- The paper introduces a neuro-inspired mixture-of-experts model that partitions EEG signals by brain region to enhance silent speech decoding.
- It uses adaptive expert routing and hierarchical cross-regional distillation to achieve up to +12.37% accuracy gains over baseline models.
- The modular design delivers robust performance with fewer parameters, advancing the development of interpretable brain-computer interfaces.
BrainStack: Functionally Guided Neuro-MoE for EEG-Based Silent Speech Decoding
Introduction and Motivation
BrainStack introduces a neuro-inspired mixture-of-experts (Neuro-MoE) paradigm that leverages the modular organization of the human cortex for EEG-based language decoding (2601.21148). Existing methods for neural decoding from EEG often treat the entire electrode montage as a homogeneous input, neglecting established neuroscientific evidence that distinct anatomical regions contribute specialized dynamics to cognitive tasks. This global treatment leads to suboptimal exploitation of distributed, low-SNR neural features, especially for silent speech, which depends on subtle and distributed inter-regional activity.
To address this, BrainStack partitions EEG signals according to functional brain regions, assigning them to a set of region-specific experts, alongside a global expert designed to capture long-range dependencies. Critical to the architecture is an adaptive expert routing gate that dynamically fuses outputs based on task context, and a hierarchical cross-regional distillation process whereby the global expert regularizes region-specific specialists, enforcing coherence across the model.
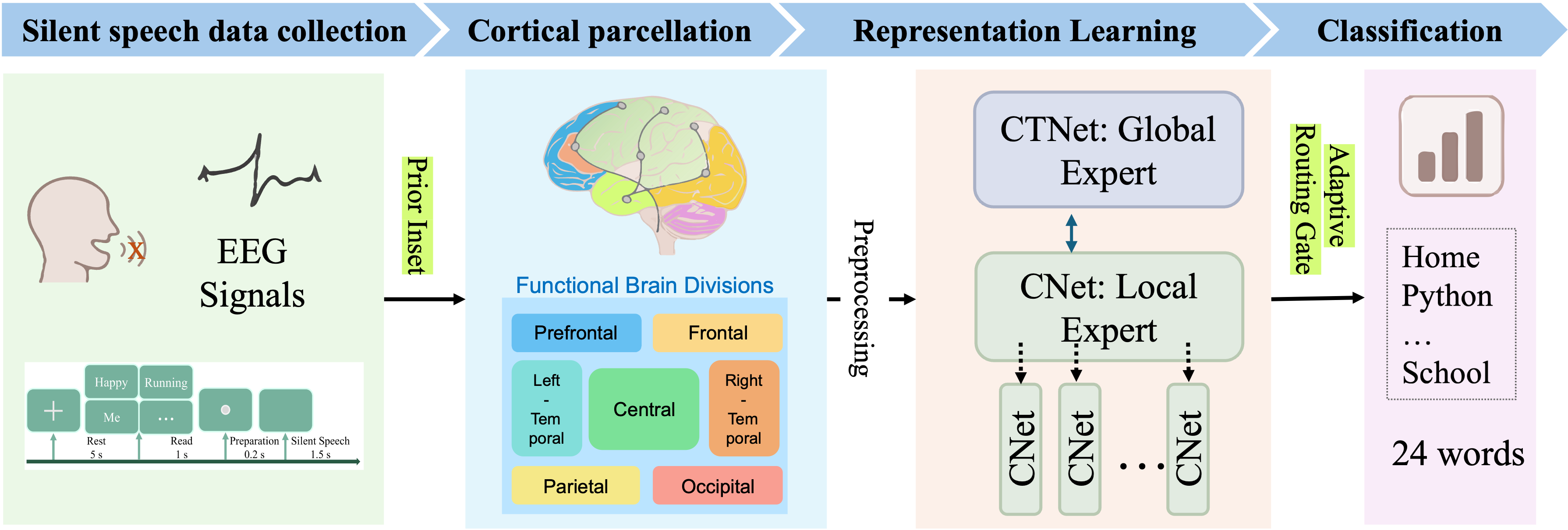
Figure 1: Overall illustration of EEG-based text decoding using BrainStack.
Architecture: Anatomically Guided Modular Design
The system architecture comprises three fundamental components:
- Anatomically Partitioned Experts: The EEG input is decomposed into seven spatial regions (Prefrontal, Frontal, Central, Left/Right-Temporal, Parietal, Occipital), each processed by a lightweight convolutional expert. These extract localized spatiotemporal dynamics relevant to their anatomical domain.
- Global Expert (CTNet): The global expert receives the whole EEG tensor, applying temporal and spatial convolutions followed by Transformer blocks. This design enables encoding of both fine-grained local and distributed global context.
- Adaptive Expert Router: Outputs from all experts are adaptively aggregated via a learnable router, which computes context-dependent softmax weights over expert representations for each prediction, enabling spatially selective and task-adaptive fusion.
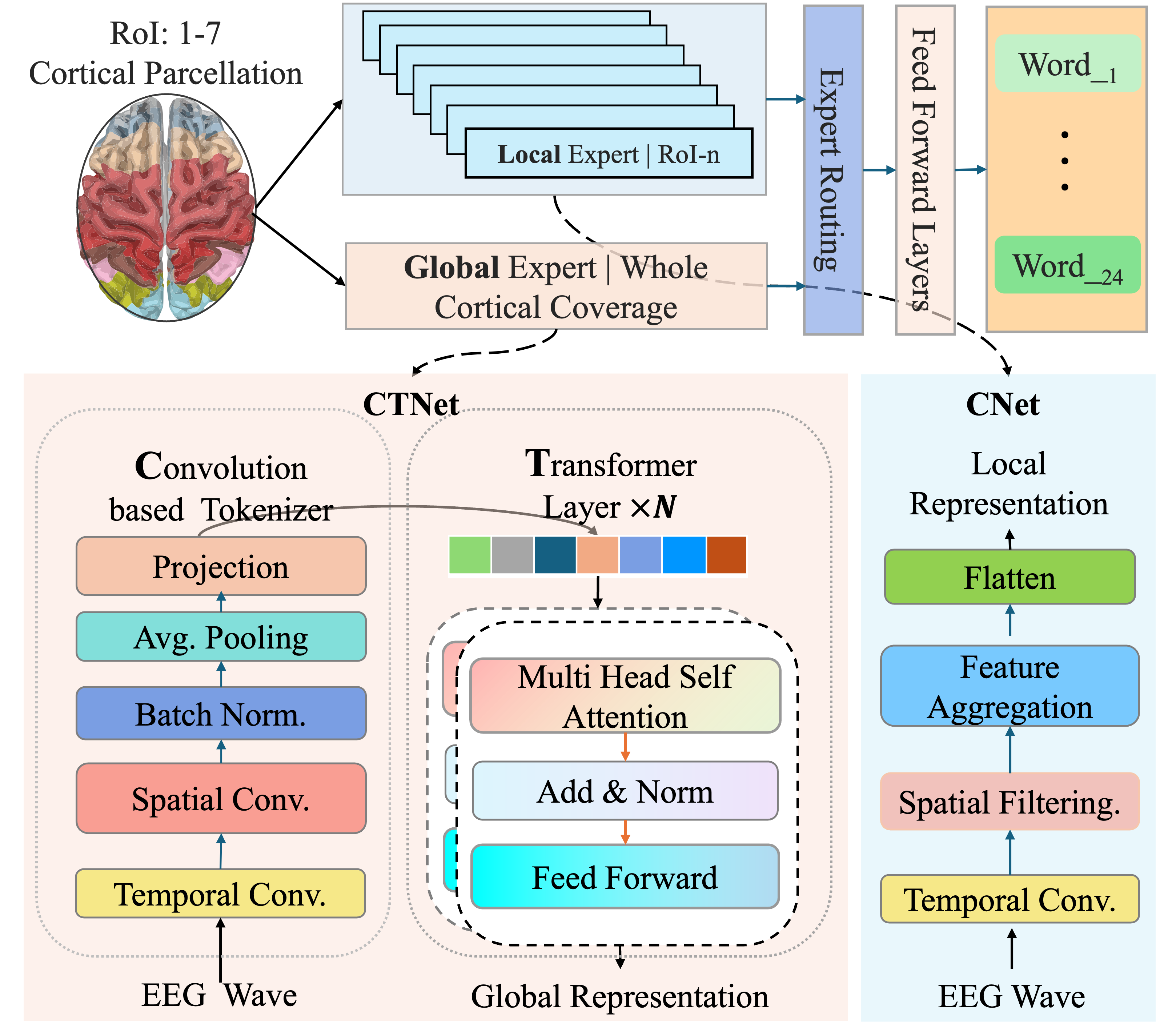
Figure 2: Overview of the proposed BrainStack for EEG-based text decoding. Raw EEG signals are regionally subdivided and processed by parallel regional experts and a global CTNet expert, with context-dependent fusion via an expert router.
A hierarchical multi-objective loss, dynamically scheduled, trains the model. The objective consists of a fusion loss (class prediction), global expert supervision, regional expert supervision, and an inter-expert distillation term. Critically, the latter imposes top-down guidance, transmitting semantic information from the global expert to each regional expert using logit-based KL divergence.
Functional and Attentional Insights
Attribution analysis provides interpretability, revealing spatiotemporal evolution of model attention during silent speech. Activation maps confirm that initial processing is localized, with activity originating in region-specific experts consistent with expected cognitive dynamics (e.g., frontal and temporal initiation), followed by progressive inter-regional integration captured in the global expert.
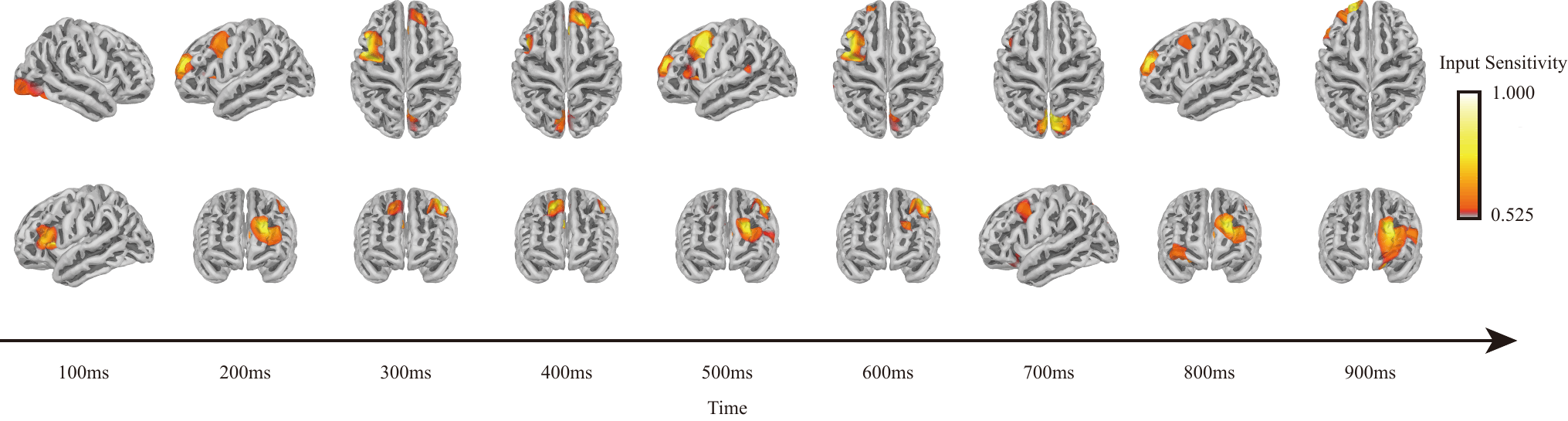
Figure 3: Spatiotemporal evolution of attention during silent speech decoding, showing transition from localized activations to broad inter-regional integration.
Further examination of the learned routing weights between experts corroborates neuroscientific hypotheses: Occipital and Temporal regions contribute most strongly to decoding accuracy, suggesting key involvement of visual-cortical and temporal-linguistic processes. Conversely, excessive dominance of global pooling is negatively correlated with subject accuracy, emphasizing that homogenized modeling can dilute region-specific discriminative information.
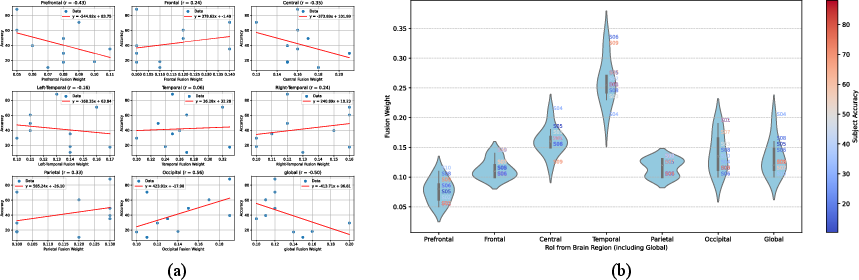
Figure 4: Analysis of routing gate reveals strong positive correlation between Occipital region contribution and decoding accuracy; violin plots expose variability in regional weights across subjects.
Experimental Results and Comparative Analysis
The SilentSpeech-EEG (SS-EEG) dataset—a large-scale corpus comprising 120 hours of 128-channel EEG from 12 subjects over 24 words—serves as the primary benchmark. This resource eclipses previous datasets in scale and vocabulary, enabling robust evaluation of within- and cross-subject generalization for silent speech decoding.
The proposed BrainStack achieves an average accuracy of 41.87% (with a peak single-subject accuracy of 88.05%), outperforming strong CNN and Transformer-based baselines (EEGNet, TCNet, EEGConformer, STTransformer) by margins up to +12.37%. Importantly, BrainStack attains these results with one-fifth the parameter count of large foundation models like LaBraM, demonstrating that functionally modular, neuro-inspired architectural design substantially outweighs brute parameter scaling for this domain.
Performance analysis highlights substantial subject-level variability, with high-performing subjects achieving significantly greater stability across random seeds. The model's modularity and dynamic routing are effective in mitigating inter-individual differences in neural signatures.
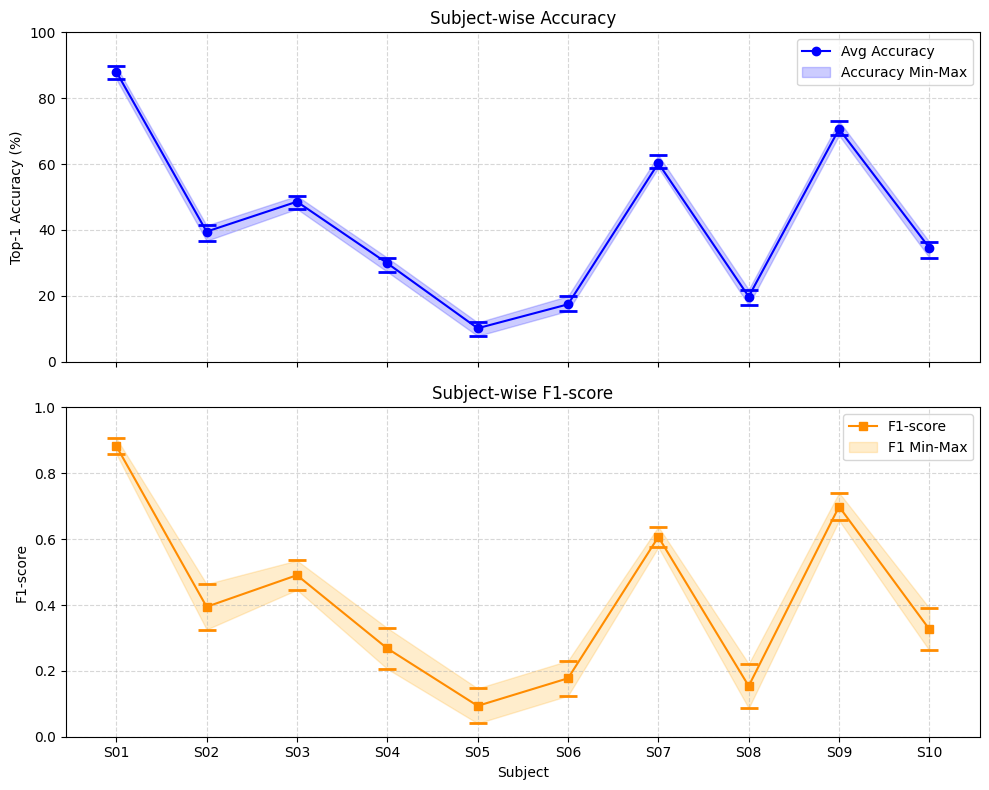
Figure 5: Subject-wise accuracy and F1-score variability, illustrating model stability for high-performing subjects and marked variance for weaker ones.
Ablation studies dissecting the role of expert heterogeneity, routing, and hierarchical loss demonstrate the necessity of each constituent: removal of hierarchical distillation (-6.18%) or adaptive routing (-12.46%) results in significant accuracy drops. Homogeneous or locally limited architectures are insufficient to capture complementary neural dynamics, supporting the central hypothesis of modular functional specialization.
Theoretical and Practical Implications
BrainStack operationalizes key neuroscientific principles (functional modularity and cross-regional integration) in a computational architecture, providing a more interpretable, robust, and generalizable framework for low-SNR EEG decoding. Practically, this carries strong implications for real-world brain-computer interface applications, enabling more reliable silent-speech decoding for communication-impaired individuals at larger vocabulary sizes than previously feasible.
On the theoretical front, the model demonstrates that explicit encoding of anatomical priors and adaptive coordination of specialized modules substantially boosts neural decoding efficacy, even when compared against pre-trained or end-to-end deep learning pipelines. This informs broader trends in neuro-inspired AI: rather than monolithic scaling or naive ensembling, domain-derived structural modularity and hierarchical information flow are necessary for bridging low SNR, high-dimensional biological signals with downstream cognition.
Further, the release of the extensive SS-EEG benchmark is poised to catalyze rigorous evaluation and methodological innovation in silent speech and broader neural decoding research.
Conclusion
BrainStack represents a distinct advance in EEG-based neural language decoding by unifying anatomically grounded modularization, regionally specialized experts, and adaptive global-local integration via a neuro-inspired mixture-of-experts framework. Through adaptive expert routing and hierarchical cross-distillation, the model delivers superior decoding accuracy and interpretability, validated on a new large-scale silent speech dataset. These results substantiate the theoretical premise of functional modularity and highlight the critical role of brain-inspired architectural priors for practical neural decoding. Future work should explore extension to richer tasks (sentence-level or open-vocabulary decoding), deployment in real-time BCI systems, and adaptation to other brain imaging modalities.