- The paper demonstrates that filtering pretraining data significantly suppresses biothreat-proxy knowledge while maintaining general model capability.
- It introduces a two-stage pipeline that combines a blocklist keyword filter with a ModernBERT classifier, using less than 1% of total pretraining FLOPs.
- Filtered LLMs exhibit strong resistance to extensive adversarial fine-tuning and, when combined with post-training defenses, offer enhanced risk management.
Deep Ignorance: Data Filtering as a Tamper-Resistant Safeguard for Open-Weight LLMs
Introduction
The proliferation of open-weight LLMs has enabled broad access to advanced AI capabilities, but it has also introduced significant risks, particularly the potential for downstream actors to elicit or revive harmful behaviors through tampering. The paper "Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs" (2508.06601) systematically investigates whether filtering dual-use content—specifically, biothreat-proxy knowledge—from pretraining corpora can serve as a robust, tamper-resistant safeguard. The authors present a scalable, multi-stage data filtering pipeline, evaluate its efficacy in suppressing unwanted knowledge, and compare it to state-of-the-art post-training defenses such as Circuit-Breaking (CB) and Latent Adversarial Training (LAT). The work also explores the limitations of data filtering, the complementarity of defense-in-depth strategies, and the challenges of synthetic document training.
Scalable Multi-Stage Data Filtering Pipeline
The core methodological contribution is a two-stage filtering pipeline designed to excise biothreat-proxy content from massive pretraining datasets. The first stage employs a blocklist-based keyword filter, rapidly excluding documents containing multiple high-risk terms. Documents flagged by the blocklist are escalated to a fine-tuned ModernBERT classifier, which semantically evaluates their content for biothreat relevance. This design achieves high recall with minimal computational overhead—less than 1% of total pretraining FLOPs.
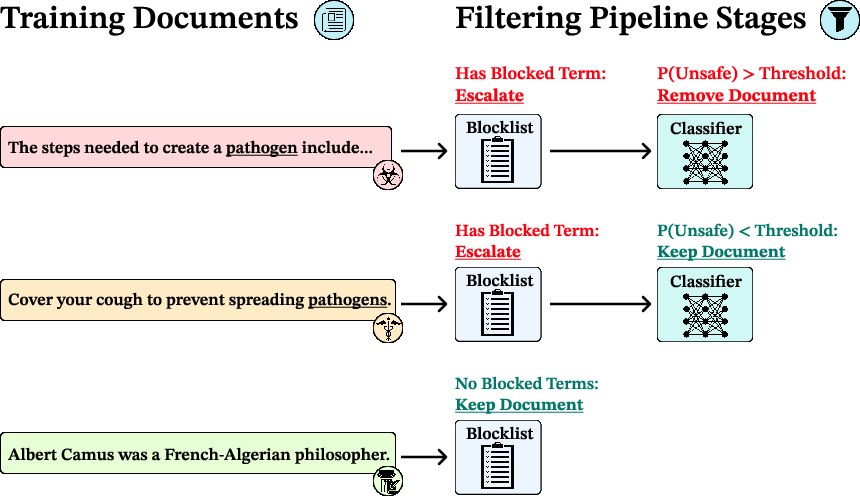
Figure 1: The multi-stage data filtering pipeline combines a blocklist filter with a ModernBERT classifier to efficiently remove biothreat-proxy content from large-scale corpora.
Empirically, the vast majority of documents are filtered by the blocklist alone, with only a small fraction requiring classifier review. The pipeline is highly parallelizable and can be tuned for precision-recall trade-offs by adjusting the escalation threshold or classifier sensitivity.
Impact on Model Capabilities and Tamper Resistance
The authors pretrain 6.9B-parameter decoder-only transformers (Pythia architecture) on 550B tokens, comparing unfiltered baselines to models trained on strongly and weakly filtered datasets. Evaluation focuses on two axes: (1) suppression of biothreat-proxy knowledge, measured via the WMDP-Bio MCQA and cloze benchmarks, and (2) preservation of general capabilities, assessed on MMLU (excluding biology), PIQA, LAMBADA, and HellaSwag.
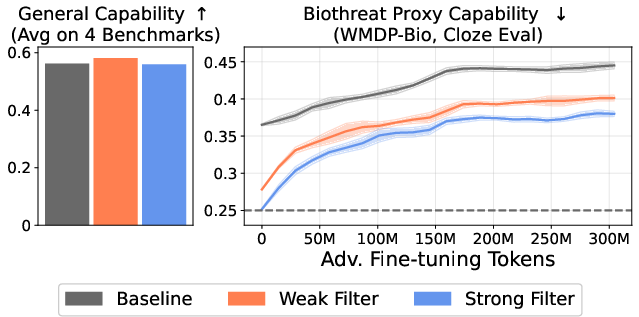
Figure 2: Data filtering preserves general capabilities (left) while substantially reducing biothreat-proxy knowledge and conferring resistance to adversarial fine-tuning (right).
Filtered models exhibit a substantial reduction in biothreat-proxy knowledge—approaching random-chance performance on cloze-style evaluations—while maintaining general performance on unrelated tasks. Notably, the filtered models are resistant to up to 10,000 steps and 300M tokens of adversarial fine-tuning, a marked improvement over post-training baselines, which typically fail after a few hundred steps.
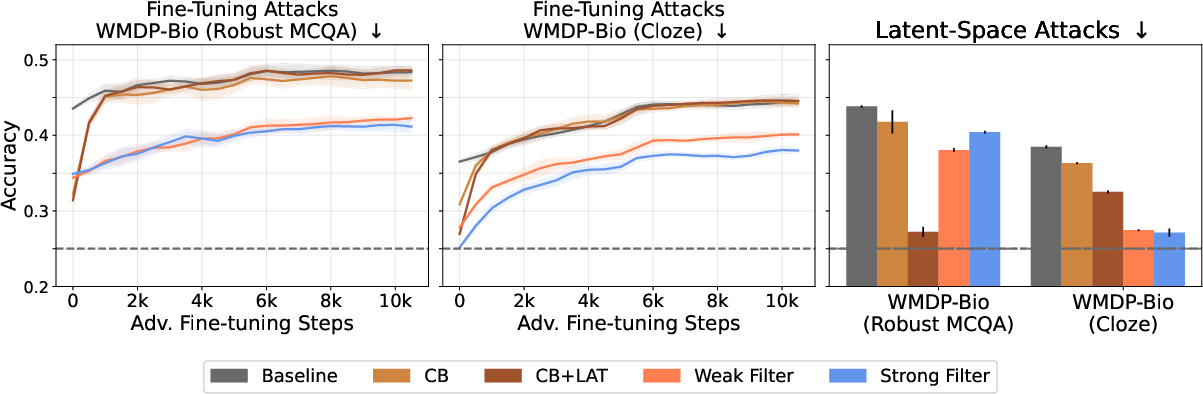
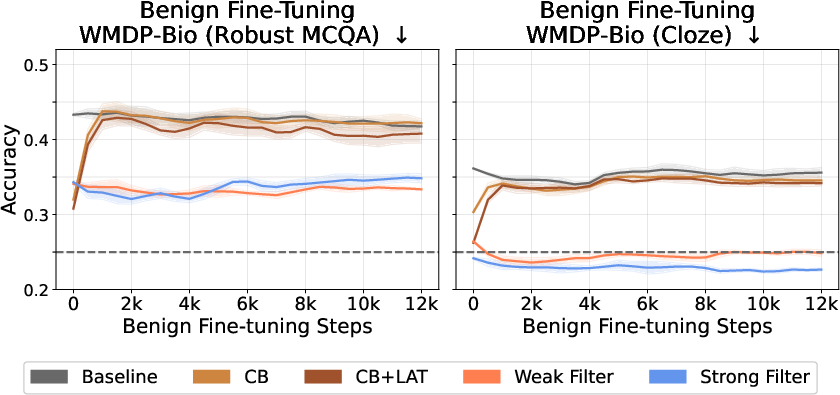
Figure 3: Filtered models maintain low biothreat-proxy knowledge even after extensive adversarial fine-tuning and are robust to latent-space attacks, with performance competitive to or exceeding CB and CB+LAT methods.
Comparative Analysis with Post-Training Defenses
The study benchmarks data filtering against CB and CB+LAT, both of which operate post hoc by modifying model activations or training on adversarially perturbed examples. While CB methods slightly outperform filtering on MCQA biothreat evaluations, filtering is superior on cloze-style and input-space adversarial attacks (e.g., fewshot, GCG-U). Importantly, data filtering is robust to benign fine-tuning, whereas CB-based defenses are rapidly undone by non-adversarial adaptation.
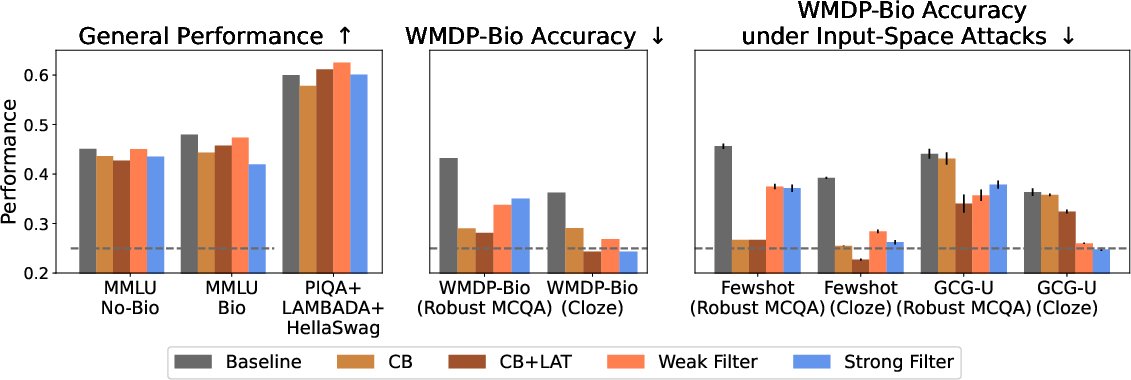
Figure 4: Data filtering and CB methods are comparable in suppressing biothreat knowledge, with filtering excelling in cloze and adversarial input settings.
Defense-in-Depth: Complementarity and Limitations
A critical finding is that data filtering alone cannot prevent in-context retrieval of harmful information when such content is provided as input (e.g., via retrieval-augmented generation). In contrast, CB methods can suppress the model's ability to leverage in-context biothreat knowledge. However, no defense resists ensemble attacks that combine fine-tuning with in-context retrieval, underscoring the necessity of layered safeguards.
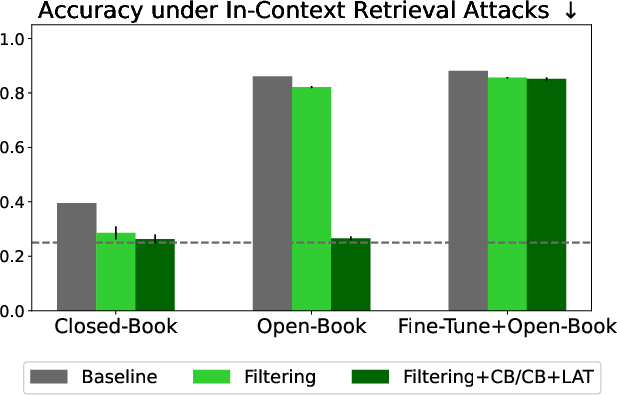
Figure 5: Data filtering fails to block in-context retrieval of biothreat knowledge, but CB methods can; ensemble attacks circumvent all tested defenses.
Combining data filtering with CB yields additive benefits, improving robustness to fewshot and latent-space attacks without sacrificing general performance.
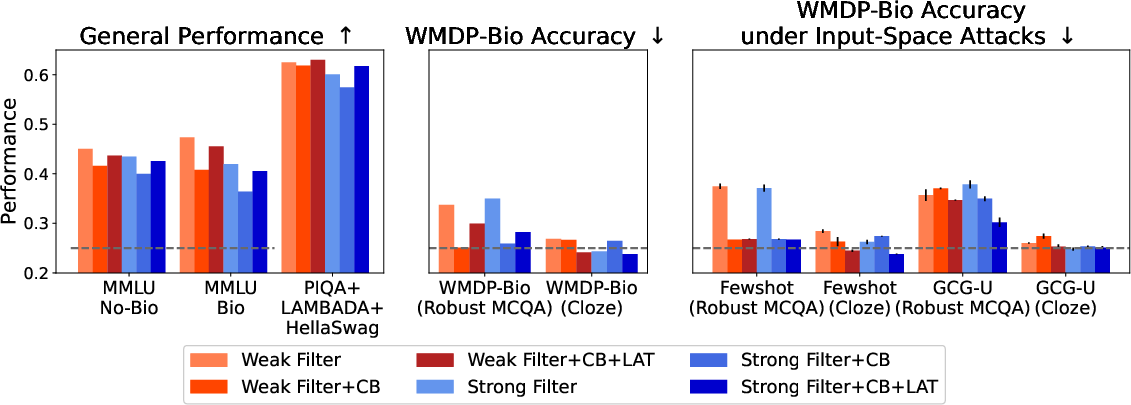
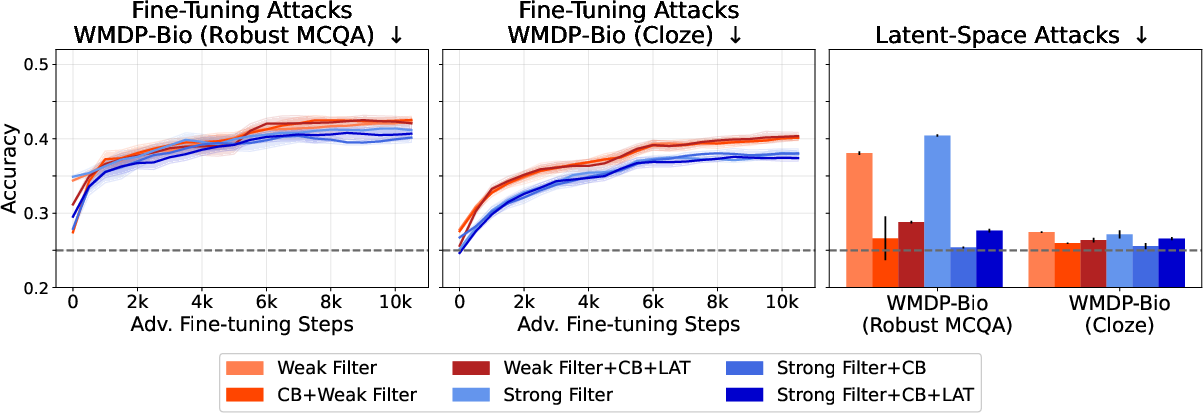
Figure 6: Combining data filtering with CB enhances resistance to fewshot attacks and maintains strong performance on general benchmarks.
Negative Results: Synthetic Document Training
The authors also test whether training on synthetic, misinformation-laden documents (SDT) can further suppress biothreat knowledge. Contrary to expectations, SDT does not improve and sometimes degrades resistance to attacks, likely due to models learning to exploit evaluation heuristics or failing to internalize coherent incorrect beliefs.
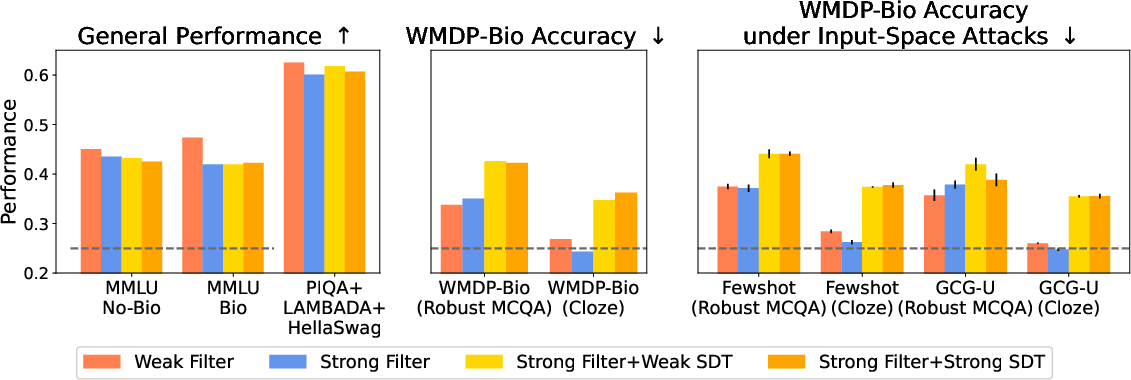
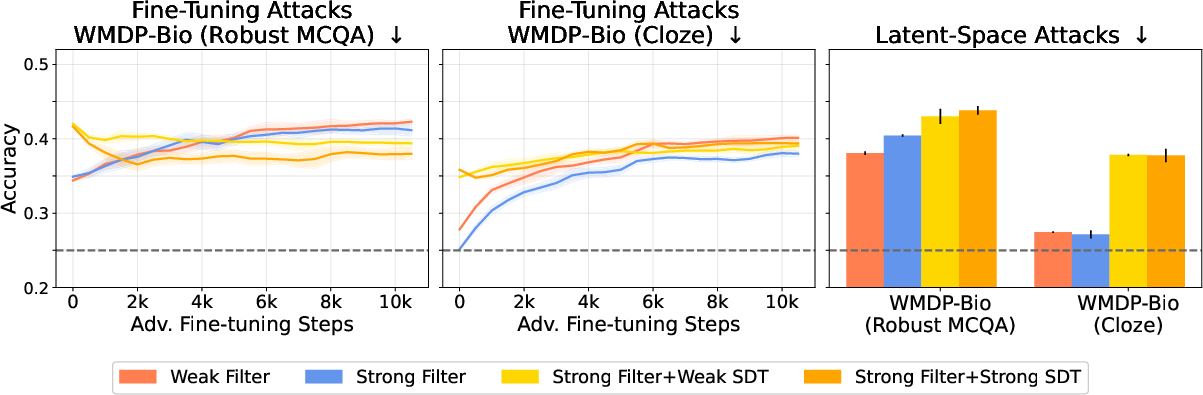
Figure 7: Synthetic document training on biothreat misinformation does not improve over data filtering and can degrade resistance to attacks.
Analysis of Filtering Efficacy and Data Sources
The filtering pipeline primarily removes documents from scientific sources (Semantic Scholar, DCLM), with high agreement between strong and weak filters for these domains. StackExchange and other non-scientific sources exhibit higher disagreement, indicating potential for further refinement in filter design.
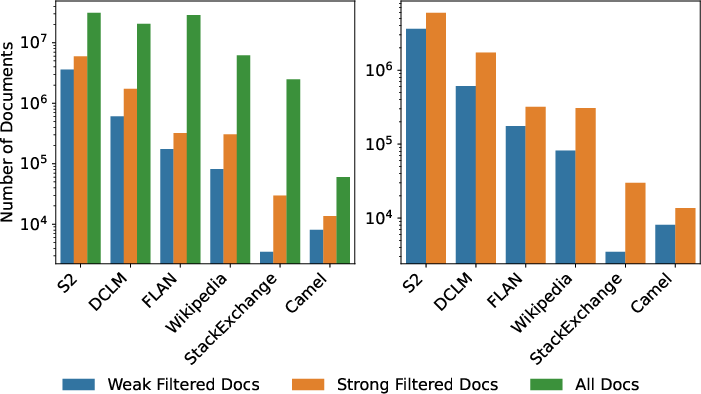
Figure 8: Most filtered documents originate from scientific sources; filter agreement is high for these, but lower for community-driven content.
Theoretical and Practical Implications
The results demonstrate that pretraining data filtering is a tractable and effective method for suppressing precise, knowledge-based harmful capabilities in LLMs, conferring state-of-the-art tamper resistance with negligible impact on general performance and minimal computational overhead. However, filtering is insufficient for suppressing emergent propensities (e.g., toxicity, compliance with harmful requests) that do not require precise knowledge, as confirmed by experiments on models filtered for toxic content.
The findings suggest that robust inability-based safety cases for open-weight LLMs are feasible for knowledge-centric risks but not for all forms of harmful behavior. Defense-in-depth, combining pretraining interventions with post-training mechanisms, is necessary for comprehensive risk management.
Limitations and Future Directions
The study is limited to 6.9B-parameter unimodal models and biothreat-proxy knowledge. Scaling trends, applicability to larger or multimodal models, and generalization to other domains remain open questions. The challenge of precisely specifying harmful content boundaries and the risk of over-filtering benign data are acknowledged. Further research is needed on mechanistic interpretability of "deep ignorance," improved filter precision, and comprehensive defense strategies for open-weight ecosystems.
Conclusion
This work establishes pretraining data filtering as a practical, scalable, and effective safeguard for suppressing knowledge-based risks in open-weight LLMs, achieving unprecedented resistance to adversarial fine-tuning. While not a panacea—especially for propensity-based harms—data filtering, when combined with post-training defenses, forms a robust foundation for open-weight model risk management. The public release of filtered models and code provides a valuable resource for further research on mechanistic interpretability, scaling, and the development of standards for AI safety in open ecosystems.
