- The paper demonstrates that sparse autoencoders can decompose LLM activations into human-interpretable reasoning features.
- It introduces ReasonScore, a novel metric with an entropy penalty, to quantify the link between reasoning-related vocabulary and model activations.
- Steering experiments show that enhancing identified reasoning features improves performance on benchmarks by up to 13.4%.
Interpretability of Reasoning Features in LLMs via Sparse Autoencoders
Introduction
The paper "I Have Covered All the Bases Here: Interpreting Reasoning Features in LLMs via Sparse Autoencoders" (2503.18878) tackles the challenge of unraveling the internal reasoning processes of LLMs. Despite the remarkable advances in LLM capabilities, particularly in structured reasoning and problem-solving, the mechanistic underpinnings of these processes remain largely opaque. The authors employ Sparse Autoencoders (SAEs) to disentangle LLM activations into human-interpretable features and introduce a novel metric, ReasonScore, to identify features active during reasoning. Their work seeks to bridge the gap between LLM output and the internal processes facilitating complex reasoning.
Methodology
Sparse Autoencoders for Feature Decomposition
SAEs serve as the cornerstone of the research, enabling the decomposition of LLM activations into sparse, interpretable components. This approach presumes that reasoning processes can be mapped onto specific activation patterns within the model. The authors leverage SAEs to make sense of these activation patterns, hypothesizing that words commonly associated with human reasoning, such as "perhaps" or "alternatively", correspond to salient features in the model's activation space.
Development and Use of ReasonScore
The introduction of ReasonScore represents a pivotal advancement in quantifying the activity of reasoning-related features. This metric evaluates the degree to which specific SAE features correlate with a predefined vocabulary of reasoning words. ReasonScore incorporates an entropy penalty to ensure that activated features are not only frequent but also diverse across contexts, enhancing interpretability.
Experimental Validation and Steering
To validate their approach, the authors conduct both manual and automatic interpretation experiments on identified features. Steering experiments further reveal that amplifying reasoning features correlates with enhanced performance on reasoning-intensive benchmarks. Specifically, they report performance improvements of up to 13.4% on the AIME-2024 benchmark and increased reasoning trace lengths, demonstrating that the identified features are causally linked to reasoning behavior.
Interpretation and Evaluation
Manual and Automatic Interpretation
The research employs a rigorous evaluation regime involving both manual and automatic interpretation of SAE features. Manual interpretation focuses on identifying activation patterns corresponding to uncertainty, exploration, and reflection, utilizing feature interfaces for detailed examination. Automatic interpretation employs feature steering and GPT-4o to annotate features with semantic functions, clustering them into categories such as numerical accuracy and reasoning depth (Figure 1).

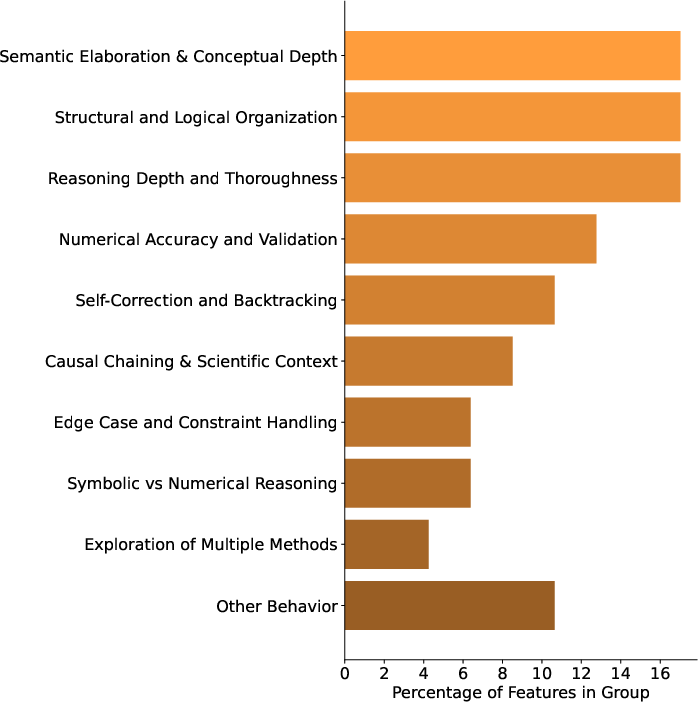
Figure 1: Interpretability results for manually verified set of features in our SAE: (a) Examples of feature interfaces used in manual interpretation experiments, (b) Distribution of reasoning features on function groups obtained by automatic interpretation pipeline by using GPT-4o as a judge.
Steering Experiments
The steering experiments provide compelling evidence of the practical implications of their findings. By modulating the activation of certain features, the LLM can be guided to produce outputs with deeper reasoning and improved performance on specific tasks. Such experiments showcase the potential for targeted interventions in LLM activations to enhance or alter reasoning processes.
Theoretical and Practical Implications
This study offers significant theoretical insights into the interpretability of reasoning processes in LLMs. By demonstrating that reasoning capabilities can be traced back to specific, interpretable components within the model's activations, the authors provide a concrete framework for understanding the internal mechanics of these complex systems. Practically, the ability to steer LLM reasoning processes opens avenues for fine-tuning models to fit specific reasoning tasks, potentially improving the efficiency and applicability of LLMs across various domains.
Conclusion
The research conducted in this paper lays foundational groundwork for interpreting and manipulating reasoning processes in LLMs via Sparse Autoencoders. By isolating features corresponding to key reasoning behaviors, such as uncertainty and exploration, and employing ReasonScore as a metric, the authors offer a novel perspective on LLM internal mechanisms. Future work can expand upon these findings, exploring the transferability of these insights across different model architectures and integrating them into more applied settings to refine AI reasoning capabilities.