evaluation costs across models, evaluators, and domains, and how can evaluation be made more efficient?
- Data contamination risk: Proprietary models may have seen source materials; were leak checks conducted, and how does contamination affect guided vs self-refinement conclusions?
- External validity: RefineBench is not validated on real conversational logs (e.g., WildChat refinement turns) or live deployments; do findings replicate in-the-wild multi-turn refinement scenarios?
- Specificity continuum: The study compares self-refinement, criteria-provided, and guided settings but does not map performance across a fine-grained continuum of feedback specificity; what is the dose–response curve for feedback detail?
- Tool use: Models did not leverage tools (retrievers, validators, checkers) during refinement; how do tool-augmented workflows affect self-refinement, especially on free-form tasks?
- Protocol transparency: Checklist creation and manual refinement steps lack detailed reproducible criteria (e.g., versioning, prompts, edit logs); can more transparent protocols improve reproducibility and trust?
- Evaluator uncertainty: Binary decisions lack confidence estimates or adjudication for borderline cases; would calibrated confidence, ensemble evaluators, or dispute resolution improve reliability?
- Source diversity: Many academic sources come from specific institutions/regions (South Korea, California Bar); does expanding geographically and culturally diverse sources change outcomes?
- Context length constraints: Small open-weight LMs perform poorly, but the role of context window and memory is not isolated; do larger context windows and memory scaffolds improve refinement?
- Benchmark scope: Coding or agentic tasks are underrepresented; how do refinement capabilities generalize to program synthesis, data analysis, and interactive agents with stateful memory?
Practical Applications
Overview
RefineBench introduces a checklist-based, multi-turn benchmark that isolates two modes of LLM refinement—self-refinement and guided refinement—across 1,000 problems in 11 domains. Key findings show that current frontier LMs struggle to self-refine (best Pass score ≈31%) but can reach near-perfect outcomes under guided refinement (often >90% by 5 turns). These insights translate into concrete applications spanning industry, academia, policy, and daily life, especially where structured feedback can be captured and fed back to models.
Immediate Applications
Below are applications that can be deployed now using guided refinement workflows, checklist-based evaluation, and existing large LMs.
- Checklist-guided model QA and acceptance testing for LLM-powered products (software)
- Use case: Integrate RefineBench-like checklist evaluation into CI/CD for chatbots, copilots, and content-generation tools to gate releases.
- Workflow/tool: “Refinement Gate” service that runs Acc_t/Pass_t per turn with an evaluator LM (e.g., GPT-4.1), returns known/unknown items, and requires meeting thresholds before deployment.
- Assumptions/dependencies: Access to reliable evaluator LM; domain-appropriate checklists; modest API cost/latency.
- Customer support and helpdesk response refinement with structured feedback (software, enterprise)
- Use case: Supervisors or users mark unmet criteria via UI checkboxes (e.g., “policy cited,” “tone polite”), enabling guided refinements to achieve near-perfect answers in 3–5 turns.
- Workflow/tool: “Support Supervisor” plugin embedding a checklist; auto-feedback generation from ticket metadata and knowledge base.
- Assumptions/dependencies: Clear organizational checklists; larger models (>70B or proprietary) for best results; integrated knowledge retrieval.
- Legal memo and brief refinement using rubrics (law, consulting)
- Use case: Lawyers apply IRAC-style checklists (issue, rule, analysis, conclusion) to iteratively refine memos with LLM support.
- Workflow/tool: “Legal Memo Refiner” that shows unmet checklist items and collects partial feedback; supports multi-turn improvement.
- Assumptions/dependencies: Domain-specific, validated legal checklists; human-in-the-loop review; attention to jurisdictional nuances and compliance.
- Medical documentation and patient communication refinement using clinical checklists (healthcare)
- Use case: Guided editing of discharge summaries, patient education materials, and administrative forms using clinical rubrics (e.g., clarity, risk disclosure, instructions).
- Workflow/tool: “Clinical Doc Refiner” highlighting unmet items; partial feedback when only some requirements are known.
- Assumptions/dependencies: Institution-approved clinical rubrics; compliance validation; larger LMs; strict data governance.
- Educational writing assistant with rubric-aligned feedback (education)
- Use case: Students receive targeted guided refinements based on instructor rubrics (thesis clarity, evidence, structure), boosting quality in 1–5 turns.
- Workflow/tool: “RubricPrompt” LMS integration that maps course rubrics to checklists and produces guided feedback; tracks Acc_t/Pass_t.
- Assumptions/dependencies: Rubrics must be explicit and course-specific; educator oversight; access to evaluator LM.
- Marketing and compliance review for financial communications (finance)
- Use case: Guided refinement of customer emails, product summaries, and disclosures to meet compliance checklists (fair balance, risk statements, data accuracy).
- Workflow/tool: “Compliance QA Loop” generating line-item feedback and Pass_t metrics for sign-off; audit trail stored for regulators.
- Assumptions/dependencies: Regulator-aligned checklists (e.g., FINRA, SEC); larger LMs; audit logging; human final approval.
- Public-sector chatbot refinement with structured citizen feedback (policy, government)
- Use case: Citizens select feedback categories (e.g., “add eligibility criteria,” “cite relevant statutes”), enabling guided multi-turn improvements.
- Workflow/tool: “Policy Chatbot Refinement UI” that captures partial feedback ratios and shows progress across turns.
- Assumptions/dependencies: Public rubrics; accessibility and multilingual support; privacy and logging.
- Editorial and documentation QA for software teams (software)
- Use case: Technical writers use checklists (completeness, accuracy, examples, API references) to guide multi-turn refinements.
- Workflow/tool: “DocCheck Refiner” integrating with docs platforms; evaluator LM scores items; partial feedback reveals gaps.
- Assumptions/dependencies: Maintained documentation standards; evaluator LM availability; versioning and review workflows.
- Grant and report preparation with checklist-driven refinement (academia, NGOs)
- Use case: Authors refine proposals and reports against funder rubrics (objectives, methods, evaluation) for higher Pass_t.
- Workflow/tool: “GrantRefine Assistant” mapping funder criteria to checklists; supports guided iteration.
- Assumptions/dependencies: Accurate rubric parsing; human approval; compliance checks.
- Model selection and procurement informed by refinement metrics (industry, academia)
- Use case: Choose LLMs based on guided vs self-refinement performance by domain (e.g., Law, Math) using Pass_t/Acc_t curves.
- Workflow/tool: “Refinement Dashboard” comparing models across turns and feedback ratios; decision support for procurement.
- Assumptions/dependencies: Representative tasks and checklists; consistent evaluator; budget and latency constraints.
- Consumer writing assistant with checklist-led “Refine my answer” (daily life)
- Use case: Users select common criteria (clarity, tone, length, structure) to steer guided refinements of emails, resumes, and essays.
- Workflow/tool: “Refine with Checklist” feature in writing apps; shows progress per item.
- Assumptions/dependencies: Lightweight, general-purpose checklists; larger LMs preferred; user consent and privacy.
- Partial-feedback refinement where only some requirements are known (cross-sector)
- Use case: Teams often know a subset of requirements; the system refines known items while flagging unknown ones as “likely gaps.”
- Workflow/tool: “Partial Feedback Manager” that tracks known vs unknown items; measures differential improvement.
- Assumptions/dependencies: Explicit ratio of known feedback; evaluator LM to identify residual gaps; user acceptance of uncertainty.
Long-Term Applications
Below are applications that require advances in self-refinement (identifying what to fix without explicit guidance), scaling, or new training strategies.
- Self-refining agents that autonomously identify and fix errors without checklists (software, robotics)
- Use case: Agents that iteratively detect unmet criteria and correct themselves in open-ended tasks and planning (e.g., task plans for robots).
- Potential tool/product: “Autonomous Refiner” agents combining meta-reasoning, verification, and exploration beyond repeating prior fixes.
- Assumptions/dependencies: Breakthroughs in error identification; robust self-verification; safe exploration strategies.
- Checklist-driven reward modeling and training (academia, model development)
- Use case: Train LMs to infer missing checklist items and optimize for Pass_t over turns using RL or direct preference optimization.
- Potential tool/product: “Checklist-RL” training pipelines where checklists serve as structured reward functions.
- Assumptions/dependencies: High-quality, scalable checklists; stable evaluator signals; curriculum design to avoid overfitting to known items.
- Domain-specialized self-refinement in law, healthcare, and finance (law, healthcare, finance)
- Use case: Models that show strong self-refinement in domain-specific tasks without guided feedback (e.g., legal IRAC structure, clinical risk disclosures).
- Potential tool/product: “Domain Self-Refiner” models trained on rubric inference and domain norms.
- Assumptions/dependencies: Large, high-quality domain data; safety and compliance validation; handling jurisdictional or regulatory variance.
- Standards and certifications for refinement capability (policy, industry consortia)
- Use case: Benchmarks and minimum performance thresholds for self-refinement and guided refinement in regulated deployments.
- Potential tool/product: “Refinement Capability Standard” and certification programs supported by RefineBench-like metrics.
- Assumptions/dependencies: Multi-stakeholder agreement; transparent evaluation; versioned benchmarks.
- Multimodal refinement with verbalized and visual checklists (software, education, healthcare)
- Use case: Refining outputs that refer to images, charts, and tables with criteria tied to visual correctness and narrative integrity.
- Potential tool/product: “Multimodal RefineBench” expansions; evaluators that can validate visual references.
- Assumptions/dependencies: Reliable multimodal evaluators; robust verbalization of visuals; dataset licensing.
- Adaptive feedback UIs that infer missing requirements (software, UX research)
- Use case: Interfaces that learn which checklist items are typically unknown and prompt users for targeted feedback.
- Potential tool/product: “Adaptive Feedback Collector” that dynamically raises the ratio of known feedback with minimal user friction.
- Assumptions/dependencies: UX optimization; data privacy; user willingness.
- Continuous evaluation platforms that measure partial-feedback assimilation (industry MLOps)
- Use case: Monitor known vs unknown feedback adoption over time; detect regressions in self-refinement and termination behavior.
- Potential tool/product: “Refinement Observability” dashboards and alerts tied to Pass_t and termination ratios.
- Assumptions/dependencies: Stable evaluator; standardized logging; correlation with business outcomes.
- Training curricula for meta-reasoning to detect what to fix (academia, model development)
- Use case: Teach models strategies to identify unsatisfied criteria, distribute attention beyond initial fixes, and avoid early termination.
- Potential tool/product: “Meta-Refine Curriculum” datasets focused on error discovery and durable retention across turns.
- Assumptions/dependencies: New data and training signals; interpretability tools to track reasoning shifts; evaluation alignment.
- Policy-guided citizen services that mandate structured feedback capture (policy, government)
- Use case: Regulations requiring public service chatbots to solicit category-based feedback to ensure guided refinement is achievable.
- Potential tool/product: “Citizen Feedback Standard” embedded in procurement and service-level agreements.
- Assumptions/dependencies: Policy adoption; accessibility concerns; multilingual support; auditing mechanisms.
- Energy and environment reporting with compliance rubrics (energy, sustainability)
- Use case: Refinement of ESG reports against checklists (scopes, baselines, methodologies) with audit trails.
- Potential tool/product: “ESG Refiner” with regulator-aligned rubrics and evaluator-backed scoring.
- Assumptions/dependencies: Evolving standards; domain data availability; stakeholder buy-in.
- Hybrid evaluators to reduce reliance on proprietary LMs (industry, open-source)
- Use case: Local or hybrid evaluator stacks to lower cost/latency and improve reproducibility.
- Potential tool/product: “Open Evaluator Suite” tuned to checklist scoring with calibration against human judgments.
- Assumptions/dependencies: Open models reaching evaluator-level robustness; validation frameworks.
- Improved termination policies and turn budgeting (software, UX)
- Use case: Optimize when to stop refining based on expected Pass_t gains, avoiding early termination and wasted turns.
- Potential tool/product: “Smart Termination Controller” predicting marginal gains, guided by model and domain.
- Assumptions/dependencies: Reliable gain estimation; telemetry; user tolerance for additional turns.
- Integration of checklist feedback into agent planning and tool use (software, robotics)
- Use case: Agents that turn unmet checklist items into tool calls (e.g., search, calculators, databases) to systematically satisfy criteria.
- Potential tool/product: “Checklist-to-Tool Planner” that maps criteria to tools and execution plans.
- Assumptions/dependencies: Tool reliability; safe execution; alignment of tools with criteria semantics.
- Large-scale benchmark-driven research on self-refinement failures (academia)
- Use case: Study patterns like repeated fixation on initially corrected aspects and design interventions to diversify exploration.
- Potential tool/product: “RefineBench Analytics Pack” with transition analyses, token usage, and domain breakdowns for research.
- Assumptions/dependencies: Expanded datasets; open metrics; reproducibility across vendors.
Notes on Feasibility and Dependencies
- Performance is highly sensitive to the presence and completeness of feedback; guided refinement outperforms self-refinement by large margins.
- Larger or proprietary LMs (>70B or frontier models) are currently required for near-perfect guided refinement; smaller open-weight LMs are less effective.
- Quality and availability of domain-specific checklists are essential; human validation improves reliability and acceptance.
- Evaluator dependence (e.g., GPT-4.1) introduces cost, latency, and vendor reliance; open evaluators are an active need for long-term sustainability.
- Multi-turn design matters: more tokens or more turns do not guarantee better self-refinement; termination and exploration strategies are an open research area.
- Safety, compliance, and human oversight are necessary, especially in law, healthcare, and finance; audit logging and final human review should be part of workflows.
Glossary
- Acc: Turn-specific accuracy measuring the fraction of checklist items satisfied; computed per instance at turn t. "Acc: This metric measures the ratio of correct checklist items among items per instance at turn "
- AIME-24: A mathematics competition benchmark (American Invitational Mathematics Examination, 2024 edition) used to test reasoning and refinement. "Strong LMs such as Claude-Sonnet-4 can self-refine effectively on AIME-24"
- Backtranslation: An automatic validation technique that translates content to another form and back to check consistency with the reference. "we employ an automatic filtering process using backtranslation with reference answers"
- Chains-of-thought: Explicit step-by-step reasoning traces generated by models during problem solving. "self-reflection patterns in their chains-of-thought"
- Checklist-based evaluation framework: A method that assesses responses using predefined binary criteria items. "a checklist-based evaluation framework"
- Concrete verification: A reasoning behavior where models validate their logic using specific examples or scenarios. "demonstrates a pronounced tendency toward self-correction/verification, concrete verification (generating specific examples or scenarios to validate its reasoning)"
- Cross-critique: A refinement approach where one model critiques another’s output to drive improvements. "extrinsic refinement via self-critique or cross-critique"
- Exact match: A verifiable task type where a response must match the correct answer exactly. "verifiable (exact match) and non-verifiable (free-form) tasks"
- Evaluator LM: A LLM dedicated to scoring responses against checklist criteria. "we use GPT-4.1 for the evaluator LM "
- Extrinsic refinement: Refinement driven by explicit, external feedback (e.g., critiques) rather than the model’s own initiative. "emphasizing extrinsic refinement via self-critique or cross-critique"
- Free-form generation tasks: Open-ended tasks requiring longer, unconstrained text outputs evaluated by qualitative criteria. "it incorporates both free-form generation tasks and tasks evaluated by answer correctness"
- Frontier LMs: The most capable, state-of-the-art LLMs available at a given time. "even frontier LMs such as Gemini 2.5 Pro and GPT-5 achieve modest baseline scores"
- Guided refinement: A setting where the model receives explicit feedback on what to fix in its previous response. "we evaluate two refinement modes: (1) guided refinement"
- Instruction-tuned LMs: Models fine-tuned to follow instructions across many tasks, typically without specialized reasoning traces. "Reasoning LMs typically self-refine better than instruction-tuned LMs"
- Intrinsic refinement: Refinement performed by the model itself without external feedback, relying on internal reasoning. "supports both extrinsic and intrinsic refinement settings"
- Multi-turn self-refinement: Iterative, repeated self-improvement of a response over several dialogue turns without external guidance. "struggled with multi-turn self-refinement"
- Non-verifiable tasks: Tasks evaluated qualitatively (e.g., essays) rather than by exact answer correctness. "verifiable (exact match) and non-verifiable (free-form) tasks"
- Open-weight LMs: Models whose parameters are publicly available for download and local inference. "both proprietary LMs and large open-weight LMs (70B)"
- Pass: A strict turn-specific metric assigning 1 only if all checklist items are satisfied at turn t; otherwise 0. "Pass: A strict metric of Acc at turn that assigns a score of 1 only if all checklist items are correct ()"
- Partially guided refinement: A setting where only some failed checklist items are revealed as feedback; the rest must be inferred by the model. "RefineBench supports a partially guided refinement setting as well"
- Reasoning LMs: Models designed to produce explicit reasoning (thinking) traces to improve problem-solving capability. "A new class of reasoning LMs... has emerged"
- Saturated benchmarks: Tasks on which models already achieve very high performance, leaving little room for improvement. "on saturated benchmarks such as MATH-500"
- Self-correction: A process where a model revises its own output by identifying and fixing errors over turns. "examines multi-turn self-correction on reasoning benchmarks such as GSM8K"
- Self-critique: A model’s practice of critiquing its own outputs to guide refinement. "extrinsic refinement via self-critique or cross-critique"
- Self-refinement: A setting where the model attempts to improve its own answer without receiving explicit guidance. "In the self-refinement setting, even frontier LMs such as Gemini 2.5 Pro and GPT-5 achieve modest baseline scores"
- Self-verification: A behavior where the model checks and validates its own reasoning or answers. "which allegedly self-verifies and self-refines its responses"
- Termination turn ratio: The distribution of turns at which models stop refining in the self-refinement setting. "Average termination turn ratio in self-refinement across 32 instruction-tuned and reasoning models."
- Test-time scaling: Increasing reasoning effort (e.g., tokens) at inference to improve performance on difficult tasks. "The test-time scaling strategy encourages LMs to engage in longer reasoning"
- Thinking mode: A model configuration that enables explicit, expanded reasoning traces during inference. "Qwen3-30B-A3B (thinking mode)"
- Transition analysis: Studying how correctness states (correct/incorrect) of responses change across consecutive refinement turns. "Transition analysis of the self-refinement capability of DeepSeek-R1 on RefineBench"
- Verbalized images: Visual data converted into detailed textual descriptions for model input and evaluation. "Total Verbalized Images"
- Verifiable tasks: Problems assessed by exact correctness of answers rather than qualitative criteria. "verifiable (exact match) and non-verifiable (free-form) tasks"
Collections
Sign up for free to add this paper to one or more collections.

