Flash Multi-Head Feed-Forward Network
Abstract: We explore Multi-Head FFN (MH-FFN) as a replacement of FFN in the Transformer architecture, motivated by the structural similarity between single-head attention and FFN. While multi-head mechanisms enhance expressivity in attention, naively applying them to FFNs faces two challenges: memory consumption scaling with the head count, and an imbalanced ratio between the growing intermediate size and the fixed head dimension as models scale, which degrades scalability and expressive power. To address these challenges, we propose Flash Multi-Head FFN (FlashMHF), with two key innovations: an I/O-aware fused kernel computing outputs online in SRAM akin to FlashAttention, and a design using dynamically weighted parallel sub-networks to maintain a balanced ratio between intermediate and head dimensions. Validated on models from 128M to 1.3B parameters, FlashMHF consistently improves perplexity and downstream task accuracy over SwiGLU FFNs, while reducing peak memory usage by 3-5x and accelerating inference by up to 1.08x. Our work establishes the multi-head design as a superior architectural principle for FFNs, presenting FlashMHF as a powerful, efficient, and scalable alternative to FFNs in Transformers.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to build a part of Transformer models (the kind of AI used in many language tools). The authors create a module called Flash Multi-Head Feed-Forward Network (FlashMHF) to replace the usual Feed-Forward Network (FFN) in Transformers. Their goal is to make models both smarter and more efficient, using less memory and running a bit faster.
What questions did the researchers ask?
The paper explores three simple questions:
- Can we make the FFN work like attention does, using multiple “heads” (specialists), to improve how the model learns?
- How do we avoid the big memory problems that come with using many heads?
- Will this new design actually make models more accurate and efficient on real tasks?
How did they approach it?
Think of a Transformer block as having two big parts:
- Attention (a group of “spotters” looking at different parts of the sentence).
- FFN (a “processor” that transforms information for each word).
The authors noticed that FFNs are structurally similar to attention: both take inputs, mix them with learned weights, and produce outputs. Since attention works better with multiple heads (several specialists working in parallel), they tried doing the same with FFNs.
Here’s their approach, broken down with everyday analogies:
- Multi-head FFN: Instead of one big FFN, use several smaller FFNs (heads). Each head focuses on a different “subspace” or angle—like a team where each member is a specialist.
- The problem they hit:
- Memory overload: If you have many heads, each creates large temporary results. Storing all of these at once uses a lot of GPU memory.
- Size imbalance: As models get bigger, the FFN grows wide inside, but each head stays narrow. This mismatch hurts performance.
- Their fix has two key parts:
- Each head is made of several mini-FFNs (sub-networks) that run in parallel.
- A simple gating mechanism (like dimmer switches) decides how much each mini-FFN contributes to the final output, per token.
- This keeps the size ratio balanced, so the heads aren’t “starved” or “overfed” as models scale.
2) A flash-style, I/O-aware kernel (inspired by FlashAttention): - Imagine fast “desk” memory (SRAM) and slower “storage room” memory (HBM). - Instead of creating one huge intermediate result and sending it back and forth to slow memory, they compute the output in small blocks that fit on the fast desk. - They process chunks piece by piece and add them up on the fly, which saves memory and avoids slow data movement.
In short: multiple specialist processors (heads), each with several mini-processors (sub-networks), plus a smart way to compute in small chunks on fast memory, so you never store huge temporary data.
What did they find, and why does it matter?
The authors tested their idea on models of different sizes: about 128 million, 370 million, and 1.3 billion parameters. They compared against the common SwiGLU FFN (the standard FFN used in many modern Transformers) and a few other variants.
Here are the highlights:
- Better accuracy:
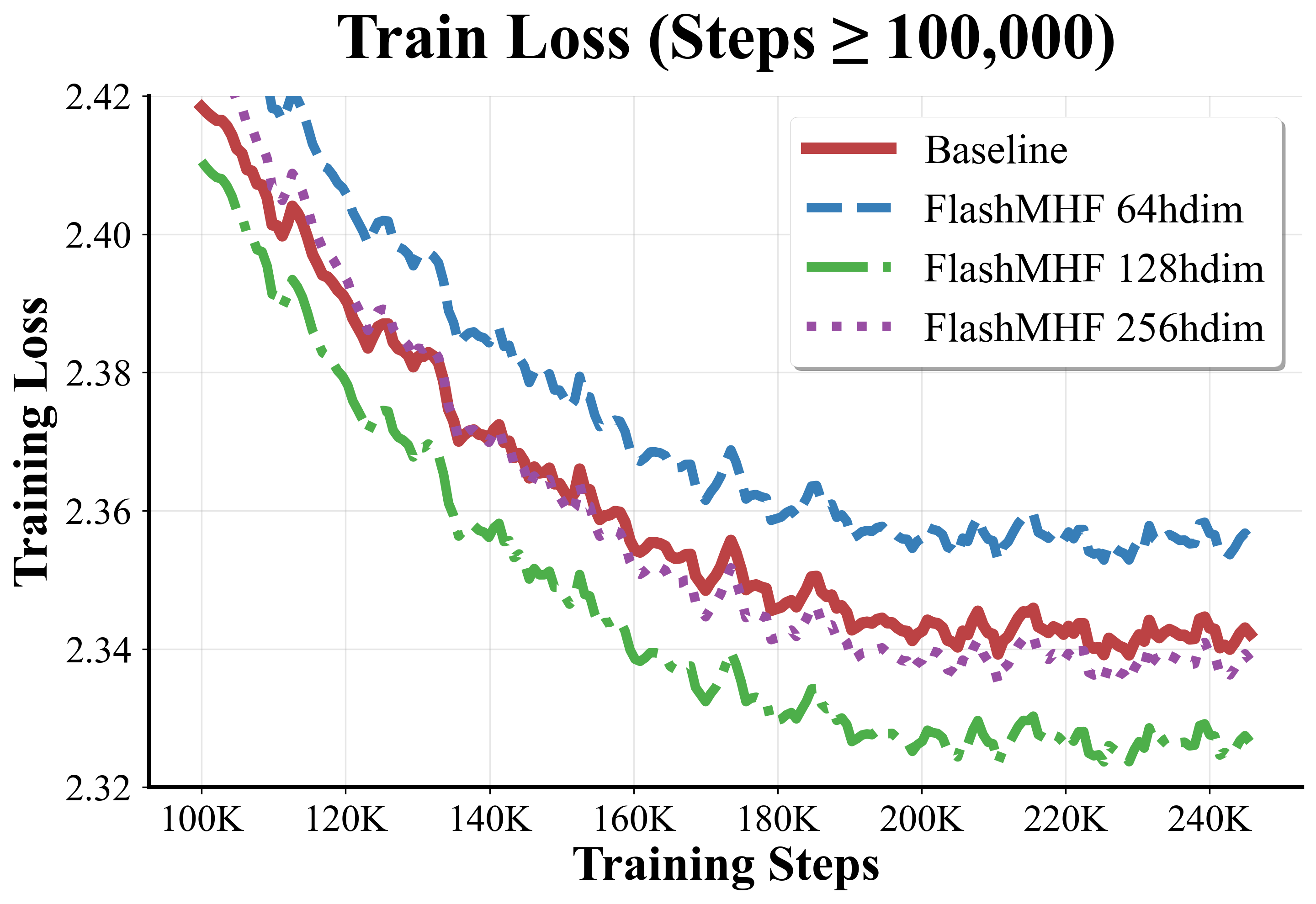
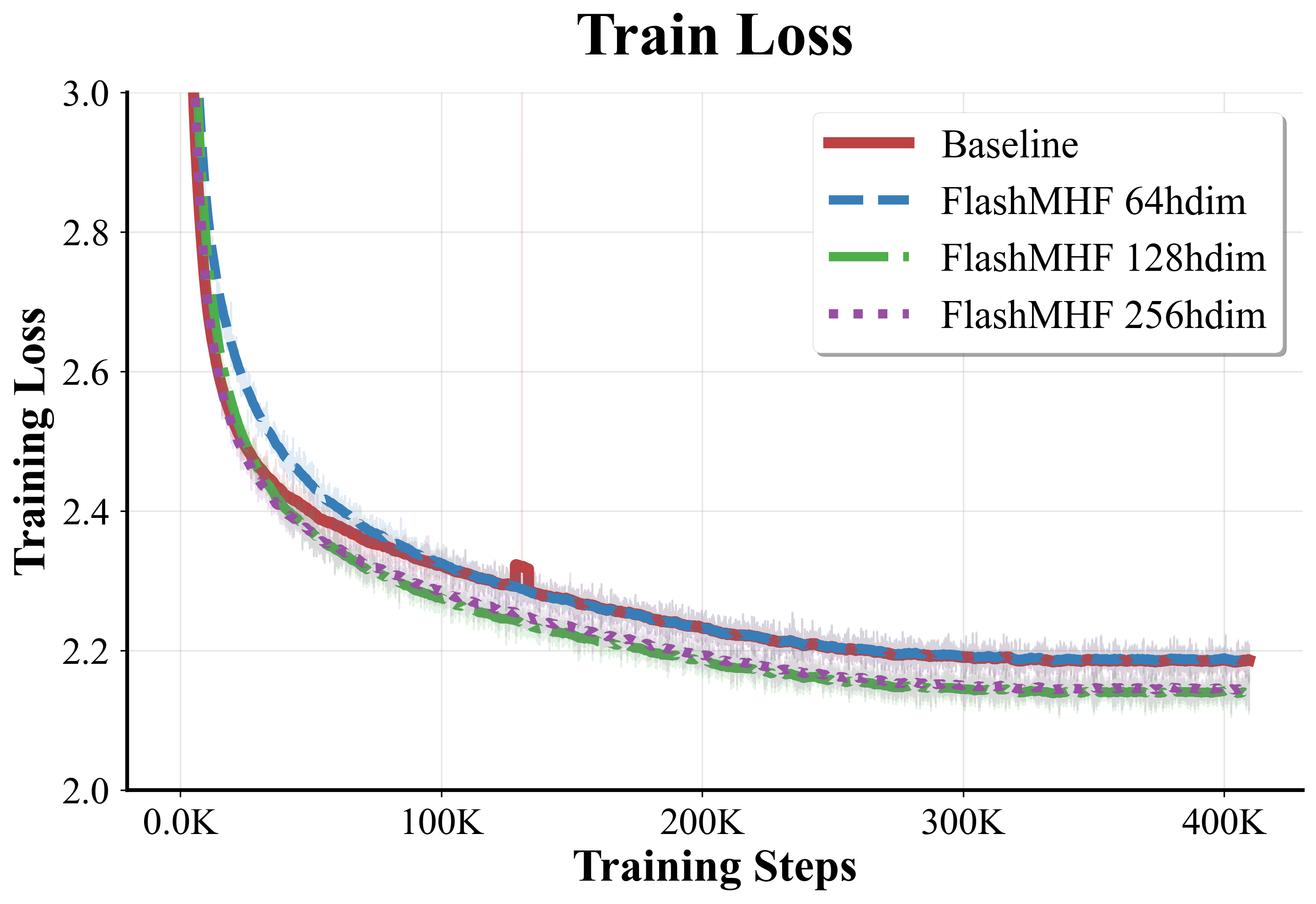
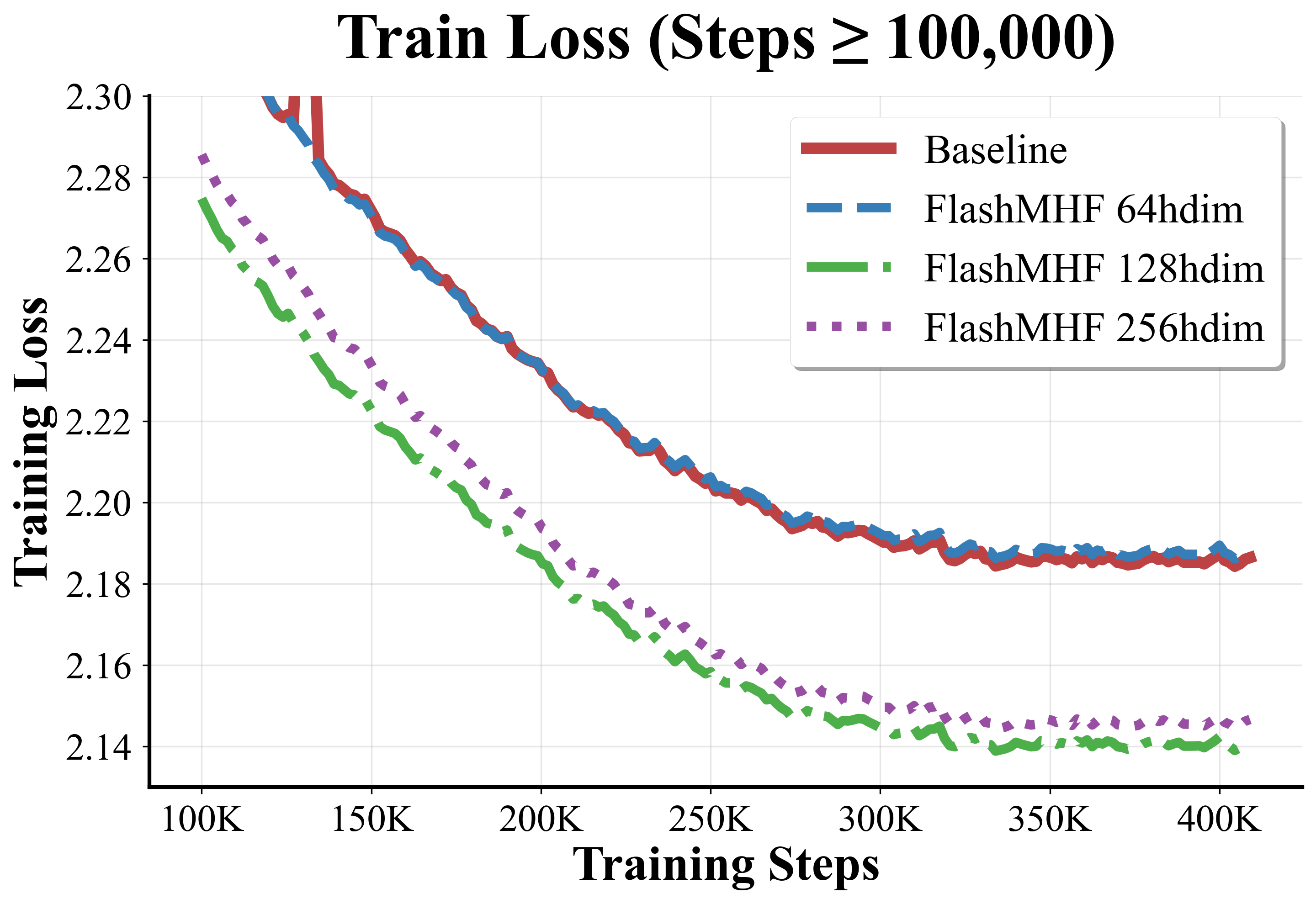
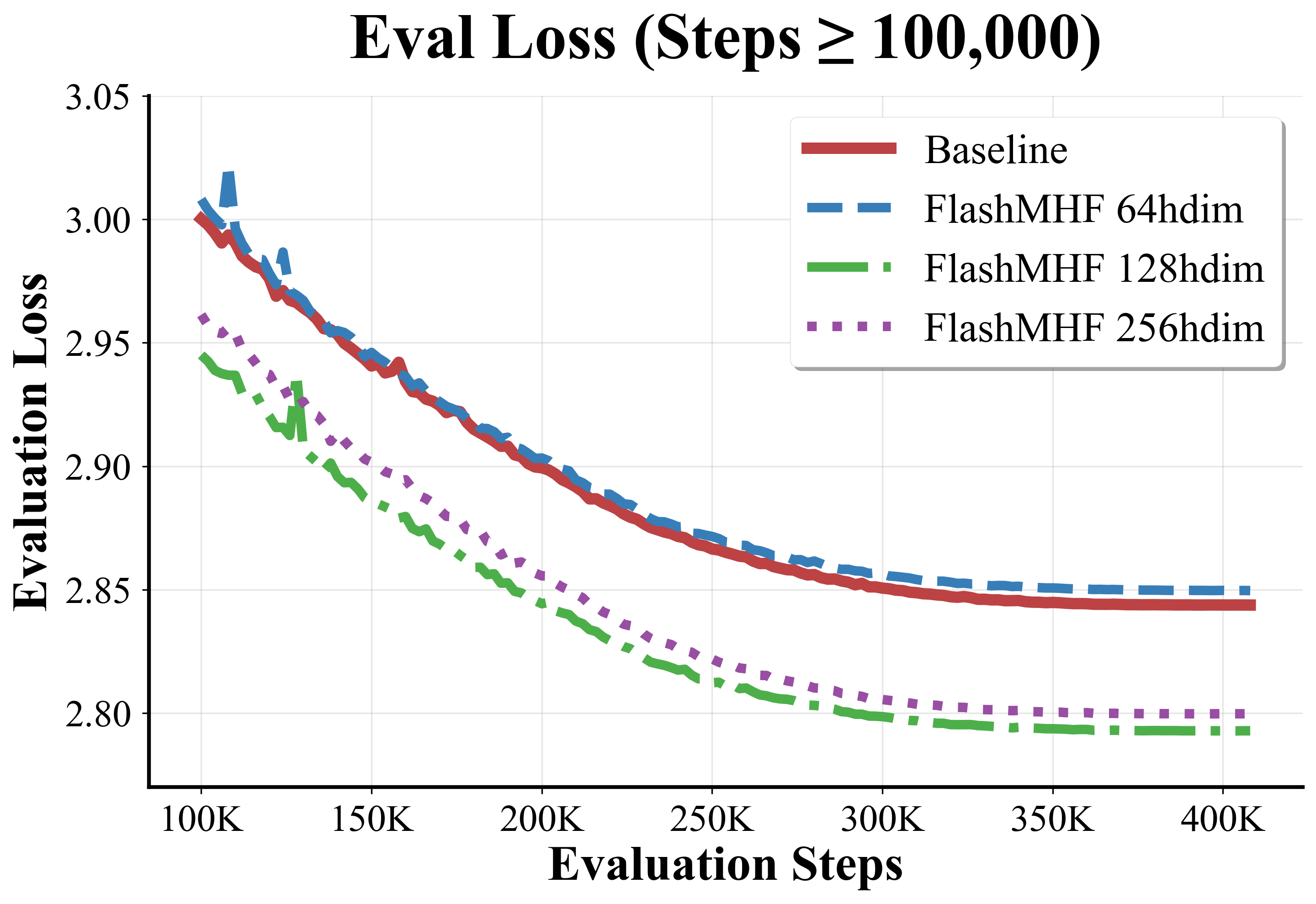
- FlashMHF consistently achieved lower validation loss and lower perplexity (a measure of how well the model predicts text—lower is better), especially noticeable at the 1.3B scale.
- It also improved scores on several downstream tasks (like commonsense reasoning and reading comprehension).
- Lower memory use:
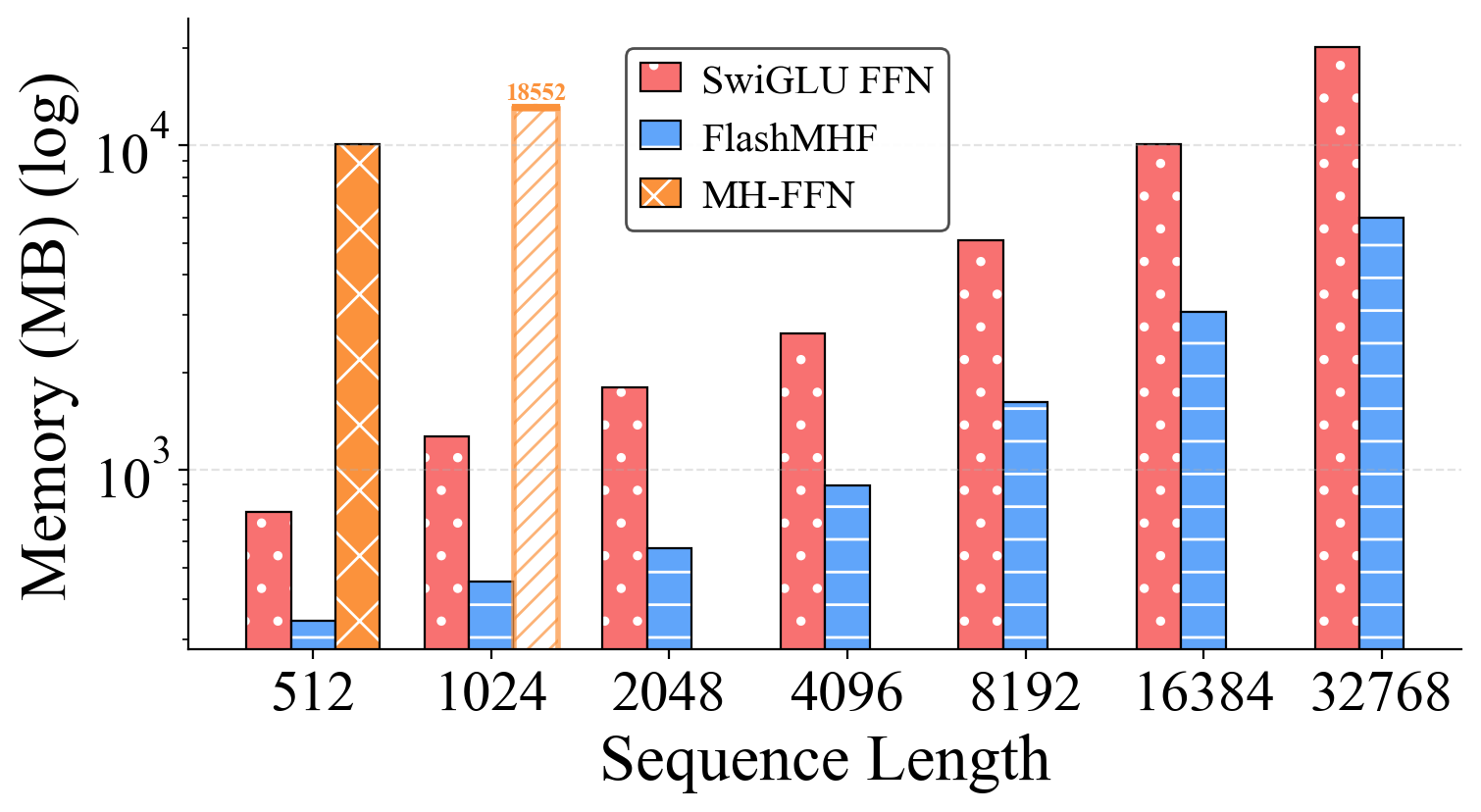
- Peak GPU memory dropped by about 3–5× compared to the standard FFN. This is a big deal for longer context lengths or bigger models.
- Slightly faster:
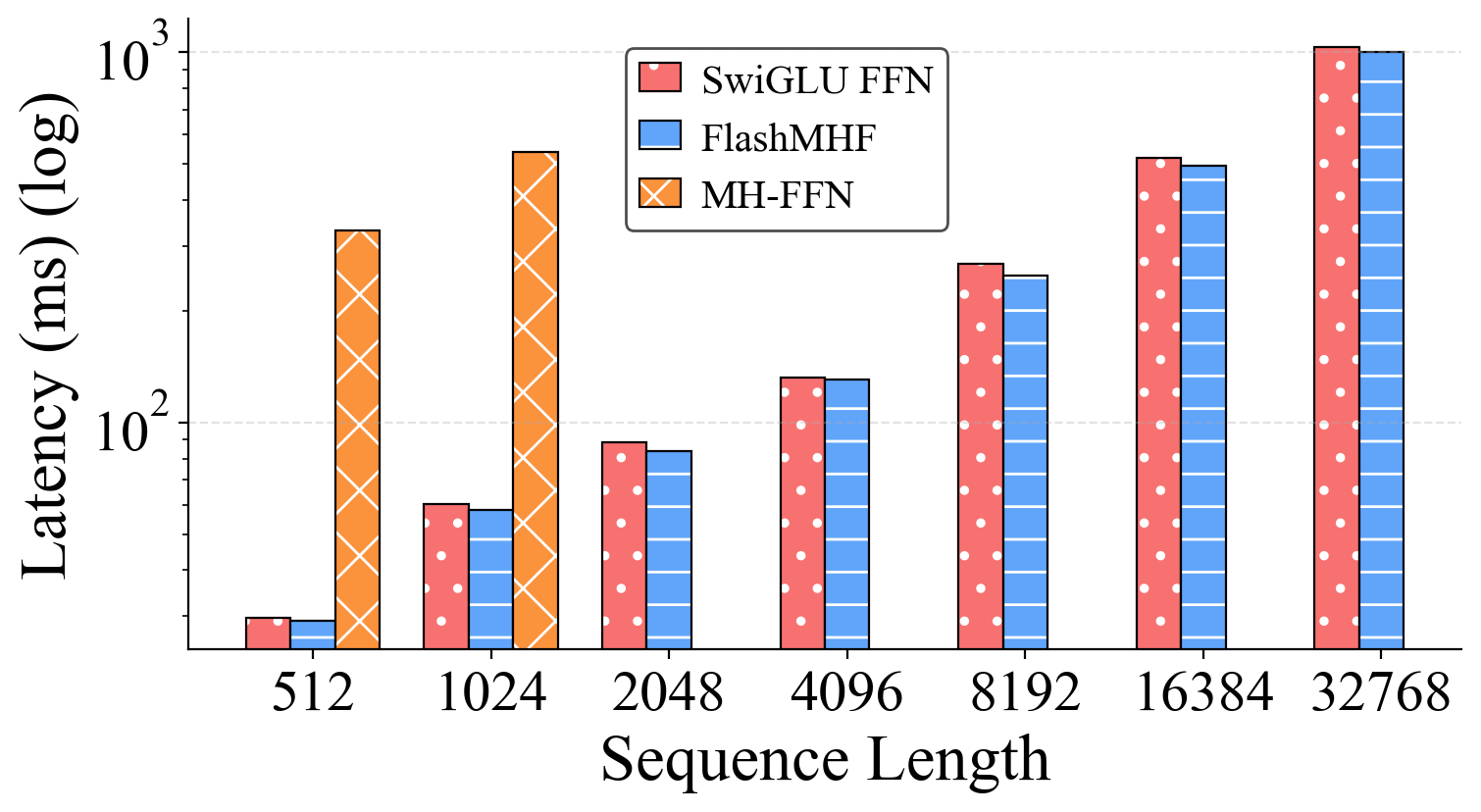
- Inference speed improved by up to about 1.08× (and typically around 1.05×), mainly thanks to avoiding big writes/reads to slow memory.
- Scales well:
- A naive multi-head FFN works at small sizes but falls behind as models get bigger. FlashMHF keeps performing well because its design keeps the size ratio balanced.
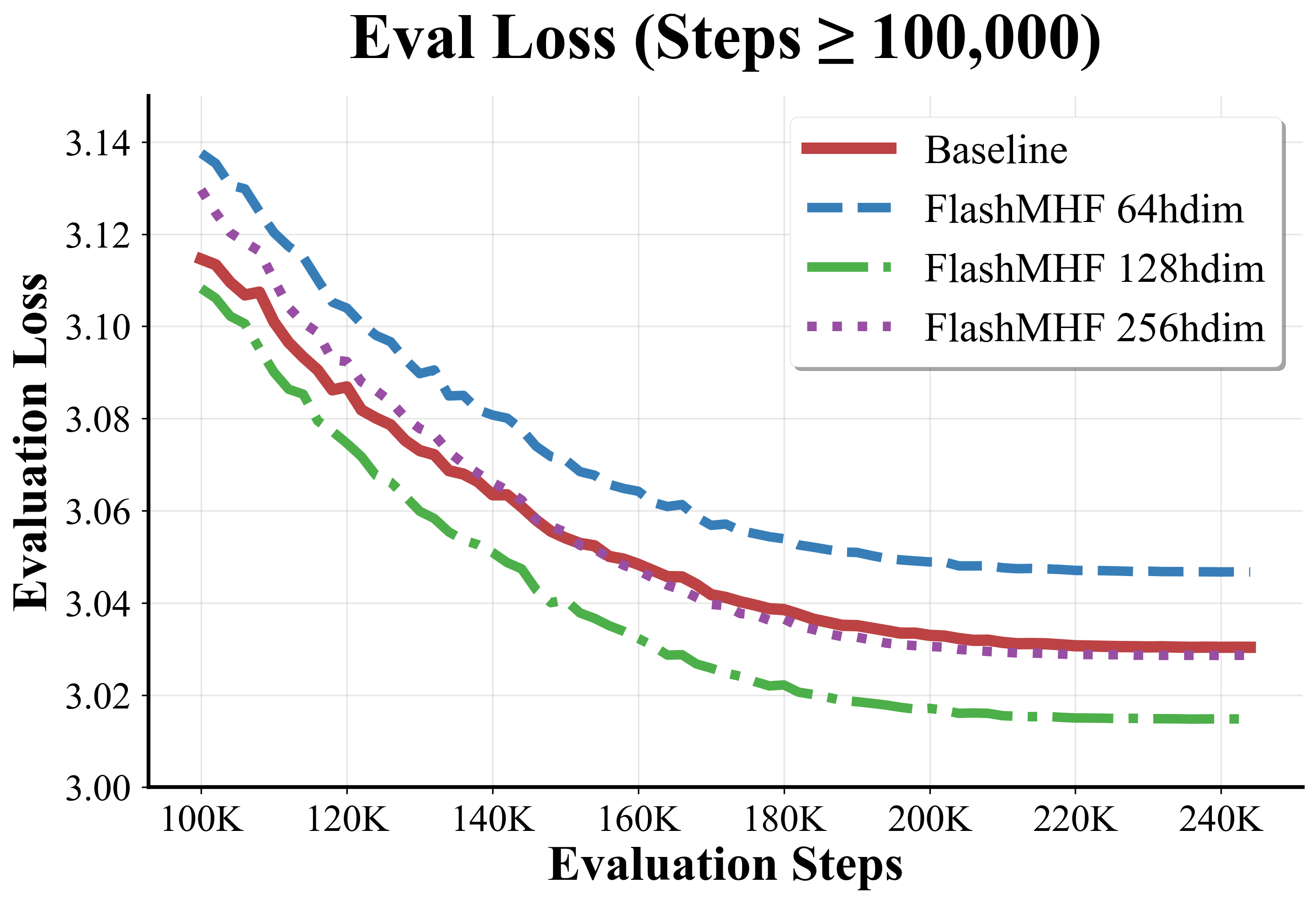
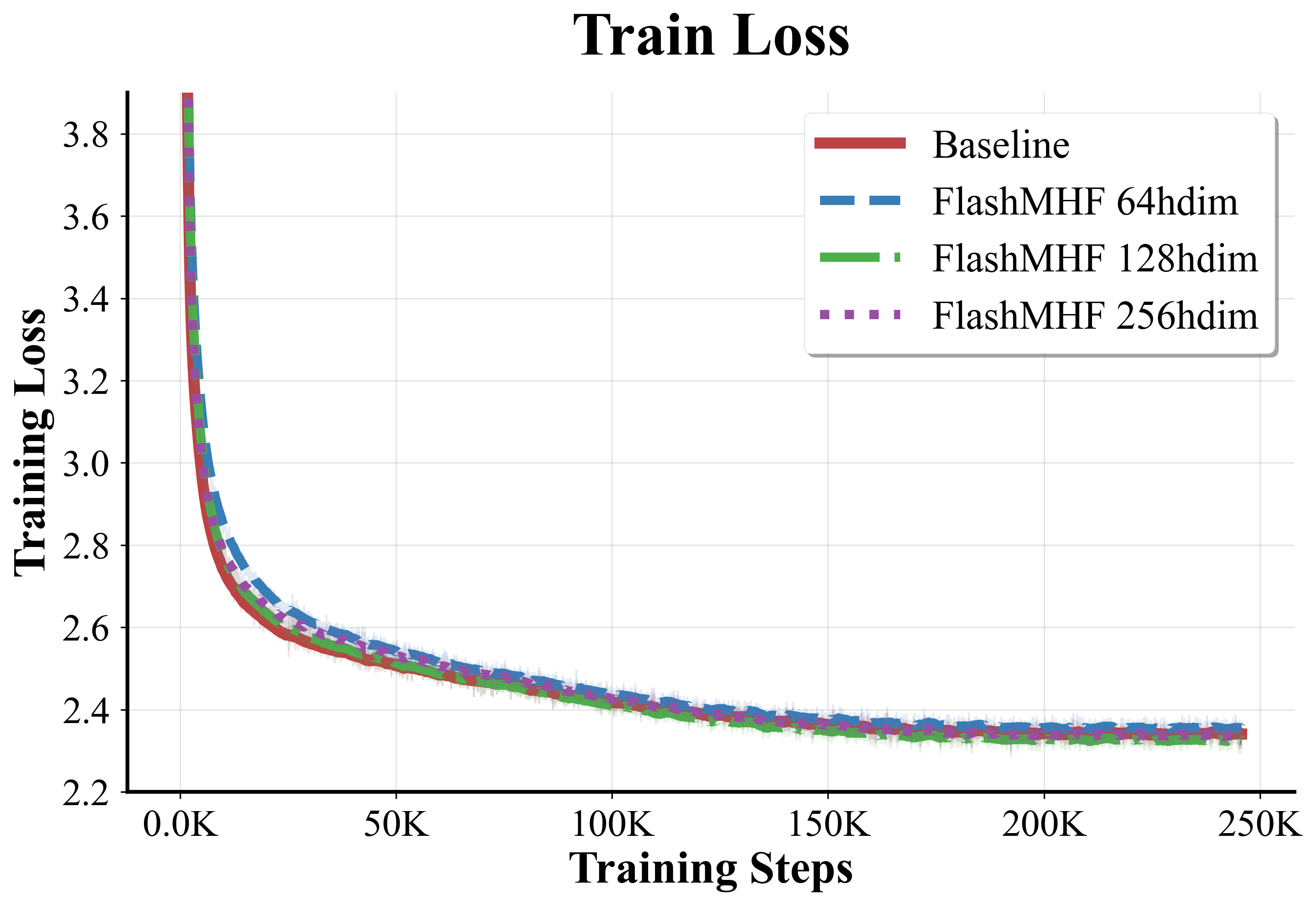
- Sweet spot for head size:
- Using a per-head dimension of 128 often gave the best results. Heads that are too small can’t learn enough; heads that are too big reduce the number of heads and lose diversity.
These results matter because they show you can swap the standard FFN for FlashMHF and get improvements in accuracy, memory, and speed—all at once.
Implications and impact
FlashMHF suggests a better “architectural principle” for the FFN part of Transformers: make it multi-headed (like attention), balance the internal dimensions as the model scales, and compute in memory-friendly blocks. This could lead to:
- More powerful models on the same hardware.
- Longer context windows and larger batch sizes without running out of memory.
- Reduced costs and energy use (greener AI).
- A foundation for future designs that treat FFNs as multi-head structures by default.
In simple terms: FlashMHF helps LLMs think in richer ways while being kinder to the computer’s memory and a bit quicker to run. It’s a practical upgrade that can make next-generation AI models more capable and more affordable to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Scaling beyond 1.3B parameters: Validate whether FlashMHF’s gains persist for ≥7B/13B+ models trained on ≥300B tokens, including convergence curves and compute-normalized performance.
- Long-context generalization: Although memory is profiled vs sequence length, models are trained with max context 4,096; assess quality and stability on long-context tasks (≥32k–128k) and datasets (e.g., LongBench, Needle-in-a-Haystack).
- Training-time efficiency: Report end-to-end training throughput, wall-clock time, and training memory usage (forward+backward) vs SwiGLU and MH-FFN under matched hardware/batch/sequence settings.
- Backward pass kernel benchmarks: Provide measured speed and memory of the custom backward pass (not just pseudocode), including recomputation vs checkpointing trade-offs.
- Hardware portability: Evaluate kernel performance and correctness on A100, consumer GPUs (e.g., RTX 4090), and TPUs; characterize reliance on Hopper-specific features and portability costs.
- Low-precision support: Quantify accuracy/throughput under FP8/INT8 or mixed-precision settings; detail tensor core utilization and numerical stability of the fused kernel under low-precision arithmetic.
- Quantization/Pruning compatibility: Test if FlashMHF is robust to post-training quantization, QAT, structured pruning, or N:M sparsity, and how these interact with the gating and fused kernel.
- Memory vs attention KV-cache dominance: For typical deployment (batch=1, streaming), quantify net memory impact when attention KV cache dominates; clarify scenarios where FlashMHF’s memory savings materially change system limits.
- FLOPs fairness and depth–width confounders: Provide precise FLOPs counts and parameter distributions per layer; isolate gains from architectural change vs reduced depth (20-layer FlashMHF vs 24-layer baseline).
- Comparison to strong FFN baselines: Compare against other state-of-the-art FFN variants (e.g., GEGLU, ReGLU, ReLU2, Gated-FFN variants, SwiGLU with fused/Flash-style kernels) and recent dense alternatives (e.g., Tokenformer components) under matched compute/params.
- Comparison to sparse MoE baselines: Include Switch/Top-2/Top-1 MoE with expert capacity tuning and load-balancing losses at equalized compute/params to contextualize dense multi-head FFN benefits.
- E (number of sub-networks) ablations: Systematically vary and the sub-network width to map performance/compute/memory trade-offs and identify scaling laws for and with model size.
- Gating function design: Compare sigmoid-normalized gating with softmax, temperature scaling, top-k routing, and adding load-balancing/entropy regularizers; study routing collapse and specialization dynamics.
- Head count and head–FFN interaction: Jointly ablate attention head count and FFN head dimension to understand cross-module interactions and optimal allocation between attention and FFN heads.
- Automatic head sizing: Explore learned or adaptive per head (or across layers), dynamic head pruning/merging, and layer-wise heterogeneity to optimize the balance automatically.
- Cross-layer parameter sharing: Test sharing sub-network weights across heads or layers to reduce parameters and improve cache locality while preserving performance.
- Interpretability and specialization: Analyze whether heads/sub-networks specialize (e.g., via routing entropy, cosine similarity of expert outputs) and whether such specialization correlates with downstream gains.
- Robustness and stability: Evaluate sensitivity to initialization, learning rate schedules, normalization choices, dropout, and label smoothing; report variance across seeds and training instabilities.
- Generalization across domains: Train/evaluate on non-Pile corpora (multilingual, code, math, scientific text) and measure transfer to code/math benchmarks (e.g., HumanEval, MBPP, GSM8K, MATH).
- Broader downstream evaluation: Include larger, diverse suites (e.g., MMLU, ARC, BIG-bench, DROP, SQuAD, TydiQA) and generative/open-ended tasks to substantiate claims beyond small multiple-choice datasets.
- Instruction tuning and alignment: Test whether FlashMHF improves data efficiency or final quality after SFT/RLHF/DPO and whether gating introduces calibration or alignment differences.
- Calibration and uncertainty: Measure ECE/Brier scores, selective prediction, and risk–coverage to see if multi-head FFN affects calibration vs SwiGLU.
- Long-horizon reasoning: Validate the “implicit thinking/beam search” hypothesis with targeted reasoning tasks (e.g., GSM8K, StrategyQA) and controlled interventions (e.g., routing sparsity/temperature).
- Robustness to distribution shift: Assess performance under domain shift, adversarial prompts, noise, or corrupted tokens to understand resilience of headwise sub-networks.
- Memory–latency trade-offs at scale: Provide detailed latency–memory Pareto curves across batch/sequence sizes and mixed workloads; include multi-GPU model- and tensor-parallel regimes.
- Pipeline/tensor parallelism: Describe sharding strategies for per-head sub-networks, collective communication costs, and scaling efficiency across nodes; identify potential load imbalance.
- Inference batching and throughput: Benchmark real-world server scenarios (dynamic batching, variable sequence lengths) to quantify throughput gains vs baseline under production-like conditions.
- Compatibility with caching and speculative decoding: Examine whether FlashMHF interacts with cache reuse/speculative decoding strategies and if its fused kernel hinders kernel fusion elsewhere.
- Kernel maintenance and ecosystem integration: Detail integration with PyTorch/Triton/CUDA versions, autotuning, compile times, fallbacks, and how shape constraints affect model flexibility.
- Safety and bias: Measure whether the new architecture alters toxicity, bias, or safety profiles relative to baseline under matched training data, noting any trade-offs with capability.
- Encoder–decoder and multimodal applicability: Test FlashMHF in encoder-decoder models (e.g., T5-like) and multimodal Transformers (e.g., ViT, vision-language) to probe generality beyond decoder-only LMs.
- Very long training runs: Investigate whether routing/gating drifts over long training (e.g., >1T tokens), causing expert collapse or over-specialization; propose stabilization if needed.
- Energy efficiency: Report energy per token (J/token) and carbon metrics; verify whether memory savings translate into measurable energy reductions in both training and inference.
- Failure modes and degenerate regimes: Identify conditions (e.g., very small , extremely large , or tiny batch sizes) where FlashMHF underperforms or becomes unstable, and provide guardrails.
Practical Applications
Immediate Applications
Below is a set of actionable use cases that can be deployed now, leveraging FlashMHF’s memory-efficient multi-head FFN architecture, fused I/O-aware kernel, and demonstrated improvements in perplexity and downstream tasks.
- Cloud LLM serving optimization (software/cloud)
- Use FlashMHF as a drop-in replacement for SwiGLU FFNs in Llama-like models to reduce peak inference memory by 3–5x and achieve modest speedups (≈1.05–1.08x), enabling longer context windows, higher batch sizes, and more concurrent sessions per GPU.
- Potential tools/products/workflows: “FlashMHF-enabled Transformer” runtime module for PyTorch; plugin for serving stacks like vLLM/TensorRT-LLM; cost-aware autoscaling policies that exploit lower VRAM footprint.
- Assumptions/dependencies: CUDA/Hopper-optimized fused kernel (NVIDIA H100-class GPUs show best results); PyTorch integration; compatibility validation with existing quantization and mixed-precision setups.
- Enterprise long-document analytics and summarization (finance, legal, compliance)
- Deploy LLM-powered pipelines that can ingest more pages per request (contracts, filings, regulatory texts) thanks to reduced activation memory in FFN, enhancing throughput and accuracy for summarization and Q&A.
- Potential tools/products/workflows: “Long-context summarizer” APIs with FlashMHF; e-discovery and policy compliance assistants that process multi-document bundles within a single inference.
- Assumptions/dependencies: End-to-end stack combines FlashMHF with FlashAttention for attention-side efficiency; validation on domain corpora; privacy/compliance controls for sensitive data.
- Code assistants with repository-scale context (software/engineering)
- Improve developer tools that need large context windows (multi-file codebases, diffs, logs) by integrating FlashMHF to extend input length without upgrading hardware.
- Potential tools/products/workflows: IDE plugins and CI bots that perform refactoring, test generation, or code review over larger code scopes; “RAG + FlashMHF” code search assistants.
- Assumptions/dependencies: Tested integration into popular model families (e.g., Llama-based); careful tuning of head dimension (128 shown as a sweet spot in the paper).
- Clinical note summarization and longitudinal EHR analysis (healthcare)
- Enable larger per-patient context and longer medical histories in LLM-based clinical summarizers by lowering memory overhead during inference.
- Potential tools/products/workflows: Hospital-deployed summarization services; care-plan synthesis tools with extended history context windows.
- Assumptions/dependencies: Healthcare-grade data governance; model fine-tuning on medical corpora; on-prem GPU availability; regulatory approval where required.
- Customer support and contact center analytics (industry operations)
- Process longer ticket threads, call transcripts, and multi-channel histories in a single pass, improving resolution suggestions and sentiment analysis.
- Potential tools/products/workflows: “Conversation intelligence” dashboards with FlashMHF; bulk summarization of chat/email threads.
- Assumptions/dependencies: Integration with existing CRM data pipelines; latency targets compatible with modest speedups; domain fine-tuning.
- Academic labs and teaching (academia/education)
- Reduce hardware barriers for training and evaluating 128M–1.3B parameter models; students explore the FFN–attention symmetry and multi-head FFN design.
- Potential tools/products/workflows: Course modules on I/O-aware kernels and Transformer internals; reproducible training recipes and open-source checkpoints; architecture ablation assignments.
- Assumptions/dependencies: Availability of the open-source FlashMHF code and training scripts; access to GPUs (even if limited); use of open datasets (e.g., The Pile).
- MLOps reliability and OOM mitigation (software/platform)
- Lower peak memory utilization in inference jobs to reduce out-of-memory failures and improve micro-batching strategies.
- Potential tools/products/workflows: Memory-aware schedulers that exploit FlashMHF’s reduced activation footprint; “OOM-guard” alerts tuned to FFN-side savings.
- Assumptions/dependencies: Monitoring hooks in serving frameworks; careful selection of batch and context size; validation under workload diversity.
- Sustainability and cost control (policy/operations)
- Immediate energy and cost benefits by serving more requests per GPU and reducing VRAM footprint; useful for internal ESG reporting.
- Potential tools/products/workflows: “Green AI” dashboards that quantify memory-related energy savings; procurement policies favoring I/O-aware architectures.
- Assumptions/dependencies: Accurate power/telemetry instrumentation; organizational policies that recognize model-level efficiency gains.
- Edge and mid-range GPU deployments (robotics/embedded, SMB IT)
- Run larger or longer-context LLMs on mid-tier GPUs in labs or SMB environments by adopting FlashMHF in inference stacks.
- Potential tools/products/workflows: Local knowledge assistants; robotics task planners requiring longer language context.
- Assumptions/dependencies: Kernel porting/tuning beyond H100 (e.g., A100, consumer GPUs, ROCm/AMD); potential re-implementation if device-specific features differ.
Long-Term Applications
These use cases are promising but require further research, scaling, broader hardware support, or ecosystem adoption before widespread deployment.
- Standardization across frameworks and model families (software ecosystem)
- Make FlashMHF a first-class alternative to SwiGLU in major libraries (e.g., Hugging Face Transformers, xFormers), and in commercial SDKs.
- Potential tools/products/workflows: “FlashMHF-enabled Transformers” presets; turnkey integrations with training/inference stacks; community benchmarks across tasks and sizes.
- Assumptions/dependencies: Broad maintainer adoption; robust kernel availability on diverse accelerators; long-term API stability.
- Ultra-long-context LLMs (cross-sector)
- Combine FlashMHF (FFN-side savings) with state-of-the-art attention optimizations to push context windows into 100k+ tokens for scientific literature review, legal e-discovery at scale, and comprehensive financial analysis.
- Potential tools/products/workflows: “ContextBoost” services for enterprises; research assistants that handle books or multi-document corpora in one pass.
- Assumptions/dependencies: Attention-side scalability (e.g., FlashAttention variants, memory-efficient KV caches); training data and curriculum for long-context stability; robust evaluation protocols.
- Cross-modal adoption (vision, speech, multimodal robotics)
- Port the multi-head FFN + flash kernel design to ViTs, ASR models, and multimodal transformers to cut memory and improve throughput in perception stacks.
- Potential tools/products/workflows: “FlashMHF-ViT” for high-res image/video; multimodal assistants processing longer audio-visual contexts.
- Assumptions/dependencies: Architecture-specific adaptations of gating and sub-network aggregation; kernel support for modality-specific tensor shapes; task validation.
- On-device and mobile AI (consumer devices, healthcare wearables, AR/VR)
- Bring larger models onto smartphones/edge NPUs by introducing FFN-side memory savings and blockwise fused kernels tuned to mobile runtimes.
- Potential tools/products/workflows: Local personal assistants; medical transcription on wearables; AR/VR language overlays with low latency.
- Assumptions/dependencies: Kernel ports to Metal/Apple Neural Engine, Qualcomm/MediaTek NPUs, or Vulkan; power-budget trade studies; privacy and safety constraints.
- Federated and personalized training (education, healthcare, finance)
- Enable larger local models for privacy-preserving personalization on client devices owing to reduced memory consumption during training epochs.
- Potential tools/products/workflows: Federated personalization pipelines for EHR summarization, tutoring systems, or portfolio assistants.
- Assumptions/dependencies: Training-side fused kernels with efficient backprop; communication-efficient federated protocols; rigorous privacy guarantees.
- Hardware co-design and accelerator features (semiconductor industry)
- Inspire SRAM-rich designs and instruction-level support for streaming FFN blocks, analogous to attention accelerators, to further amplify speed and efficiency.
- Potential tools/products/workflows: Next-gen accelerators with “FlashMHF ops” support; compiler passes that schedule blockwise FFN compute and asynchronous movement.
- Assumptions/dependencies: Collaboration between model architects and hardware vendors; standardized kernels; industry benchmarks validating ROI.
- Quantization and low-precision synergy (software/hardware)
- Explore FP8/INT8 variants of FlashMHF, leveraging gating and blockwise computation for additional memory/speed gains without substantial quality loss.
- Potential tools/products/workflows: “FlashMHF-INT8” inference kits; mixed-precision training recipes.
- Assumptions/dependencies: Careful numerics for SiLU and gating normalization; hardware support (e.g., FP8 tensor cores); task-specific calibration.
- Policy and democratization of AI (public sector, non-profits)
- Use memory- and cost-efficiency to make high-quality LLMs accessible to universities, NGOs, and small labs; embed FlashMHF into grant programs and public compute initiatives.
- Potential tools/products/workflows: Funding criteria that prioritize I/O-aware architectures; open benchmarks comparing energy per token.
- Assumptions/dependencies: Transparent reporting standards; independent verification of energy savings; community uptake.
- Domain-specific, compliance-grade deployments (healthcare, finance, legal)
- Build certifiable, on-prem LLMs with longer context windows and constrained memory profiles for regulated environments.
- Potential tools/products/workflows: Audited inference pipelines; explainability layers matched to FlashMHF’s gating; data residency-friendly deployments.
- Assumptions/dependencies: Regulatory approvals; robust safety/fairness evaluations; long-horizon reliability tests under domain workloads.
Glossary
- attention over parameters: Reinterpreting FFN computations as an attention mechanism operating over learned parameter vectors. "Thus, we can reinterpret FFNs as ``attention over parameters" of length $d_{\text{ff}$ \citep{vaswani2017attention_v2,Geva2020TransformerFL}."
- asynchronous data movement: A GPU execution technique that overlaps data transfers with computation to improve throughput. "techniques such as {asynchronous data movement} and {warp-group specialization}"
- beam search: A heuristic search strategy that explores multiple candidate paths in parallel, often used in sequence modeling. "FlashMHF's architecture is analogous to performing a beam search over this implicit thinking process."
- Blockwise Computation: Executing large matrix operations in smaller blocks to fit on-chip memory and reduce I/O. "Blockwise Computation."
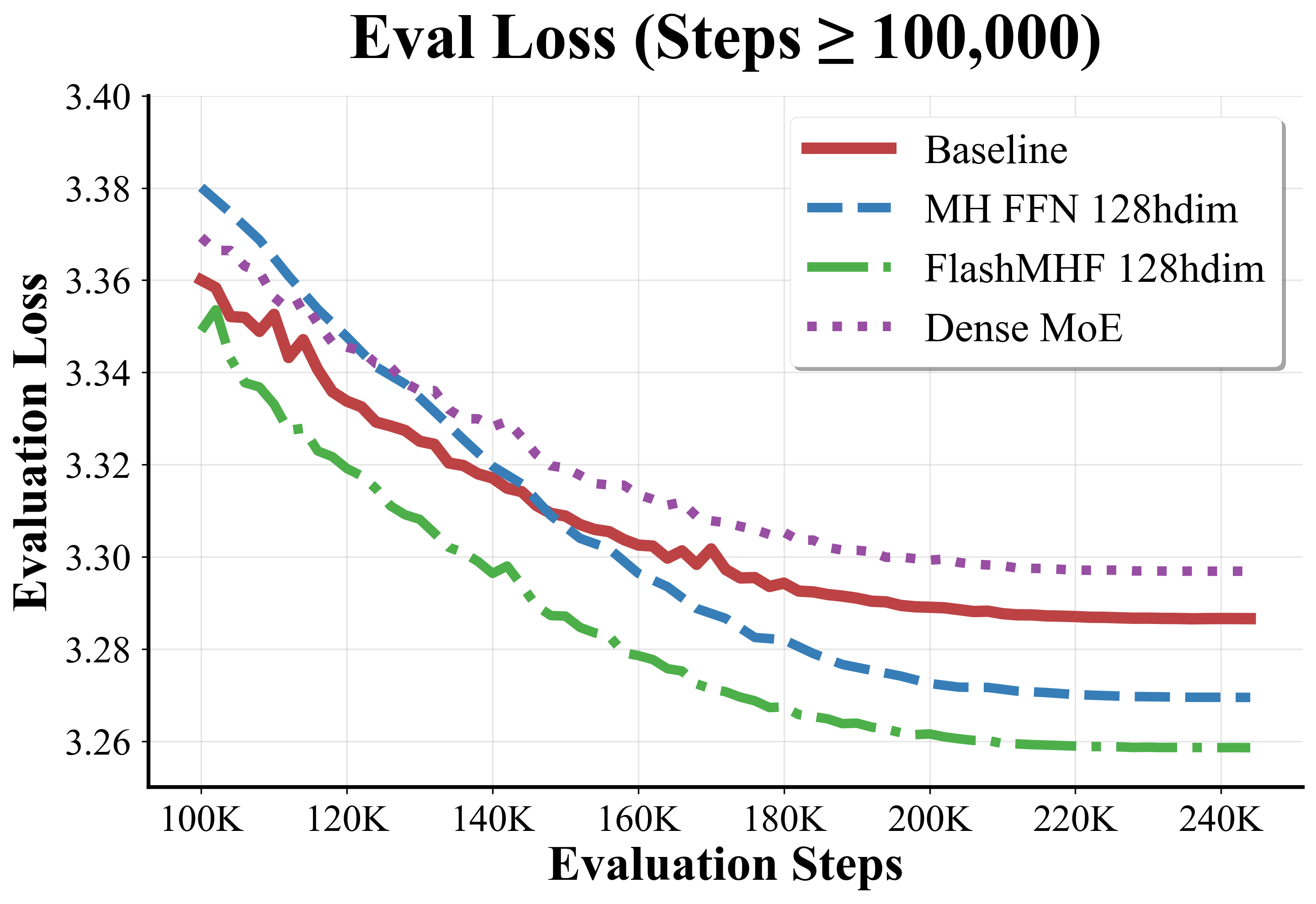
- Dense MoE: A Mixture-of-Experts variant where all experts are active (no sparse routing), often used as a control baseline. "This control group is equivalent to a dense MoE."
- FlashAttention: An I/O-aware attention algorithm that avoids materializing large intermediates by computing softmax online. "analogously to FlashAttention's online softmax \citep{Dao2022FlashAttentionFA}"
- FlashMHF: Flash Multi-Head Feed-Forward Network; a multi-head FFN with a fused, I/O-aware kernel and parallel sub-networks. "we propose Flash Multi-Head FFN (FlashMHF), with two key innovations: an I/O-aware fused kernel computing outputs online in SRAM akin to FlashAttention"
- fused kernel: A single GPU kernel that combines multiple operations to minimize memory traffic and kernel launch overhead. "This entire loop is executed within a single fused kernel:"
- gating weights: Learned per-token weights that modulate how sub-network outputs are combined in a mixture-style architecture. "These logits are then transformed into normalized gating weights, , via a sigmoid activation followed by a numerically stable normalization."
- HBM: High Bandwidth Memory; off-chip GPU memory with high bandwidth but higher latency than on-chip SRAM. "without materializing the large intermediate hidden state in HBM."
- Hopper architecture: NVIDIA’s GPU microarchitecture generation (e.g., H100) targeted by the paper’s benchmarks. "a 1.00x-1.08x inference speedup on the Hopper architecture"
- I/O-aware algorithm: An algorithm designed to minimize data movement between memory hierarchies, improving performance and memory use. "we introduce an I/O-aware algorithm for the FFN computation that avoids materializing the large intermediate activation tensor."
- I/O bottleneck: Throughput limitation caused by excessive reads/writes to off-chip memory rather than computation. "This speedup primarily stems from eliminating the I/O bottleneck of writing and reading the large intermediate activation tensor to and from HBM."
- Mixture-of-Experts (MoE): An architecture that routes inputs through multiple specialized expert networks, typically via learned gating. "draws inspiration from Mixture-of-Experts \citep{Shazeer2017OutrageouslyLN}"
- Multi-Head Feed-Forward Network (MH-FFN): An FFN variant that splits processing into multiple heads, analogous to multi-head attention. "We explore Multi-Head FFN (MH-FFN) as a replacement of FFN in the Transformer architecture"
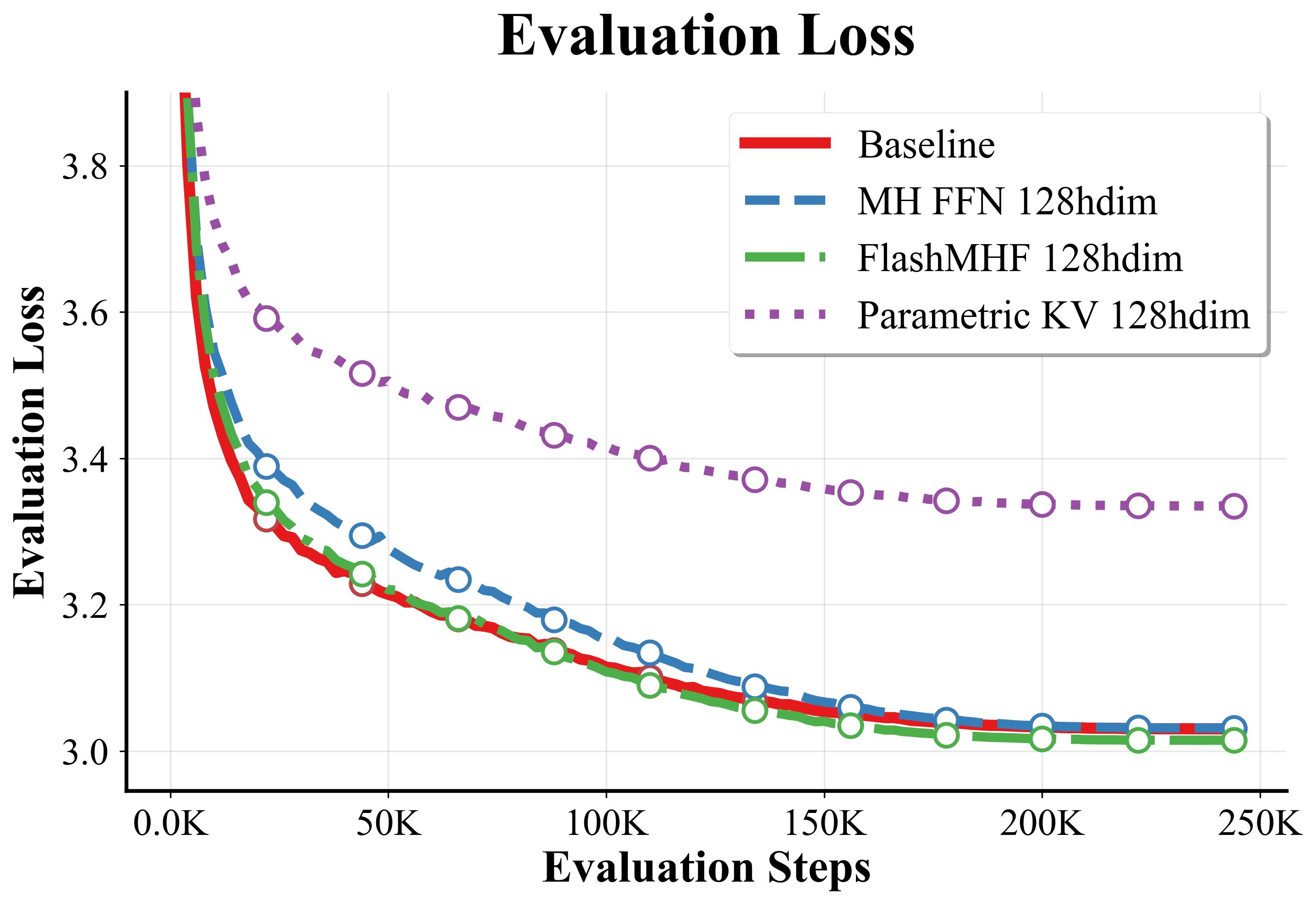
- Parametric KV (PKV): A baseline where attention keys and values are trainable parameters instead of being derived from inputs. "we introduce the PKV baseline, which replaces the {SwiGLU} FFN with a multi-head attention whose keys and values are learnable model parameters."
- perplexity: A measure of LLM uncertainty; lower values indicate better predictive performance. "Validated on models from 128M to 1.3B parameters, FlashMHF consistently improves perplexity and downstream task accuracy over SwiGLU FFNs"
- Rotary Position Embeddings (RoPE): A positional encoding method that applies rotations in feature space to incorporate token positions. "multi-head self-attention with Rotary Position Embeddings (RoPE) \citep{Su2021RoFormerET}"
- SiLU: Sigmoid Linear Unit; an activation function defined as x·sigmoid(x), also called swish. "For FFNs we write for an element-wise nonlinearity (e.g., ReLU, GeLU, SiLU)."
- SRAM: On-chip static RAM; much faster and lower-latency memory used for intermediate computations on GPUs. "an I/O-aware fused kernel computing outputs online in SRAM akin to FlashAttention"
- SwiGLU: A gated FFN activation combining SiLU and a multiplicative gate; commonly used in modern Transformers. "In modern Transformers, the gated variant is the common choice instead of vanilla ."
- SwiGLU ratio: The standard expansion ratio between FFN intermediate and model dimensions (often 8/3) used in SwiGLU layers. "We adopt the standard SwiGLU ratio by setting \citep{Touvron2023LLaMAOA}."
- top-k expert selection: Sparse routing mechanism in MoE where only the top-k experts are activated per token. "omits sparse top-k expert selection."
- warp-group specialization: A GPU optimization strategy that assigns specialized roles to warp groups to improve throughput. "techniques such as {asynchronous data movement} and {warp-group specialization}"
Collections
Sign up for free to add this paper to one or more collections.