Beyond Data Filtering: Knowledge Localization for Capability Removal in LLMs
Abstract: LLMs increasingly possess capabilities that carry dual-use risks. While data filtering has emerged as a pretraining-time mitigation, it faces significant challenges: labeling whether data is harmful is expensive at scale, and given improving sample efficiency with larger models, even small amounts of mislabeled content could give rise to dangerous capabilities. To address risks associated with mislabeled harmful content, prior work proposed Gradient Routing (Cloud et al., 2024) -- a technique that localizes target knowledge into a dedicated subset of model parameters so they can later be removed. We explore an improved variant of Gradient Routing, which we call Selective GradienT Masking (SGTM), with particular focus on evaluating its robustness to label noise. SGTM zero-masks selected gradients such that target domain examples only update their dedicated parameters. We test SGTM's effectiveness in two applications: removing knowledge of one language from a model trained on a bilingual synthetic dataset, and removing biology knowledge from a model trained on English Wikipedia. In both cases SGTM provides better retain/forget trade-off in the presence of labeling errors compared to both data filtering and a previously proposed instantiation of Gradient Routing. Unlike shallow unlearning approaches that can be quickly undone through fine-tuning, SGTM exhibits strong robustness to adversarial fine-tuning, requiring seven times more fine-tuning steps to reach baseline performance on the forget set compared to a finetuning-based unlearning method (RMU). Our results suggest SGTM provides a promising pretraining-time complement to existing safety mitigations, particularly in settings where label noise is unavoidable.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how to stop LLMs from learning certain kinds of knowledge that could be misused, like dangerous biology information. Instead of only trying to remove risky data before training (which is hard and error-prone), the authors teach the model to store targeted knowledge in a special “section” of its brain. Later, they can delete that section to remove the risky capability without breaking the rest of the model.
They propose a new training method called Selective GradienT Masking (SGTM), test it on two tasks (removing Spanish from a bilingual model and removing biology knowledge from a Wikipedia-trained model), and compare it to common approaches like data filtering and earlier “gradient routing” techniques.
Key Questions
The paper asks:
- Can we guide an LLM to keep certain knowledge (like general English) while isolating other knowledge (like Spanish or biology) in a specific set of its parameters?
- If some dangerous data slips past our filters (labeling errors), can the model still keep that knowledge isolated and removable?
- Does this isolation hold up under attacks, like fine-tuning that tries to relearn the removed knowledge?
- How well does this approach balance forgetting the targeted capability with keeping everything else working?
How They Did It (Methods in Everyday Terms)
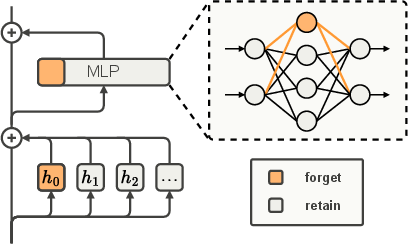
Think of a model as a huge machine with many knobs and switches (its parameters). The idea is to assign two sets of knobs:
- “Retain knobs” for regular, useful knowledge (the safe stuff).
- “Forget knobs” for the risky domain we want to remove later (like biology).
During training, they do two smart tricks to push different data to different knobs:
- For “forget” examples (like biology articles), they block updates to the “retain knobs” so only the “forget knobs” learn from this data. In machine terms, they zero out certain gradients so those parts don’t get changed.
- For “retain” examples (like general topics), they temporarily turn off the “forget knobs” during the forward pass, so the model learns to do well even without those risky parts.
After training, they simply set the “forget knobs” to zero (delete that section), which removes the targeted capability while keeping most other abilities.
A few helpful analogies:
- It’s like having two colored circuits inside the model: orange for “forget” and blue for “retain.” Forget data only wires up the orange circuit; retain data encourages the blue circuit.
- When you later cut the orange wires, the machine still works because it learned to do the main job using the blue wires.
Why this helps with labeling errors (some risky data not marked as risky):
- The method encourages “self-localization.” Once the model starts using the “forget circuit” for risky content, even unlabeled risky examples naturally send stronger training signals to that circuit. So mislabeling hurts less because those examples still mostly update the orange/forget parts.
Main Findings and Why They Matter
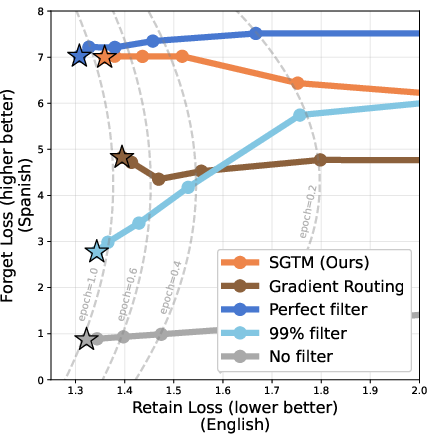
1) TinyStories bilingual experiment (removing Spanish)
- The team trained a model on English + Spanish story data, then tried to remove Spanish.
- SGTM beat both data filtering and a previous gradient routing method:
- It kept general abilities better while forgetting Spanish more, especially when some Spanish data was mislabeled and slipped through.
- With small amounts of mislabeled data, data filtering quickly failed to remove Spanish; SGTM stayed effective.
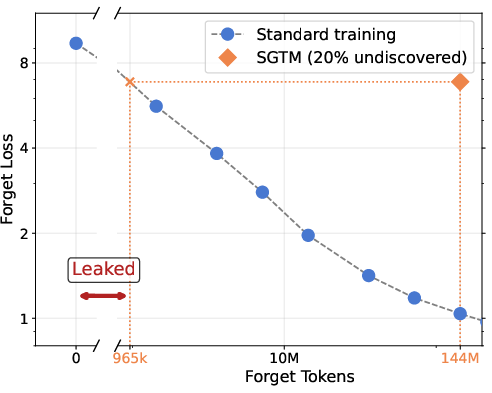
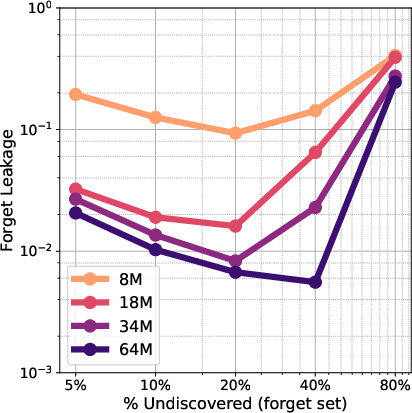
- Leakage (how much unlabeled Spanish accidentally affects the “retain knobs”) was very low and decreased as models got larger. In bigger models, mislabeling mattered less because the risky knowledge stayed better compartmentalized.
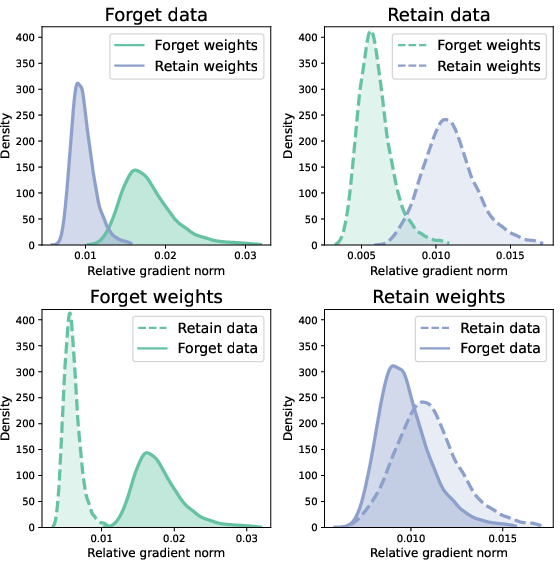
- Their gradient measurements showed “self-reinforcing localization”: Spanish examples mostly updated the “forget knobs,” while English examples mostly updated the “retain knobs.” This confirms the method’s intended behavior.
Why this matters: It shows that even if your data filter misses some risky samples, SGTM can still prevent that knowledge from spreading into the model’s safe parts.
2) Wikipedia experiment (removing biology)
- The model was trained on English Wikipedia and asked to forget biology knowledge.
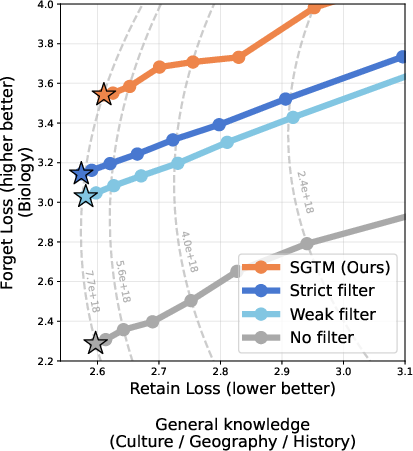
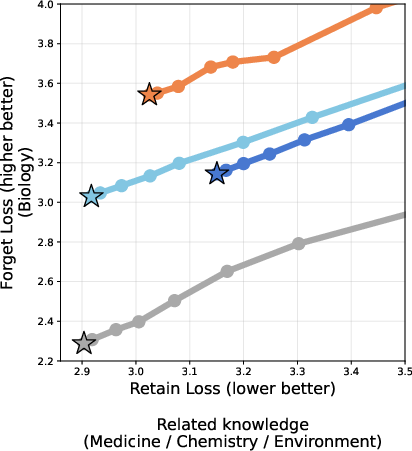
- SGTM outperformed both weak filtering (removing only biology articles) and strict filtering (also removing medicine, chemistry, and environment).
- For any fixed level of general performance, SGTM achieved stronger forgetting of biology than filtering.
- SGTM had a small training efficiency cost (roughly a 5–6% compute penalty to reach similar general performance).
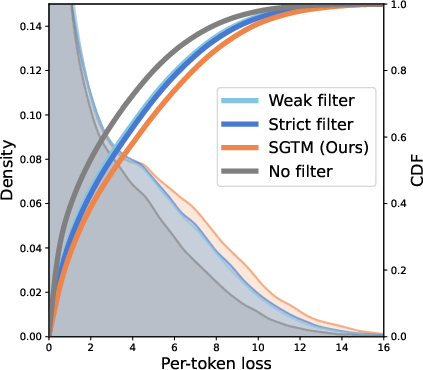
- Per-token analysis showed that SGTM’s forgetting wasn’t just from a few extreme mistakes—it broadly reduced accuracy across biology tokens.
- Robustness to fine-tuning attacks:
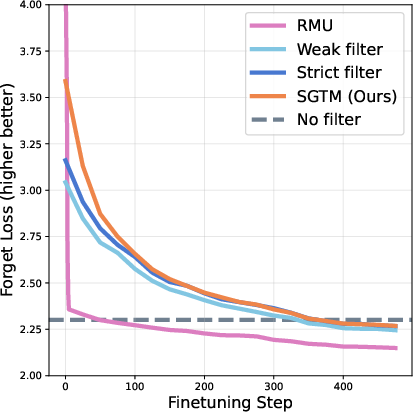
- A strong post-training unlearning method (RMU) was quickly undone (relearned biology in far fewer steps).
- SGTM resisted relearning much longer, needing about 7× more fine-tuning steps to return to baseline biology performance—similar to strict filtering and stronger than weak filtering early on.
Why this matters: SGTM provides more reliable removal of targeted knowledge in real-world data with noisy labels and resists adversarial attempts to bring that knowledge back.
Implications and Potential Impact
- SGTM is a promising pretraining-time safety tool. Instead of relying entirely on perfect data filters (which are hard to build and inevitably make mistakes), SGTM provides a second line of defense that:
- Localizes risky knowledge so it can be removed later,
- Stays effective even with labeling errors,
- Is harder to undo through fine-tuning.
- This method could be part of “defense in depth.” It won’t stop all attacks (for example, users can still try to feed dangerous content to the model at runtime), but it helps ensure the model doesn’t internally store or rely on risky knowledge.
- Practical benefits:
- Developers can train once and keep two versions: a full-capability model for trusted settings, and a safer version with risky sections removed for general use.
- Limitations:
- The experiments used smaller models and proxy tasks (like Spanish or biology), not real CBRN tests.
- It’s not a stand‑alone solution; other safety layers are still needed.
- There’s a small compute/training efficiency cost.
Overall, SGTM offers a clearer, more robust way to “put risky knowledge in a box” during training so it can be deleted later, improving safety without greatly harming the model’s useful skills.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper.
- Scalability to frontier models: Validate SGTM on billion+ parameter LLMs and modern training regimes (e.g., MoE, long-context, instruction-tuned models); quantify leakage, retain/forget trade-offs, and compute penalties at scale.
- Architecture generality: Test SGTM across diverse architectures (decoder-only vs encoder-decoder, rotary vs ALiBi, residual stream variants) and with MoE gating to see if localization properties persist or improve.
- Optimal capacity allocation: Systematically study how many heads/MLP units per block should be designated to the forget domain as a function of domain size, overlap, and label quality; derive guidelines for h_forget/d_forget selection and per-layer placement.
- Embedding-layer treatment: Investigate whether dedicating or splitting embeddings (or vocabularies) to forget vs retain domains reduces leakage, especially for shared subword vocabularies in multilingual or cross-domain settings.
- Mechanistic understanding beyond magnitudes: Move from gradient norm analysis to gradient directionality/alignment, path attribution, and circuit-level mechanisms to explain “absorption” and identify where information flows despite masking (e.g., down-projections, residual pathways).
- Leakage metric validation: Validate the “equivalent token exposure” leakage measure across seeds, training schedules, and model scales; compare against alternative metrics (e.g., probing, representational similarity, causal tracing) to triangulate leakage.
- Robustness to adversarial mislabeling/poisoning: Evaluate SGTM under adversarially crafted mislabeled data that hides harmful content inside benign contexts; test correlated, non-random label errors and poisoning strategies at very low discovery rates (<10%).
- Beyond loss proxies: Assess removal on capability-level benchmarks (e.g., WMDP, real CBRN-relevant tasks, exploit generation) to confirm that higher forget loss translates into materially reduced dangerous capabilities.
- Fine-tuning attack surface: Extend robustness testing to LoRA/adapters, instruction tuning, RLHF, gradient surgery, and jailbreak prompts; quantify relearning speed under different defense-aware attacker strategies and data mixtures.
- RAG and in-context injection: Evaluate whether localized removal resists retrieval-augmented generation or prompt-injected harmful content at inference; quantify leakage when the model is fed external domain knowledge.
- Compute penalty mitigation: Profile and reduce the reported 5–6% compute penalty; explore selective or scheduled masking, curriculum strategies, or adaptive budgets that maintain retain performance while preserving localization strength.
- Multi-domain forgetting: Test SGTM on simultaneous removal of multiple overlapping domains; analyze interactions, compositional leakage, and cross-domain side effects on benign knowledge.
- Calibration dependence: Verify that conclusions hold without trained logit bias or under alternative calibration schemes; quantify sensitivity of forget/retain loss comparisons to calibration choices.
- Operational integration: Document and test SGTM in distributed/sharded training, mixed precision, and different optimizers (AdamW vs Adafactor); identify stability issues and provide reproducible engineering guidance.
- Post-ablation retain recovery: Determine if retain-only fine-tuning can restore the retain loss penalty without reintroducing forget knowledge; characterize the boundary between benign recovery and harmful relearning.
- Long-context reasoning side effects: Measure whether SGTM impacts chain-of-thought, multi-step reasoning, and long-range dependencies in retain domains; identify potential degradation patterns.
- Alternative ablation mechanisms: Compare zeroing-out to gating, pruning, or reparameterization for disabling forget segments; quantify inference-time stability, calibration shifts, and residual activity in ablated segments.
- Minimal labeling requirements: Establish lower bounds on required labeled forget data for SGTM to localize effectively; explore active learning/semi-supervised methods to prioritize labeling and reduce dependency on imperfect classifiers.
- Formal guarantees: Develop theoretical analysis for absorption/localization (conditions, bounds on leakage and retain degradation) under specific architectures/optimizers and label error models.
- Adjacent-benign knowledge impact: Expand evaluation of side effects on biology-adjacent and more distant benign domains; use semantic probes to detect subtle capability losses beyond aggregate loss changes.
- False positives (benign → forget): Quantify harm when benign retain data is mislabeled as forget and masked; propose detection/correction strategies to avoid unnecessary capability loss.
- Training-phase scheduling: Study early vs late application of SGTM, partial-phase masking, and adaptive schedules to optimize localization with minimal retain degradation.
- Weight merging/editing risks: Test whether merging ablated models with baseline checkpoints or applying weight editing can undo SGTM; design safeguards against post-hoc reconstruction of forget capabilities.
- Governance for dual-model deployment: Specify policies, access controls, and audit mechanisms for managing pre-ablation and post-ablation models to prevent leakage or misuse, especially in shared or open-source settings.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s method (SGTM) and provided tooling, with modest engineering effort and standard ML infrastructure. They are grounded in the paper’s demonstrated ability to localize and remove targeted knowledge during pretraining, with better retain/forget trade-offs and robustness to label noise than conventional data filtering.
- Industry (Model Development and Safety Engineering)
- Safer foundation-model pretraining pipelines
- Use SGTM in pretraining to localize high-risk domains (e.g., biology, software exploits) into dedicated parameters that can be ablated before deployment, complementing data filtering when labels are noisy.
- Workflow: split parameters into “forget” and “retain” segments per transformer block, apply gradient masking for forget-labeled data, parameter masking for retain-labeled data, then ablate forget parameters and calibrate logits for evaluation.
- Tools/products: “SGTM Training Module” (code provided), “Ablation Manager” to produce safe variants from the same run, “Leakage Monitor” to quantify absorption and leak metrics.
- Assumptions/dependencies: availability and quality of domain classifiers; acceptance of small compute penalties (≈5–6%) and modest retain-loss trade-offs; careful hyperparameter selection for forget head/unit allocation.
- Dual-release model provisioning (“capability-gated” offerings)
- Maintain two variants from one run: pre-ablation (full) for trusted users and post-ablation (safe) for general deployment.
- Sector links: cloud AI platforms, enterprise AI vendors, safety-focused model hosting.
- Assumptions/dependencies: policy and access-control frameworks; auditing of which users qualify for access; secure handling of the more capable pre-ablation model.
- Robustness testing and reporting for safety claims
- Integrate SGTM’s fine-tuning robustness tests (adversarial relearning) and per-token loss audits into safety QA, demonstrating that removed capabilities are not trivially recovered.
- Tools/products: “Safety QA Dashboard” for retain/forget trade-off curves, per-token loss distributions, and relearning curves versus baselines (filtering and RMU).
- Assumptions/dependencies: standardized evaluation datasets; acceptance of loss-based proxies where downstream evals are unavailable; recognition that SGTM is still vulnerable to in-context injection attacks.
- Academia (Research and Methods Development)
- Mechanistic studies of knowledge localization and gradient dynamics
- Use gradient norm analyses to study how unlabeled forget examples preferentially update forget parameters (self-reinforcing localization).
- Sector links: machine learning research, interpretability, safety science.
- Assumptions/dependencies: access to training traces and gradient norms; reproducible small- to mid-scale pretraining runs; adequate compute for multiple variants.
- Benchmarks and metrics for pretraining-time safety
- Adopt leakage as a metric and test SGTM against filtering across mislabeling regimes, languages, and domains.
- Tools/products: reproducible benchmark suites (bilingual TinyStories; Wikipedia with topic taxonomy).
- Assumptions/dependencies: reliable synthetic or semi-real labels; comparability across architectures; clear reporting standards.
- Policy and Compliance
- Pretraining-time safety assurance in vendor assessments
- Encourage or require vendors to use pretraining localization with leakage reporting, retain/forget trade-off plots, and fine-tuning robustness checks.
- Sector links: regulators, standards bodies, procurement teams.
- Assumptions/dependencies: policy frameworks that recognize pretraining-time mitigations; alignment with dual-use risk taxonomies (CBRN, cybersecurity).
- Controlled-access model governance
- Permit tightly regulated use of pre-ablation models by vetted institutions (e.g., biosecurity labs) while general users receive post-ablation variants.
- Assumptions/dependencies: vetting processes; secure deployment practices; clear delineation of legitimate versus prohibited use.
- Daily Life and Education
- Safer consumer assistants and age-appropriate models
- Deploy post-ablation models for general users that lack detailed instructions in risky domains while retaining broad utility (e.g., general science without wet-lab protocols).
- Sector links: education technology, consumer AI apps.
- Assumptions/dependencies: topic classifiers tuned to age-appropriateness; acceptance of slight performance trade-offs; guardrails for in-context injection risks.
Long-Term Applications
The following applications likely require further research, scaling studies, or product maturation (especially at billion-parameter frontiers, across modalities, and with stronger guarantees).
- Healthcare and Biosecurity
- Capability-partitioned medical assistants
- Train medical LLMs where clinical reasoning remains, but dual-use biology knowledge (e.g., wet-lab protocols, pathogen engineering) is localized and removable; grant gated access for licensed professionals with oversight.
- Potential workflows: multi-level SGTM partitions for granular removal (e.g., separate forget segments for wet-lab protocols vs. advanced synthesis).
- Assumptions/dependencies: fine-grained, high-precision medical/bio risk classifiers; evaluation beyond loss metrics (task performance, real-world safety audits); scalability to frontier models and MoE architectures.
- Software and Cybersecurity
- Exploit-resilient coding assistants
- Localize exploit-generation knowledge (e.g., RCE chains, malware tooling) and ablate for general users; enable controlled access to full capabilities for red-teamers under strict governance.
- Tools/products: secure “capability toggles” with attestation and logging, exploit-taxonomy classifiers, audit trails for relearning robustness.
- Assumptions/dependencies: accurate exploit labeling under adversarial data; demonstrated robustness against jailbreaks and in-context attack content; clear policies for legitimate red-team use.
- Education and Public Safety
- Curriculum-aware knowledge gating
- Partition advanced or risky content (e.g., hazardous chemistry, advanced fabrication) so educational models match grade-level scope while preserving general learning outcomes.
- Assumptions/dependencies: reliable curricular ontologies; content taxonomies aligned with developmental appropriateness; long-term monitoring for leakage as models scale.
- Robotics and Manufacturing
- Safety-aware instruction models
- Remove detailed assembly and hazardous operation instructions in consumer-facing robotics assistants while allowing general troubleshooting; grant elevated variants to certified technicians.
- Assumptions/dependencies: domain-specific risk taxonomies for physical operations; integration with hardware safety policies; empirical testing beyond token-loss proxies.
- Energy and Critical Infrastructure
- Restricted domain expertise containment
- Localize and ablate advanced nuclear/industrial process details for public models while preserving general STEM knowledge; allow controlled access in regulated environments.
- Assumptions/dependencies: sector-specific risk labeling under noisy data; joint policy-technical governance; resilience to in-context technical documents.
- Model Architecture and Tooling Ecosystem
- Multi-compartment capability controls in large MoE systems
- Extend SGTM to mixtures-of-experts and adapter-rich architectures for finer-grained capability gating; dynamic selection of forget segments per domain, region, or policy.
- Tools/products: “Capability Gateways” that manage parameter compartments, “Policy-driven SGTM Orchestrators” for automated ablation based on compliance rules.
- Assumptions/dependencies: scaling evidence at billion-parameter regimes; latency and throughput impacts; sophisticated routing and masking strategies compatible with modern training stacks.
- Standards and Certification
- Safety certifications incorporating pretraining-time localization
- Formalize guidelines requiring leakage metrics, retain/forget trade-off analyses, adversarial fine-tuning robustness, and documentation of dual-model governance.
- Assumptions/dependencies: consensus on safety metrics; third-party auditing capacity; calibrated thresholds for acceptable leakage/robustness.
- Cross-Modal Extensions
- Vision, audio, and multimodal capability removal
- Apply SGTM-style localization to multimodal models (e.g., removing detailed schematics interpretation or lab equipment identification while retaining general visual reasoning).
- Assumptions/dependencies: gradient-routing analogs for multimodal backbones; high-quality cross-modal risk labeling; empirical evidence for localization under multimodal entanglement.
General Assumptions and Dependencies Across Applications
- Labeling quality and taxonomy design: SGTM’s effectiveness depends on classifiers or rules that identify “forget” domains. Robustness to label noise helps, but systematic mislabeling will degrade outcomes.
- Architecture and hyperparameters: Forget/retain partitions (e.g., number of heads/units) must be tuned; suboptimal splits can hurt retain performance or allow leakage.
- Scale and modality: The paper shows promising trends up to 254M parameters on text; frontier-scale and multimodal generalization remains to be demonstrated.
- Evaluation and guarantees: Loss-based proxies are helpful but do not replace task-level, safety-relevant evaluations; SGTM is not a defense against in-context attacks and should be part of defense-in-depth.
- Compute and performance trade-offs: Expect small training slowdowns and modest retain losses; teams must budget for the compute penalty and post-ablation calibration workflows.
- Governance and access control: Dual-model provisioning and capability gating require strong policies, secure infrastructure, and transparent auditing.
Glossary
- Ablation: Post-training removal of designated model parameters to erase targeted knowledge or capabilities. "Ablation. After the training is complete, we set $\theta_{\text{forget}=0$ to remove knowledge specific to $\mathcal{D}_{\text{forget}$."
- Absorption property: The ability of gradient-routing methods to localize the impact of mislabeled harmful samples into designated parameters despite labeling errors. "These methods share a crucial advantage over data filtering: the absorption property~\citep{cloud2024gradient}."
- Adapters: Lightweight add-on modules that enable specialization by training a small parameter set while keeping the base model mostly frozen. "or adapters~\citep{hu2022lora,ponti-etal-2023-combining}"
- Adversarial fine-tuning: Deliberate fine-tuning aimed at restoring or enhancing removed or suppressed model capabilities. "SGTM exhibits strong robustness to adversarial fine-tuning, requiring seven times more fine-tuning steps to reach baseline performance on the forget set compared to a finetuning-based unlearning method (RMU)."
- Biology-adjacent knowledge: Domains closely related to biology that may contain overlapping or entangled biological information. "On general knowledge (left) and biology-adjacent knowledge (right) SGTM yields higher forget loss at any given retain loss value."
- CBRN: The category of chemical, biological, radiological, and nuclear applications with potential for dual-use or harm. "ranging from software exploits to dangerous chemical, biological, radiological, and nuclear (CBRN) applications~\citep{urbina2022dual,kang2024exploiting}."
- Chinchilla-optimal scaling: A data-parameter scaling regime that balances model size and training tokens for optimal performance. "for one full epoch, following Chinchilla-optimal scaling~\citep{hoffmann2022training}."
- Compute efficiency penalty: The extra computation required by a method to reach the same level of performance as a baseline. "SGTM incurs a compute efficiency penalty, requiring more compute to achieve the same retain loss value."
- Data filtering: Pretraining-time removal of potentially harmful or restricted content from training datasets. "While data filtering has emerged as a pretraining-time mitigation, it faces significant challenges"
- Data poisoning: Injection of malicious or crafted data into training sets to manipulate model behavior. "recent work on data poisoning~\citep{souly2025poisoning} shows that the number of malicious or mislabeled samples required to influence model behavior remains roughly constant with scale"
- Defense-in-depth: A layered security approach that combines multiple safeguards to reduce risk. "we view our method as part of a defense-in-depth approach, where knowledge localization and removal serve as one layer among multiple security measures rather than a standalone solution."
- Down-projection layers: Layers that project higher-dimensional representations back to lower dimensions, affecting how information flows in networks. "since activation-gradient masking does not block updates to down-projection layers (See Appendix~\ref{app:gradient_routing_variants})."
- Dual-use risks: Capabilities that can be used for both beneficial and harmful purposes. "LLMs increasingly possess capabilities that carry dual-use risks."
- False Negative Rate (FNR): The proportion of harmful samples that a classifier fails to identify, treating them as benign. "This could also be seen as FNR (False Negative Rate) of the hypothetical classifier identifying the forget data."
- FLOPs: Floating point operations, a measure of computational cost. "Dashed lines show equal compute expenditure in FLOPs (not shown on right)."
- Forget loss: Evaluation loss on the targeted domain intended for removal; higher values indicate stronger forgetting. "The y-axis shows forget loss (Biology), where higher values indicate stronger removal of biology knowledge."
- Gradient norms: Measures of gradient magnitude used to analyze which parameters are being updated and by how much. "we study the localization mechanistically using gradient norms, which serve as a proxy for identifying which parts of the network are being updated during training."
- Gradient Routing: A training-time technique that steers gradients to localize target knowledge into designated parameters. "prior work proposed Gradient Routing~\citep{cloud2024gradient} -- a technique that localizes target knowledge into a dedicated subset of model parameters so they can later be removed."
- Jailbreaks: Techniques to bypass model safety mechanisms and elicit restricted outputs. "Refusal training teaches models to decline unsafe requests, but these safeguards can often be bypassed through jailbreaks and prompt engineering~\citep{kumar2024refusal,andriushchenko2024does}."
- Kernel density estimates: Non-parametric methods for estimating the probability density function of a random variable. "Each panel shows kernel density estimates of relative gradient norms () for different parameter-data combinations."
- Knowledge localization: Constraining specific knowledge to a subset of model parameters to enable targeted removal. "we hypothesize that the model develops self-reinforcing knowledge localization."
- Label noise: Errors in dataset labels that lead to misclassification of training examples. "with particular focus on evaluating its robustness to label noise."
- Leakage: Unintended transfer of target-domain information into non-designated (retain) parameters during training. "We quantify the rate of data leakage from forget data into non-forget parameters across multiple model scales, finding that leakage decreases as models grow larger"
- Logit bias: A learned adjustment to logits applied post-training to calibrate losses or probabilities. "Calibration is computed with a trained logit bias post-training (see Appendix~\ref{app:tinystories_experimental_details})."
- LoRA: Low-Rank Adaptation; an adapter method that restricts gradient updates to small modules while freezing the base model. "The gradient masking in SGTM mirrors adapter methods like LoRA~\citep{hu2022lora}:"
- Mixture of Experts: Architectures that route inputs to specialized expert sub-models to improve modularity and efficiency. "Mixture of Experts~\citep{shazeer2017outrageously,gururangan2021demix,park2025monet}"
- Modular architectures: Designs that separate functionality across specialized components to promote composability and isolation. "modular architectures~\citep{jacobs1991task,jacobs1991adaptive,andreas2016nmn,alet2018modular,kirsch2018modular,ruder2019latent,pfeiffer2023modular}"
- Output classifiers: Auxiliary models that filter or assess generated text for safety or compliance. "Output classifiers -- auxiliary models that filter generated text -- can be circumvented by determined adversaries~\citep{schwinn2023adversarial,mckenzie2025stack}."
- Pareto dominating: Achieving strictly better trade-offs across multiple objectives than another method. "SGTM consistently achieves lower retain loss than the Gradient Routing variant of~\citet{cloud2024gradient}, while maintaining higher forget loss -- Pareto dominating prior Gradient Routing across all discovery rates tested."
- Per-token loss: Loss measured at the token level to assess granular capability degradation. "we analyze per-token loss and show that SGTMâs increased forget loss reflects broadly elevated error across biology tokens rather than a small number of extreme outliers"
- Precision and recall: Metrics for classifier performance; precision measures correctness of positive predictions, recall measures coverage of actual positives. "achieves only 44\% precision at 98\% recall, leading to the removal of over 8\% of training data."
- Representation Misdirection for Unlearning (RMU): A post-training unlearning method that redirects representations to suppress specific knowledge. "Representation Misdirection for Unlearning (RMU)~\citep{li2024wmdp}"
- Selective GradienT Masking (SGTM): A gradient-masking variant that localizes target-domain updates to designated parameters for later removal. "We explore an improved variant of Gradient Routing, which we call Selective GradienT Masking (SGTM)"
- Selective Gradient Masking: An intervention that zero-masks gradients for retain-designated parameters on forget examples during backpropagation. "Selective Gradient Masking. For samples from $\mathbf{D}_{\text{forget}$, we apply selective gradient masking during the backward pass so that these samples do not update ."
- Selective Parameter Masking: An intervention that zeroes designated forget parameters during the forward pass on retain examples to condition performance without them. "Selective Parameter Masking. For samples from $\mathbf{D}_{\text{retain}$ we apply selective parameter masking during the forward pass"
- Self-reinforcing knowledge localization: A phenomenon where initial localization causes unlabeled target-domain examples to preferentially update designated parameters. "we hypothesize that the model develops self-reinforcing knowledge localization."
- TinyStories: A synthetic dataset of short stories used for controlled bilingual experiments. "bilingual TinyStories dataset~\citep{eldan2023tinystories}."
- Transformer block: A unit in transformer architectures containing multi-head attention and MLP sublayers. "We consider a transformer block~\citep{vaswani2017attention} consisting of a multi-head attention and an MLP layer"
- Undiscovered forget percentage: The fraction of forget-domain data that remains unlabeled and thus not treated as forget during training. "We define ``undiscovered forget percentage'' as the percentage of all Spanish data that is allocated to $\mathbf{D}_{\text{unlabeled}$ instead of $\mathbf{D}_{\text{forget}$"
- Unlearning (Machine unlearning): Techniques to remove specific data or knowledge from trained models after training. "Machine unlearning techniques instead attempt to erase specific knowledge from trained models"
- WMDP: A benchmark evaluating models’ potential to assist in harmful biological tasks (Weaponizable Molecular Design or related). "Given computational constraints and needing to train models from scratch, our models are not large enough to yield meaningful results on evaluations that directly probe dangerous capabilities, like WMDP~\citep{li2024wmdp}."
Collections
Sign up for free to add this paper to one or more collections.

