- The paper introduces an orthogonality regularization framework to distinctly recover intervenable features and reduce superposition in sparse autoencoders.
- It employs a two-step fine-tuning process that first constrains the decoder and then adapts the language model to enhance feature disentanglement.
- The study confirms that increasing the orthogonality penalty boosts interpretability and eases controlled feature intervention, improving model robustness.
Identifying Intervenable and Interpretable Features via Orthogonality Regularization
Introduction
The paper "Identifying Intervenable and Interpretable Features via Orthogonality Regularization" (2602.04718) offers an approach to enhance the identifiability and interpretability of features in sparse autoencoder (SAE) models applied to LMs. By imposing orthogonality regularization on the decoder matrix, the method seeks to reduce feature interference and superposition, aiding the recovery of unique and intervenable components in learned representations.
Identifiable Dictionary Learning
The central thesis of the paper revolves around the identifiability of dictionary learning, a principle that concerns the recovery of unique feature sets from data represented as sparse combinations of these features. The core concept of self-coherence, pivotal in ensuring accurate sparse recovery, is defined as the maximum similarity between atoms in a dictionary. The paper asserts that ensuring low self-coherence (i.e., near orthogonality) among dictionary atoms guarantees the uniqueness of feature decomposition and sparse representations, aligning with classical dictionary learning theories [donoho2005stable].
This orthogonality approach is extended to LLM feature dictionaries, addressing challenges posed by inherent structural dependencies in LM activations that foster high self-coherence naturally, complicating identifiability.
Orthogonality Regularization
Orthogonality regularization is introduced as an empirical solution to improve the modularity and causal interpretability of sparse autoencoders. By penalizing the lower triangular elements of the decoder matrix during training, thereby encouraging near orthogonal features, the model is expected to enhance the distinctness and separation of latent features.
Experimental Validation
The study exercises a two-step fine-tuning process: first regularizing an SAE decoder within the LM architecture on a specified penalty λ, and subsequently adapting the LM parameters around this constrained SAE using methods like LoRA [hu2021lora]. The empirical analysis showcases that increasing λ reduces orthogonality loss, confirming the intended architectural improvement.
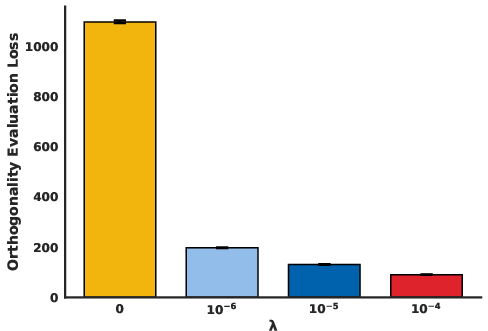
Figure 1: Orthogonality Evaluation Loss We plot the orthogonality loss $\|tril({^ {)\|_F^2$ for all values of λ.
Intervenability and Interpretability
Orthogonality is posited to improve interpretability without compromising on performance. By achieving feature disentanglement and reducing mating features in the activation space, this approach aligns feature representations closer to human-understandable concepts. The experiments provide evidence for consistent interpretability scores with varying λ, demonstrating that introducing orthogonality constraints does not negatively impact interpretability relative to unregularized models.
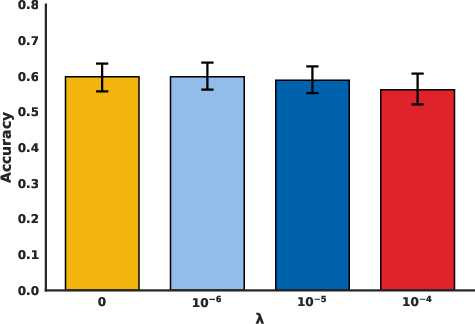
Figure 2: Evaluation on GSM8K We evaluate on the GSM8K test set.
Furthermore, the paper explores intervenability, a concept referring to the ease of manipulating individual features within a model without affecting others. The ICM principle emphasizes maintaining the autonomy of causal mechanisms, serving as a backdrop to argue for the localized manipulation capabilities enhanced by orthogonality. Predictably, higher orthogonality penalties facilitate easier intervention, allowing controlled feature swaps and increasing potential practical applications of such models.
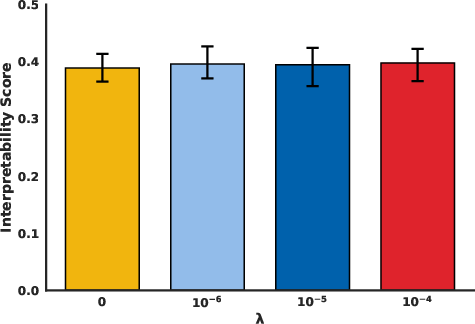
Figure 3: Interpretability Score We plot the interpretability score of correctly identifying one out of five examples.
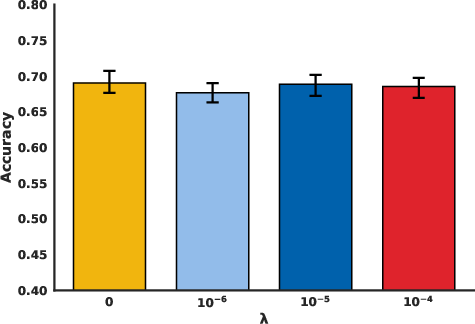
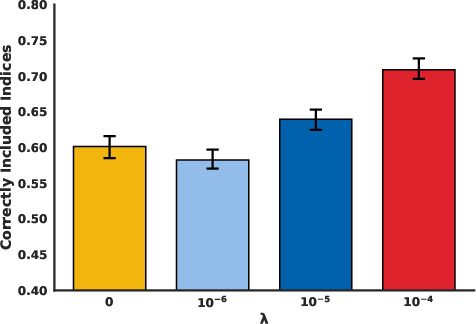
Figure 4: Evaluation on Mathematical Reasoning We plot mathematical reasoning performance on 3960 hand-designed examples after intervening on the SAE.
Discussion
The theoretical and practical implications of this work suggest substantial advancements in enhancing the modular representation and causal inference of LLMs. The study delineates possibilities for applying these findings across a variety of datasets and tasks beyond mathematical reasoning, considering expansion to generalized language understanding and sequencing tasks.
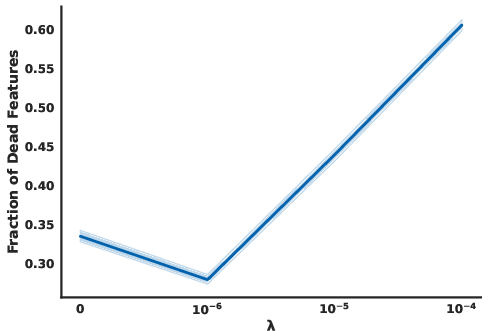
Figure 5: Dead Features We plot the fraction of dead features with increasing orthogonality penalty.
Conclusive remarks propose orthogonality regularization as a promising approach to mitigate limitations of feature superposition, manifested in phenomena like adversarial vulnerability within LMs. This architectural adjustment is hence positioned as a pathway toward building safer, more robust models optimized for identifiability.
Conclusion
The orthogonality regularization framework significantly augments the interpretability and intervenability prospects of LLMs integrated with sparse autoencoders. It presents a formidable step towards resolving superposition conflicts and identifying canonical features across large datasets. The approach promises enhanced modularity in learned representations, offering a strategic advantage in the ever-evolving landscape of AI-driven discovery.