- The paper presents a systematic evaluation of CNN, LSTM, Transformer variants, and state-space models for naturalistic EEG decoding using a movie-watching dataset.
- It demonstrates that longer EEG segments improve classification, with S5 achieving 98.7% accuracy and operating with 20× fewer parameters than CNN.
- It reveals key trade-offs in cross-frequency and cross-subject generalization, highlighting that robust EEGXF designs better handle domain shifts despite lower overall accuracy.
Benchmarking Temporal Context and Model Architecture for Naturalistic EEG Decoding
Introduction
This paper ("Temporal Context and Architecture: A Benchmark for Naturalistic EEG Decoding" (2601.21215)) systematically evaluates how model architecture and temporal context interact in the classification of naturalistic EEG, using the HBN movie-watching dataset as a controlled benchmark. Five major neural sequence architectures are compared—CNN, bidirectional LSTM, vanilla Transformer, stabilized Transformer (EEGXF), and structured state-space models (S4, S5)—across a range of segment lengths (8–128 s) to elucidate design trade-offs for EEG decoding under real-world conditions.
Methodology
Dataset and Preprocessing
The benchmark employs raw 64-channel EEG data from the HBN collection, focusing on three movie-viewing tasks and a resting-state baseline. Signals were preprocessed via bandpass filtering, channel normalization, and segmentation (8–128 s windows, 50% overlap). Careful train/validation/test splits were applied at the recording level, eliminating the risk of temporal leakage between splits. The resulting task is 4-way classification over >15,000 segments from 40 subjects.
Model Architectures
- CNN: Local 1D convolutional encoder, favoring short-range dependencies and computational efficiency.
- LSTM: Bidirectional recurrent network designed for sequential temporal processing but encountered convergence difficulties.
- Transformer (EEGXF): Stabilized compact Transformer with aggressive normalization, norm-first architecture, and attention pooling for robust training on noisy inputs.
- S4/S5: Structured state-space models leveraging diagonalization and parameter-efficient, near-linear parallel scans for effective long-range modeling.
All models process tensor inputs of shape (batch, 64, T), with T corresponding to segment length. S5 is configured with 183K parameters, a fraction of the CNN’s 4.4M, making parameter efficiency a point of comparison.
Results
Performance Scaling with Temporal Context
Longer EEG segments boost classification accuracy for all competent architectures, with S5 and CNN displaying notably strong scaling behavior. At 64 s, S5 achieves 98.7% ± 0.6 accuracy using ~20× fewer parameters than CNN. CNN remains marginally faster in wall-clock training time, but S5 competes on both time and much-reduced resource requirements. The LSTM and S4 baselines lagged substantially; LSTM did not converge, and S4, though accurate, was too slow to be practical.
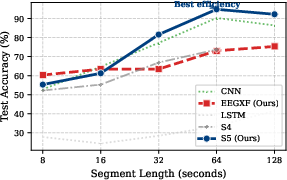
Figure 1: Test accuracy versus segment length; S5 and CNN deliver the strongest scaling with temporal context.
Evaluation at 64 s windows reveals a distinct Pareto frontier: S5 provides state-of-the-art accuracy per parameter, delivering best-in-class results at a tiny model footprint but with longer training times than CNN. EEGXF strikes a middle ground in resource usage but does not match the high-accuracy regime of CNN or S5.
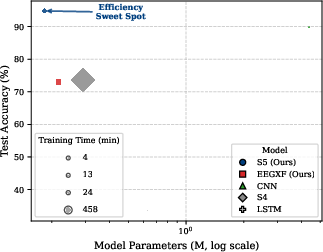
Figure 2: Model accuracy versus parameter count at 64 s; S5 is the most parameter-efficient, while CNN is fastest to train.
Generalization and Robustness
Cross-Frequency Generalization
Models were subjected to a zero-shot domain shift by testing at lower sampling rates (downsampling to 128 Hz and 64 Hz, though trained at 250 Hz). S5's accuracy degraded sharply (from 53.1% to 34.4%), indicating sensitivity to the temporal structure and possible overfitting to the original frequency. EEGXF, in contrast, maintained stable accuracy (approximately 40%), signaling greater robustness to frequency domain shifts.
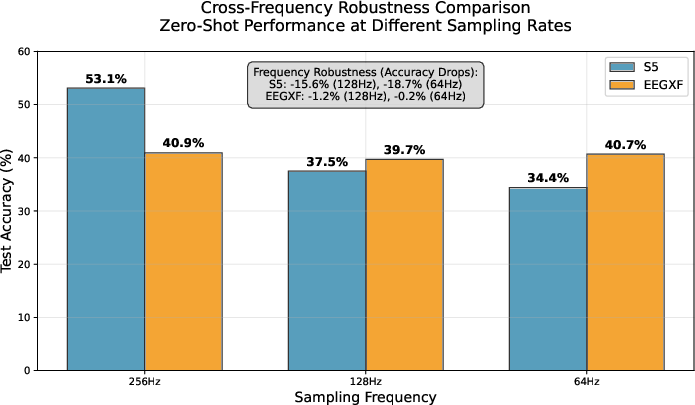
Figure 3: Zero-shot accuracy across sampling rates; S5 is sensitive to downsampling while EEGXF remains robust, reflecting a speed-accuracy-robustness triad.
Cross-Subject (LOSO) and Out-of-Distribution (OOD) Generalization
LOSO experiments demonstrated S5’s superior cross-subject generalization (mean accuracy 55.9% vs. EEGXF’s 48.4%). Statistical analysis confirmed the significance of this margin across test folds.
For OOD generalization, the classifiers were exposed to novel cognitive state tasks. S5 exhibited highly overconfident, erroneous predictions (specializing in a single movie-class output), performing well on confidence calibration in-distribution but demonstrating substantial risk in OOD deployment. EEGXF, conversely, collapsed to a neutral "resting state" prediction with appropriate uncertainty (lower mean confidence), indicating an advantageous risk-aware failure mode for real-world BCI robustness.
Implications
These results identify clear, quantifiable trade-offs between raw accuracy, efficiency, and robustness to distribution shift in naturalistic EEG decoding:
- S5, and by extension state-space models, set a new bar for parameter-efficient sequence modeling on long-context, subject-mixed neural data. They generalize better across subjects but can fail silently with high confidence on unmodeled data.
- EEGXF (and analogous stabilized transformer designs) are more robust against temporal domain shifts, and their conservative uncertainty handling aligns with safety requirements in practical BCIs or clinical monitoring.
- CNNs achieve strong but less scalable results and remain an optimal baseline for low-resource, controlled tasks, but lack generalization depth.
Discussion and Future Directions
This systematic benchmarking demonstrates the necessity of multi-faceted evaluation: accuracy alone is insufficient for critical systems where generalization and robustness are paramount. The sharp accuracy drop for S5 under cross-frequency tests, and its overconfident errors on OOD tasks, highlight avenues for targeted regularization or hybridization with uncertainty-aware modules. Adaptation to domain shift—whether temporal, subject-level, or context-based—remains a core challenge.
Open directions include validating these architectural results on additional datasets (e.g., Sleep-EDF) and integrating hybrid approaches that combine the calibration strengths of robust transformers with the parameter and generalization efficiency of structured state-space models. Finally, the methodology and codebase published with this benchmark serve as a reference resource for reproducible EEG architecture evaluation.
Conclusion
This research provides an authoritative analysis of how temporal context and network architecture interact for naturalistic EEG decoding. S5 sets the standard for accuracy and efficiency in favorable distributions, but its lower robustness compared to EEGXF frames a fundamental trade-off for BCI deployment. The insights and open-source tools offered here will shape both practical system design and theoretical advances in neural sequence modeling.