EEG Emotion Classification Using an Enhanced Transformer-CNN-BiLSTM Architecture with Dual Attention Mechanisms
Abstract: Electroencephalography (EEG)-based emotion recognition plays a critical role in affective computing and emerging decision-support systems, yet remains challenging due to high-dimensional, noisy, and subject-dependent signals. This study investigates whether hybrid deep learning architectures that integrate convolutional, recurrent, and attention-based components can improve emotion classification performance and robustness in EEG data. We propose an enhanced hybrid model that combines convolutional feature extraction, bidirectional temporal modeling, and self-attention mechanisms with regularization strategies to mitigate overfitting. Experiments conducted on a publicly available EEG dataset spanning three emotional states (neutral, positive, and negative) demonstrate that the proposed approach achieves state-of-the-art classification performance, significantly outperforming classical machine learning and neural baselines. Statistical tests confirm the robustness of these performance gains under cross-validation. Feature-level analyses further reveal that covariance-based EEG features contribute most strongly to emotion discrimination, highlighting the importance of inter-channel relationships in affective modeling. These findings suggest that carefully designed hybrid architectures can effectively balance predictive accuracy, robustness, and interpretability in EEG-based emotion recognition, with implications for applied affective computing and human-centered intelligent systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a computer to guess someone’s emotional state (neutral, positive, or negative) by looking at their brainwave data, called EEG. The authors build a new “hybrid” AI model that mixes several smart parts so it can find patterns in these complicated signals more accurately and more reliably than older methods.
What questions did the researchers ask?
They focused on two big questions:
- Can a model that combines three ideas—convolutions (spotting local patterns), sequences (tracking changes over time), and attention (focusing on the most important parts)—do a better job at recognizing emotions in EEG than common machine learning methods?
- Which types of EEG features (like basic statistics, frequency bands, or relationships between brain channels) are most helpful for telling emotions apart?
How did they do it?
First, here’s what EEG is: EEG (electroencephalography) measures tiny electrical signals from your brain with sensors on the scalp. Imagine placing many microphones around a stadium to listen to a crowd—each mic hears part of the whole story. The challenge is that EEG data is high-dimensional (lots of numbers), noisy, and varies from person to person.
They used a public dataset with:
- 2,529 examples.
- Each example has 988 features (numbers describing the EEG signal in different ways).
- Three emotion labels: neutral (0), positive (1), negative (2).
To prepare the data, they:
- Standardized features (like converting different units to a common scale so no feature dominates unfairly).
- Split data into training and testing sets (80%/20%) and used cross-validation (testing across multiple folds) to avoid lucky results.
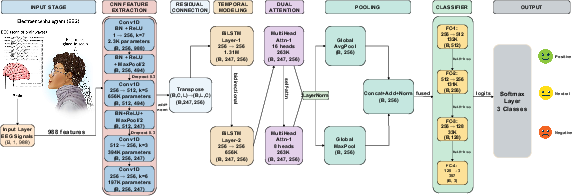
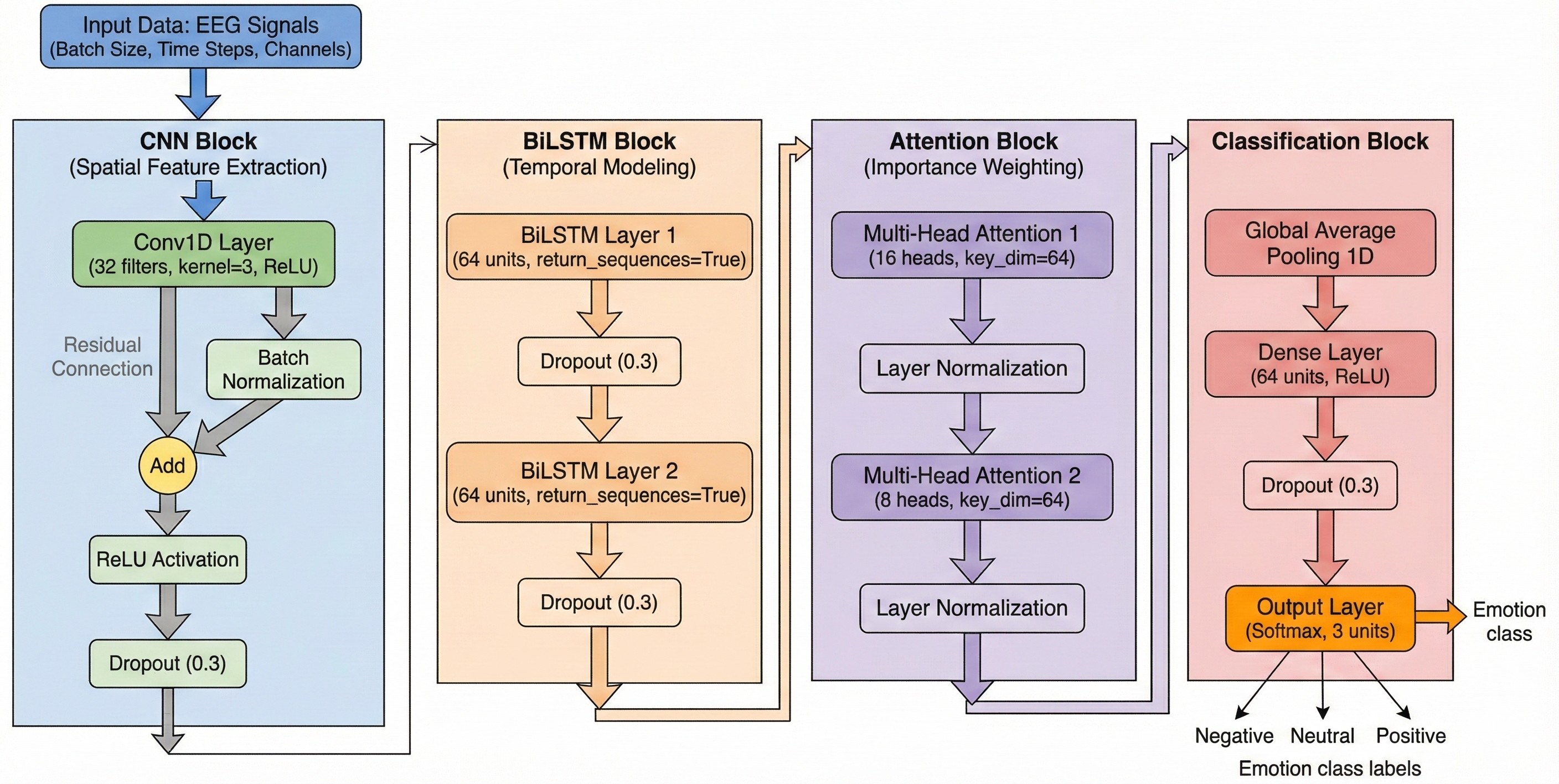
Their model is a “hybrid” that combines several parts, each with a role:
- CNN (Convolutional Neural Network): Think of this as a pattern spotter. It looks across features to pick up local shapes or patterns.
- BiLSTM (Bidirectional Long Short-Term Memory): Imagine two readers going through a sentence, one from start to end and one from end to start, then comparing notes. This helps the model understand how the signal changes over time in both directions.
- Self-Attention (Transformer-style): Like a spotlight that highlights the most important moments or features. They use two attention layers (“dual attention”) with different settings to catch different kinds of important details.
- Pooling: Two ways of summarizing—average pooling (overall trend) and max pooling (strongest moments).
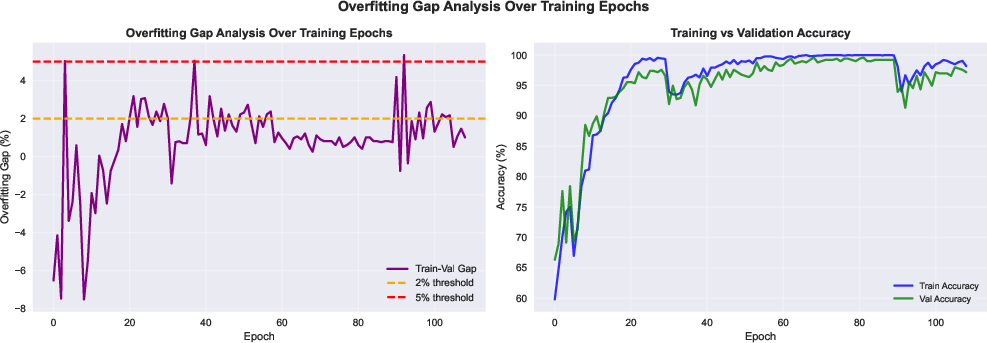
- Regularization tricks to prevent overfitting (doing great on training but poorly on new data), such as dropout (randomly “turning off” parts during training), weight decay (discouraging overly large settings), label smoothing (not being too confident), and early stopping (stop training if it stops improving).
They also compared their new model to common baselines:
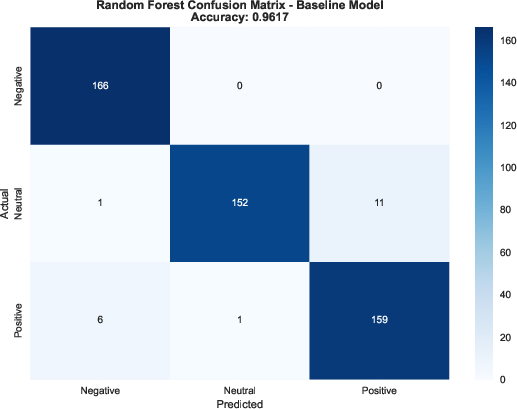
- Random Forest (many decision trees).
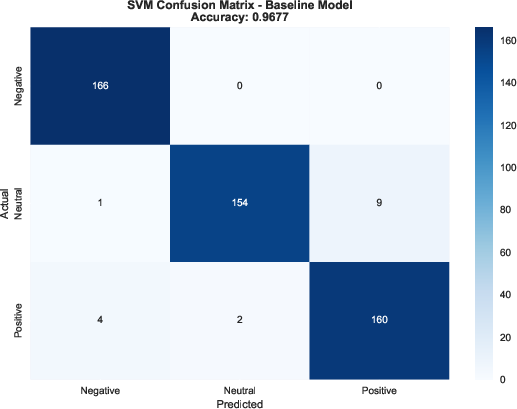
- SVM (Support Vector Machine).
- A simple neural network (MLP).
Finally, they used statistical tests (Friedman and Wilcoxon tests) to check if their improvements were real and not just luck.
What did they find, and why does it matter?
Here are the main results:
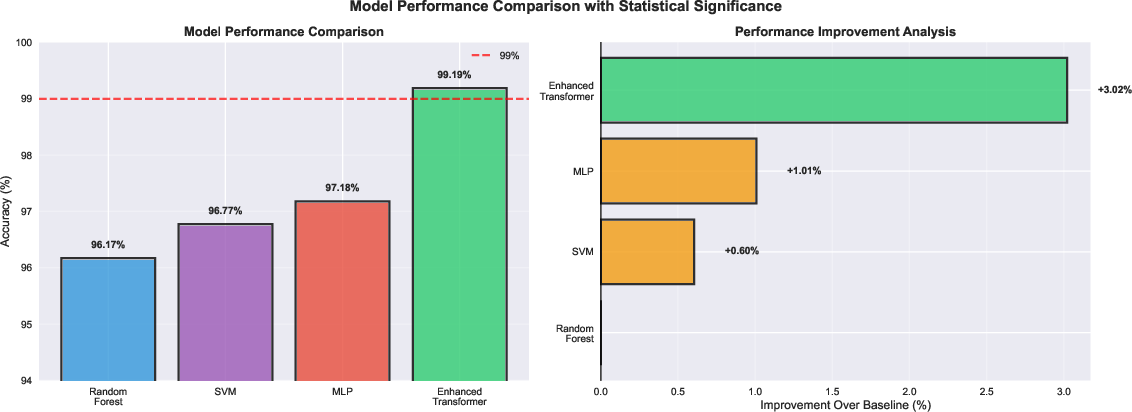
- Their model reached about 99.19% accuracy on the test data, beating all baselines (Random Forest ≈ 96.5%, SVM ≈ 96.8%, MLP ≈ 97.2%).
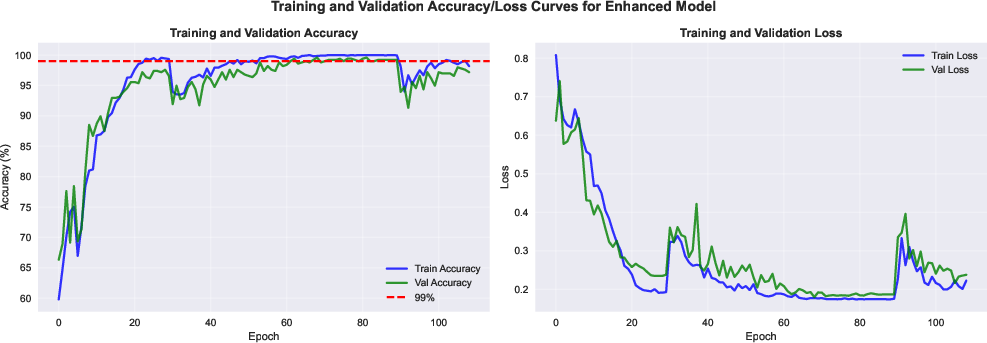
- The gap between training and test accuracy was tiny (about 0.56%), which means it didn’t overfit much and generalizes well on this dataset.
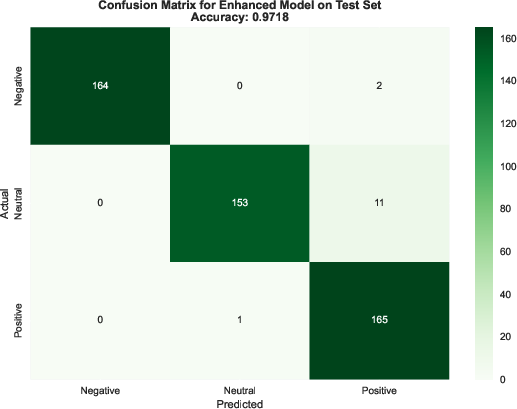
- Performance was balanced across all three emotion classes (precision/recall/F1 all ≈ 99%), so it didn’t favor one emotion over another.
- Statistical tests showed the improvement over the baselines was significant (unlikely to be due to chance).
Which features mattered most?
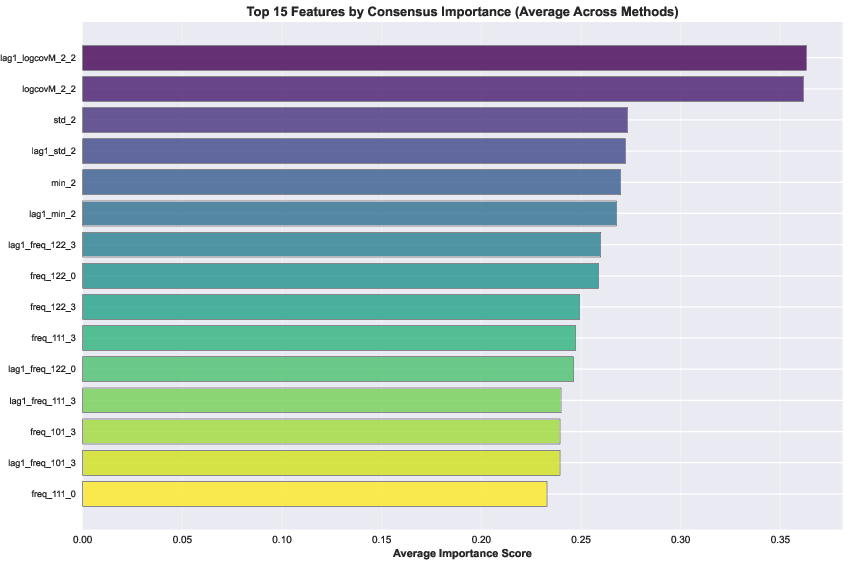
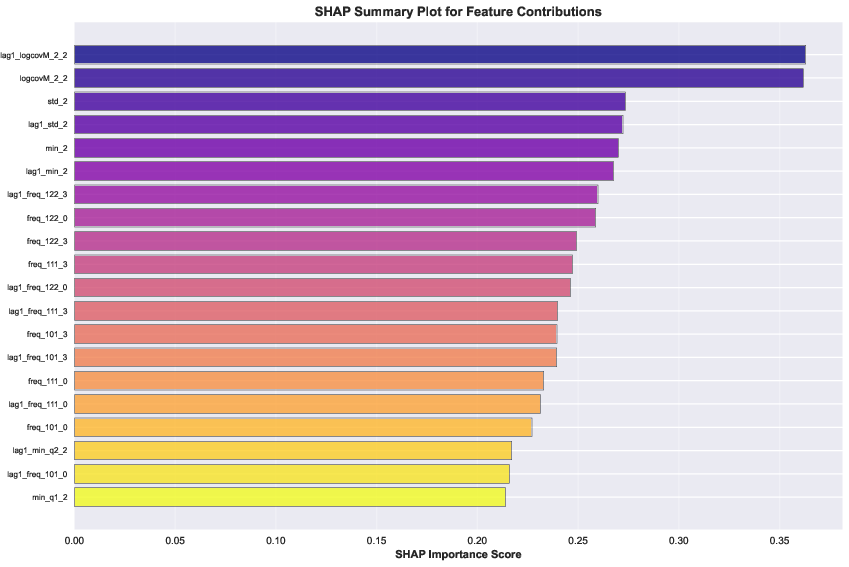
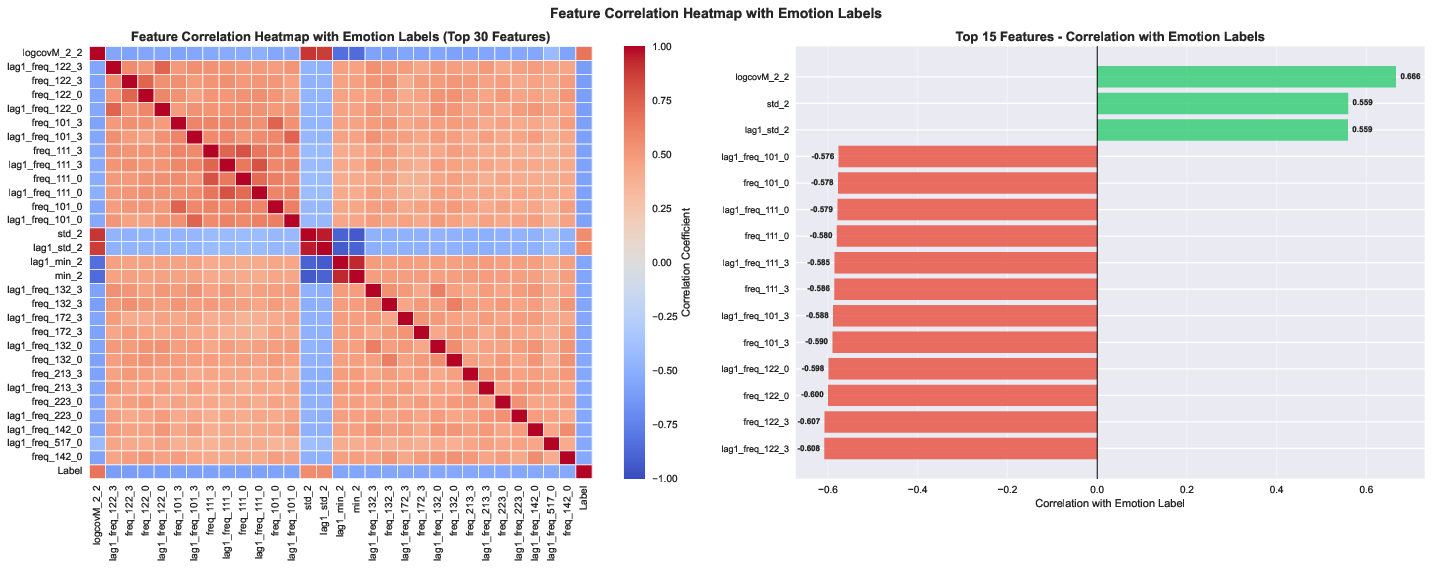
- Features that describe how different EEG channels relate to each other (called “covariance”) were the most important. When they removed these, accuracy dropped the most (by about 15%).
- Statistical features (like mean/variance) and frequency features (like power in alpha/beta/gamma bands) also helped, but less than covariance.
- This suggests emotions are reflected not just in what each EEG channel does alone, but mainly in how brain regions work together.
Why is this important?
- It shows that a carefully designed hybrid model can make emotion recognition from EEG more accurate and robust.
- Emphasizing “relationships between channels” lines up with the idea that emotions involve networks across the brain, not just one spot.
What could this mean for the future?
Potential impact:
- Health and wellbeing: More objective tools to monitor emotions could support mental health check-ins, therapy progress, or early warning signs for mood disorders.
- Smarter devices: Computers and apps that respond to how you feel (e.g., adjusting difficulty in learning apps or offering breaks when you’re stressed).
- Research insights: Knowing that inter-channel relationships matter most can guide future brain studies and better feature design.
Cautions and next steps:
- The study used one public dataset. We need tests across more datasets, different headsets, and real-time settings.
- Emotions are complex and often continuous, not just three categories.
- Explanations from attention and feature importance show correlations, not true cause-and-effect.
- Real-world use will need to handle noise, subject differences, and privacy concerns.
The takeaway
By combining pattern spotting (CNN), time understanding (BiLSTM), and smart focus (attention), plus strong anti-overfitting strategies, the authors built a model that recognizes emotions from EEG very accurately on their dataset. The relationships between brain channels (covariance) are especially key. This approach moves us closer to reliable, understandable, and practical emotion-aware systems—but broader testing and careful, ethical deployment are essential.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- External validity: Results are shown on a single Kaggle feature dataset; no cross-dataset evaluation (e.g., DEAP, SEED, AMIGOS, MAHNOB-HCI) to establish generalizability.
- Subject-independent generalization: The dataset description does not include subject IDs, and splits appear sample-wise; evaluate leave-one-subject-out or leave-one-session-out protocols to prevent within-subject leakage.
- Potential preprocessing leakage: The paper states features were z-score standardized before partitioning; re-run with scalers fit only on training folds to eliminate target leakage risk.
- Raw signal vs. precomputed features: The model is applied to 988-dimensional feature vectors, not raw multi-channel EEG; test the architecture on raw time-series to verify its capacity to learn spatial-temporal patterns directly from signals.
- Temporal modeling validity: With static feature vectors, the BiLSTM treats the feature index as a “sequence”; clarify and quantify whether this pseudo-temporal ordering is meaningful, and compare against treating the input as non-sequential.
- Architectural ablations: No component-level ablation of residual CNNs, dual BiLSTMs, dual attention, dual pooling, label smoothing, or weight decay; provide ablations to isolate each component’s contribution to accuracy and generalization.
- Attention design choices: The dual attention configuration (16+8 heads) is not justified via sensitivity analysis; explore different head counts, attention placements, and compare to single-attention or transformer-only variants.
- Pooling strategy: Dual max/average pooling is not compared to alternatives (e.g., learnable pooling, CLS-token strategies); benchmark pooling choices for performance and stability.
- Baseline coverage: Comparisons exclude widely used deep EEG baselines (e.g., EEGNet, Shallow/DeepConvNet, TSception, TCNs, GNN/GCN/AGCN models, transformer-only baselines); include these to substantiate state-of-the-art claims.
- Benchmarking on standard corpora: Claims of “state-of-the-art” are not evaluated on community benchmarks with standard protocols; replicate on DEAP/SEED with published splits for comparable rankings.
- Statistical rigor: No nested cross-validation or clear separation between model selection and final testing; adopt nested CV and report effect sizes and confidence intervals for all metrics (not only accuracy).
- Calibration and uncertainty: No assessment of probability calibration (e.g., ECE, Brier score) or uncertainty estimation; add calibration curves and uncertainty-aware evaluation for deployment readiness.
- Robustness to real-world noise: Robustness is only tested with Gaussian noise and feature scaling; evaluate resilience to EEG-specific artifacts (EOG/EMG, motion), channel dropouts, electrode shifts, and session-to-session non-stationarity.
- Distribution shift: No tests under domain shifts (cross-session, cross-device, cross-lab); incorporate domain adaptation or transfer learning experiments to assess out-of-distribution generalization.
- Label taxonomy: Only three discrete classes (negative/neutral/positive); extend to continuous affect (/), multi-label emotion, and ambiguous/mixed states.
- Personalization: No subject-specific adaptation (e.g., fine-tuning, few-shot transfer, meta-learning) is explored; evaluate personalized vs. population-level performance trade-offs.
- Interpretability limits: SHAP and attention analyses are correlational; perform perturbation-based tests, causal proxies (e.g., counterfactuals), and consistency checks between SHAP and attention to strengthen interpretability claims.
- Neurophysiological grounding: Top features are not mapped back to electrodes/regions or frequency bands; link feature attributions to scalp topography and known affective neurophysiology for validation.
- Connectivity feature provenance: Covariance features dominate performance, but their computation (channels, montage, reference, windowing) is unspecified; detail and verify their robustness across montages and with raw-signal connectivity (e.g., Riemannian methods).
- Error analysis: No qualitative/quantitative analysis of misclassifications; examine confusion patterns, class-conditional errors, and hard cases to guide model and feature refinements.
- Data augmentation breadth: Augmentations are limited; evaluate EEG-tailored augmentations (time-warping, band-limited perturbations, mixup/cutmix, channel dropout, specaugment-like transformations).
- Hyperparameter transparency: Critical hyperparameters (e.g., learning rate values, batch size, number of epochs, kernel sizes, filter counts, hidden units) and exact layer configurations are not fully reported; provide full specs for reproducibility.
- Reproducibility artifacts: Code, training scripts, and random seeds are not provided; release an open-source implementation, versioned dependencies, and exact checkpoints.
- Resource profiling: Inference/training latency, FLOPs, memory footprint, and energy usage are not quantified; measure and report resource costs on target hardware (edge vs. GPU) and assess real-time feasibility.
- Online/real-time evaluation: All results are offline on preprocessed features; validate a streaming pipeline with window lengths, overlap, and end-to-end latency under real-time constraints.
- Class imbalance and prevalence shift: Although roughly balanced here, real-world deployments may be skewed; test performance under varying class prevalences and apply appropriate reweighting/calibration.
- Fairness and bias: No analysis across demographic or clinical subgroups; if metadata become available, quantify performance disparities and mitigate bias.
- Adversarial robustness and security: Sensitivity to adversarial or spurious perturbations is untested; evaluate adversarial robustness and defenses for safety-critical applications.
- Confidence intervals for all metrics: Only accuracies have CIs; provide CIs for precision/recall/F1 (macro and per-class) to assess variability comprehensively.
- Consistency of evaluation protocol: The paper mentions both 5-fold cross-validation and an 80/20 held-out test; clarify the evaluation pipeline to avoid data reuse and ensure clean separation of training/validation/test sets.
Practical Applications
Immediate Applications
The following items distill concrete, deployable use cases that leverage the paper’s hybrid EEG emotion-classification model, dual attention mechanisms, and feature insights. Each bullet includes sector alignment and feasibility considerations.
- Emotion-aware human–computer interaction prototypes
- Sectors: software, education, gaming, customer service
- Application: Adaptive interfaces that modulate content, difficulty, notification frequency, and tone based on detected neutral/positive/negative states in real time (e.g., e-learning platforms that reduce cognitive load when negative affect is detected; games that tune challenge level).
- Tools/Workflows: Lightweight inference service (ONNX/TensorRT), real-time pipeline (acquisition → artifact filtering → z-score normalization → inference → UI hooks), Unity/Unreal plugins, web SDK.
- Assumptions/Dependencies: Availability of consumer-grade EEG headsets with sufficient channel quality; user consent and privacy controls; acceptable latency; generalization beyond the paper’s dataset; artifact handling in non-lab environments.
- Neurofeedback session personalization in clinical or lab settings
- Sectors: healthcare, wellness
- Application: Use dual attention maps and SHAP-style attributions to tailor neurofeedback protocols (e.g., focusing on channels/relationships highlighted by covariance feature importance), improving training efficiency.
- Tools/Workflows: “Attention-guided neurofeedback” module integrated with EEG systems; clinician dashboard showing attention overlays and connectivity indices; session logging.
- Assumptions/Dependencies: Not a medical diagnostic; requires IRB approval for clinical research; headset comfort and session compliance; clinician training for interpretation.
- UX research and advertising effectiveness measurement
- Sectors: marketing, product design, media
- Application: Augment A/B tests with objective affect measures to quantify engagement and valence shifts; identify content segments eliciting negative vs. positive responses.
- Tools/Workflows: “EEG Affect Dashboard” for experiment orchestration; batch inference on recorded sessions; per-stimulus affect timelines; export to BI tools.
- Assumptions/Dependencies: Participants willing to wear EEG; standardized protocol to minimize artifacts; sample sizes sufficient for statistical power; compliance and consent.
- Academic benchmarking and teaching materials
- Sectors: academia, data science education
- Application: Use the Enhanced Transformer-CNN-BiLSTM architecture and training practices (AdamW, label smoothing, cosine scheduling, gradient clipping) to teach robust deep learning for physiological signals and to benchmark new datasets.
- Tools/Workflows: Open-source reproducible pipelines; Jupyter tutorials; assignments focusing on regularization and attention interpretability.
- Assumptions/Dependencies: GPU availability for training; access to EEG datasets; alignment with institutional curricula.
- Covariance-first feature engineering toolkit for EEG
- Sectors: neuroscience R&D, EEG software vendors
- Application: Provide a feature pipeline that prioritizes covariance/connectivity features (most discriminative per ablation) with optional statistical and spectral augmentations; channel-pair selection tooling.
- Tools/Workflows: “EEG-CovFeat” library (feature builders, ablation toggles, importance ranking), integration with MNE, EEGLAB.
- Assumptions/Dependencies: Sufficient channel count and quality to estimate covariance reliably; consistent preprocessing; calibration per device.
- Real-time emotion monitoring pilot for opted-in workplace well-being
- Sectors: HR tech, wellness programs
- Application: Short-term, voluntary pilots where individuals use EEG headsets to track affect during focused tasks; prompts for breaks or mindfulness when negative affect persists.
- Tools/Workflows: Edge inference app; local data storage with privacy safeguards; opt-in consent workflows; anonymized summary reports.
- Assumptions/Dependencies: Strict privacy and ethical safeguards; non-coercive participation; user comfort; environmental artifact management.
- Social robotics lab prototypes with affect-aware behavior
- Sectors: robotics (R&D), eldercare tech (pilot studies)
- Application: Robots adjust speech, pacing, and interaction strategies based on detected affect; used in controlled lab or assisted living pilot studies.
- Tools/Workflows: ROS node subscribing to affect classification API; behavior policy engine; logging and safety checks.
- Assumptions/Dependencies: Headset comfort for users; controlled environments; small-scale trials; ethical review.
- Clinical research-grade logging and auditability
- Sectors: healthcare research, regulatory science
- Application: Attention-based interpretability reports used to audit sessions (e.g., which features/channels drove decisions), supporting transparency and bias checks.
- Tools/Workflows: Auto-generated session reports with attention overlays, feature importance summaries, confidence intervals; data lineage and versioning.
- Assumptions/Dependencies: Does not confer clinical diagnosis; standardized reporting formats; careful communication to avoid over-interpretation.
- Edge deployment demos on embedded hardware
- Sectors: IoT/edge computing
- Application: Demonstrate feasible inference with ~2.1M parameters on Jetson Nano/Orin or equivalent, validating latency and power targets for portable use.
- Tools/Workflows: Model quantization/pruning; ONNX export; performance benchmarking scripts; telemetry dashboard.
- Assumptions/Dependencies: Adequate optimization for target hardware; sustained accuracy after compression; battery and thermal constraints.
- Policy and governance quick-start guidance for emotion AI pilots
- Sectors: policy, compliance, institutional review boards
- Application: Immediate checklists for consent, data minimization, bias assessment, transparency of attention-based explanations, and opt-in participation, tailored to EEG-based emotion pilots.
- Tools/Workflows: Template consent forms; risk assessment worksheets; governance logs referencing interpretability artifacts.
- Assumptions/Dependencies: Limited to pilot contexts; not a substitute for comprehensive regulation; institutional buy-in.
Long-Term Applications
The following items represent applications that require further research, scaling, multi-site validation, regulatory approval, device advances, or multimodal integration before reliable deployment.
- Clinical-grade diagnostics and longitudinal monitoring for mood disorders
- Sectors: healthcare
- Application: Objective biomarkers for depression, anxiety, bipolar episodes using continuous or periodic EEG-based affect tracking integrated with EHRs; treatment response monitoring.
- Tools/Workflows: Clinical validation studies; multi-site trials; standardized acquisition protocols; clinician-facing dashboards; integration with digital phenotyping.
- Assumptions/Dependencies: Regulatory approval (FDA/CE); robust cross-subject generalization; culturally sensitive labeling; rigorous artifact suppression; clinical utility evidence.
- Consumer wearables for emotion health tracking
- Sectors: wellness, consumer electronics
- Application: Comfortable, low-profile EEG wearables that deliver privacy-preserving, on-device affect estimates to support stress management and mindfulness coaching.
- Tools/Workflows: Edge ML pipelines; secure enclaves; adaptive calibration; mobile UX for trends and recommendations.
- Assumptions/Dependencies: Advances in unobtrusive EEG sensors; long battery life; robust performance “in the wild”; strong privacy guarantees; user acceptance.
- Affective tutoring systems for schools and neurodiverse learners
- Sectors: education
- Application: Emotion-aware curricula that modulate pacing, modality, and feedback based on real-time affect and engagement; personalized learning plans.
- Tools/Workflows: School-scale deployment frameworks; multimodal fusion (EEG + eye tracking + interaction logs); teacher dashboards and guardrails.
- Assumptions/Dependencies: Device affordability and hygiene; parental consent; equitable access; evidence of learning gains; policy compliance.
- Multimodal affect platforms combining EEG with other signals
- Sectors: healthcare, automotive, safety-critical systems
- Application: Robust affect estimation using EEG fused with PPG/ECG, EDA, facial expressions, voice, and context to reduce false positives/negatives under noise.
- Tools/Workflows: Fusion architectures (transformers + GNNs), calibration protocols, uncertainty estimation, continuous learning.
- Assumptions/Dependencies: Sensor integration and synchronization; domain adaptation across contexts; privacy-preserving multimodal data processing.
- Automotive driver-state monitoring (stress/fatigue)
- Sectors: automotive
- Application: Cabin systems adjusting HVAC, infotainment, and ADAS alerts based on driver affect and workload.
- Tools/Workflows: Embedded inference; headband/seat-integrated sensors; safety policies.
- Assumptions/Dependencies: Unobtrusive EEG form factors; regulatory/insurance acceptance; robust performance during motion and vibration; strong safety cases.
- Workplace safety and high-stress operations (opt-in)
- Sectors: industrial safety, aviation, healthcare operations
- Application: Monitoring operators for sustained negative affect or overload to trigger mitigation protocols in safety-critical environments.
- Tools/Workflows: Real-time monitoring platforms; alerting policies; post-event analysis.
- Assumptions/Dependencies: Ethical frameworks preventing surveillance misuse; union/regulator approval; non-coercive participation; resilience to operational artifacts.
- Personalized digital therapeutics and precision psychiatry
- Sectors: healthcare, digital health
- Application: Adaptive treatment selection and dosing informed by EEG-based affect trajectories; closed-loop interventions.
- Tools/Workflows: Predictive models with patient-specific calibration (transfer learning/few-shot adaptation), uncertainty-aware decision support.
- Assumptions/Dependencies: Longitudinal evidence; interoperability with care pathways; rigorous safety and efficacy trials.
- Pharmaceutical R&D for emotion-modulating treatments
- Sectors: pharma
- Application: Objective EEG affect endpoints in clinical trials to measure drug efficacy (e.g., antidepressants, anxiolytics).
- Tools/Workflows: Standardized protocols; endpoint validation; regulatory alignment.
- Assumptions/Dependencies: Acceptance of EEG-based endpoints; cross-site reproducibility; device standardization.
- Standards, certification, and auditing frameworks for EEG-based emotion AI
- Sectors: policy, standards bodies
- Application: Norms for transparency (attention/explanation reporting), fairness audits across demographics, consent, data retention, and risk management.
- Tools/Workflows: Certification processes; audit toolkits; reference implementations; public registries.
- Assumptions/Dependencies: Multi-stakeholder consensus; international harmonization; ongoing oversight.
- Covariance-aware hardware and channel-layout optimization
- Sectors: EEG device manufacturing, neuroscience engineering
- Application: Sensor arrays and electrode placements optimized to maximize discriminative inter-channel covariance, improving sensitivity while minimizing channels.
- Tools/Workflows: Design-space exploration using feature importance maps; simulation with synthetic and real datasets.
- Assumptions/Dependencies: Collaboration between hardware and algorithm teams; validation across head geometries and hair types; cost and ergonomics constraints.
Glossary
- Ablation study: A systematic removal of components or features to assess their individual contribution to performance. "ablations identify functional connectivity as most informative."
- AdamW optimizer: An adaptive gradient descent optimizer that decouples weight decay from the gradient-based update. "the AdamW optimizer"
- Affective computing: A field that studies systems and devices that can recognize, interpret, and process human emotions. "affective computing"
- ANOVA: Analysis of variance; a statistical test comparing means across groups, often referenced via the F-statistic. "F-statistic (ANOVA)"
- Bidirectional long short-term memory (BiLSTM): A recurrent neural network that processes sequences in both forward and backward directions to capture temporal dependencies. "bidirectional long short-term memory (BiLSTM) layers."
- Bonferroni correction: A multiple-comparisons adjustment that controls the family-wise error rate by dividing the significance threshold by the number of tests. "Bonferroni correction ()"
- Cosine annealing schedule: A learning-rate schedule that decays the rate following a cosine curve, often with warm-up. "cosine annealing schedule with an initial warm-up phase"
- Covariance features: Measures capturing pairwise relationships between EEG channels, reflecting inter-channel dependencies. "covariance features dominate discrimination"
- Cross-entropy loss: A loss function measuring the difference between predicted probability distributions and true labels. "cross-entropy loss function with label smoothing"
- Cross-validation: A model evaluation method that partitions data into multiple folds to assess generalization reliably. "5-fold cross-validation"
- Differential entropy: A continuous analog of entropy used to quantify the uncertainty of continuous random variables. "using differential entropy and power spectral density features"
- Domain adaptation: Techniques for transferring knowledge from a source domain to a different but related target domain. "domain adaptation techniques"
- Dropout: A regularization technique that randomly deactivates neurons during training to prevent overfitting. "dropout with a rate of 0.3"
- Early stopping: A regularization method that halts training when validation performance ceases to improve. "Early stopping was employed based on validation loss"
- Eigenvalue-based features: Features derived from eigenvalues of matrices (e.g., covariance), summarizing structural properties of signals. "eigenvalue-based features"
- Electroencephalography (EEG): A non-invasive method to record electrical activity of the brain via scalp electrodes. "Electroencephalography (EEG)-based emotion recognition"
- Extra Trees: An ensemble method similar to Random Forests but using more randomization in split thresholds and feature selection. "Extra Trees importance"
- F-statistic: A ratio of variances used in ANOVA to test group differences. "F-statistic (ANOVA)"
- Friedman test: A non-parametric statistical test for detecting differences in treatments across multiple test attempts. "the Friedman test was applied"
- Functional connectivity: Statistical dependencies between spatially distinct brain regions, indicating network interactions. "functional connectivity as most informative."
- Gaussian noise injection: Data augmentation by adding Gaussian-distributed noise to inputs to improve robustness. "Gaussian noise injection"
- Gini impurity: A metric for decision tree splits that measures the likelihood of incorrect classification. "Gini impurity splitting"
- Global average pooling: A pooling operation that averages feature maps across spatial or temporal dimensions. "global average pooling and global max pooling"
- Global max pooling: A pooling operation that takes the maximum over spatial or temporal dimensions. "global average pooling and global max pooling"
- Gradient clipping: Constraining gradients to a maximum norm to stabilize training and prevent exploding gradients. "Gradient clipping with a maximum norm of 1.0"
- Graph neural networks: Neural architectures that operate on graph-structured data, leveraging node and edge relationships. "regularized graph neural networks"
- Label smoothing: A regularization technique that softens hard labels to reduce overconfidence and improve generalization. "label smoothing"
- Layer normalization: A normalization technique that normalizes activations across features within a layer. "layer normalization"
- L2 weight decay: A regularization technique that penalizes large weights to reduce overfitting. "an L2 weight decay coefficient"
- Multi-head self-attention: An attention mechanism that projects queries, keys, and values into multiple subspaces to capture diverse dependencies. "dual multi-head self-attention modules (16+8 heads)"
- Mutual information: A measure of the amount of information one variable contains about another. "Mutual Information scores"
- Non-stationarity: A property of signals whose statistical characteristics change over time. "non-stationarity in EEG signals"
- Pearson correlation coefficient: A measure of linear correlation between two variables. "Pearson correlation coefficients"
- Power spectral density: A function that quantifies the power present in different frequency components of a signal. "power spectral density within alpha, beta, and gamma bands"
- Radial basis function (RBF) kernel: A kernel function used in SVMs that measures similarity based on distance in feature space. "radial basis function kernel ()"
- Residual connections: Skip connections that add inputs to outputs of layers to facilitate gradient flow in deep networks. "residual connections are incorporated"
- SHAP: A model-agnostic method for interpreting predictions using Shapley values from cooperative game theory. "SHAP attribution"
- Softmax: A function that converts logits into probabilities by exponentiating and normalizing. "softmax output layer"
- Stratified sampling: A sampling strategy that preserves class proportions across splits. "stratified sampling to preserve class proportions"
- Transformer: A neural architecture based on self-attention mechanisms for modeling long-range dependencies. "transformer-based attention mechanisms"
- Wilcoxon signed-rank test: A non-parametric test for comparing paired samples to assess differences in their distributions. "Wilcoxon signed-rank tests"
- Z-score normalization: A standardization method that rescales features to zero mean and unit variance. "z-score normalization"
Collections
Sign up for free to add this paper to one or more collections.

