- The paper shows that a universal quantization codebook achieves near-optimal distortion with a maximum overhead of 0.11 bits per coordinate compared to waterfilling.
- It employs random coding with isotropic Gaussian codewords and concentration inequalities to guarantee uniform performance over all activation covariances.
- The findings imply that hardware designs and quantization algorithms can achieve nearly optimal rate-distortion tradeoffs without relying on ΣX-adaptive waterfilling.
Authoritative Summary: "Price of Universality in Vector Quantization is at most 0.11 bit" (2602.05790)
Motivation and Context
Vector quantization of neural network weights is central to efficient deployment of large-scale models, including LLMs. The process of converting full-precision weights W to low-precision representations W^ enables substantial reductions in storage and communication costs. Crucially, optimal quantization is dependent on data statistics: the degradation measured by W⊤X−W^⊤X is tightly coupled to the statistical properties of the activation vector X, specifically its covariance ΣX. Classical results show that adapting the quantization codebook to the principal directions (PCA) of X—a strategy referred to as "waterfilling allocation"—substantially improves the rate-distortion tradeoff. However, in hardware implementations, the codebook must be universal, i.e., independent of ΣX. This paper investigates the information-theoretic gap between such universal quantization and ΣX-aware waterfilling.
Main Contributions
The fundamental scenario is weight-only quantization under the Hilbert metric dΣX(W,W^)=(W−W^)⊤ΣX(W−W^), with W∼N(0,In). Codebooks of size 2nR enable encoding at R bits per coordinate. When ΣX is known to both encoder and decoder, the optimum distortion-rate tradeoff is achieved by waterfilling—allocating quantization resolution along the principal axes according to the eigenstructure Λ of ΣX (see Prop. {oracle_wf}). The challenge is to construct a codebook C whose performance is uniformly near-optimal across all possible ΣX.
Existence of Universal Codebook with Constant Rate Gap
The principal result (Theorem {union}) asserts that there exists a universal codebook C of rate R such that, for any ΣX∈S+n, the distortion attained is at most the waterfilling-optimal distortion at rate R−0.11 bits per coordinate. Equivalently, for any desired distortion D, the rate gap Runiv−Rwf is bounded by $0.11$ bits per coordinate.
Tight Upper Bound on Universality Cost
Through explicit random coding analysis and numerical extremal computations (see Section {worst_case}), the worst-case rate gap between universal random-coding and oracle waterfilling is calculated and shown not to exceed $0.11$ bits. The hardest cases are spectrally unbalanced covariance matrices, yet even there the gap remains uniformly bounded.
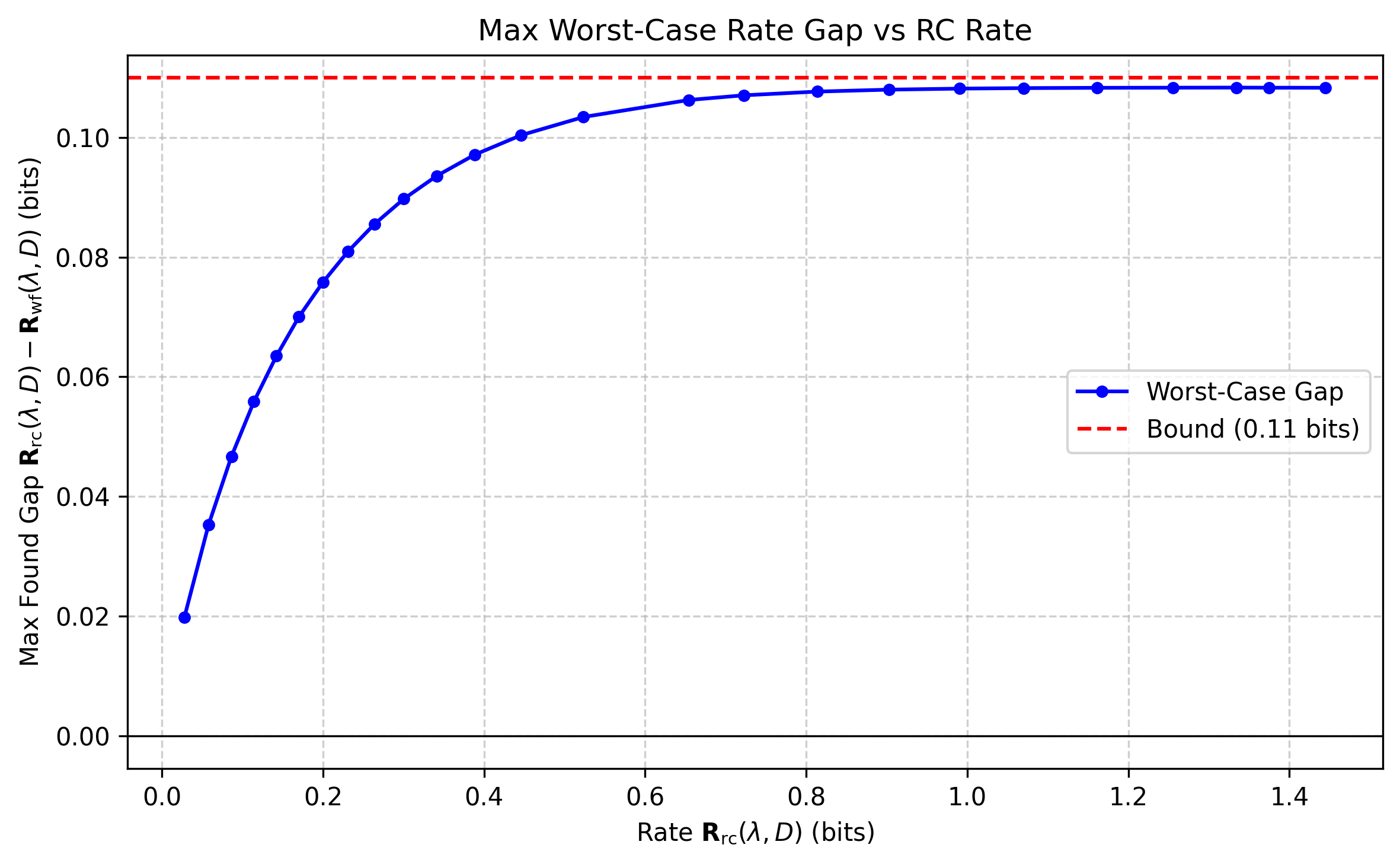
Figure 1: Maximum rate gap found numerically at each R=R(λ,D), demonstrating the upper bound of $0.11$ bits for all spectra.
Technical Approach
The universal codebook existence proof is non-constructive and relies on random coding with isotropic Gaussian codewords. The encoder, equipped with knowledge of ΣX, selects an optimal scaling parameter τ(ΣX,R) for codebook vectors, with negligible overhead for communicating τ. The encoder then searches for the nearest codeword under dΣX. Performance analysis employs large deviations estimates and concentration inequalities to show high-probability codebook success across all ΣX. Covering arguments for the space of covariance matrices ensure uniformity.
Notably, for "semi-flat" spectra—covariances with a subset of equal eigenvalues and remainder zero—the universal codebook achieves exactly waterfilling performance, with the rate gap only arising in spectrally diverse cases. The universality cost is thus concentrated in non-flat, non-rank-1 ΣX.
Comparison to Lattice Quantizers
Lattice quantization algorithms (e.g., GPTQ) are optimal for fixed norms but fail to be near-optimal simultaneously for all ΣX due to their reliance on fixed basis; rotations yield suboptimal alignments. The rate gap for lattices can be at least $0.254$ bits for some ΣX, far above the $0.11$ bit upper bound for universal random coding. This sheds light on the limitations of practical quantization schemes relying solely on lattice structures.
Numerical and Analytical Verification
The supremum rate gap was analyzed over spectra with up to five distinct eigenvalues. The computational sweep confirmed the $0.11$ bit bound. Spectra with equal eigenvalues (identity or rank-1) have exactly zero gap. The largest overhead appears for extremal distributions of the spectrum, confirming the analytical predictions.
Practical and Theoretical Implications
- Hardware Design: It's feasible to implement a ΣX-oblivious (universal) codebook with minimal overhead relative to optimally tuned waterfilling quantization. This guarantees almost optimal quantization performance irrespective of the activation statistics encountered in downstream tasks.
- Theory of Quantized Inner Products: The existence of universal nets simultaneously covering spheres in all Hilbert norms advances both rate-distortion theory and geometric analysis of high-dimensional quantization.
- Algorithmic Limitations: The proof is existential and non-constructive; explicit efficient universal codebook construction remains an open research problem. Practical quantization schemes should incorporate approaches beyond classical lattices to approach the $0.11$ bit universality bound.
- Implications for Post-Training Quantization: Existing methods that calibrate to activation statistics may perform well but incur hardware complexity. Universal algorithms can approach theoretical limits with simpler deployment.
The results also connect to the additive rate-distortion function for quantizing colored sources, and directly generalize classical Shannon bounds for vector quantization under quadratic loss.
Directions for Future Research
- Analytic characterization of spectra achieving maximal universality gap, potentially tightening the $0.11$ bit bound.
- Constructive universal codebook design, possibly with efficient encoders/decoders and explicit scaling distributions.
- Extensions to quantization of matrix multiplication with nested codebooks, and further analysis in settings with partial side-information.
- Investigation of implications for weight quantization in transformer architectures, especially considering low-rank activation statistics and spectral diversity.
Conclusion
This paper establishes an information-theoretic upper bound of $0.11$ bits per coordinate on the universality penalty in vector quantization for neural network weights, showing that a universal codebook is almost as efficient as optimally tuned waterfilling quantization for any possible activation covariance ΣX. The results clarify theoretical limits of low-precision weight encoding in large-scale models and expose new avenues for robust, near-optimal quantization design, both in theory and in hardware practice.

