Self-Attention at Constant Cost per Token via Symmetry-Aware Taylor Approximation
Abstract: The most widely used AI models today are Transformers employing self-attention. In its standard form, self-attention incurs costs that increase with context length, driving demand for storage, compute, and energy that is now outstripping society's ability to provide them. To help address this issue, we show that self-attention is efficiently computable to arbitrary precision with constant cost per token, achieving orders-of-magnitude reductions in memory use and computation. We derive our formulation by decomposing the conventional formulation's Taylor expansion into expressions over symmetric chains of tensor products. We exploit their symmetry to obtain feed-forward transformations that efficiently map queries and keys to coordinates in a minimal polynomial-kernel feature basis. Notably, cost is fixed inversely in proportion to head size, enabling application over a greater number of heads per token than otherwise feasible. We implement our formulation and empirically validate its correctness. Our work enables unbounded token generation at modest fixed cost, substantially reducing the infrastructure and energy demands of large-scale Transformer models. The mathematical techniques we introduce are of independent interest.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making the “self‑attention” part of Transformer AI models much cheaper to run when reading or generating very long texts. Normally, the cost per token (each word or piece of a word) grows as the text gets longer, which means more memory, more time, and more energy. The authors show a way to compute self‑attention so that the cost per token stays roughly the same no matter how long the text is, while still staying accurate. They do this by using a math shortcut called a Taylor series and a trick for avoiding repeated work by using symmetry (treating repeated patterns as one thing).
What questions are the authors asking?
- Can we compute self‑attention with a fixed, constant cost per token that does not grow with context length?
- Can we approximate the usual attention (which uses an exponential function) accurately using only a small number of terms from a Taylor series?
- Can we avoid storing every past token’s information (the “KV cache”) and instead keep a compact running summary?
- If we do this, does it actually work in practice and save memory and time?
How does their method work?
First, a tiny bit of background in everyday language:
- In Transformers, every token is turned into three vectors: a query (Q), a key (K), and a value (V). Attention decides how much each past token matters to the current one by scoring how similar the current query is to each past key, then mixing their values.
- The usual attention score uses an exponential of a dot product: roughly exp(q * k / √d). Doing this for every past token is what makes cost grow as the context gets longer.
- The “KV cache” is a running storage of all past keys and values. It grows with the number of tokens, so memory usage grows with context length.
What the authors do:
- Replace the expensive exponential with a Taylor series:
- Think of exp(x) as a recipe you can approximate by adding a few ingredients: 1 + x + x²/2! + x³/3! + ...
- Here, x is q * k / √d. If you keep just the first few terms, you get a good approximation without computing exp exactly.
- Tame the explosion of terms using symmetry:
- When you expand (q * k)p (that’s the p-th power), you get many products of q’s and k’s components. Many of these are the same except for order (like picking chocolate–vanilla is the same as vanilla–chocolate).
- The authors group “same regardless of order” combinations together. That means they only compute each unique combination once and remember how many times it occurs (its weight). This “minimal set” of unique combinations is the symmetry trick.
- Turn attention into a sum of simple inner products:
- For each degree p (0, 1, 2, ...), they map q and k into compact feature vectors that contain exactly those unique combinations.
- They precompute a diagonal weight vector that says how often each unique combination appears.
- Then (q * k)p becomes a weighted inner product of those feature vectors.
- Add up these inner products over the few Taylor terms you keep (say P = 4), and you have a good approximation of the original exponential score.
- Stream it like linear attention:
- Because inner products are linear, you can keep a running “summary” over past keys and values instead of storing them all. Think of it like keeping a scoreboard instead of saving every play.
- This makes the per‑token work constant: it depends on head sizes and how many Taylor terms you use (P), not on how many tokens you’ve seen.
Key ideas in plain terms:
- Taylor series: a shortcut that lets you approximate exp() by summing a few powers.
- Symmetry/minimal basis: compute each unique combination once instead of many times with different orders.
- Feature map: a way to turn q and k into compact, comparable lists of numbers so their similarity is easy to compute.
- Streaming/scan: update a fixed‑size summary as new tokens arrive, no matter how long the sequence gets.
What did they find and why does it matter?
Main findings:
- Accuracy: Using just four Taylor terms (P = 4) matched the standard attention very closely—within the normal rounding noise of Float16, which is already used in many AI systems. Using more terms increases accuracy further.
- Constant per‑token cost: Memory and compute per token no longer grow with context length. Instead, they depend on head sizes and P (the number of Taylor terms you keep).
- Big savings at long context: As context length grows to millions or more tokens, their method uses orders of magnitude less memory and time per token than the standard method.
- More, smaller heads become practical: Their per‑token cost actually goes down as head sizes get smaller, so you can use more heads without paying the usual linear cost increase.
Why this matters:
- It makes very long or even “endless” contexts possible at a modest, fixed cost.
- It reduces the need for huge server farms and lowers energy use, making AI services more sustainable and affordable.
- It opens up new model designs (like more attention heads) that were previously too costly.
What is the potential impact and what are the limits?
Implications:
- Long‑context AI becomes more practical: chat histories, long documents, codebases, and step‑by‑step reasoning can be handled without costs exploding.
- New tuning knob: You can choose P (the number of Taylor terms) to trade a tiny bit of accuracy for big efficiency, or vice versa.
- Better fit for memory‑limited devices: Since you don’t need to store the full KV cache, edge devices could run longer‑context models.
Limits and next steps:
- The current code is a proof of concept. With specialized, hardware‑optimized kernels, it should be even faster.
- Full end‑to‑end training with this attention needs testing to confirm downstream performance.
- You still need a positional encoding that works for very long sequences.
- The method shines with smaller head sizes and modest P; very large heads or very high P increase fixed cost per token.
In short: The paper shows a clear, math‑based way to keep attention accurate while making its cost per token constant, not growing with context length. That could make long‑context AI both faster and greener.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to enable concrete follow-up by future researchers.
- Lack of formal error bounds for the truncated Taylor approximation: No theoretical guarantees on approximation error of the exponential kernel as a function of truncation order P, head sizes, and the distribution of . Provide uniform and worst-case error bounds for the kernel and for the normalized attention output .
- Positivity and normalization issues: A finite Taylor polynomial of can be negative for sufficiently negative . This risks negative kernel values, denominators , or division instability. Characterize when can approach zero or become negative and propose mechanisms (e.g., positivity-preserving approximations, Padé/chebyshev expansions, reweighting, or clamping) to ensure safe normalization.
- Numerical stability over very long contexts: The paper demonstrates accumulation up to 100M tokens but does not analyze rounding error, catastrophic cancellation, overflow/underflow, or drift in low-precision formats (FP16/BF16/FP8) for the recurrent sums and . Develop summation schemes (e.g., Kahan, chunked scans, dynamic rescaling) and quantify stability over practical sequence lengths.
- Backpropagation complexity and training memory: Constant-cost claims focus on the forward pass. Derive gradient recurrences, analyze backward-pass FLOPs and memory footprints (including activation storage), and establish whether training can be done with constant per-token cost (or with checkpointing/reversible strategies).
- End-to-end task performance: No evaluation on trained models (from scratch or finetuned). Assess downstream accuracy, convergence behavior, and stability across NLP/vision tasks; determine how P and head sizes affect perplexity, long-range recall, and alignment.
- Break-even analysis vs optimized baselines: The paper compares against a conventional (non-fused) implementation but not against strongly optimized attention (e.g., FlashAttention) or SSMs. Provide rigorous throughput/memory/latency and energy comparisons across context lengths, head sizes, and dtypes; identify the regime where the proposed method wins.
- Multi-head and multi-layer practicality: While costs are “constant,” the hidden state size can still be large at realistic d_K, d_V, P, and many heads/layers. Quantify per-layer/per-model totals, assess feasibility on current GPUs/TPUs, and provide design guidelines for choosing d_K, d_V, and P under realistic memory budgets.
- Storage and generation of index matrices and weights: The precomputed index matrix and diagonal may be large. Measure their memory footprint, loading overhead, cache locality, and provide compressed or on-device generation strategies; exploit hierarchical structure to reduce storage and compute.
- Parallel execution of P scans: No quantitative analysis of latency, stream scheduling, resource contention, and benefits of fused kernels for the P independent scans. Develop and benchmark fused kernels; analyze throughput/latency trade-offs as P grows.
- Compatibility beyond causal self-attention: Extend and evaluate the method for encoder (bidirectional) attention, encoder–decoder cross-attention, and arbitrary masking patterns (e.g., prefix, block-sparse). Specify how masks and attention biases are incorporated into the feature-accumulation framework.
- Positional encoding at extreme lengths: The paper notes this as a dependency but provides no guidance. Identify positional encoding schemes that remain numerically and representationally stable with unbounded contexts and test their interaction with the proposed attention.
- Kernel-choice and approximation strategy: Explore alternatives to Taylor polynomials (e.g., Padé, Chebyshev, RBF expansions, or exponential series with guaranteed positivity) that may require fewer terms or provide better stability; formalize conditions under which the sum of degree-wise kernels preserves desirable properties (PSD, positivity, monotonicity).
- Impact of small head sizes on representation capacity: Since efficiency improves with smaller d_K/d_V, quantify the effect on model expressivity and task performance when increasing head count while shrinking head dimensions; identify optimal configurations.
- Adaptive truncation policies: Investigate data-dependent or head-dependent selection of P (e.g., based on the magnitude of , estimated error, or per-head variance), and study scheduling implications for parallel scans.
- Quantization compatibility: Examine accuracy and stability under BF16, FP8, and INT8 quantization, including required accumulation precision and calibration rules to avoid saturation in higher-order monomial features.
- Real-activation distributions: Reconstruction experiments use synthetic Gaussian inputs. Characterize statistics in trained models, typical ranges of , and how these affect required P, error, and stability.
- Incorporating masks and additive biases: Conventional attention supports causal masks, padding masks, ALiBi/relative position biases, and temperature schedules. Specify and validate how such terms are embedded into the symmetry-aware feature framework without breaking associativity or stability.
- Denominator regularization: Provide principled safeguards (e.g., epsilon-stabilization, lower bounds, or renormalization strategies) to prevent division by near-zero and to control sensitivity of to small denominator errors.
- Feature-space compression at higher orders: Propose and evaluate concrete compression schemes (e.g., dropping low-weight basis components using , low-rank approximations, structured sparsity, random projections) with quantified error and speed gains.
- Distributed training/inference: Detail how per-degree states are partitioned and synchronized across devices; analyze communication overhead and consistency in pipeline/data parallel settings.
- Convergence rates on relevant domains: Derive explicit convergence rates of the truncated series on intervals determined by typical ranges, and map these to P choices for a target error .
- Comparative accuracy vs other linear attention approaches: Provide head-to-head evaluations against Performer, linear transformers with exponential feature maps, and Taylor-based quadratic methods, quantifying accuracy, stability, and cost at matched settings.
- Sensitivity to scaling : Analyze how the standard scaling interacts with the polynomial approximation and with head size, and whether alternative normalizations reduce required P or improve stability.
- Formal proof and constructive algorithm for combinatorial weights: The diagonal entries of encode multiplicities; supply a complete derivation, constructive algorithms, and complexity analysis for building efficiently and exactly for arbitrary .
Practical Applications
Immediate Applications
The following applications can be deployed now by swapping conventional self-attention with the paper’s symmetry-aware Taylor approximation (SATA) attention, using the provided PyTorch implementation and standard linear-attention workflows. Each item notes sector(s), potential tools/workflows, and critical assumptions or dependencies.
- Large-scale LLM inference with long context at fixed per-token cost
- Sectors: software, cloud, enterprise IT
- What: Replace KV-cache attention in inference servers (e.g., vLLM/TGI-style stacks) with SATA to serve chat assistants, copilots, and RAG systems that need very long histories without per-token cost growth.
- Tools/Workflows: PyTorch module; parallel prefix-scan pipelines; batched multi-head configurations with smaller head dimensions; A/B tuning of Taylor truncation order P (start at P≈4); observability for error vs throughput.
- Assumptions/Dependencies: Acceptable approximation at P≈4 (Float16-like error floor); positional encodings (e.g., RoPE variants) must support long sequences; best performance requires fused CUDA/Triton kernels (paper’s current PoC works but is not fully optimized).
- Cost and energy reduction in data centers running LLMs
- Sectors: energy, cloud operations, sustainability reporting
- What: Lower GPU memory footprint by eliminating growing KV caches and reduce FLOPs per token; throttle energy use with bounded per-token work regardless of context length.
- Tools/Workflows: Capacity planning models that assume O(1) per-token cost; carbon accounting dashboards; scheduling policies that prefer SATA-enabled models for long sessions.
- Assumptions/Dependencies: End-to-end bottlenecks may shift to other layers; measured gains improve with optimized kernels and parallel evaluation of Taylor terms.
- Edge deployment of long-context assistants
- Sectors: mobile, embedded/IoT, automotive
- What: Run on-device assistants (smartphones, wearables, vehicle head units) with persistent user memory without streaming large KV caches to cloud.
- Tools/Workflows: On-device inference stacks (CoreML/NNAPI + custom CUDA/Triton where available); quantized models with small heads; streaming accumulation of SATA states.
- Assumptions/Dependencies: Hardware must support parallel scan and enough local memory for fixed hidden state; task tolerance to approximation error.
- Streaming transcription/translation and time-series modeling with unbounded sequences
- Sectors: speech, media, industrial monitoring, finance
- What: Continuous processing (ASR, translation, anomaly detection) where context grows indefinitely; swap in SATA to bound per-token compute and memory.
- Tools/Workflows: Real-time pipelines with prefix-scan accumulators per Taylor term; windowless streaming modes; telemetry on approximation drift.
- Assumptions/Dependencies: Stable positional encoding for long streams; domain-specific acceptance criteria for minor kernel approximation errors.
- Multi-head designs with many small heads
- Sectors: model design/research, software
- What: Exploit SATA’s inverse scaling with head size to distribute attention across more, smaller heads without linear cost growth; useful in inference-only model variants.
- Tools/Workflows: Architecture configs that lower d_K/d_V and raise number of heads; tuning P jointly with head size for accuracy/throughput trade-offs.
- Assumptions/Dependencies: Accuracy must be validated for chosen head configurations; may require light fine-tuning after swapping attention.
- Academic teaching and reproducible research on efficient attention
- Sectors: academia, education
- What: Use the open-source repo to teach symmetry-aware feature maps, kernel approximations, and parallel scan; benchmark long-context attention complexity.
- Tools/Workflows: Course labs; reproducible notebooks comparing KV-cache vs SATA; experiments on precision vs P; exploratory projects on symmetric indices.
- Assumptions/Dependencies: PoC code suffices for pedagogy; deeper performance studies will need optimized kernels.
- Policy pilots for “green AI” procurement
- Sectors: policy, public sector IT
- What: Encourage agencies to adopt constant-cost attention in inference systems for citizen-facing services with long histories, reducing energy demand.
- Tools/Workflows: Procurement checklists favoring O(1) per-token attention; pilot deployments in call centers/portals; energy monitoring baselines.
- Assumptions/Dependencies: Policy acceptance of approximation-based methods; verification of user-perceived quality under P≈3–5.
- Daily life: “infinite context” personal assistants
- Sectors: consumer software
- What: Personal note-taking/chat history that never truncates; assistants can recall long-term preferences and activities without escalating device cost.
- Tools/Workflows: Apps with on-device SATA attention; persistent attention state storage; user controls for accuracy/performance mode (adjust P).
- Assumptions/Dependencies: Privacy-preserving local storage; positional encoding compatible with very long sequences.
Long-Term Applications
These require further research, scaling, or development, including optimized kernels, end-to-end training, and broader ecosystem changes.
- Fully trained SATA-Transformers with end-to-end evaluation
- Sectors: software, academia
- What: Train models from scratch or via transfer learning using SATA attention; quantify downstream accuracy, convergence, and stability across tasks.
- Tools/Workflows: Fused CUDA/Triton kernels; mixed precision regimes; curriculum to increase P as needed; task-specific validation suites.
- Assumptions/Dependencies: Training dynamics under approximated Softmax kernel; potential need for architectural tweaks (e.g., normalization, gating).
- Hardware and compiler support for symmetry-aware feature maps
- Sectors: semiconductors, systems software
- What: New instructions/kernels that avoid temporary copies and exploit hierarchical symmetric indices; compiler passes to fuse multi-term scans.
- Tools/Workflows: Vendor libraries (cuDNN/ROCm) with SATA primitives; graph compilers (TVM/XLA) that recognize and optimize Phi_p and C_p patterns.
- Assumptions/Dependencies: Hardware roadmaps; cooperation from ecosystem maintainers; cost-effective engineering to achieve near-theoretical gains.
- Adaptive and dynamic approximation orders
- Sectors: software, research
- What: Runtime systems that adjust Taylor truncation P per head/token based on confidence/entropy, or data distribution, balancing accuracy and cost.
- Tools/Workflows: Controllers for P; per-head error monitors; mixture-of-degrees modules; fallback to conventional attention for “hard” tokens.
- Assumptions/Dependencies: Reliable error proxies; negligible control overhead; stability guarantees.
- Compressed higher-order feature spaces
- Sectors: software, research
- What: Dimensionality reduction for large p (e.g., random projections, low-rank bases, coefficient pruning from C_p) to keep state small while improving accuracy.
- Tools/Workflows: Offline basis design; training-time regularizers; approximate feature maps with bounded error.
- Assumptions/Dependencies: Error bounds under compression; domain-specific tolerance.
- Extensions to other analytic kernels and attention variants
- Sectors: machine learning research
- What: Apply symmetry-aware approximations to alternative kernels (beyond exponential/Softmax), e.g., Gaussian/RBF or task-specific kernels.
- Tools/Workflows: Kernel library with feature-map generators; comparative studies of attention patterns and inductive biases.
- Assumptions/Dependencies: Mathematical tractability; integration with normalization schemes; stability in training.
- “Infinite-context” product lines
- Sectors: healthcare, legal, finance, education
- What: Assistants that retain unbounded patient histories, case files, compliance logs, or student records while running on bounded compute.
- Tools/Workflows: Sector-specific workflows (EHR summarization, legal drafting, audit trails, personalized tutoring) backed by persistent SATA states.
- Assumptions/Dependencies: Robust privacy, governance, and positional encoding at extreme lengths; domain validation of approximation effects.
- Robotics and real-time control with streaming attention
- Sectors: robotics, autonomous systems
- What: Controllers that leverage long episodic memory without scaling cost; interpret long sensor streams for situational awareness.
- Tools/Workflows: Real-time pipelines; safety monitors; SATA-aware control stacks.
- Assumptions/Dependencies: Hard real-time constraints; certification and safety validation.
- Cloud pricing and resource scheduling reforms
- Sectors: cloud, policy
- What: Billing models that reflect O(1) per-token cost for long sessions; schedulers that prefer SATA models for sustained workloads.
- Tools/Workflows: Cost models; SLAs for infinite-context tiers; sustainability-linked pricing.
- Assumptions/Dependencies: Customer education; verified performance at scale; interoperability with existing inference frameworks.
- Standards and governance for energy-efficient AI
- Sectors: policy, standards bodies
- What: Formalize best practices for constant-cost attention in public-sector and enterprise deployments; include approximation standards and audit methods.
- Tools/Workflows: Benchmarks for energy/latency vs P; conformance tests; reporting templates.
- Assumptions/Dependencies: Consensus on acceptable approximation levels; independent evaluation infrastructure.
- Multimodal long-context AI (video/audio/time-series)
- Sectors: media, surveillance, industrial IoT
- What: Unified long-context attention for multimodal streams (video frames, audio, telemetry) with bounded per-token cost.
- Tools/Workflows: Cross-modal SATA attention layers; streaming feature accumulation by modality; adaptive P per modality/head.
- Assumptions/Dependencies: Modal-specific positional encodings; domain robustness under approximation.
Notes on feasibility across all applications:
- Numerical precision and accuracy depend on P, head sizes (d_K, d_V), and data distributions; many inference tasks tolerate P≈3–5, but mission-critical domains may require validation or dynamic fallback.
- Positional encoding must support extreme sequence lengths; SATA does not replace that requirement.
- Realizing the full performance potential requires optimized device kernels, parallel evaluation of Taylor terms, and avoiding temporary data copies as highlighted in the paper’s implementation notes.
- Training-time behavior is an open area; early deployments should prioritize inference-only swaps or light fine-tuning and monitor downstream quality.
Glossary
- Accumulated state: A running feature/state summary maintained across tokens for streaming computation; it replaces storing all past keys/values. "the number of elements in accumulated state, per token, for linear attention"
- Autocasting: Automatic selection of floating‑point precision per operation by the framework to meet accuracy needs while improving performance. "All operations are executed with autocasting, {\em i.e.}, letting PyTorch decide which floating-point format to use, as necessary, for matching the precision required by each operation."
- Causal self-attention: Attention that only considers past (and current) tokens when computing the current token’s output. "Consider causal self-attention over a sequence of tokens"
- Diagonal weight matrix: A square matrix with nonzero entries only on its diagonal, used to weight feature components in an inner product. "C_p \in \mathbb{R}{m_p \times m_p} is a constant diagonal weight matrix"
- Embarrassingly parallel: A computation that can be performed in parallel without dependencies or communication among tasks. "a maximally succinct, computationally efficient, embarrassingly parallel transformation."
- Exponential kernel: A kernel function of the form k(q,k)=exp((qT k)/c) that underlies the Softmax attention. "approximates the exponential kernel underlying its Softmax function while eliminating its dependence on context length."
- Exponentiated dot product: The exponential of a scaled dot product, central to Softmax attention weights. "the exponentiated dot product can be approximated as a weighted sum of inner products."
- Feature map: A mapping from input vectors to a higher-dimensional feature space in which kernel evaluations become inner products. "This naturally suggests defining a feature map "
- FLOPs: The count of floating‑point operations (multiplies and adds) required by a computation; used to measure computational cost. "a constant number of floating-point operations (FLOPs) per token in the forward pass"
- Hadamard product: Elementwise multiplication of two tensors/vectors of the same shape. "where denotes elementwise (Hadamard) product"
- Head size: The dimensionality of a Transformer attention head (e.g., d_K for keys, d_V for values). "Notably, cost is fixed inversely in proportion to head size"
- Hidden state size: The number of elements in the accumulated state needed per token to compute linear attention. "We define ``hidden state size'' as the number of elements in accumulated state, per token, for linear attention (Appendix~\ref{appsec:linear_attention})."
- Key--value cache (KV cache): Memory that stores past keys and values for all tokens to compute attention at later steps. "the key--value cache (``KV cache,'' for short)"
- Kernel function: A function that implicitly defines an inner product in a feature space, enabling kernel methods. "evaluates the associated kernel function to arbitrary Taylor truncation order at constant cost per token."
- Linear attention: Attention mechanisms that can be computed via streaming accumulation (without a full attention matrix), often using kernel features. "Our formulation is a form of linear attention"
- Linear recurrence: A recurrence relation where the update is a linear function of the previous state and input; amenable to parallel scans. "RNNs with linear recurrences computable via parallel scan"
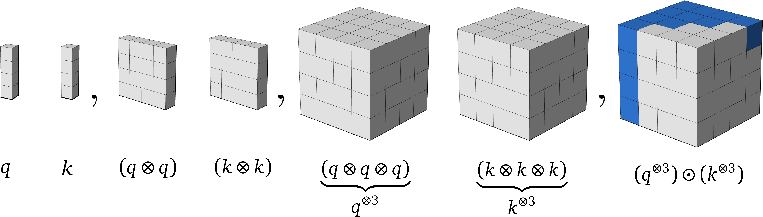
- Minimal basis: The smallest set of unique monomials needed to represent all polynomial interactions of a given degree. "contain the unique monomials combining elements of and , respectively, that make up the {\em minimal basis}"
- Monomial: A single-term product of variables raised to nonnegative integer powers (e.g., q_i q_j …). "contains the unique monomials"
- Parallel prefix-sum (scan): A parallel algorithm that computes all prefix sums of a sequence, used to evaluate linear recurrences efficiently. "can therefore be computed efficiently via either sequential recurrence or parallel prefix-sum (scan)."
- Parallel scan: The parallel computation of prefix operations across a sequence; used to make attention linear-time. "computable via parallel scan"
- Polynomial-kernel feature basis: The set of feature coordinates corresponding to polynomial kernel monomials used to approximate the exponential kernel. "minimal polynomial-kernel feature basis"
- Positional encoding: A scheme that injects position information into token embeddings to allow sequence order to be modeled. "so long as the Transformer's positional encoding scheme can accommodate sequences of indefinite length."
- Reproducing kernel Hilbert space (RKHS): A Hilbert space in which evaluation at a point is represented by an inner product with a kernel function. "there exists a reproducing kernel Hilbert space (RKHS)"
- Softmax: A normalization function that turns scores into probabilities via exponentiation and normalization. "underlying its Softmax function"
- State space models (SSMs): Sequence models that evolve a hidden state via structured (often linear) state-space dynamics. "including state space models (SSMs)"
- Symmetric tensor: A tensor whose entries are invariant under permutations of indices, leading to repeated elements outside an ordered region. "are order- symmetric tensors obtained by chains of tensor products:"
- Taylor expansion: A series that expresses a function as an infinite sum of polynomial terms derived from derivatives at a point. "The core operation's Taylor expansion is:"
- Tensor (outer) product: The operation that forms a higher-order tensor by multiplying vectors componentwise across dimensions. "and denotes tensor (outer) product."
- Upper hyper-triangular region: The subset of a symmetric tensor indexed by nondecreasing indices that contains all unique elements. "its upper hyper-triangular region, consisting of"
- Weighted inner product: An inner product modified by a weighting matrix (often diagonal) to account for multiplicities or scaling of features. "can be written as a weighted inner product"
Collections
Sign up for free to add this paper to one or more collections.