- The paper introduces a compliant LLM ecosystem that enforces retroactive robots.txt and robust filtering, ensuring data privacy and ethical pretraining.
- The study presents innovative techniques like xIELU activation and Goldfish loss, achieving comparable loss with 30–40% fewer tokens and enhanced training stability.
- Extensive multilingual benchmarks and transparent, open-sourced artifacts validate the model’s performance and pave the way for reproducible, global LLM research.
Apertus: Open, Compliant, and Multilingual LLMs for Global Language Environments
Introduction and Motivation
The Apertus project presents a suite of LLMs designed to address two persistent deficits in the open LLM ecosystem: (1) the lack of data compliance and transparency, and (2) insufficient multilingual representation, especially for low-resource languages. The work is distinguished by its rigorous approach to data governance, including retroactive enforcement of robots.txt exclusions, comprehensive filtering for non-permissive, toxic, and personally identifiable content, and a strong focus on reproducibility. Apertus models are released at 8B and 70B parameter scales, with all scientific artifacts—data preparation scripts, checkpoints, evaluation suites, and training code—publicly available under permissive licenses.
Data Compliance and Filtering Pipeline
Apertus sets a new standard for data compliance in LLM pretraining. The pretraining corpus is constructed exclusively from openly available data, with retroactive application of robots.txt exclusions as of January 2025, ensuring that content owners' opt-out preferences are respected even for historical web crawls. The pipeline further removes personally identifiable information (PII) and applies multilingual toxicity filtering using language-specific classifiers trained on annotated corpora.

Figure 1: Document filtering pipeline for selected resource datasets used during pretraining, encompassing all compliance and quality filters.
This approach results in a measurable reduction in available data (e.g., 8% token loss in English), but is necessary for legal compliance under frameworks such as the EU AI Act. The filtering pipeline is fully reproducible and open-sourced, enabling external audit and extension.
Multilinguality and Tokenization
Apertus is pretrained on 15T tokens spanning 1811 languages, with approximately 40% of the data allocated to non-English content. This is a significant expansion over prior open models, which typically cover an order of magnitude fewer languages. The tokenizer is a byte-level BPE model adapted from Mistral-Nemo, selected via a rigorous evaluation of fertility rate, compression ratio, vocabulary utilization, and Gini coefficient for fairness.
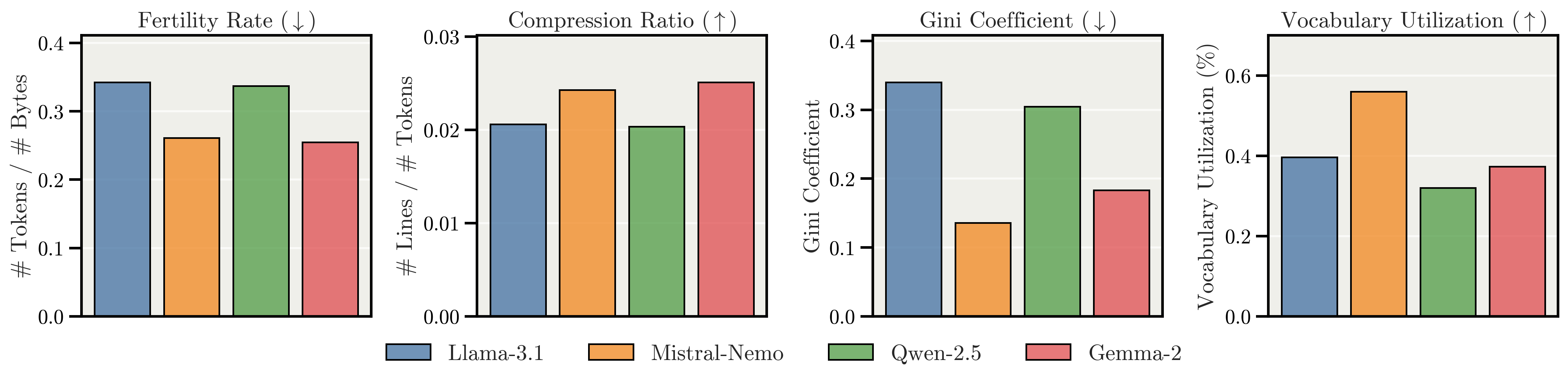
Figure 2: The Mistral-Nemo tokenizer achieves superior efficiency and fairness across languages compared to other major multilingual tokenizers.
This choice ensures equitable tokenization costs and efficient representation for both high- and low-resource languages, supporting the model’s global ambitions.
Model Architecture and Training Recipe
Apertus employs a dense decoder-only Transformer architecture with several notable modifications:
- xIELU activation: A non-gated, piecewise activation function with trainable parameters, empirically shown to outperform SwiGLU in ablations.
- QK-Norm: Query-key normalization in attention layers for improved stability.
- RMSNorm and Pre-Norm: For enhanced training stability and efficiency.
- Grouped-Query Attention (GQA): For inference efficiency at long context lengths.
- Goldfish Loss: A masked language modeling objective that suppresses verbatim memorization without degrading downstream performance.
- AdEMAMix Optimizer: A momentum-based optimizer with long-term EMA, yielding faster convergence and improved scaling.
Ablation studies demonstrate that the combination of these architectural and recipe changes enables the model to match the final training loss of a strong Llama baseline with 30–40% fewer tokens, and with improved stability and gradient norms.
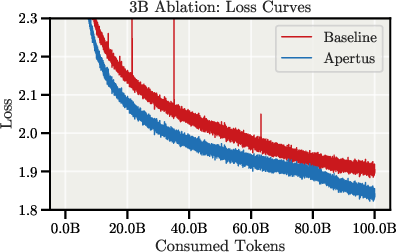
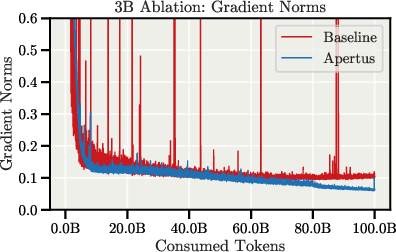
Figure 3: The final Apertus architecture achieves improved stability and matches baseline loss with substantially fewer tokens.
Pretraining is conducted on up to 4096 GPUs, with context lengths extended up to 65k tokens via staged long-context adaptation.
Pretraining Stability and Efficiency
The pretraining process is characterized by exceptional stability, with no major loss spikes or rollbacks, even during batch size doubling and data mixture transitions.
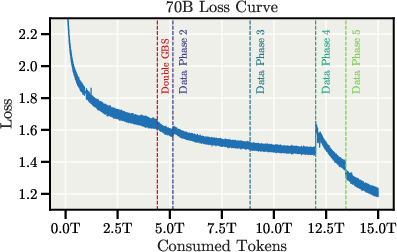
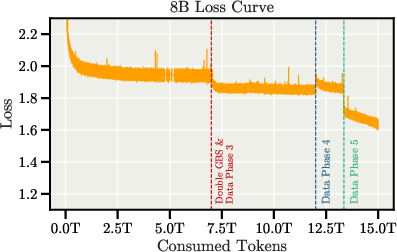
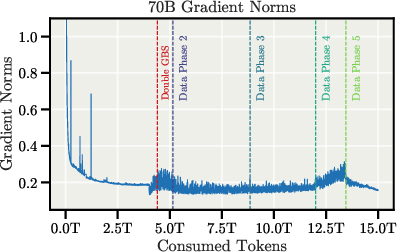
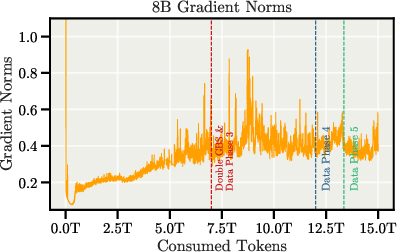
Figure 4: Pretraining loss curves and gradient norms for both 8B and 70B models, demonstrating stable training dynamics.
Aggressive gradient clipping (value 0.1) is applied, especially important for the AdEMAMix optimizer. Experiments with FP8 training yielded a 26% throughput increase but resulted in loss instability, necessitating a rollback to BF16.
Post-Training: Instruction Tuning and Alignment
Post-training follows a two-stage process: supervised finetuning (SFT) on a curated, license-compliant, and decontaminated instruction-following corpus (3.8M+ examples), and alignment using Quantile Reward Policy Optimization (QRPO). QRPO enables direct optimization of absolute reward signals, supporting both reward model and LLM-as-judge feedback, and is shown to outperform DPO at scale.
Alignment is further extended to encode constitutional values, specifically the Swiss AI Charter, validated via public surveys and operationalized through LLM-as-judge scoring for controversial prompts.
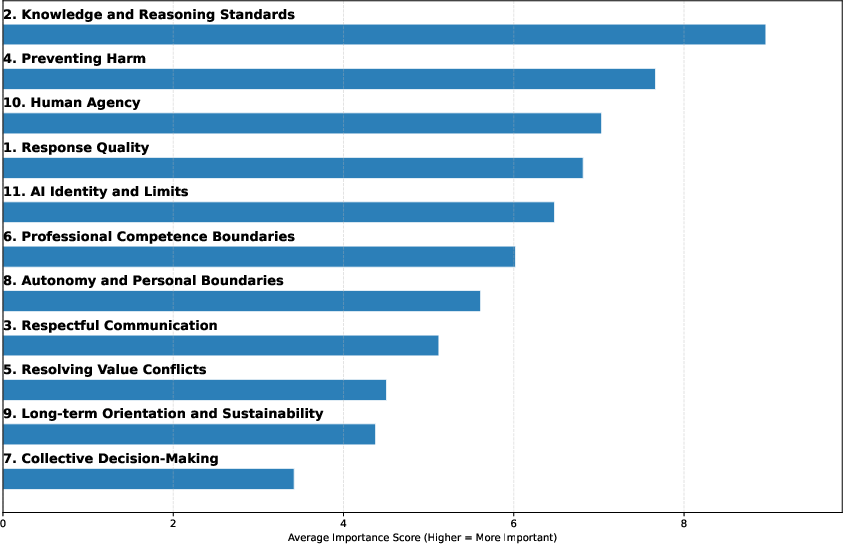
Figure 5: Survey-based rankings of the relative importance of Swiss AI Charter principles for LLM alignment.
Evaluation: Multilingual, Cultural, and Safety Benchmarks
Apertus models are evaluated on an extensive suite of benchmarks, including general language understanding, factual knowledge, reasoning, mathematics, coding, instruction following, cultural knowledge, and safety. The evaluation suite covers 94 languages, with particular attention to African and Eurasian languages.
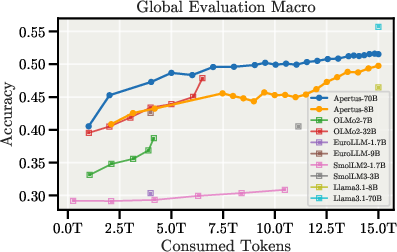
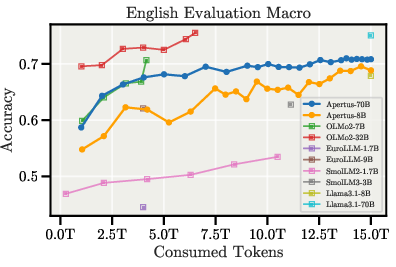
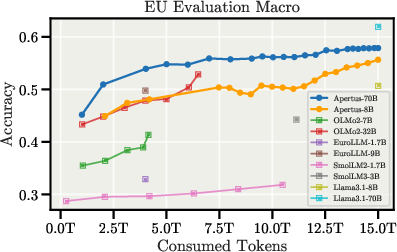
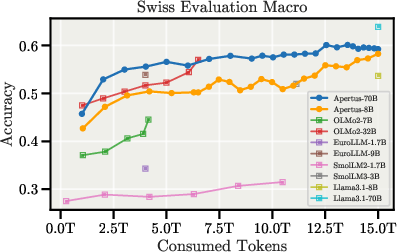
Figure 6: Downstream evaluation curves during pretraining, showing strong multilingual and regional performance.
Apertus-70B achieves the highest score among all evaluated models on the multilingual XCOPA benchmark and outperforms all other fully open models on INCLUDE V1/V2 and SwitzerlandQA. The models also demonstrate robust performance on low-resource translation tasks, notably for Romansh and its dialects.
Memorization Mitigation and Analysis
Apertus employs the Goldfish loss to suppress verbatim memorization. Empirical analysis using injected Gutenberg sequences at controlled frequencies shows that both 8B and 70B models maintain baseline Rouge-L scores across all exposure frequencies and prefix lengths, indicating effective mitigation.
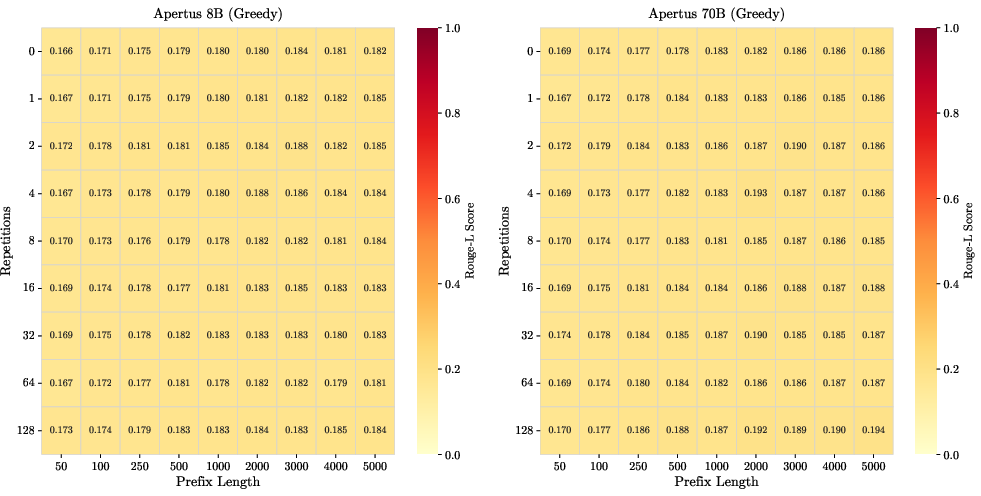
Figure 7: Heatmaps of Rouge-L scores for suffixes of 500 tokens, demonstrating successful mitigation of verbatim memorization across exposure frequencies and prefix lengths.
Further analysis reveals that Goldfish loss disrupts the typical positional fragility of memorization, with recall fluctuating rather than decaying sharply with offset. However, the approach is fragile to near-duplicates due to deterministic masking, and high recall is still observed for highly repetitive or canonical content.
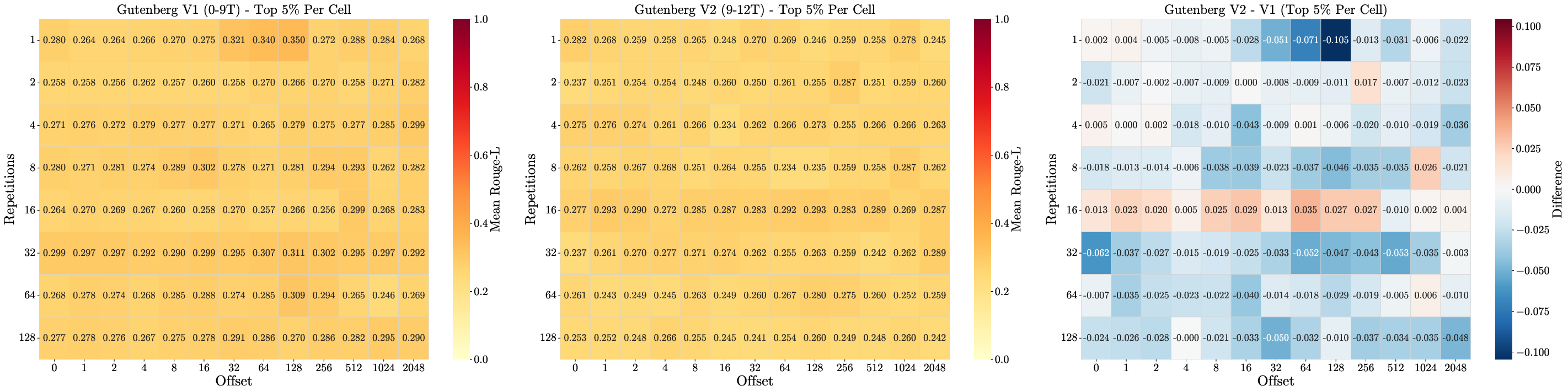
Figure 8: Memorization dynamics for sequences injected at different pretraining stages, showing a primacy effect for earlier exposures.
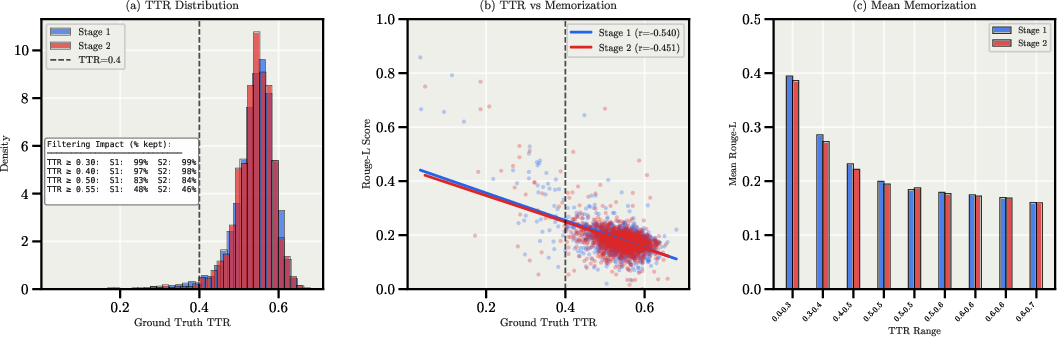
Figure 9: Negative correlation between TTR and Rouge-L, indicating that low-diversity sequences are more susceptible to template memorization.
Infrastructure and Scaling
Apertus was trained on the Alps supercomputing infrastructure, leveraging up to 4096 NVIDIA Grace-Hopper GPUs. The training pipeline incorporates containerized environments, node-vetting, and robust checkpointing strategies. After extensive systems-level and software optimizations, the 70B model achieved 80% strong scaling efficiency at 4096 GPUs, with a throughput of 723 tokens/sec/GPU.
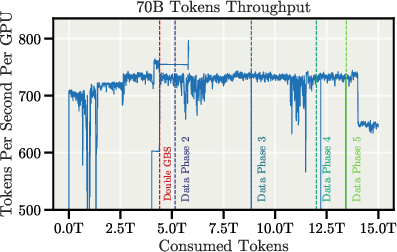
Figure 10: Token throughput during training for 70B and 8B models.
Figure 11: Throughput improvements before and after stability enhancements, highlighting the impact of storage and driver fixes.
Figure 12: Strong and weak scaling efficiency for the 70B model, demonstrating high parallel efficiency at scale.
Safety and Security
Safety evaluations include multilingual toxicity and bias benchmarks, as well as manual spot-testing for high-risk scenarios. The models perform comparably to other fully open models on BBQ, HarmBench, and RealToxicityPrompts, but do not pursue jailbreak resistance due to the open-weight nature of the release. The safety pipeline is designed to be robust across languages, with explicit recognition of the challenges posed by low-resource and non-English settings.
Conclusion
Apertus establishes a new baseline for open, compliant, and multilingual LLMs. The project demonstrates that it is feasible to train large-scale, high-performing models with rigorous data governance, full transparency, and strong multilingual coverage. The release of all artifacts under permissive licenses, together with detailed documentation and reproducibility scripts, enables independent audit and extension. The work highlights several open directions, including further scaling, distillation, data-to-performance mapping, adaptive compute, RL with verifiers, multimodality, societal alignment, and field evaluation.
Apertus provides a robust foundation for future research and deployment of trustworthy, globally relevant LLMs, and sets a precedent for open, reproducible, and compliant model development in the field.

