Fast and Simplex: 2-Simplicial Attention in Triton
Published 3 Jul 2025 in cs.LG and cs.AI | (2507.02754v1)
Abstract: Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern LLMs increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that $2$-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.
The paper introduces a Triton-optimized 2-simplicial Transformer that alters scaling laws and improves token efficiency for reasoning tasks.
It details a sliding-window approach and kernel optimizations that reduce the cubic complexity of trilinear attention.
Experimental results demonstrate enhanced performance on math, coding, and logic benchmarks compared to standard dot-product attention.
Fast and Simplex: 2-Simplicial Attention in Triton
The paper "Fast and Simplex: 2-Simplicial Attention in Triton" (2507.02754) introduces an efficient implementation of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions. By optimizing the implementation using Triton, the authors demonstrate improved token efficiency compared to standard Transformers, particularly on tasks requiring mathematics, coding, reasoning, and logic. The paper quantifies these gains by showing that 2-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks relative to dot product attention.
Background and Motivation
Scaling laws in LLMs suggest that training loss decreases as a power law with both model size and the number of tokens. Compute-optimal models require scaling model size and token count together. However, modern LLMs increasingly rely on massive internet-scale datasets, making the assumption that they are compute-bound less valid. This shift highlights the need for architectures that prioritize token efficiency, and the paper revisits and optimizes the 2-simplicial Transformer [clift2019logic] to address this need. Prior research indicates that most architectural and optimizer improvements do not fundamentally alter the power-law exponent governing scaling, but the authors posit that 2-simplicial attention can offer such a change.
2-Simplicial Attention
The 2-simplicial Transformer extends dot-product attention from bilinear to trilinear forms. In standard attention, given a sequence X∈Rn×d, query Q, key K, and value V projections are computed. The attention logits are then given by A=QK⊤/d. The 2-simplicial Transformer introduces additional key and value projections, K′ and V′, and computes attention logits as a trilinear product:
The final output is a linear combination of values, weighted by attention scores.
(Figure 1)
Figure 1: Geometry of dot product attention and 2-simplical attention.
Rotation Invariant Trilinear Forms
The paper explores generalizations of RoPE to trilinear functions, presenting a rotation-invariant trilinear form. Standard RoPE captures positional information in a sequence by applying position-dependent rotations to queries and keys, such that the dot product is a function of the relative distance i−j. The authors note that the basic trilinear form is not invariant to rotation, and propose an alternative using determinants:
This determinant-based approach involves six terms, requiring two einsums in the implementation, compared to one einsum for the simpler trilinear form.
Model Design and Kernel Optimization
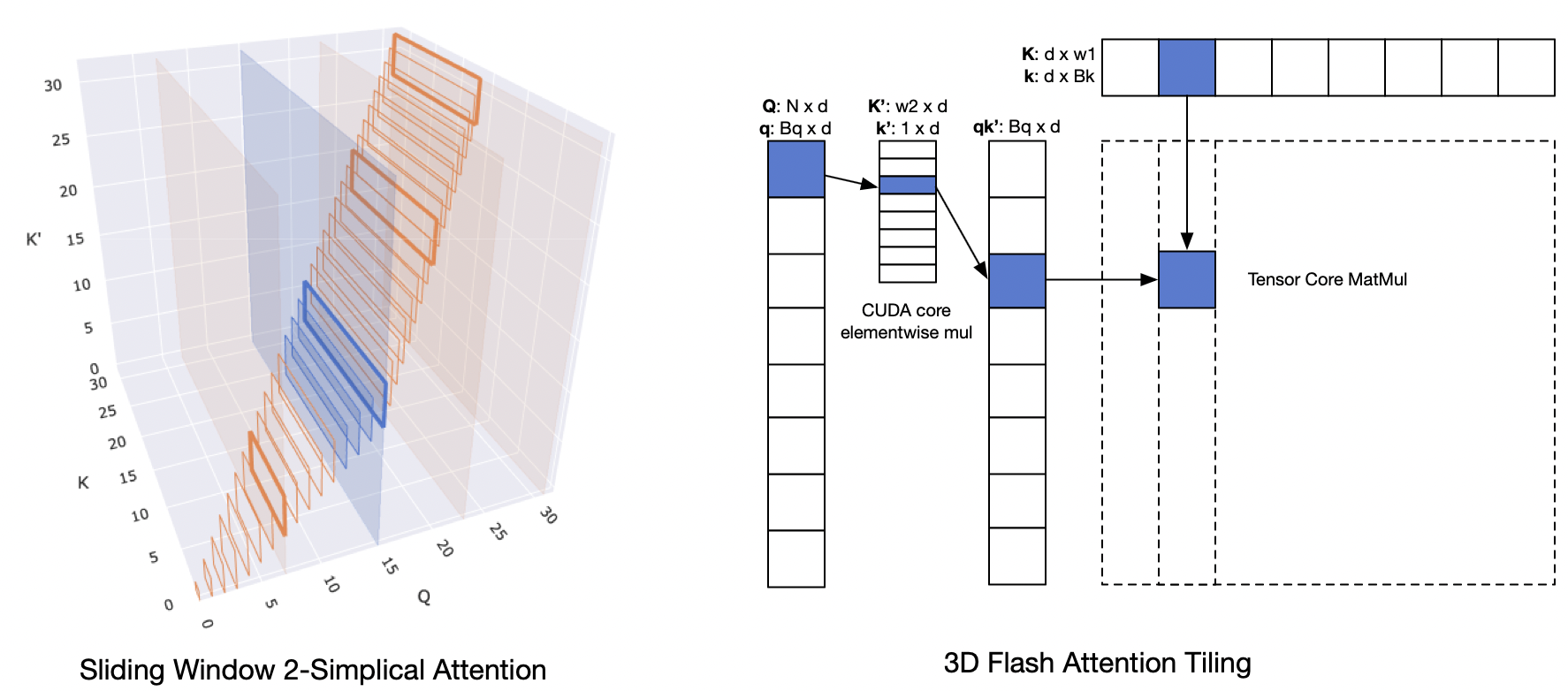
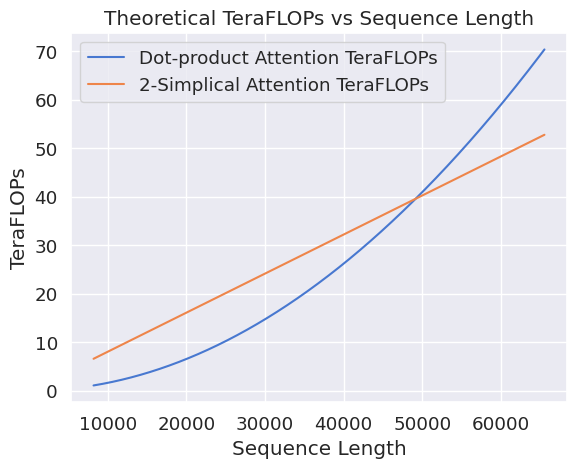
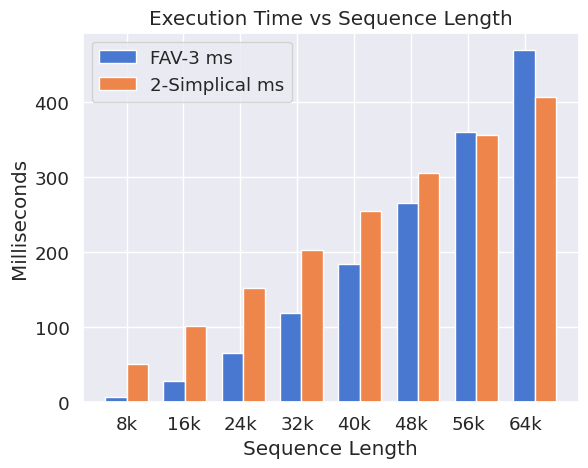
Due to the O(n3) scaling of 2-simplicial attention, the authors employ a sliding window approach, parameterizing the computation as O(n×w1×w2), where w1 and w2 define the dimensions of the sliding window. A window size of (512, 32) is chosen to balance latency and quality, making the computational complexity comparable to dot-product attention at 48k context length. Inspired by Native Sparse Attention, the model architecture leverages a high GQA ratio of 64, enabling efficient tiling along query heads. The authors introduce kernel optimizations for 2-simplicial attention, building on Flash Attention and using online softmax. 2D tiling is performed by merging one of the inputs via elementwise multiplication and executing matmul on the product. This allows overlapping QK and VV′ on CUDA cores with (QK)@K′ and P@(VV′) on Tensor Cores, achieving 520 TFLOPS in Triton.
Figure 2: Left: Visualization of sliding window 2-simplical attention. Each Qi attends to a [w1,w2] shaped rectangle of K, K′. Right: Tiling to reduce
2-simplicial einsum QKK′ to elementwise mul QK′ on CUDA core and tiled matmul (QK′)@K on tensor core.
Figure 3: FLOPs and Latencies of FAv3 vs 2-simplical attention.
For the backward pass, the authors decompose it into two distinct kernels: one for computing dK and dV, and another for dK′, dV′, and dQ. This approach reduces overhead from atomic operations.
Experimental Results
The authors trained a series of MoE models, ranging from 1 billion to 3.5 billion active parameters, with interleaved sliding-window 2-simplicial attention. Every fourth layer is a 2-simplicial attention layer to distribute the computational load when using pipeline parallelism. The models were evaluated on GSM8k, MMLU, MMLU-pro, and MBPP benchmarks.
The experiments demonstrated that the decrease in negative log-likelihood scaling from a 1.0 billion (active) parameter model increases going to a 3.5 billion (active) parameter model. The results also showed that models smaller than 2.0 billion (active) parameters did not benefit from 2-simplicial attention. By fitting parametric functions to the loss, the authors estimated the exponents in the scaling laws for both Transformer and 2-simplicial attention models. The 2-simplicial attention model exhibited a steeper slope α in its scaling law compared to the dot-product attention Transformer, indicating a more favorable scaling under token constraints.
Conclusions
The paper presents a Triton-optimized implementation of the 2-simplicial Transformer, demonstrating improved token efficiency on reasoning, math, and coding problems. The authors quantify these improvements by showing that 2-simplicial attention changes the exponent in the scaling law, leading to more favorable scaling under token constraints. While the Triton kernel is efficient for prototyping, the authors note that further co-design with hardware accelerators is needed for production use.