EEG-Titans: Long-Horizon Seizure Forecasting via Dual-Branch Attention and Neural Memory
Abstract: Accurate epileptic seizure prediction from electroencephalography (EEG) remains challenging because pre-ictal dynamics may span long time horizons while clinically relevant signatures can be subtle and transient. Many deep learning models face a persistent trade-off between capturing local spatiotemporal patterns and maintaining informative long-range context when operating on ultralong sequences. We propose EEG-Titans, a dualbranch architecture that incorporates a modern neural memory mechanism for long-context modeling. The model combines sliding-window attention to capture short-term anomalies with a recurrent memory pathway that summarizes slower, progressive trends over time. On the CHB-MIT scalp EEG dataset, evaluated under a chronological holdout protocol, EEG-Titans achieves 99.46% average segment-level sensitivity across 18 subjects. We further analyze safety-first operating points on artifact-prone recordings and show that a hierarchical context strategy extending the receptive field for high-noise subjects can markedly reduce false alarms (down to 0.00 FPR/h in an extreme outlier) without sacrificing sensitivity. These results indicate that memory-augmented long-context modeling can provide robust seizure forecasting under clinically constrained evaluation
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about predicting epileptic seizures before they happen by reading brain signals recorded with EEG (electroencephalography). The authors built a new AI model, called EEG-Titans, that tries to catch tiny warning signs that can appear many minutes before a seizure, even when the signals are noisy and the important patterns are spread out over long periods of time.
Key Objectives
The researchers set out to answer simple but tough questions:
- Can we predict seizures early (5–30 minutes before they start) using scalp EEG?
- Can a model watch both short, quick changes and slow, long-term trends at the same time?
- Can we do this in a way that works realistically over time, without “cheating” by peeking at future data during training?
- Can we keep sensitivity (catching true seizure warnings) very high while keeping false alarms low, especially for patients with noisy recordings?
How They Did It
The team combined smart data preparation with a dual-branch AI model that looks at brain signals in two different ways—like using both a magnifying glass and a long-term diary.
Data and Labeling
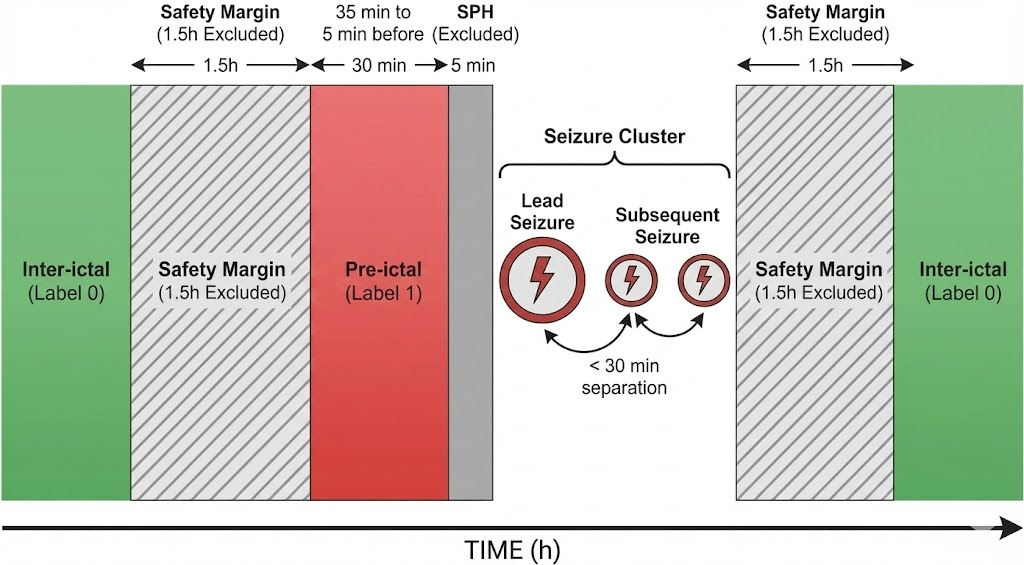
- They used a well-known dataset called CHB-MIT, which contains many hours of EEG from children with epilepsy.
- From 24 original subjects, they selected 18 who had consistent recordings and enough seizure events to evaluate properly over time.
- They focused on the “pre-ictal” period, which is the 30 minutes before a seizure. To be realistic and give time for action, they ignored the last 5 minutes just before the seizure (this is called the Seizure Prediction Horizon, SPH).
- To avoid mixing normal brain activity with seizure-related changes, they removed 1.5 hours of EEG around each seizure cluster, so the “inter-ictal” (normal) data is clean.
The Model: Two Branches Working Together
Think of EEG-Titans like a two-tool system:
- A “spatial tokenizer” first listens to the EEG from multiple channels, a bit like tuning a radio to different frequencies and directions across the head. It turns raw signals into compact “tokens” that capture useful patterns.
- A “temporal backbone” then reads those tokens over time using two branches:
- Short-term attention: like a spotlight scanning the last few seconds to catch quick spikes or odd shapes.
- Neural memory: like a diary that keeps track of slower changes building up over minutes. It updates gently, remembering important trends while ignoring random noise.
- A smart gate blends the two: if quick changes look meaningful and match the longer build-up, the model raises the seizure probability. If quick changes look like random noise, the memory branch can tone them down.
Turning Predictions into Practical Alarms
To avoid triggering alarms from one noisy moment:
- The model looks at a short window of recent predictions and averages the top few scores, making alarms more stable.
- Each patient gets their own alarm threshold (because EEGs vary a lot from person to person).
- There’s a 30-minute “cooldown” after any alarm, so you don’t get spammed by repeated alerts from the same episode.
Evaluation That Respects Time
- They trained the model on earlier recordings and tested it on later ones, keeping the time order. This prevents accidental “future knowledge.”
- They focused on segment-level sensitivity, meaning: does the model consistently spot most of the pre-ictal segments, not just trigger one alarm?
- They measured false positives per hour (FPR/h), which tells you how many wrong alarms you’d get in an hour of normal EEG.
Main Findings
Across 18 patients:
- The model reached an average segment-level sensitivity of 99.46%. For 16 out of 18 patients, it was 100%.
- The average false alarm rate was 0.371 per hour. Most patients had low false alarms (often below 0.2 per hour), but two patients were outliers.
Two key lessons stood out:
- For a very noisy patient (CHB15), increasing the short-term context from 1 minute to 5 minutes made a huge difference: false alarms dropped from 3.87 per hour to 0.00, while sensitivity jumped to 99.86%. Longer context helped the model see that brief bursts of noise didn’t match a steadily growing pre-seizure pattern.
- For a very young patient (CHB06), the model kept perfect sensitivity but had higher false alarms (0.90 per hour), likely because pediatric EEG can be highly variable and seizures were very short. This suggests some patients may need special tuning.
An additional “ablation” test compared versions of the model:
- The neural memory branch helped reduce false alarms compared to using only attention or only an LSTM (a common type of recurrent neural network), while keeping sensitivity high. This supports the idea that memory-augmented long-range modeling stabilizes predictions.
Why It Matters
This research shows a practical way to predict seizures early, with high coverage and careful respect for time. The dual-branch design—fast attention plus slow memory—seems especially good at telling the difference between true warning signs and random noise. It can:
- Improve safety by catching most pre-seizure periods.
- Reduce alarm fatigue by lowering false positives, especially if we adjust the context length for noisy patients.
- Fit real-life use by avoiding methods that are too slow or require looking far into the future.
Implications and Potential Impact
- For patients and caregivers: More reliable early warnings could help people get to a safe place or prepare medication before a seizure happens.
- For clinicians: A “sensitivity-first” setup reflects real-world priorities—missing a seizure is worse than a few false alarms. Still, the model shows concrete ways to cut false alarms with patient-specific adjustments.
- For AI in healthcare: Memory-augmented models that handle long-range context efficiently can be useful beyond seizures, like in other brain or heart monitoring tasks where important changes build up slowly.
- For future work: Automating the choice of context length and adding pediatric-specific calibration could make the system even more robust and fair across different patients.
In short, EEG-Titans is a promising step toward trustworthy, long-horizon seizure forecasting: it listens closely, remembers wisely, and balances quick signals with slow trends to keep people safer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and can guide future research:
- External validity beyond CHB-MIT: No evaluation on independent datasets (e.g., TUH, EPILEPSIAE, Melbourne) or adult/intracranial EEG, leaving cross-site and cross-population generalization unknown.
- Patient-level generalization: The chronological hold-out is within-subject; it remains unclear whether a single global model generalizes across unseen patients without subject-specific calibration.
- Selection bias from subject exclusions: Six subjects were excluded (montage heterogeneity, insufficient clusters, missing metadata); the impact of these exclusions on representativeness and performance estimates is not quantified.
- Montage constraints: Restricting to 18 common bipolar channels improves consistency but limits applicability to centers with different montages; robustness to alternative/variable montages is untested.
- Real-time feasibility and resource costs: No measurements of latency, memory footprint, energy use, or throughput for streaming inference on edge/wearable hardware despite long-context claims.
- Event-level performance: Results emphasize segment-level sensitivity; event-based metrics (per-seizure sensitivity, time-in-warning, time-to-alarm distribution) are not reported.
- Alarm timing and anticipation: Early warning horizons and alarm lead-time variability relative to onset are not analyzed, impeding assessment of practical intervention windows.
- Operating characteristic curves: Lack of ROC/PR curves or operating-point sweeps under the same protocol limits interpretability of sensitivity–specificity trade-offs and comparison with prior work.
- Comparability to prior SOTA: Reported FPR/h differs markedly from some literature; absence of re-evaluation of baselines under the same chronological protocol hinders apples-to-apples comparisons.
- Confidence intervals and statistical testing: No per-subject or cohort-level CIs, variance across runs, or statistical tests, limiting conclusions about robustness and significance.
- Threshold calibration: Patient-specific thresholding via coarse grid search (0.05 steps) may be suboptimal; calibration reliability and overfitting risks to validation splits are not examined.
- Distribution shift and drift: Model robustness under day-to-day non-stationarity, medication changes, sleep–wake cycles, and longer-term drift is not evaluated; no continual/adaptive learning strategy is proposed.
- Memory behavior characterization: The effective time horizon, retention/forgetting dynamics, and susceptibility to memory contamination by artifacts are not analyzed; no reset policy for memory across seizure/post-ictal transitions in continuous monitoring is specified.
- Parameter-matched ablation: Ablations do not control for model capacity; it is unclear how much of the gain stems from the memory mechanism versus parameter count or architecture depth.
- Hyperparameter sensitivity: Key design choices (local attention window, token length, memory size, soft-fusion window W and top-K) lack sensitivity analyses or principled selection guidance.
- Labeling assumptions: Performance sensitivity to pre-ictal window (35–5 min), SPH=5, SOP=30, and the 30-min seizure clustering rule is not tested; clinical variability in pre-ictal duration remains unaddressed.
- Safety margins and real-world transfer: A 1.5-hour safety margin around seizures is enforced for training/evaluation; performance without such margins (as in real deployments) is unknown.
- Artifact handling: Apart from basic filtering, no explicit artifact detection/suppression (e.g., EMG/eye/motion) is integrated; robustness to artifact bursts and different noise sources is only qualitatively discussed.
- Pediatric heterogeneity: Elevated FPR in very young subjects (e.g., CHB06) suggests age-dependent non-stationarity; no dedicated pediatric calibration protocol or age-stratified analysis is provided.
- Context-length adaptation: Extending context from 60 s to 300 s reduces FPR in CHB15, but there is no automatic, causal policy to adapt context online or analysis of the trade-off with warning latency.
- Interpretability: No channel-, frequency-, or time-level attribution for predictions or memory states; clinical validation of learned biomarkers is lacking.
- Probability calibration and uncertainty: Predicted probabilities’ calibration quality is not assessed; there is no uncertainty/OOD detection to defer decisions in artifact-heavy or ambiguous segments.
- Imbalance and augmentation: The impact of using overlapped positives only during training on generalization/calibration is unclear; alternative class-imbalance strategies (e.g., focal loss, cost-sensitive learning) are not explored.
- Sleep and behavioral covariates: No modeling or stratification by sleep stage/time-of-day, despite their known influence on seizure likelihood and EEG background.
- Refractory-period choice: The 30-minute refractory period’s effect on FPR/h and missed alarms is not ablated; optimal refractory durations may vary by patient/context.
- Preprocessing portability: Notch filtering is fixed at 60 Hz; performance in 50 Hz regions or with different hardware noise profiles is unknown.
- Seizure-type stratification: Lack of analysis by seizure morphology (focal vs generalized), duration, or localization obscures condition-specific strengths/weaknesses.
- Continuous deployment protocol: Procedures for memory resets, handling post-ictal transition, and safe re-entry to inter-ictal operation in uninterrupted monitoring are not specified.
- Reproducibility: Training details (seeds, epochs, early stopping), code/models, and exact hyperparameters are not released, limiting independent verification and extension.
- Ethical and fairness considerations: The paper flags outlier cases but does not quantify subgroup fairness (age, sex), user burden (alarms/day), or patient-reported outcomes in a deployment scenario.
- Alternative long-sequence baselines: No direct empirical comparison to modern state-space models (e.g., Mamba/SSMs) under the same protocol, despite positioning memory as a long-context solution.
- Multimodal integration: Potential gains from adding ECG/EOG/accelerometry for artifact disambiguation and context are not explored.
Glossary
- Adaptive decay mechanism: A learnable update rule that controls how much of the previous memory state is retained versus overwritten at each time step. "updated at each time step via an adaptive decay mechanism"
- Band-pass filter: A signal processing filter that keeps frequencies within a specified range and attenuates those outside it. "and then band-pass filtered from 0.5 to 100~Hz to retain physiologically relevant activity."
- Bipolar channels: EEG channel configuration formed by taking the voltage difference between pairs of electrodes to improve spatial specificity. "we restrict analysis to 18 bipolar channels that are common across all subjects,"
- CBAM-3D CNN: A 3D convolutional neural network enhanced with Convolutional Block Attention Module to emphasize informative features. "CBAM-3D CNN + BiLSTM (STFT)"
- Causal mask: A masking matrix that prevents attention from accessing future time steps, preserving temporal causality. "a causal mask is applied:"
- Causal sliding-window attention: Attention restricted to a recent, causal neighborhood to model short-range dependencies without future leakage. "Local branch (causal sliding-window attention):"
- CHB-MIT Scalp EEG database: A public pediatric EEG dataset widely used for seizure prediction research. "This study uses the CHB-MIT Scalp EEG database, a widely used benchmark for seizure prediction research"
- Chronological hold-out: An evaluation protocol that trains on earlier data and tests on later data to preserve temporal order and avoid leakage. "a chronological hold-out strategy that preserves temporal order between training and testing data."
- Continuous Wavelet Transform (CWT): A time–frequency transform that represents a signal with scaled and shifted wavelets for multi-resolution analysis. "Multi-channel ViT + CWT"
- False positive rate per hour (FPR/h): The number of false alarms generated per hour of inter-ictal data, reflecting usability. "False positive rate per hour (FPR/h):"
- Filter Bank Common Spatial Patterns (FBCSP): A feature extraction method that learns spatial filters across multiple frequency bands to maximize class separability. "Filter Bank Common Spatial Patterns (FBCSP)"
- Ictal: Pertaining to the seizure event period itself. "In contrast to the pronounced morphological signatures observed during ictal events,"
- Inter-ictal: Periods between seizures characterized by baseline EEG activity. "The inter-ictal phase (Label~0) represents baseline EEG far from seizure activity."
- International 10–20 electrode placement system: A standardized scheme for placing EEG electrodes on the scalp. "Recordings follow the international 10--20 electrode placement system;"
- Log-power representation: A feature representation obtained by averaging squared signal values and applying a logarithm to approximate power on a log scale. "This yields a log-power representation, which is closely related to spectral power features"
- Log-variance activation: An EEG-specific nonlinearity combining squaring, averaging, and logarithmic compression to approximate signal power. "Log-variance activation (square and log-pooling):"
- Memory-as-a-Gate (MAG): A Titans module that fuses local attention with a neural memory branch via a learned gate to balance short- and long-term context. "specifically the Memory-as-a-Gate (MAG) variant,"
- Montage (EEG montage): The arrangement or referencing scheme of EEG electrodes that determines how signals are derived. "substantial montage changes"
- Neural memory: A learnable persistent state that stores long-range information with fixed per-step computation for long-context modeling. "a modern neural memory mechanism for long-context modeling."
- Notch filter: A filter that removes a narrow band of frequencies, commonly used to suppress power-line interference. "Raw EEG is notch-filtered at 60~Hz to attenuate power-line interference,"
- Post-ictal: The recovery period following a seizure, often featuring altered EEG dynamics. "To reduce contamination by post-ictal effects and potential early physiological drifts near seizure onset,"
- Pre-ictal: The period leading up to a seizure where subtle predictive changes may occur. "The pre-ictal phase (Label~1) is defined as the interval from 35 to 5 minutes prior to the onset of the lead seizure"
- Refractory period: A fixed interval after an alarm during which additional alarms are suppressed to avoid duplicates. "we enforce a 30-minute refractory period"
- Safety-first: An operating philosophy prioritizing maximal sensitivity (avoiding missed seizures) before optimizing false alarms. "We adopt a safety-first perspective that prioritizes high sensitivity"
- Safety margin: A buffer interval excluded from analysis to prevent label leakage and contamination around seizure-related periods. "we enforce a safety margin of 1.5 hours around each seizure cluster"
- Seizure cluster: A group of seizures occurring close in time, treated as a single episode for labeling and evaluation. "we group seizures separated by less than 30 minutes into a single cluster,"
- Seizure Occurrence Period (SOP): The time window after an alarm within which a seizure is expected for it to count as a correct prediction. "the Seizure Occurrence Period (SOP)."
- Seizure Prediction Horizon (SPH): A buffer period immediately before seizure onset during which alarms are not counted to allow for response time. "The final 5 minutes before onset correspond to the Seizure Prediction Horizon (SPH)"
- Segment-based sensitivity: The proportion of correctly identified pre-ictal segments, measuring consistent detection across the target window. "Segment-based sensitivity:"
- ShallowConvNet: An EEG-specific convolutional architecture designed to learn spectro-spatial filters and approximate classical pipelines like FBCSP. "We adopt ShallowConvNet as the spatial tokenizer"
- Sliding-window attention: Attention computed over a moving local window to capture short-term dependencies efficiently. "The model combines sliding-window attention to capture short-term anomalies"
- Spectro-spatial features: Features that jointly capture frequency (spectral) and spatial (across channels) characteristics of EEG. "to extract spectro-spatial features and produce a token sequence;"
- State-space models (SSMs): Sequence models with latent dynamical systems that are efficient for long-range temporal dependencies. "state-space models (SSMs) have recently gained traction for long-context learning"
- STFT (Short-Time Fourier Transform): A time–frequency transform that analyzes localized frequency content over sliding windows. "3-Tower Transformer + STFT"
- TCN (Temporal Convolutional Network): A convolutional sequence model with causal, dilated convolutions for long-range dependencies. "TCN + Self-Attention"
- Titans: A memory-augmented long-context modeling framework that integrates test-time neural memory with attention. "inspired by Titans, a recent advance in long-context modeling via test-time memory mechanisms"
- Transformer-based self-attention: A mechanism that models pairwise interactions across sequence positions, enabling global context integration. "Transformer-based self-attention alleviates the global-context bottleneck,"
- Vision Transformer (ViT): A transformer architecture originally for images, here adapted to multi-channel EEG representations. "Multi-channel ViT + CWT"
- Window-based soft decision: A decision strategy that aggregates model probabilities over a window to stabilize alarms against transient artifacts. "we adopt a window-based soft decision scheme rather than applying an instantaneous hard threshold"
Practical Applications
Practical Applications of the paper’s findings, methods, and innovations
Below are actionable use cases derived from EEG-Titans’ dual-branch attention with neural memory, the safety-first evaluation strategy, and the hierarchical context adaptation findings.
Immediate Applications
These can be piloted today (with appropriate clinical oversight and non-diagnostic positioning), or adopted directly in research, product prototypes, and hospital IT workflows.
- Healthcare: EEG seizure forecasting decision-support add-on for inpatient monitoring
- Use case: Real-time pre-ictal warning aid on hospital EEG systems (central monitoring dashboards), using patient-specific thresholds, Top-K soft fusion, and a 30-minute refractory period to reduce alarm fatigue.
- Potential tools/products: “EEG‑Titans Live” plugin for existing EEG monitoring software; clinician-facing alert dashboard; alarm-triage module.
- Assumptions/Dependencies: Non-diagnostic positioning; subject-specific calibration; artifact-heavy cases may require context extension; evaluated mainly on pediatric CHB-MIT—adult/generalization not yet established.
- Digital health: Ambulatory EEG alert prototype (home/outpatient)
- Use case: Near real-time smartphone notifications for patients wearing ambulatory EEG or consumer-grade headbands; integrates diary logging and caregiver alerts.
- Potential tools/products: Mobile app + cloud inference; low-latency streaming pipeline; patient calibration wizard (threshold/tuning).
- Assumptions/Dependencies: Reliable wearable EEG data quality; battery/compute constraints; caregiver workflows; data privacy and HIPAA/GDPR compliance.
- Clinical workflow optimization: Safety-first operating policy
- Use case: Standardize sensitivity-first operation with SPH/SOP parameters, subject-specific thresholds, and refractory periods to harmonize alarm handling and documentation.
- Potential tools/products: SOP/SPH-aware alert rules engine; policy checklist; alarm audit reports (FPR/h per patient).
- Assumptions/Dependencies: Institutional buy-in; alignment with clinical risk tolerance; acceptance that false positives may remain in edge cases.
- Research/Academia: Reproducible, causal evaluation toolkit
- Use case: Adopt chronological hold-out (no temporal leakage), seizure clustering, safety margins, and segment-level sensitivity for fair benchmarking across labs.
- Potential tools/products: Open-source “ChronEval-EEG” pipeline (EDF ingestion, clustering, labeling, SPH/SOP enforcement).
- Assumptions/Dependencies: Access to raw timeline metadata; standardized channels; consistent preprocessing; community consensus on protocol.
- Healthcare IT/Software: Artifact-aware context tuning workflow
- Use case: When FPR/h spikes (e.g., muscle artifacts), automatically extend local context windows (e.g., 60s → 300s) to suppress temporally incoherent bursts.
- Potential tools/products: Context-length controller; artifact detection heuristics integrated with MAG backbone.
- Assumptions/Dependencies: Artifact detection confidence; latency trade-offs; maintain causal processing and responsiveness.
- MLOps for clinical AI: Reliability monitoring and patient-level analytics
- Use case: Continuous tracking of segment-level sensitivity and FPR/h per patient; alert consolidation via refractory period; gating diagnostics.
- Potential tools/products: Reliability dashboards; alarm fatigue KPIs; per-subject performance cards; drift and non-stationarity alerts.
- Assumptions/Dependencies: Longitudinal data; robust telemetry; privacy-preserving logging; clinician review loops.
- Software/ML: Ready-to-use modeling components for long-horizon streams
- Use case: Package ShallowConvNet tokenizer + Titans MAG backbone for tokenization and scalable long-context modeling in streaming EEG.
- Potential tools/products: “EEG‑Titans SDK” (Python/PyTorch), with causal sliding-window attention and memory-as-a-gate.
- Assumptions/Dependencies: Engineering integration; parameter tuning; compute constraints on edge vs. cloud.
- Industry prototypes (anomaly detection): Streaming log/telemetry monitoring
- Use case: Apply MAG-style memory gating to reduce false alarms while keeping high sensitivity in industrial telemetry (e.g., manufacturing line sensors, basic cybersecurity log anomalies).
- Potential tools/products: Memory-augmented streaming anomaly detector; sliding-window attention in SIEM/IoT analytics.
- Assumptions/Dependencies: Domain data availability; quick adaptation of tokenization; KPIs adapted from FPR/h to domain-specific rates.
Long-Term Applications
These require additional clinical validation, scaling, cross-population generalization, regulatory clearance, or substantial engineering.
- Healthcare/Medical devices: Regulatory-approved seizure forecasting wearables
- Use case: Certified pre-ictal warning system integrated into medical-grade ambulatory EEG or consumer wearables, with cloud/edge inference and clinician oversight.
- Potential tools/products: FDA/CE-marked predictive device; reimbursement-ready digital therapeutic; care team portal.
- Assumptions/Dependencies: Multi-center trials across diverse cohorts (adult/pediatric); rigorous clinical endpoints (event-based metrics); regulatory evidence for safety and efficacy.
- Neurostimulation and therapeutics: Closed-loop intervention
- Use case: Trigger responsive neurostimulation (RNS/DBS) or just-in-time medication reminders/dispensing during pre-ictal windows.
- Potential tools/products: Interfaces between EEG-Titans and implantable stimulators/drug pumps; safety interlocks.
- Assumptions/Dependencies: Extremely low false positives; latency guarantees; clinical protocols and ethics; device interoperability.
- Pediatric care pathways: Age-specific calibration and fairness protocols
- Use case: Dedicated pediatric modeling strategies (non-stationary EEG, short seizures), with fairness audits and adaptive retention parameters.
- Potential tools/products: Pediatric calibration module; age-aware thresholds and frequency weighting; fairness dashboards.
- Assumptions/Dependencies: Large pediatric datasets; normative EEG development models; clinical guideline integration.
- Automated context selection and artifact governance
- Use case: Meta-controller that adapts context window and memory retention online based on artifact scores, uncertainty, and patient state.
- Potential tools/products: Context/retention scheduler; artifact classifiers; policy engine enforcing causality.
- Assumptions/Dependencies: Robust artifact detection; on-device resource headroom; rigorous validation to avoid missed events.
- Multimodal forecasting: EEG + ECG + motion + EDA integration
- Use case: Combine physiological streams to improve robustness and reduce false alarms, using memory gating across modalities.
- Potential tools/products: Multisensor wearable suite; cross-modal tokenizer; fusion MAG backbone.
- Assumptions/Dependencies: Sensor fusion standards; synchronization and drift handling; privacy and consent for multi-stream data.
- Personalization at scale: Continual/federated learning
- Use case: Privacy-preserving updates to patient models, subject-specific thresholds, and retention gates over time.
- Potential tools/products: Federated training platform; on-device adaptation; calibration-as-a-service.
- Assumptions/Dependencies: Data governance; catastrophic forgetting safeguards; robust personalization KPIs.
- Trust and interpretability: Memory/gate explainability for clinicians
- Use case: Visualize which signals influence alarms, how the gate balances local vs. long-term context, and provide case-level rationales.
- Potential tools/products: Explainability suite (gate trajectories, token saliency); chart-integrated narratives.
- Assumptions/Dependencies: Clinician usability; validated explanations aligned with neurophysiology; medico-legal considerations.
- Cross-domain long-horizon anomaly forecasting
- Use case: Adapt MAG memory gating to energy grid stability forecasting, predictive maintenance in robotics/industrial IoT, and finance market microstructure anomaly alerts.
- Potential tools/products: Sector-specific tokenizers (spectral for grid; vibration for machines; order-book tokens for finance); streaming inference.
- Assumptions/Dependencies: Domain data and labels; KPI alignment (e.g., outage prevention, downtime reduction); sector-specific compliance.
- Policy and standards: Evaluation and safety frameworks for forecasting AI
- Use case: Codify chronological hold-out (no leakage), SOP/SPH definitions, alarm fatigue metrics (FPR/h), and subject-level reporting in regulatory guidance and clinical standards.
- Potential tools/products: Standard operating procedures; certification checklists; reporting templates.
- Assumptions/Dependencies: Multi-stakeholder consensus; alignment with payers and professional societies; post-market surveillance.
- Data infrastructure: Longitudinal, diverse EEG repositories and synthetic augmentation
- Use case: Build large-scale, heterogeneous EEG datasets (adult/pediatric, ambulatory/inpatient), with standardized montages and artifact labels for robust training.
- Potential tools/products: Data commons; annotation tooling; cohort curation and provenance tracking.
- Assumptions/Dependencies: Funding, ethical approvals, de-identification; interoperability across devices/montages.
- Edge AI hardware/software: Low-power deployment of MAG on wearables
- Use case: Optimize Titans/MAG inference on microcontrollers or neural accelerators to extend battery life while maintaining long-context memory.
- Potential tools/products: Kernel libraries for causal attention + memory; quantization/pruning strategies; on-device schedulers.
- Assumptions/Dependencies: Hardware vendor collaboration; acceptable latency/accuracy trade-offs; robust OTA updates.
- Clinical trial platforms: Sensitivity-first studies and alarm management
- Use case: Orchestrate trials that prioritize sensitivity, track alarm fatigue, and evaluate subject-level adaptation (e.g., context length policies).
- Potential tools/products: Trial management software; standardized endpoints; remote monitoring integration.
- Assumptions/Dependencies: Regulatory design approvals; patient adherence; multi-site coordination.
Notes on overarching assumptions and dependencies
- Data realism and generalization: Results are derived from CHB-MIT (pediatric, limited to 18 subjects after channel standardization and sequence constraints). Adult and broader ambulatory generalization needs validation.
- Labeling protocol: Pre-ictal defined as 35–5 minutes before onset; 5-minute SPH, 30-minute SOP, and 1.5-hour safety margins. Clinical utility may vary with different horizons and care pathways.
- Patient heterogeneity: Elevated false positives in artifact-heavy/non-stationary cases (e.g., CHB15, CHB06) highlight the need for subject-specific adaptation.
- Resource constraints: Long-context modeling must meet edge compute and battery requirements for wearables; memory gating helps but still needs optimization.
- Regulatory and clinical adoption: Diagnostics require rigorous trials, interpretability, and trust frameworks; near-term positioning should be “adjunct decision support,” not standalone diagnostic.
Collections
Sign up for free to add this paper to one or more collections.