- The paper introduces MP-SAE, which leverages a residual-guided matching pursuit algorithm to iteratively capture hierarchical and multimodal sparse features.
- The MP-SAE architecture outperforms traditional SAEs by achieving higher reconstruction (R²) and Babel scores while preserving feature structure.
- Empirical results demonstrate MP-SAE's adaptive inference-time sparsity and effective extraction of complex, nonlinear representations from both synthetic and pretrained data.
Overview
The paper introduces a novel sparse autoencoder (SAE) architecture, the MP-SAE, which extends the classical Matching Pursuit (MP) algorithm to capture hierarchical, nonlinear, and multimodal features in neural networks. This approach diverges from the Linear Representation Hypothesis (LRH) that enforces globally quasi-orthogonal representations, highlighting limitations of traditional SAEs in capturing conceptual structures like hierarchy and modality-independent features.
Sparse Autoencoders and Linear Representation Hypothesis
SAEs, motivated by the LRH, aim to decompose neural network representations into a set of sparse, approximately orthogonal features. Under LRH, a representation x is decomposed as x=zD, where D is an overcomplete dictionary of size p≫m, with quasi-orthogonal columns, and z is a sparse coefficient vector. This setup, which emphasizes linear accessibility of features, has facilitated interpretability in vision and LLMs but fails to accommodate non-linear or hierarchical structures observed in recent empirical studies (Figure 1).
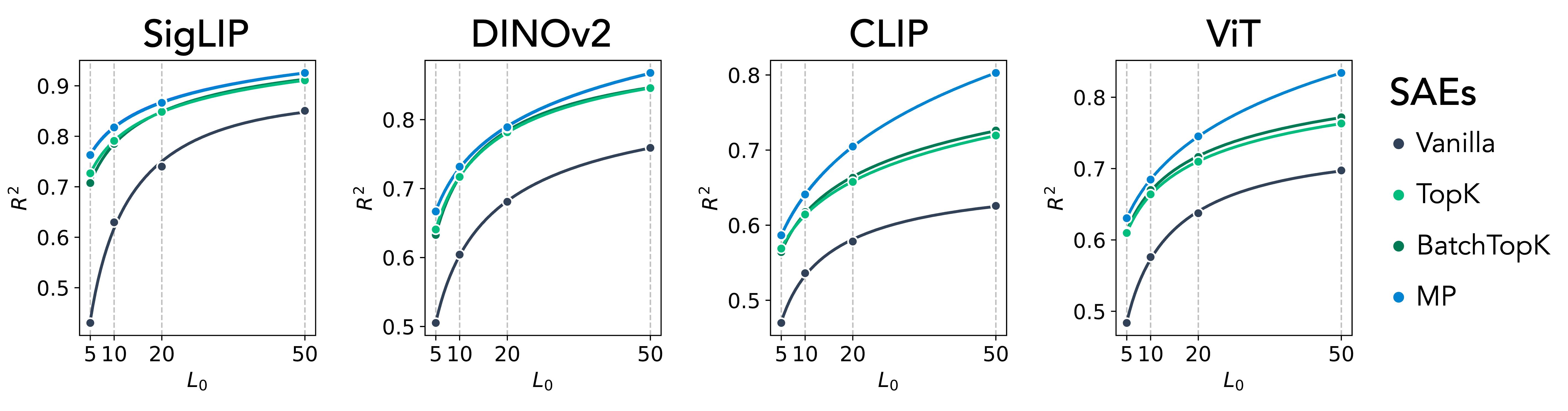
Figure 1: MP-SAE recovers more expressive features than standard SAEs. Reconstruction performance (R2) as a function of sparsity level across four pretrained vision models: SigLIP, DINOv2, CLIP, and ViT. MP-SAE consistently achieves higher R2 at comparable sparsity, indicating more efficient and informative decompositions.
Architectures and Conditional Orthogonality
MP-SAE unrolls its encoder into a sequence of residual-guided steps, promoting conditional orthogonality—orthogonalizing representations only across different hierarchical levels, and thus capturing complex structures beyond LRH's scope. This method iteratively selects features that are orthogonal to what has already been explained, fostering a conditionally orthogonal structure that is naturally hierarchical and multimodally aligned.
Matching Pursuit Sparse Autoencoder (MP-SAE)
MP-SAE's distinctive feature is its ability to sequentially explain input representations through iterative updates, leveraging residual-based greedy selection of features. This process not only fosters conditional orthogonality but also uniquely uncovers higher-order features which are inherently nonlinearly accessible. In this sequential setup, MP-SAE shows consistent performance improvements in capturing both intra- and inter-level feature correlations better than traditional SAEs.

Figure 2: MP-SAE promotes conditional orthogonality at inference. Babel scores for full dictionaries (top) and co-activated subsets (bottom). MP-SAE dictionaries exhibit higher global coherence than standard SAEs, but select more separated features at inference.
Empirical Evaluations
Synthetic Data
MP-SAE outperforms conventional SAEs in synthetic datasets designed to test hierarchical representation capture. It maintains hierarchical structures while also capturing intra-level correlations, a task where traditional architectures fail due to feature absorption.
Pretrained Model Representations
- Expressivity: MP-SAE achieves higher R2 scores across multiple models, indicating superior feature extraction efficiency.
- Coherence: Uses Babel score to exhibit its ability to construct coherent but non-interfering feature sets at inference time.
- Adaptive Inference-Time Sparsity: The monotonically decreasing reconstruction error with an increasing number of active features at inference time distinguishes MP-SAE's flexibility from traditional methods.
- Multimodal Features: In vision-LLMs, MP-SAE successfully identifies and aligns shared concepts between modalities (Figure 3).
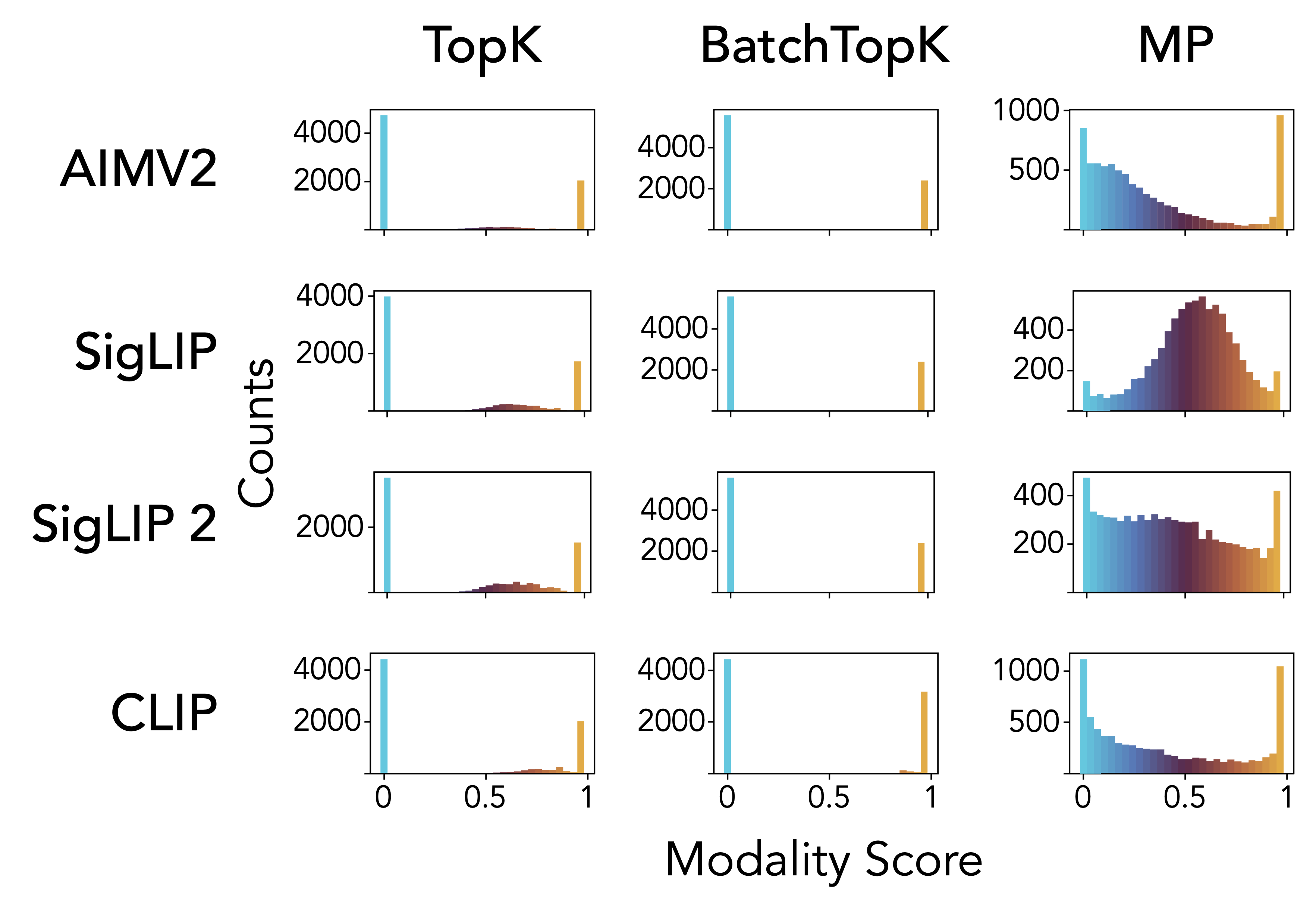
Figure 3: Distribution of modality scores for features learned by different SAEs, across four vision-LLMs: CLIP, SigLIP, SigLIP2, and AIMv2. In contrast, MP-SAE yields a significantly flatter distribution with substantial density near 0.5, revealing genuinely multimodal features.
Conclusion
The introduction of MP-SAE highlights the architectural enhancements required to interpret complex nonlinear structures in neural representations effectively. Beyond traditional linear assumptions, MP-SAE explores the field of adaptive, dynamically sparse inference, offering theoretical support and practical benefits in recovering richly structured features. The results suggest novel interpretability avenues that more closely reflect the inherent hierarchical and nonlinear nature of learned representations. This work initiates further exploration into enhancing logical coherence and explainability of AI systems, crucial for their deployment in diverse, sensitive domains.
