- The paper introduces a novel pretraining method that integrates Safety Filtering, Safety Rephrasing, native refusal, and harmfulness-tag annotation to embed safety from the start.
- It demonstrates a reduction in attack success rate from 38.8% to 8.4% while maintaining performance on standard NLP tasks.
- The approach shifts AI safety from reactive post-hoc corrections to proactive, foundational embedding of ethical principles in model training.
Safety Pretraining: Toward the Next Generation of Safe AI
Introduction
The escalating integration of LLMs in critical domains such as healthcare and public policy underscores an urgent need for robust mechanisms ensuring the safety and ethical alignment of these models. Traditional post-hoc alignment techniques fall short, as they largely fail to unlearn harmful patterns once internalized during pretraining. "Safety Pretraining: Toward the Next Generation of Safe AI" presents a novel data-centric pretraining approach designed to inherently embed safety within AI models from inception, aiming to address pervasive shortcomings in post-hoc alignment.
Methodology
The paper introduces a comprehensive framework encompassing four critical steps to fortify safety during pretraining:
- Safety Filtering: Development of a Safety Classifier distinguishes between safe and unsafe data, trained on annotated samples with an emphasis on broad adoption potential.
- Safety Rephrasing: Recontextualizing potentially unsafe web data into narratives that emphasize historical and ethical context without propagating harmful content.
- Native Refusal: Curating datasets such as RefuseWeb to inculcate models with the ability to ethically refuse harmful queries.
- Harmfulness-Tag Annotated Pretraining: Flagging unsafe content during training to guide the generation process away from potentially harmful outputs.
This strategy not only reduces the attack success rate from 38.8% to 8.4% on benchmark tests but also maintains performance on standard NLP tasks.
Results
The proposed safety pretraining framework demonstrates substantial efficacy in reducing harmful outputs:
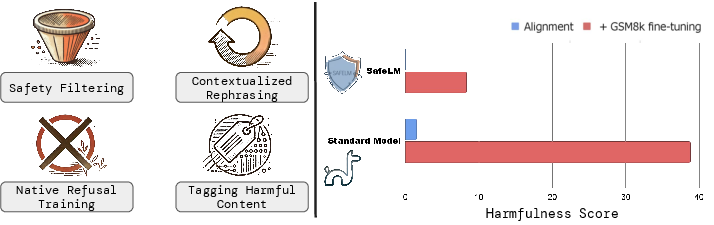
Figure 1: Safety Pretraining Yields Natively Aligned and Robust Models Against Attacks, demonstrating significantly reduced ASR across various settings.
The framework's effectiveness is evidenced by a considerable decrease in ASR and increased robustness against adversarial attacks, compared to models relying solely on post-hoc tuning.
Practical and Theoretical Implications
The research illuminates that data-centric interventions, such as rephrasing unsafe content and using moral education, build a more resilient model framework. Training models on contextually enriched data rather than excluding harmful content altogether allows models to better understand and respond to unsafe prompts responsibly.
Practically, this pretraining method ensures models are not only safer but also retain their functional efficacy across standard tasks. Theoretically, it shifts the focus in AI safety from reactive, post-training corrections to proactive, foundational embedding of safety—pioneering a pathway for creating AI systems that intrinsically align with societal and ethical norms.
Future Directions
The proposed methodology opens new avenues for research into embedding intrinsic safety features during the pretraining phase. Future work could explore integrating harmfulness-tags within different model architectures or expanding the scope of safety metrics used to evaluate model outputs.
Conclusion
In conclusion, the paper highlights the limitations of current post-hoc alignment strategies and successfully presents a strategy for embedding safety during the pretraining phase. This approach sets a precedent for developing inherently safe AI systems, advocating for a foundational embedding of ethical principles rather than relying solely on post-training adjustments.

