Shaping capabilities with token-level data filtering
Abstract: Current approaches to reducing undesired capabilities in LLMs are largely post hoc, and can thus be easily bypassed by adversaries. A natural alternative is to shape capabilities during pretraining itself. On the proxy task of removing medical capabilities, we show that the simple intervention of filtering pretraining data is highly effective, robust, and inexpensive at scale. Inspired by work on data attribution, we show that filtering tokens is more effective than filtering documents, achieving the same hit to undesired capabilities at a lower cost to benign ones. Training models spanning two orders of magnitude, we then demonstrate that filtering gets more effective with scale: for our largest models, token filtering leads to a 7000x compute slowdown on the forget domain. We also show that models trained with token filtering can still be aligned on the forget domain. Along the way, we introduce a methodology for labeling tokens with sparse autoencoders and distilling cheap, high-quality classifiers. We also demonstrate that filtering can be robust to noisy labels with sufficient pretraining compute.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a new way to prevent AI LLMs from learning skills we don’t want them to have. Instead of trying to block or remove dangerous behavior after the model is trained, the authors shape what the model learns during training. As a test case, they try to make models “forget” medical know-how while keeping other useful skills like general biology, science, and everyday knowledge.
Key Questions
The paper focuses on a few simple questions:
- Can we stop a model from learning certain knowledge (like medical details) by filtering the training data before or during training?
- Is it better to filter at the level of whole documents (like removing entire articles) or at the level of individual tokens (small pieces of text, like words or word parts)?
- Does this approach still let us control the model’s behavior later (for example, getting it to politely refuse dangerous questions)?
- Is this filtering approach hard to break if someone tries to “re-teach” the model the forbidden skills after the fact?
- Can we do all this cheaply and at scale, even if our labels are a bit noisy or imperfect?
Methods and Approach (in everyday terms)
Think of training a LLM like teaching a student by giving them a huge library to read. The student learns everything that’s in the books. If you don’t want the student to learn certain topics (say, detailed medical procedures), you can:
- Remove entire books or articles that contain medical content (document-level filtering).
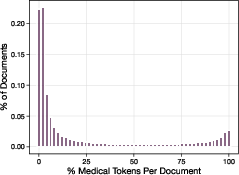
- Or, more precisely, black out only the specific words and phrases about medical content inside otherwise useful books (token-level filtering).
The authors compare both strategies and introduce practical tools to make token-level filtering work well:
- Token-level filtering: They try two versions:
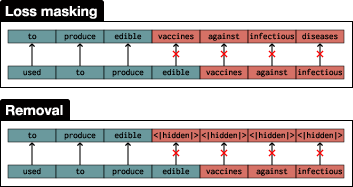
- Loss masking: The model sees medical tokens in context but those tokens don’t count toward what it learns (like reading a sentence but ignoring certain words for grading).
- Removal: They replace medical tokens with a special placeholder (like [hidden]) so those tokens aren’t seen or learned at all.
- Classifiers: They train small, efficient models to spot medical tokens. These classifiers act like smart highlighters: they mark which parts of text are medical.
- Sparse autoencoders (SAEs): This is a technique that finds patterns in how a large model’s “brain” lights up for different concepts. The authors use SAEs to generate weak labels—rough guides for which tokens look medical—then train better, cheaper classifiers on top of those labels. You can think of SAEs like microscopes that help identify “medical-feeling” patterns, which are then used to teach a simpler tool to recognize medical tokens in new text.
- Evaluation: They check results in three ways:
- Text difficulty (perplexity): Does the model struggle with medical text more than normal?
- Multiple-choice tests (like exam questions): Does the model get medical questions wrong while still doing fine on biology, math, or other topics?
- Free-response answers: Can the model write helpful answers for normal questions but fail to provide correct medical advice?
They also test robustness: if someone tries to fine-tune (retrain) the model later to re-learn medicine, how hard is it to get back those skills? And they test alignment: can we still teach the filtered model to politely refuse medical questions rather than give risky answers?
Main Findings and Why They Matter
Here are the key results, introduced by a short sentence and then listed for clarity:
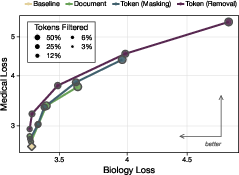
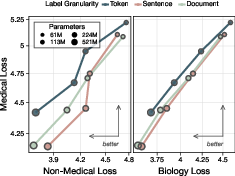
To stop unwanted skills, token-level filtering works better than document-level filtering and becomes even more effective for larger models.
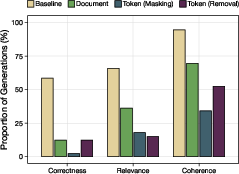
- Token filtering beats document filtering: By removing just the specific medical tokens (rather than entire documents), the model loses medical skill but keeps more of the good, related skills. This is a “Pareto improvement”—better tradeoffs all around.
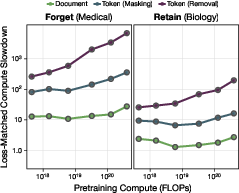
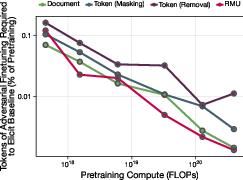
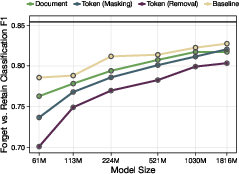
- Bigger models, stronger effect: As models get larger, token filtering reduces medical capability more and more compared to an unfiltered model. For their largest models, token filtering caused about a 7000× “compute slowdown” on the medical domain. Plain English: it would take about 7000 times more training effort to reach the same medical skill as an unfiltered model.
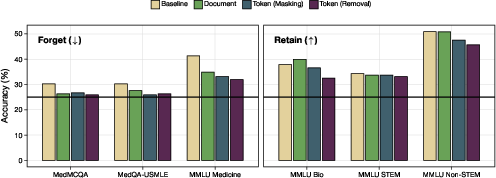
- Real-task tests: On medical multiple-choice exams (like MedMCQA and USMLE-style questions), filtered models scored near chance, showing they truly “forgot” medical knowledge. Meanwhile, their performance on other subjects (biology, STEM, non-STEM) stayed strong.
- Free-response quality: When asked open-ended medical questions, token-filtered models gave answers that were much less coherent, relevant, and correct (this is what you want if you’re trying to remove medical capabilities). But on non-medical tasks, they were fine.
- Harder to re-teach (robustness): Compared to a leading “unlearning” method used after training, models filtered during pretraining were much harder to re-train back to medical skill with a small fine-tuning dataset. In short, filtering during training is harder to undo than post-training fixes.
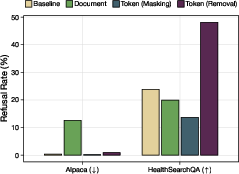
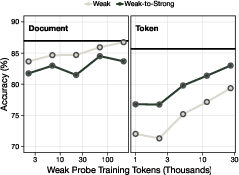
- Alignment stays possible—and can get easier: Despite removing medical knowledge, token-filtered models can still be trained to recognize medical questions and refuse them politely. In fact, token removal sometimes made this refusal behavior easier to teach and more reliable than for document filtering.
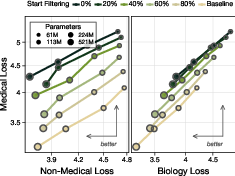
- Noisy labels still work: Even if the token classifier isn’t perfect, you can set the threshold to be more cautious (high recall: catch more of the medical tokens) and still get strong filtering results, especially with enough training compute.
- Cheap, effective classifiers: By using SAEs to create weak labels and then distilling them into small bidirectional models (two simpler models that read left-to-right and right-to-left), the authors built accurate token classifiers that are much cheaper than big general-purpose models.
Why this matters: Today, many safety methods try to teach models to behave well after they already learned everything (“post hoc”). Those can be bypassed by tricks or by retraining the model. This paper shows that if you filter the training data smartly—especially at the token level—you can significantly weaken the unwanted capability in the base model itself, making later misuse much harder.
Implications and Potential Impact
- Safer foundation models: Training-time filtering helps ensure the model never becomes strong in dangerous areas (like detailed medical advice, bio threats, disinformation techniques), making downstream safety simpler and more reliable.
- More robust to attacks: Because the base model itself lacks the skill, attackers have a much harder time restoring it with small fine-tunes or jailbreaks.
- Better precision with less collateral damage: Token-level filtering lets developers target only the risky parts of text without throwing away useful content, preserving beneficial capabilities.
- Practical and scalable: The approach uses small, task-focused classifiers and works even with imperfect labels. It gets more effective as models get larger—a rare advantage in modern AI scaling.
- Still alignable: You can still train filtered models to recognize and refuse dangerous questions, striking a balance between safety (do not help with risky tasks) and usefulness (answer normal questions well).
In short, this paper suggests a practical blueprint for building LLMs that are strong where we want them to be—and weak where we need them to be—by shaping what they learn from the very start.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address:
- Validate external generalization: test token-level filtering beyond the proxy “medical” domain on truly dangerous capabilities (CBRN, cyber-offense, dual-use wet lab, radiological) using established risk benchmarks (e.g., WMDP, biorisk evals) and larger models.
- Scale limits: assess whether the reported effectiveness and robustness trends persist at frontier model scales (≥10B–70B+ parameters) and pretraining corpora of trillions of tokens, not just up to 1.8B on FineWeb-Edu.
- Retain-domain breadth: quantify impacts on a broader set of desired capabilities (coding, math, reasoning, multilingual, long-form writing, retrieval, tool-use) to detect subtle off-target damage not captured by biology/STEM/non-STEM MMLU slices.
- Benchmark diversity: complement MedMCQA/MedQA/HealthSearchQA with clinical reasoning, procedural knowledge, and step-by-step tasks; include standardized instruction mixes (e.g., Flan, Tulu, UltraFeedback) to reduce confounds from custom SFT.
- Evaluation reliability: replace single-LLM judging (Claude Sonnet 4) with multi-judge setups, human raters, rubric-based scoring, and inter-rater reliability analyses; quantify judge bias relative to ground truth.
- Adversarial finetuning coverage: stress-test robustness under diverse attacker recipes (LoRA/QLoRA, full finetuning, mixtures with chain-of-thought, instruction poisoning, synthetic curricula, large compute budgets) and measure regained downstream capabilities (not only perplexity).
- Tokenization sensitivity: study how different tokenizers (BPE, SentencePiece, WordPiece, multilingual tokenizers) and segmentation rules affect classifier recall/precision and filtering efficacy, especially for multilingual and domain-specific subwords.
- Cross-domain leakage: measure whether models reconstruct forbidden capabilities from related retain domains (e.g., medical physiology via biology; cyber-offense via general programming) and characterize the minimal “leakage pathways.”
- Loss masking vs removal trade-offs: conduct mechanistic analyses to quantify how each method encodes or suppresses forbidden representations, impacts context coherence and long-range dependencies, and alters internal circuits across layers.
- Soft filtering variants: explore graded loss weighting, curriculum schedules, and learnable gates (e.g., dynamic confidence-weighted masking) versus hard masking/removal to balance recall and collateral damage.
- Combined interventions: evaluate whether data filtering composes with unlearning, representational editing, gradient routing, or post hoc safety training to yield additive or synergistic robustness, and identify conflicts.
- Alignment generality: test refusal alignment across multiple simultaneous forget domains, measure fine-grained control (subdomain discrimination), and probe failure modes (e.g., inappropriate refusals on benign queries).
- Boundary ambiguity: quantify sensitivity near domain boundaries (e.g., medicine vs biology; cybersecurity vs general IT) with fine-grained subdomain probes and measure false positive/negative rates under realistic ambiguity.
- Classifier calibration and abstention: analyze calibration, selective prediction, and abstain options; incorporate active learning to preferentially label uncertain spans and reduce systematic mislabeling.
- Label noise tolerance curves: systematically map filtering effectiveness versus classifier precision/recall under controlled noise levels, varying thresholds and pretraining compute, to derive practical operating points.
- SAE label dependence: test robustness of SAE-based labeling across layers, SAE widths, training regimes, autointerp quality, and base models; compare against alternative weak labeling methods (pattern matching, keyword spans, distant supervision).
- Retokenization artifacts: quantify mislabeling introduced by mapping SAE labels to different tokenizers and evaluate span-consistency strategies to minimize label fragmentation.
- Compute accounting: provide end-to-end cost-benefit analyses that include classifier pretraining/inference, data labeling, and filtering overheads; validate “7000× compute slowdown” using capability-centric metrics (accuracy/sample efficiency), not only matched-loss interpolation.
- Training dynamics side-effects: investigate whether masking/removal induces distribution shifts, harms discourse coherence, degrades rare-token handling, or alters optimization stability (e.g., gradient variance, catastrophic forgetting of nearby concepts).
- Data pipeline integration: detail scalable engineering for token-level filtering over trillion-token corpora (I/O throughput, streaming inference, memory footprint, dedup interaction), and quantify failure modes at ingestion time.
- Jailbreak resistance at inference: measure how filtering interacts with at-deployment defenses (system prompts, input/output and internals-based classifiers), and whether token-filtered bases reduce jailbreak surface area compared to unfiltered baselines.
- Retrieval and tool-use impacts: evaluate filtered models in RAG/tool-use scenarios where forbidden tokens may appear in context, including effects on refusal, extraction, and reasoning fidelity when ‘seeing’ but not ‘learning’ forbidden content.
- Safety outcomes: assess whether suppression of medical knowledge leads to harmful misinformation or unsafe behavior (e.g., false confident answers) with clinically grounded metrics and adverse outcome scoring.
- Long-term maintainability: study drift and domain evolution (new medical/cyber terminology), classifier updating schedules, and robustness to time-shifted corpora; quantify the cost of keeping filters current.
- Open-world generalization: examine feasibility of filtering in settings with multimodal data (images, code execution traces), mixed-language documents, and noisy web content, including cross-modal transfer of forbidden capabilities.
Practical Applications
Capability shaping via token-level data filtering offers a practical way to reduce specific, undesired model skills during pretraining while preserving desired ones. The paper demonstrates that token-level filtering (loss masking or removal) Pareto-dominates document-level filtering, becomes more effective with scale (up to a 7000× effective compute slowdown on the “forget” domain for 1.8B models), is more robust than state-of-the-art unlearning to adversarial fine-tuning, and does not impede (and can improve) alignment and refusal training. It also contributes a reusable pipeline for weakly supervised token labeling using sparse autoencoders (SAEs) and linear-probe classifiers.
Below are actionable applications, grouped by deployment horizon.
Immediate Applications
The following applications can be adopted now with modest engineering effort and standard compute, especially for small-to-mid-scale models or domain-limited pretraining.
- Industry safety pipelines: integrate token-level filtering into pretraining
- Sectors: software/AI labs, platform safety, open-source model builders
- What: add a token-level classifier and loss-masking/removal in the pretraining data loader to suppress risky domains (e.g., biorisk, malware, violent/sexual content), while preserving adjacent skills (e.g., biology, general coding).
- Tools/workflows: SAE-assisted weak labeling → small biLM classifier (linear probe) → token filtering with adjustable threshold; track “effective compute slowdown on forget domain” as a safety metric; routine adversarial fine-tuning tests.
- Dependencies/assumptions: access to pretraining loop; domain-specific labeled corpora; classifier quality (F1/recall); acceptance of the proxy (medical) result generalizing to target domains.
- Compliance-graded, capability-shaped model variants for regulated sectors
- Sectors: healthcare, finance, legal, education, enterprise SaaS
- What: ship base models tailored to refuse specific classes of advice (diagnosis, prescribing, investment/legal guidance, exam solutions) without degrading general capabilities (e.g., writing, general STEM).
- Tools/workflows: token-level removal on forbidden domains + refusal SFT for those domains; include “retain canaries” (adjacent subjects) to monitor collateral damage.
- Dependencies/assumptions: clear domain boundaries; sector-specific evaluation sets; legal/compliance sign-off on refusal behavior and disclosures.
- Robustness-focused safety evaluation and model cards
- Sectors: industry, policy/auditors
- What: report “effective compute slowdown” on the forget domain and “steps-to-parity under adversarial fine-tuning” as core safety metrics; compare against unlearning baselines.
- Tools/workflows: standard adversarial fine-tuning harness (few-step regain tests); include results in model cards.
- Dependencies/assumptions: availability of representative forget/retain corpora; compute for tests; agreed benchmarks.
- Token-level dataset curation and moderation
- Sectors: data engineering/MLOps, privacy
- What: use the biLM+probe classifier to flag or remove risky tokens inside otherwise benign documents; reduces over-filtering vs doc-level approaches and preserves scarce high-quality data.
- Tools/workflows: integrate classifier into DVC/Hugging Face datasets; per-domain filtering thresholds; drift monitoring for classifier performance.
- Dependencies/assumptions: classifier calibration; tolerance for noisy labels; cost of scanning large corpora.
- Safer consumer assistants with improved refusal control
- Sectors: consumer apps, enterprise chatbots
- What: deploy assistants that remain capable in benign domains but are much less coherent/correct in forbidden ones and can be trained to refuse reliably (token filtering made refusal training easier in the paper).
- Tools/workflows: token removal + lightweight refusal SFT; judge-based regression tests on free-response quality and refusal precision/recall.
- Dependencies/assumptions: acceptance that behavior arises from “not having learned content” (reduced risk of jailbreaks) rather than post hoc policies alone.
- Open models with stronger jailbreak and fine-tuning resistance
- Sectors: open-source ecosystems, labs publishing base models
- What: release capability-shaped checkpoints (e.g., no biorisk instructions) that are significantly harder to “train back” via cheap fine-tuning than unlearning-based variants.
- Tools/workflows: publish thresholds, filtered-token percentages, robustness curves; provide training scripts.
- Dependencies/assumptions: transparency about filtering scope; community acceptance; monitoring for unintended bias or capability gaps.
- Privacy- and safety-preserving pretraining via token filtering
- Sectors: privacy, compliance, data governance
- What: adapt the token classifier to PII and other sensitive attributes (e.g., secrets), masking/removing sensitive tokens while maintaining surrounding context for learning.
- Tools/workflows: PII-specific token classifiers; high-recall thresholds; audits for leakage.
- Dependencies/assumptions: reliable PII labeling; acceptable utility trade-offs.
- Research and teaching: reproducible SAE→probe labeling pipelines
- Sectors: academia, applied research labs
- What: reuse the paper’s pipeline to generate weak token labels from SAEs, then distill into small, domain-specific biLMs with linear probes; compare loss masking vs removal in classroom/research settings.
- Tools/workflows: pretrained SAEs (e.g., Gemma 2); weak-to-strong generalization exercises; public benchmark suites (MCQ, free-response).
- Dependencies/assumptions: SAE availability; compute to label subsets; careful threshold tuning to manage label noise.
Long-Term Applications
These require further research, scaling, standardization, or ecosystem adoption but are plausible extensions of the paper’s findings.
- Standardized capability-shaping certifications and procurement rules
- Sectors: policy, government, enterprise buyers
- What: require demonstrable “effective compute slowdown” on prohibited domains and robustness to adversarial fine-tuning for model procurement; include token-level filtering reports in audits.
- Dependencies/assumptions: consensus on target domains/benchmarks; third-party audit infrastructure; cost-effective verification.
- Multi-domain, fine-grained “capability dials”
- Sectors: software/AI platforms, safety engineering
- What: multi-label token classifiers enabling adjustable suppression across many domains (e.g., biorisk, cyber-offense, extremist tactics) with tunable precision/recall per domain.
- Tools/workflows: taxonomy design; hierarchical classifiers; per-domain loss masking schedules; monitoring for interference between dials.
- Dependencies/assumptions: scalable labeling; managing cross-domain bleed (retain/forget boundary complexity).
- Hybrid methods: combine token filtering with routing/architectural shaping
- Sectors: model architecture research
- What: integrate token filtering with gradient routing or modular subnets to localize risky capabilities; aim for stronger robustness and data efficiency than either alone.
- Dependencies/assumptions: stable training of routed models at scale; empirical proof that hybrids outperform.
- Safety-preserving scientific assistants
- Sectors: healthcare, biotech, chemistry, materials
- What: assistants that read and summarize literature or plan benign experiments but cannot produce step-by-step dangerous protocols; combine pretraining filtering with retrieval and refusal policies.
- Dependencies/assumptions: carefully drawn “retain vs forget” within close scientific neighbors (e.g., benign vs actionable protocols); acceptable utility for researchers.
- Enterprise on-premises capability shaping over proprietary corpora
- Sectors: finance, pharma, manufacturing
- What: pretrain/fine-tune internal models that avoid learning sensitive or regulated instructions while retaining productivity skills; mitigate internal misuse risks.
- Dependencies/assumptions: compute access; high-recall internal classifiers; governance over shifting internal taxonomies.
- Continual data ingestion with real-time token filtering and drift detection
- Sectors: MLOps, data engineering
- What: “always-on” ingestion pipelines that apply token-level filters to new crawl data, track filtered-token ratios, and detect domain drift or classifier degradation.
- Dependencies/assumptions: scalable inference; periodic relabeling; ops maturity for feedback loops.
- Formal guarantees and theory for capability suppression
- Sectors: academia, standards bodies
- What: characterize scaling laws under filtering, upper bounds on adversarial regain, and conditions under which token filtering preserves retain-domain scaling exponents.
- Dependencies/assumptions: shared datasets; reproducible training runs; openness from labs.
- Education-grade age/level targeting
- Sectors: education/edtech
- What: models shaped to a grade level or pedagogical scope (e.g., avoid exam key leakage, violent/sexual content), while keeping core reasoning and explanation skills.
- Dependencies/assumptions: community-agreed content taxonomies; fairness/bias audits to avoid disproportionate suppression of dialects/cultures.
- Safety metrics and documentation standards
- Sectors: policy, industry consortia
- What: standardize reporting of classifier F1/recall, thresholds, fraction of tokens filtered, effective compute slowdown, adjacent-domain (retain) degradation, and robustness-to-regain curves in model cards.
- Dependencies/assumptions: incentives to disclose; comparability across labs and training stacks.
- Privacy-first foundation models
- Sectors: privacy, regulation
- What: extend token filtering to privacy attributes at scale (PII, secrets), aligning with data-minimization principles while preserving model utility in non-sensitive domains.
- Dependencies/assumptions: mature PII tokenizers/classifiers; regulatory validation; careful monitoring for residual leakage.
Notes on feasibility and caveats across applications:
- Generalization: Results are shown on a medical proxy; effectiveness on high-stakes domains (e.g., dual-use biosynthesis, cyber-offense) must be validated with domain-tailored labels and evals.
- Labeling quality: Token-level classifiers benefit from high recall; noisy weak labels can work with threshold tuning and sufficient pretraining compute, but poor calibration can cause retain-domain damage.
- Data regime: Precision matters most in limited-data regimes; document-level filtering may be adequate where data is abundant, but token-level precision yields better Pareto trade-offs.
- Compute and access: Pretraining-time interventions require access to the base model training loop; API-only settings can still benefit from token classifiers for curation but not full capability shaping.
- Alignment interactions: Token filtering can make refusal training easier, but fine-grained, multi-domain control remains an open research area.
- Ethics and bias: Over-filtering can inadvertently remove benign content tied to specific communities or topics; fairness audits and “retain canaries” are important.
- Security: While more robust than unlearning in reported tests, determined adversaries with substantial compute could still recover capabilities; defense-in-depth remains necessary.
Glossary
- adversarial finetuning: Post-training updates meant to intentionally reintroduce or elicit suppressed capabilities. "Filtering is also 10× more robust to adversarial finetuning attacks than a state-of-the-art unlearning intervention"
- autointerp: Automated procedures that generate natural-language explanations for learned features in interpretability work. "We require that a token activate multiple latents because of feature splitting and high variance in autointerp quality."
- backpass: The backward pass of gradient-based training where gradients are propagated to update parameters. "After labeling our pretraining set using a model-based classifier, we remove {forget} tokens from the Transformer backpass."
- biLM (bidirectional LLM): A model that uses both left-to-right and right-to-left contexts, often by jointly training two autoregressive models. "We also test whether scaling the size of these biLMs improves performance"
- capability shaping: Intentionally adjusting which abilities a model acquires, reducing unwanted ones while preserving useful ones. "an important design goal is capability shaping: selectively reducing undesired capabilities without harming desired ones."
- Chinchilla: A scaling rule/dataset-size regime indicating compute-optimal token budgets for given model sizes. "We train two 61M parameter models (so, 122M altogether) on FineWeb-Edu, each for 4.8B tokens (4× Chinchilla)."
- cloze-style selection: An evaluation format where models choose the correct completion for a blank from candidates. "We also evaluate using cloze-style selection, which bears out similar distinctions"
- compute-optimal (Transformers): Training at model/data scales predicted to maximize performance per unit of compute. "We train compute-optimal Transformers at scales ranging from 61M to 1.8B parameters"
- compute slowdown: Increased effective compute needed to reach the same performance due to an intervention. "token filtering leads to a 7000× compute slowdown on the forget domain."
- control tokens: Special tokens inserted during training to condition models on attributes (e.g., toxicity). "for example by adding control tokens for toxicity"
- data attribution: Methods that trace how training data points influence model predictions or capabilities. "Inspired by work on data attribution"
- document filtering: Removing entire documents from the pretraining corpus based on a classifier or rules. "Token filtering Pareto dominates document filtering."
- embedding scoring: Using embedding-based metrics to assess the quality of feature explanations or labels. "We additionally score all explanations using \citet{paulo2024automatically}'s embedding scoring"
- feature splitting: When a single semantic concept is represented across multiple learned features/latents in an SAE. "We require that a token activate multiple latents because of feature splitting"
- gradient routing: Techniques that steer gradients or representations during training to segregate capabilities. "propose gradient routing, which attempts to segment capabilities within the model ab initio."
- influence functions: Tools to estimate how much specific training examples affect model outputs or losses. "estimate influence functions using tokens, rather than documents, as training examples."
- jailbreaks: Prompts or strategies that circumvent safety measures to elicit restricted capabilities. "adversaries can still elicit them via jailbreaks or finetuning"
- L-BFGS: A quasi-Newton optimization algorithm often used for fitting linear probes. "We choose to fit linear probes using L-BFGS rather than doing full finetuning"
- linear probe: A simple linear classifier trained on frozen representations to test what information is encoded. "We fit a linear probe to each model to classify {forget} vs. {retain} tokens"
- loss masking: Training-time omission of gradients/loss terms for selected tokens to prevent learning from them. "We consider two strategies for token filtering: loss masking, where we remove gradients computed for {forget} tokens from the backpass"
- machine unlearning: Techniques intended to remove specific knowledge or capabilities from a trained model. "recent work has instead attempted to use machine unlearning to extract capabilities from the pretraining base"
- masked language modeling (MLM): A pretraining objective where some tokens are masked and the model predicts them. "we pretrain a 65M parameter RoBERTa-like model on FineWeb-Edu with a masked language modeling objective."
- muP (μP): μ-parameterization; a scaling rule for optimizers and learning rates to stabilize training across scales. "We optimize using AdamW and scale learning rate with μP"
- Pareto dominance (Pareto improvement): An intervention that improves one objective without worsening another relative to a baseline. "token filtering is a Pareto improvement over document filtering"
- perplexity: A common language modeling metric reflecting how well a model predicts test text; lower is better. "Text perplexity"
- refusal training: Finetuning models to decline or refuse answering queries in a specified domain. "A more realistic setting is refusal training: say we remove dangerous biology knowledge from pretraining."
- relative scaling laws: Plots/relations comparing how performance scales with compute under different interventions. "We plot relative scaling laws that show the effective compute required to train a Transformer on filtered data that matches the loss on a baseline trained on completely unfiltered data."
- RMU: A representation-based unlearning method that aligns forbidden-domain representations to random vectors while preserving others. "We use RMU as an example of a state-of-the-art unlearning safeguard"
- scaling exponents: Parameters describing how loss or performance scales with compute/model size. "models trained with data filtering have lower magnitude scaling exponents on the {forget} domain."
- sparse autoencoders (SAEs): Models that learn sparse latent features to represent internal activations for interpretability or labeling. "utilizing sparse autoencoders to label tokens"
- sparse dictionary learning: Learning sparse latent bases (dictionaries) that reconstruct activations or data. "using sparse dictionary learning with sparse autoencoders"
- token filtering: Filtering at the token level rather than documents to precisely remove unwanted content. "We consider two strategies for token filtering: loss masking, where we remove gradients computed for {forget} tokens from the backpass, and removal, where we replace {forget} tokens with a special <|hidden|> token"
- token removal: Replacing selected tokens with a special placeholder so the model never trains on them. "removal, where we replace {forget} tokens with a special <|hidden|> token (and similarly mask the loss on these tokens)."
- weak-to-strong generalization: Training a model to generalize beyond noisy/weak labels to the true concept. "We frame classifier training as a kind of weak-to-strong generalization problem"
Collections
Sign up for free to add this paper to one or more collections.