- The paper introduces a late-interaction VLM embedding architecture that encodes document pages as sequences of visual tokens for fine-grained matching.
- It employs contrastive learning with hard-negative mining, cluster-based sampling, and model merging to enhance retrieval accuracy.
- Empirical results on ViDoRe and MIRACL benchmarks demonstrate significant performance gains, despite increased storage and inference complexity.
Nemotron ColEmbed V2: Late Interaction VLM Embeddings for Visual Document Retrieval
Introduction and Motivation
Nemotron ColEmbed V2 represents a technically significant advance in the domain of visual document retrieval (VDR), integrating late interaction embedding architectures with vision-LLMs (VLMs) to achieve state-of-the-art performance on complex retrieval benchmarks. The work systematically addresses the limitations of both OCR-centric and single-vector VLM retrieval by leveraging multi-vector late-interaction designs, enabling fine-grained matching between queries and document page images without sacrificing efficiency and scalability.
Architectural Overview
The Nemotron ColEmbed V2 family comprises three key variants, differentiated by parameter count (3B, 4B, 8B) and VLM backbone: Eagle 2/Llama 3.2 for 3B, and Qwen3-VL for 4B/8B models. All leverage SigLIP 2 image encoders and LLM backbones reconfigured to use bidirectional attention for improved global context encoding.
The canonical bi-encoder design, used in many prior approaches, pools the representation of an entire query or document into a single vector, simplifying retrieval but dramatically compressing multimodal and layout information (Figure 1).
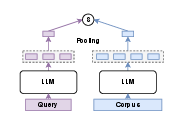
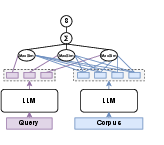
Figure 1: Bi-encoder architecture with pooling, using independent projection for query and document to global vectors.
The late interaction approach adopted in Nemotron ColEmbed V2 encodes each document page image as a sequence of visual tokens (via dynamic image tiling), and each query as a sequence of query tokens. During retrieval, token-level similarity is computed exhaustively via the MaxSim operator, aggregating token-wise maximum similarities for a more expressive signal.
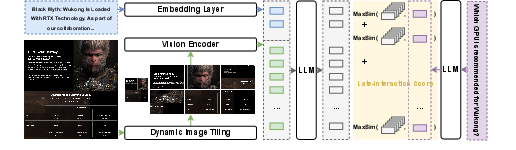
Figure 2: llama-nemotron-colembed-vl-3b-v2 architecture, highlighting dynamic image tiling and late interaction scoring.
Core to this approach is the decoupling of image-tiled encoding and late interaction scoring, supporting scalable pre-indexing of document embeddings while enabling rich, token-level matching at inference.
Training Pipeline and Key Techniques
Nemotron ColEmbed V2 employs contrastive learning with InfoNCE loss, targeting maximized similarity for positive query-document pairs and minimized similarity for hard negatives. Several design and training strategies underpin the model's empirical success:
- Bidirectional Attention in LLMs: Conversion from standard causal to bidirectional attention in the backbone unlocks access to full token context, yielding improved retrieval accuracy in embedding use cases.
- Hard-Negative Mining: Utilizing a retrieval teacher for mining top-k hard negatives, filtered by positive-score margins, ensures high-quality challenging negatives and reduces label noise.
- Cluster-Based Data Sampling: Training corpora are balanced by clustering positive contexts (using PCA-reduced embeddings and gap-statistics KMeans), then uniformly sampling to mitigate domain bias.
- Cross-Lingual Translation: Augmentation of queries into multiple languages via Qwen3-235B enables robust cross-lingual performance, supporting diverse ViDoRe and MIRACL-Vision tasks.
- Model Merging ("Souping"): Ensembling via weighted averaging of model weights, post-training on variations of training blends/hyperparameters, leads to robust aggregation of learned representations and consistently improved NDCG metrics.
The training paradigm is two-stage for the 3B model (text-only, then image), and single-stage (image corpus) for larger models, leveraging pre-trained VLMs for efficient cross-modal alignment.
Empirical Evaluation
Nemotron ColEmbed V2 models establish superior performance on industry-standard benchmarks:
- ViDoRe V3: The 8B model attains NDCG@10 of 63.42, a +3% margin over the next closest competitor, ranking first on this large-scale, cross-lingual, multi-domain benchmark. The 4B and 3B variants are also top-ranked for their size class.
- ViDoRe V1/V2: The 8B model secures the second position with NDCG@5 of 84.80, closely trailing the leading model and surpassing near-peers of comparable scale.
- MIRACL-Vision: The Nemotron ColEmbed V2 suite consistently outperforms alternatives across languages, especially in under-resourced languages, highlighting the efficacy of cross-lingual and cluster-balanced training blends.
In all benchmarks, the models maintain high accuracy with minimal loss when reducing embedding dimension to 512 or 128, highlighting their robustness to storage-accuracy tradeoffs.
Deployment Implications: Storage, Latency, and Efficiency
While late interaction architectures yield the best accuracy, this comes at considerable cost in storage (multi-vector per document) and inference complexity (query-token × doc-token MaxSim computation). For example, nemotron-colembed-vl-8b-v2, at default 4096-dim embedding and 773 tokens/image, incurs 5.9 TB of storage per million pages (fp16), compared to less than 4 GB for a bi-encoder. The storage can be mitigated using projection layers and quantization (float16 or int8), but remains orders of magnitude higher than single-vector alternatives.
Serving latency also scales superlinearly with corpus/document size, demanding specialized vector DB support. The authors discuss alternative pipelines (smaller bi-encoder + cross-encoder reranking) as better trade-offs for some production workloads.
Ablation and Model Compression
A detailed ablation shows that projecting late interaction embeddings to 512- or even 128-dim maintains 96% of the original NDCG@10 while reducing storage by 87–97%. However, even these compressed models incur substantial storage overhead, necessitating further research in quantization and hybrid late/early interaction strategies (e.g., late-pooling, MUVERA FDEs).
Theoretical and Practical Implications
Nemotron ColEmbed V2 establishes a new paradigm for VDR, validating that late-interaction, VLM-based embeddings can exploit document visual modality and layout, significantly outperforming methods limited to text or global representations. The fine-grained multimodal matching, combined with smart data mixing and robust cross-lingual training, generalizes well to real-world, multilingual, multi-domain corpora.
From a systems and algorithmic perspective, the paper provides a comprehensive analysis of the practical challenges—especially model size, storage, and latency tradeoffs—offering pathways to balance accuracy and deployment costs via data-efficient training, model merging, and embedding compression.
Future research is likely to focus on augmenting late-interaction designs with further advances in quantization, dynamic token reduction (late-pooling), and adaptive routing to minimize overhead without sacrificing retrieval fidelity.
Conclusion
Nemotron ColEmbed V2 provides a high-performance family of late-interaction VLMs for visual document retrieval, decisively advancing SOTA on complex benchmarks and offering robust support for multilingual and cross-domain scenarios. The comprehensive methodology—integrating architectural innovations, rigorous training techniques, and system-level tradeoff analysis—sets a new technical benchmark for the field, while also illuminating the computational and engineering frontiers that remain for scalable VDR in enterprise and open-domain applications.