Foundations of Vector Retrieval
Abstract: Vectors are universal mathematical objects that can represent text, images, speech, or a mix of these data modalities. That happens regardless of whether data is represented by hand-crafted features or learnt embeddings. Collect a large enough quantity of such vectors and the question of retrieval becomes urgently relevant: Finding vectors that are more similar to a query vector. This monograph is concerned with the question above and covers fundamental concepts along with advanced data structures and algorithms for vector retrieval. In doing so, it recaps this fascinating topic and lowers barriers of entry into this rich area of research.
- QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks (2024)
- Searching in one billion vectors: re-rank with source coding (2011)
- Bolt: Accelerated Data Mining with Fast Vector Compression (2017)
- RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search (2024)
- Vector and Line Quantization for Billion-scale Similarity Search on GPUs (2019)
- Quantization based Fast Inner Product Search (2015)
- QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead (2024)
- Reducing the Footprint of Multi-Vector Retrieval with Minimal Performance Impact via Token Pooling (2024)
- Lossless Compression of Vector IDs for Approximate Nearest Neighbor Search (2025)
- Faster Linear Algebra Algorithms with Structured Random Matrices (2025)
Summary
- The paper introduces novel quantization and sketching methods to reduce memory footprint while accelerating high-dimensional vector retrieval.
- It details structured approaches like product, optimized, and additive quantization, balancing accuracy with computational cost.
- It analyzes sketching strategies, including JL transforms and importance sampling, to maintain efficient approximations in large-scale systems.
Vector Compression and Sketching for Efficient Vector Retrieval
Introduction
The "Foundations of Vector Retrieval" monograph dedicates significant attention to the storage and computational efficiency challenges associated with large-scale vector databases, especially in high dimensions. The compression and sketching chapters present a comprehensive theoretical and algorithmic treatment of data-oblivious and data-driven methods for reducing memory footprint and computational cost, with a focus on quantization and sketching as primary paradigms for vector representation compression. This essay presents an in-depth synthesis of the design, properties, and analysis of such techniques as described in the monograph, with attention to consequences for retrieval systems, scalability, and new research opportunities.
Quantization as Structured Vector Compression
Quantization is introduced as an extension of clustering-based retrieval, formalizing the assignment of vectors to compact codebooks that capture data geometry in a lossy fashion. Letting ζ:Rd→[C] denote a quantizer, all data vectors assigned to cluster i are approximated by codeword μi, leading to a compressed storage model with asymptotic size O(Cd+mlog2C) for a collection of m vectors. This enables computation of point-to-query distances via inexpensive table lookups, rather than brute-force evaluation.
The reconstruction error for a codebook is the mean squared error E[∥μζ(U)−U∥22], which directly connects quantization to Lloyd-optimal KMeans clustering, guaranteeing asymptotic minimization of the quantization distortion under standard conditions. This establishes vector quantization as a theoretically sound approach for isotropic L2 or L1 spaces.
Product Quantization (PQ) further decomposes the ambient space into L orthogonal subspaces via selector matrices Si∈{0,1}d∘×d (with d=Ld∘). Per-subspace quantizers ζi independently assign block Siu of a vector u to one of C centroids μi,j. The PQ-reconstructed vector is
u~=i=1⨁Lμi,ζi(Siu)
and the overall quantization error is the sum of per-block cluster distortions due to orthogonality. For queries q, distances to codewords can be precomputed for each subspace and individually summed, yielding a quantized lookup cost of O(LCd∘+mL) for m database vectors and codebook size L×C×d∘.
This structure enables storage of massive databases with modest accuracy loss (e.g., PQ code sizes as small as 8-16 bytes per vector for d=128), and allows asymptotic scaling far beyond what explicit or coarse quantization enables. PQ can be augmented with coarse quantization (clustering), residual quantization, or memory/disk-aware optimizations to further enhance efficiency.
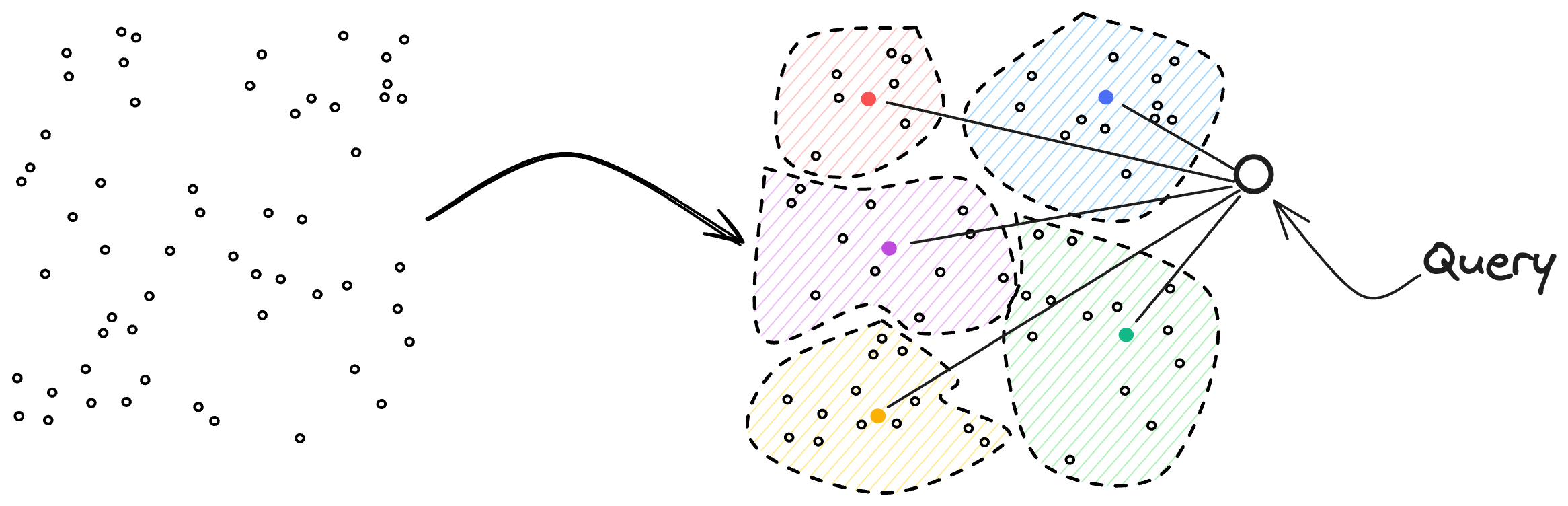
Figure 1: Illustration of the clustering-based retrieval method, highlighting cluster assignment and table lookup.
PQ's extension, Optimized Product Quantization (OPQ), relaxes the axis-aligned decomposition by learning an orthogonal rotation matrix R to mahimize entropy of each subspace, via alternating minimization of the codebook assignment and the rotation. Subsequent advances, such as Locally Optimized Product Quantization and Composite Quantization, offer further reductions in distortion at increased computational cost.
Additive Quantization: Increased Representational Power
Additive Quantization (AQ) generalizes PQ by dispensing with subspace constraints, designing L codebooks of full-dimensional (Rd) codewords. Each vector is represented as a sum of L codewords, one per codebook (u~=∑i=1Lμi,ζi(u)). AQ contains PQ as a special case, as block-diagonal codebooks induce independent subspaces. In practice, AQ can achieve lower distortion per bit at the expense of a more expensive encoding process, typically solved via beam search or heuristic methods.
Distance computations for AQ require precomputing all inner products between query vectors and codewords, as well as codeword codeword pairs because of the non-orthogonal structure. This increases cache requirements but still allows efficient lookup-based evaluation.
Quantization for Inner Product Search
Classical quantization is fundamentally isotropic and thus best suited for L2 nearest neighbor retrieval. However, for MIPS and applications with highly anisotropic query distributions, Eq[qqT] may deviate drastically from a multiple of the identity. Directly minimizing Eq[(⟨q,u⟩−⟨q,u~⟩)2] reduces to a Mahalanobis distance minimization problem, as highlighted by [guo2016Quip], but in practice, precise estimation of this objective is costly without many training queries.
A score-aware quantization approach is proposed by [scann], replacing the uniform weighting of all vectors in X with a weighting function ω that upweights database points that are likely to maximize ⟨q,u⟩, ideally putting dominant mass on expected maximizers. The loss decomposes as
ℓ(u,u~,ω)=Eq[ω(⟨q,u⟩)(⟨q,u−u~⟩)2]
and, for spherically symmetric query distributions, admits separation into parallel and orthogonal components with respect to u. For large d, the parallel (norm) distortion dominates, implying that accurate preservation of codeword norms is more critical for high-probability MIPS error minimization than angular deviation, unless the data distribution is nearly magnitude-homogeneous.
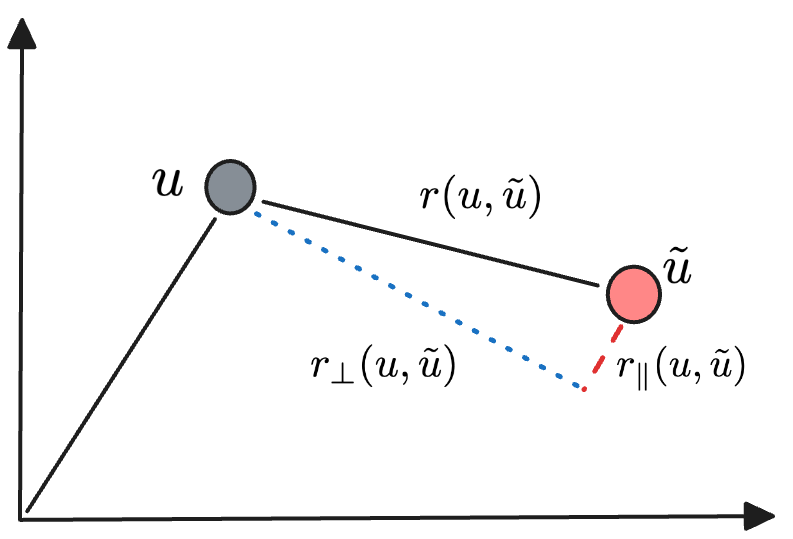
Figure 2: Decomposition of the residual error r(u,u~) into parallel and orthogonal components, relevant to different error contributions under MIPS.
This insight leads to codebooks optimized for weighted reconstruction errors or minimum parallel (norm) variance, and can be extended with learned query-dependent weights or codebooks [queryAwareQuantization], producing superior code utilization and retrieval accuracy.
Sketching: Oblivious Dimensionality Reduction
Linear Sketches via JL Transforms
Oblivious linear sketching, as typified by Johnson-Lindenstrauss (JL) transforms, projects vectors u∈Rd to ϕ(u)=Ru for random R∈Rd∘×d, d∘=O(ε−2logm). When R is appropriately designed (e.g., Gaussian or Rademacher), inner products and L2 distances are preserved with additive error O(ϵ) with high probability. The variance of the estimator for ⟨u,v⟩, as analyzed in the monograph, scales as O(1/d∘)(∥u∥22∥v∥22+⟨u,v⟩2−2∑ui2vi2). For highly sparse vectors, the error is tolerable, but for dense high-dimensional data, the norm terms dominate and higher d∘ (hence larger sketches) are required.
Asymmetric Sketches
For sparse or streaming settings, [bruch2023sinnamon] proposes asymmetric sketches, storing, for each data vector, the set of nonzero coordinates' indices and per-hash upper/lower bounds of nonzero values across codewords. For a query q, sparse or not, the asymmetric computation yields an upper bound on ⟨q,u⟩ by selecting the minimal upper-bounded value for each hashed nonzero coordinate, enabling aggressive filtering of data points in retrieval while ensuring recall. The overestimation error is theoretically characterized via the collision statistics of the hash maps and the distribution tails of active vector entries.
Figure 2: Decomposition of the residual error r(u,u~) for parallel and orthogonal analysis in sketching.
Additionally, when applied in streaming environments, such sketches remain robust and incrementally updatable without requiring retraining or codebook relearning.
Importance-Sampled Sketches
[daliri2023sampling] further presents importance/geometric sampling sketches tailored to preserve inner products. Each coordinate i of u is included in the sketch with probability proportional to ui2/∥u∥22, ensuring that coordinates with highest energy are favored, which aligns with inner product concentration. The sketch comprises the indices and values of selected coordinates (plus the squared norm), and an unbiased estimator for ⟨u,v⟩ is computed by scaling by selection probabilities. The variance of the estimator decays as O(1/d∘) and has a dependence on the intersection sparsity of u and v, favoring data distributions with significant overlap structure.
Performance, Tradeoffs, and Implementation Considerations
Complexity and Resource Footprint
Product quantization and its derivatives offer practically minimal database sizes, with entire codes fitting into cache or even L2 RAM for large m at O(few bytes) per vector. Lookup-based distance evaluation with precomputed codeword tables permits effective SIMD acceleration and vectorization, as exploited by [pqWithGPU, Andre_2021]. Both quantization and sketching can be batched, pipelined, and combined with hierarchical index structures (inverted files, multi-indexes) for further speedups.
Sketching techniques, particularly for sparse data, are tractable for streaming and distributed environments, as sketches can be computed online or in parallel with minimal coordination overhead and no codebook storage. Threshold sampling and asymmetric sketches can be implemented using fixed-size hash maps or Bloom-filtered arrays, providing robust error controls and near-constant-time updates.
Approximation and Error Analysis
Theoretical bounds on recall, error, and convergence rates for quantization and sketching are mathematically characterized, with key dependencies on sketch/quantization size (d∘, C, L), data sparsity, codebook orthogonality, and alignment of query–database distributions. For MIPS, failure to preserve norm information can yield catastrophic errors (selecting high-norm but misaligned vectors). In such cases, score-aware or residual-enhanced quantizers are required.
Quantization-based approaches may require retraining when the underlying data distribution drifts or if query statistics change, whereas oblivious sketches retain their approximation guarantees.
Conclusion
The comprehensive analysis and unification of vector compression and sketching in the "Foundations of Vector Retrieval" monograph provide a critical theoretical and algorithmic toolkit for realizing scalable, resource-efficient, and robust vector retrieval systems. Product quantization and its extensions balance memory and accuracy in static high-dimensional settings, while sketching affords adaptive, streaming-compatible approximations with quantifiable error and resilience. The formalization of MIPS-specific loss and score-aware quantization objectives addresses prior limitations and better aligns with practical workloads in modern retrieval systems (e.g., large-scale ANN, embedding-based search, neural ranking).
Future developments will likely emphasize learned quantizaton tailored to structured and dynamic data distributions, tighter theoretical analysis of streaming sketches in adversarial settings, and the integration of sketching-quantization hybrids to leverage the strengths of both paradigms for emerging modalities and retrieval demands.
Paper to Video (Beta)
No one has generated a video about this paper yet.
Whiteboard
No one has generated a whiteboard explanation for this paper yet.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Open Problems
We're still in the process of identifying open problems mentioned in this paper. Please check back in a few minutes.
Continue Learning
- How do the proposed quantization methods specifically reduce computational costs in vector retrieval?
- What are the advantages of using product quantization over additive quantization in this context?
- How does score-aware quantization improve performance in Maximum Inner Product Search (MIPS)?
- What trade-offs emerge when employing linear sketching versus asymmetric sketching for high-dimensional data?
- Find recent papers about efficient vector retrieval systems.
Collections
Sign up for free to add this paper to one or more collections.
Tweets
Sign up for free to view the 28 tweets with 1373 likes about this paper.
HackerNews
- Foundations of Vector Retrieval (2 points, 0 comments)
- Foundations of Vector Retrieval (Sebastian Bruch) (2 points, 0 comments)
- Foundations of Vector Retrieval (1 point, 0 comments)