- The paper identifies an amortisation gap in sparse autoencoders, highlighting the performance shortfall between learned encoders and optimal sparse inference.
- It compares various methods, showing that SAE+ITO and MLPs can improve inference efficiency by incorporating optimization at inference time.
- Experimental results demonstrate that sparse coding achieves higher accuracy and better interpretability across diverse data regimes.
Compute Optimal Inference and Provable Amortisation Gap in Sparse Autoencoders
Introduction
The exploration of sparse autoencoders (SAEs) as a means of enhancing interpretability in neural network representations remains a prominent area of inquiry in machine learning. This paper examines the limitations of traditional SAE approaches, particularly focusing on their inadequacy to perform accurate sparse inference due to computational constraints inherent in their linear-nonlinear encoding mechanism. By leveraging sparse coding techniques, the investigation seeks to evaluate and improve sparse inference capabilities, particularly in LLMs.
Sparse Representations and Superposition
Sparse representations in neural networks are characterized by activation patterns involving only a small subset of neurons, offering enhanced interpretability and efficiency. SAEs and sparse coding techniques aim to map input data into such sparse latent spaces. However, sparse coding involves solving an optimization problem for individual inputs, while SAEs rely on a learned encoding function, potentially compromising on optimal sparsity due to computational efficiency.
The concept of superposition suggests that neural networks can represent multiple features in fewer dimensions, often exceeding the number of orthogonal vectors that can fit in a space. This is predicated on the network's ability to leverage non-orthogonal directions when representing features, which may lead to complex, overlapping feature interactions.
Amortisation Gap in Sparse Autoencoders
In this study, the authors identify the "amortisation gap," which is the performance shortfall of SAEs compared to an optimal sparse inference solution due to architectural limitations in the encoder. Despite the theoretical possibility of optimal sparse recovery from lower-dimensional representations, SAEs employing linear-nonlinear encoders fall short of achieving this due to inadequate computational complexity.
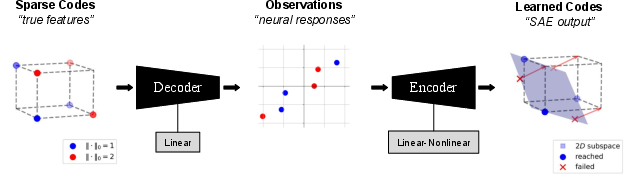
Figure 1: Illustration of SAE Amortisation Gap. Left shows sparse sources in a 3-dimensional space with constraints. Middle exhibits the linear decoding of sources into observation space. Right demonstrates the encoder's task of projecting points, which the SAE fails to execute optimally.
Experimental Analysis and Results
Empirical evaluations leverage synthetic datasets with known ground-truth features, examining various sparse encoding strategies including: standard SAEs, MLPs, traditional sparse coding, and an innovative SAE approach with inference-time optimization (SAE+ITO). These methods are evaluated based on their alignment with true sparse features and computational efficiency.
- Known Sparse Codes: MLPs outperform SAEs by achieving higher Mean Correlation Coefficient (MCC) values, despite requiring more computational resources.
- Known Dictionary: When the dictionary is known, MLPs demonstrate superior performance over SAEs, though SAE+ITO achieves the highest MCC by incorporating optimization at inference time.
- Unknown Sparse Codes and Dictionary: Sparse coding outperforms the other approaches in both latent prediction and dictionary learning, underscoring its effectiveness in diverse scenarios.
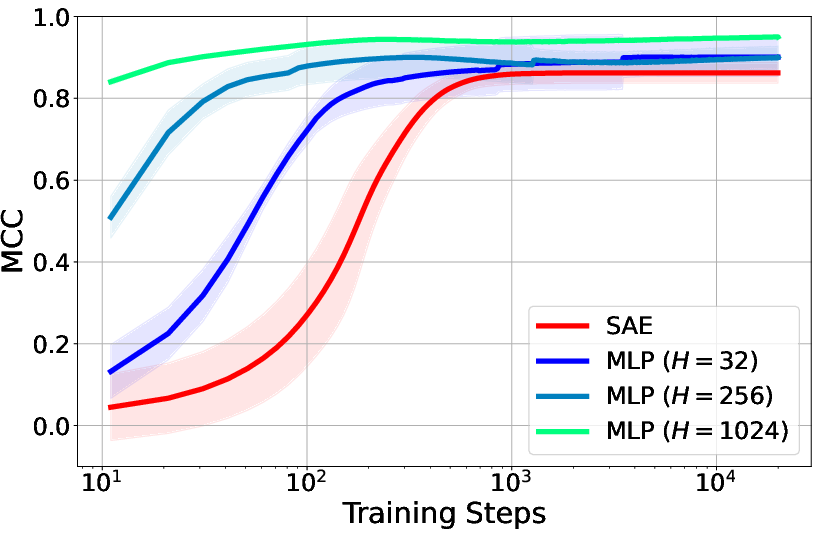
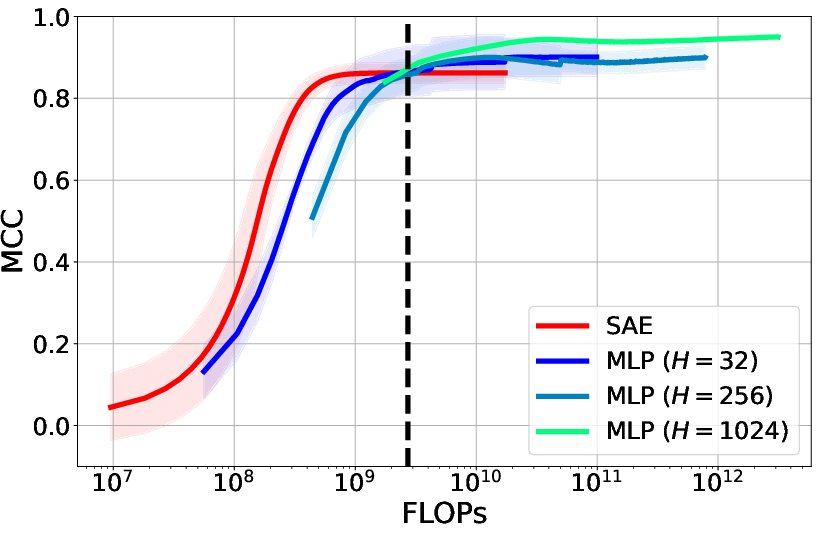
Figure 2: MCC vs. training steps showcasing the performance of different encoding strategies.
The study explores varying data regimes by manipulating dimensions and active components in latent representations. Sparse coding consistently exhibits superior performance across regimes that align with theoretical predictions of recoverability, reaffirming its utility in sparse inference challenges.
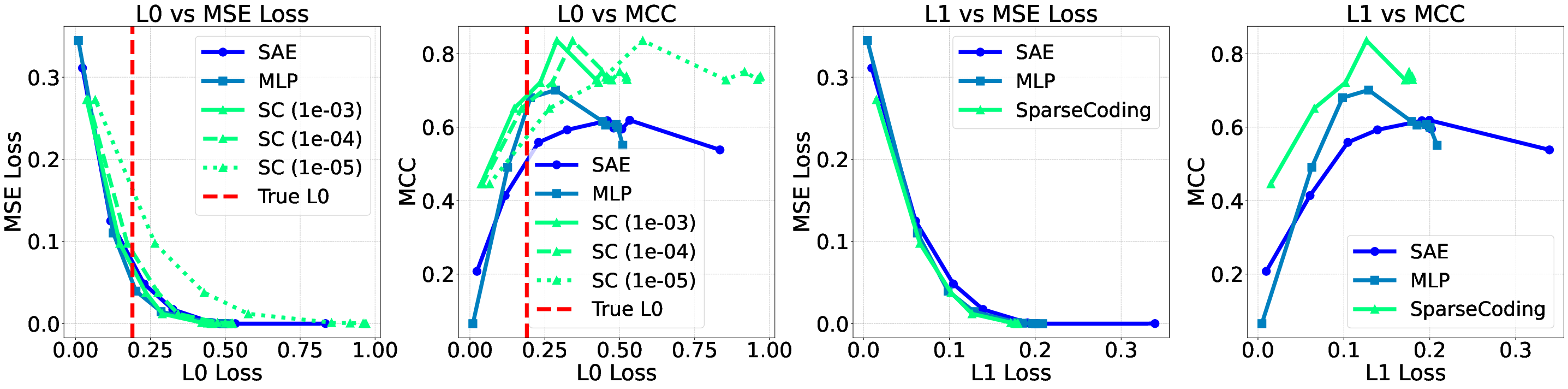
Figure 3: Pareto curves illustrating trade-offs between sparsity and performance across different models and loss functions.
Implications and Future Directions
The results underscore the significance of sophisticated encoding techniques, such as MLPs and sparse coding, in achieving better interpretability without sacrificing feature validity. These findings suggest potential avenues for enhancing representation extraction in LLMs and other complex neural architectures.
The limitations of current SAE approaches highlight the need for more refined models that address amortisation gaps. Future research should focus on optimizing these models, exploring hybrid approaches like top-k sparsity, and examining their application to larger, more intricate models.
Conclusion
The analysis provides substantial evidence of the inherent limitations in traditional sparse autoencoders due to amortisation gaps, especially in high-stakes applications involving large-scale neural networks. By applying more sophisticated inference techniques, researchers can achieve not only better performance but also maintain or improve the interpretability of complex neural models. The continued exploration and refinement of these techniques are crucial for advancing our understanding and utility of neural network representations in practical applications.